1. Tabuľka hodnôt F-F-testu pre hladinu významnosti α = 0,05
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 12 | 24 | ∞ | |
| 1 | 161,45 | 199,50 | 215,72 | 224,57 | 230,17 | 233,97 | 238,89 | 243,91 | 249,04 | 254,32 |
| 2 | 18,51 | 19,00 | 19,16 | 19,25 | 19,30 | 19,33 | 19,37 | 19,41 | 19,45 | 19,50 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,84 | 8,74 | 8,64 | 8,53 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,04 | 5,91 | 5,77 | 5,63 |
| 5 | 6,61 | 5,79 | 5,41 | 5, 19 | 5,05 | 4,95 | 4,82 | 4,68 | 4,53 | 4,36 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,15 | 4,00 | 3,84 | 3,67 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,73 | 3,57 | 3,41 | 3,23 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,44 | 3,28 | 3,12 | 2,93 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,23 | 3,07 | 2,90 | 2,71 |
| 10 | 4,96 | 4,10 | 3,71 | 3,48 | 3,33 | 3,22 | 3,07 | 2,91 | 2,74 | 2,54 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3, 20 | 2,95 | 2,79 | 2,61 | 2,40 |
Keď m = 1, vyberte 1 stĺpec.
k 2 = n-m = 7 - 1 = 6 - t.j. 6. riadok - vezmite hodnotu Fisherovej tabuľky
F tab = 5,99, porov. = celkom: 7
Vplyv x na y je mierny a negatívny
ŷ - hodnota modelu.
| F calc. = | 28,648: 1 | = 0,92 |
| 200,50: 5 |
A = 1/7 * 398,15 * 100 % = 8,1 %< 10% -
prijateľná hodnota
Model je dostatočne presný.
F calc. = 1/0,92 = 1,6
F calc. = 1,6< F табл. = 5,99
Mala by byť F calc. > karta F
Porušené tento model, preto táto rovnica nie je štatisticky významná.
Keďže vypočítaná hodnota je menšia ako tabuľková hodnota, ide o nevýznamný model.
| 1 | Σ | (y - ŷ) | *100% | |
| N | r |
Chyba aproximácie.
A = 1/7 * 0,563494 * 100 % = 8,04991 % 8,0 %
Predpokladáme, že model je presný, ak je priemerná chyba aproximácie menšia ako 10 %.
Parametrická identifikácia páru nie lineárna regresia
Model y = a * x b - výkonová funkcia
Ak chcete použiť známy vzorec, musíte logaritmovať nelineárny model.
log y = log a + b log x
Y = C + b * X - lineárny model.
C = 1,7605 - (- 0,298) * 1,7370 = 2,278
Návrat k pôvodnému modelu
Ŷ = 10 s * x b = 10 2,278 * x -0,298
| N / a | Mať | X | Y | X | Y * X | Mať | I (y-ŷ) / yI | |
| 1 | 68,80 | 45,10 | 1,8376 | 1,6542 | 3,039758 | 2,736378 | 60,9614643 | 0,113932 |
| 2 | 61, 20 | 59,00 | 1,7868 | 1,7709 | 3,164244 | 3,136087 | 56,2711901 | 0,080536 |
| 3 | 59,90 | 57, 20 | 1,7774 | 1,7574 | 3,123603 | 3,088455 | 56,7931534 | 0,051867 |
| 4 | 56,70 | 61,80 | 1,7536 | 1,7910 | 3,140698 | 3, 207681 | 55,4990353 | 0,021181 |
| 5 | 55,00 | 58,80 | 1,7404 | 1,7694 | 3,079464 | 3,130776 | 56,3281590 | 0,024148 |
| 6 | 54,30 | 47, 20 | 1,7348 | 1,6739 | 2,903882 | 2,801941 | 60,1402577 | 0,107555 |
| 7 | 49,30 | 55, 20 | 1,6928 | 1,7419 | 2,948688 | 3,034216 | 57,3987130 | 0,164274 |
| Celkom | 405, 20 | 384,30 | 12,3234 | 12,1587 | 21,40034 | 21,13553 | 403,391973 | 0,563493 |
| Priemerná | 57,88571 | 54,90 | 1,760486 | 1,736957 | 3,057191 | 3,019362 | 57,62742 | 0,080499 |
EXCEL vstúpime cez program "Štart". Údaje zapíšeme do tabuľky. V časti "Služba" - "Analýza údajov" - "Regresia" - OK
Ak v ponuke "Služba" chýba riadok "Analýza údajov", musíte ho nainštalovať cez "Služba" - "Nastavenia" - "Balík analýzy údajov"
Predpovedanie dopytu po produktoch spoločnosti. Pomocou funkcie "Trend" v MS Excel
A je dopyt po produkte. B - čas, dni
| P / p č. | A | |
| 1 | 11 | 1 |
| 2 | 14 | 2 |
| 3 | 13 | 3 |
| 4 | 15 | 4 |
| 5 | 17 | 5 |
| 6 | 17,9 | |
| 7 | 18,4 | 7 |
Krok 1. Príprava počiatočných údajov
Krok 2. Predĺžte časovú os, nastavte ju dopredu o 6,7; máme právo predpovedať 1/3 údajov.
Krok 3. Vyberte rozsah A6: A7 pod budúca prognóza.
Krok 4. Vložiť funkciu
Vložiť vlastné hladké grafy
rozsah je pripravený.

Ak sa každá nasledujúca hodnota našej časovej osi nebude líšiť o niekoľko percent, ale niekoľkokrát, potom musíte použiť nie funkciu "Trend", ale funkciu "Growth".
Bibliografia
1. Eliseeva "Ekonometria"
2. Eliseeva „Workshop o ekonometrii“
3. Carlsberg "Excel pre účely analýzy"
Aplikácia
| ZÁVERY VÝSLEDKOV | ||||||||
| Štatistiky registrácie | ||||||||
| Viacnásobné R | 0,947541801 | |||||||
| R-štvorec | 0,897835464 | |||||||
| Normalizovaný R-štvorec | 0,829725774 | |||||||
| Štandardná chyba | 0,226013867 | |||||||
| Pozorovania | 6 | |||||||
| ANOVA | ||||||||
| Význam F | ||||||||
| Regresia | 2 | 1,346753196 | 0,673376598 | 13,18219855 | 0,032655042 | |||
| Zvyšok | 3 | 0,153246804 | 0,051082268 | |||||
| Celkom | 5 | 1,5 | ||||||
| Šance | Štandardná chyba | t-štatistika | P-hodnota | Spodných 95 % | 95 % najlepších | Spodných 95 % | 95 % najlepších |
|
| Priesečník Y | 4,736816539 | 0,651468195 | 7,27098664 | 0,005368842 | 2,66355399 | 6,810079088 | 2,66355399 | 6,810079088 |
| Premenná X1 | 0,333424008 | 0,220082134 | 1,51499807 | 0,227014505 | -0,366975566 | 1,033823582 | -0,366975566 | |





zapnuté tento príklad Uvažujme, ako sa odhaduje spoľahlivosť získanej regresnej rovnice. Rovnaký test sa používa na testovanie hypotézy, že regresné koeficienty sú súčasne rovné nule, a = 0, b = 0. Inými slovami, podstatou výpočtov je odpovedať na otázku: možno ich použiť na ďalšie analýzy a prognózy?
Použite tento t-test na určenie podobnosti alebo rozdielu v rozptyloch v dvoch vzorkách.
Účelom analýzy je teda získať nejaký odhad, pomocou ktorého by bolo možné tvrdiť, že pre určitú úroveň α je získaná regresná rovnica štatisticky spoľahlivá. Pre to používa sa koeficient determinácie R 2.
Kontrola významnosti regresného modelu sa uskutočňuje pomocou Fisherovho F-testu, ktorého vypočítanú hodnotu zistíme ako pomer rozptylu počiatočnej série pozorovaní študovaného ukazovateľa a nezaujatého odhadu rozptylu reziduálneho ukazovateľa. poradie pre tento model.
Ak je vypočítaná hodnota s k 1 = (m) ak 2 = (n-m-1) stupňami voľnosti väčšia ako tabuľková hodnota pre danú hladinu významnosti, potom sa model považuje za významný.
kde m je počet faktorov v modeli.
stupňa štatistická významnosť párová lineárna regresia sa vykonáva podľa nasledujúceho algoritmu:
1. Vysúva sa nulová hypotézaže rovnica ako celok je štatisticky nevýznamná: H 0: R 2 = 0 na hladine významnosti α.
2. Ďalej sa určí skutočná hodnota F-kritéria: ![]()
![]()
kde m = 1 pre párovú regresiu.
3. Tabuľková hodnota je určená z Fisherových distribučných tabuliek pre danej úrovni význam, berúc do úvahy, že počet stupňov voľnosti pre celková sumaštvorcov (väčší rozptyl) je 1 a počet stupňov voľnosti reziduálneho súčtu štvorcov (menší rozptyl) pre lineárnu regresiu je n-2 (alebo cez Funkcia Excel FDISP (pravdepodobnosť; 1; n-2)).
F tabuľka je maximálna možná hodnota kritéria pod vplyvom náhodných faktorov pre dané stupne voľnosti a hladinu významnosti α. Úroveň významnosti α je pravdepodobnosť zamietnutia správnej hypotézy za predpokladu, že je správna. Zvyčajne sa α rovná 0,05 alebo 0,01.
4. Ak je skutočná hodnota F-kritéria menšia ako tabuľková, potom hovoria, že nie je dôvod zamietnuť nulovú hypotézu.
V opačnom prípade sa nulová hypotéza zamietne a prijme sa alternatívna hypotéza o štatistickej významnosti rovnice ako celku s pravdepodobnosťou (1-α).
Tabuľková hodnota kritéria so stupňami voľnosti k 1 = 1 ak 2 = 48, F tab = 4
závery: Keďže skutočná hodnota F> F tabuľka, koeficient determinácie je štatisticky významný ( zistený odhad regresnej rovnice je štatisticky spoľahlivý) .
ANOVA
.Indikátory kvality regresnej rovnice
Príklad. Pre súhrn 25 obchodných podnikov sa skúma vzťah medzi vlastnosťami: X - cena produktu A, tisíc rubľov; Y - zisk obchodný podnik, miliónov rubľov Pri hodnotení regresný model boli získané nasledujúce medzivýsledky: ∑ (yi-yx)2 = 46000; ∑ (y i -y avg) 2 = 138000. Aký je korelačný index, ktorý možno z týchto údajov určiť? Vypočítajte hodnotu tohto ukazovateľa na základe tohto výsledku a pomocou Fisherov F test urobte záver o kvalite regresného modelu.
Riešenie. Na základe týchto údajov môžete určiť empirický korelačný pomer:  , kde ∑ (y av -y x) 2 = ∑ (y i -y av) 2 - ∑ (y i -y x) 2 = 138 000 - 46 000 = 92 000.
, kde ∑ (y av -y x) 2 = ∑ (y i -y av) 2 - ∑ (y i -y x) 2 = 138 000 - 46 000 = 92 000.
η 2 = 92 000/138 000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
Fisherov F test n = 25, m = 1.
R2 = 1 – 46 000/138 000 = 0,67, F = 0,67 / (1 – 0,67) x (25 – 1 – 1) = 46. F tab (1; 23) = 4,27
Keďže skutočná hodnota F> Ftabl, nájdený odhad regresnej rovnice je štatisticky spoľahlivý.
Otázka: Aké štatistiky sa používajú na testovanie významnosti regresného modelu?
Odpoveď: Pre významnosť celého modelu ako celku sa používa F-štatistika (Fisherov test).
Vymenovanie. Testovanie hypotézy, že dva rozptyly patria k tej istej všeobecnej populácii, a teda ich rovnosť.
Nulová hypotéza. S22 = S12
Alternatívna hypotéza... existuje nasledujúce možnosti HA v závislosti od toho, ktoré kritické oblasti sa líšia:
1.S12> S22. Najčastejšie používaný variant HA. Kritická oblasť je horná časť F-distribúcie.
2.S 1 2< S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. Obojstranné S 1 2 ≠ S 2 2. Kombinácia prvých dvoch.
Predpoklady.Údaje sú nezávislé a distribuované podľa bežného zákona. Hypotéza o rovnosti rozptylov dvoch normálnych všeobecných populácií je prijatá, ak je pomer väčšieho rozptylu k menšiemu menší kritický Fisherova distribúcia.
FP = S12 / S22
Poznámka. Pri opísanej testovacej metóde musí byť hodnota Fpacc nevyhnutne väčšia ako jedna. Kritérium je citlivé na porušenie predpokladu normality.
Pre obojstrannú alternatívu S 1 2 ≠ S 2 2 je akceptovaná nulová hypotéza, ak je splnená podmienka:
F l - α / 2< Fрасч < F α /2
Príklad
Termofyzikálne boli stanovené komplexnou termometrickou metódou. charakteristiky (TFH) zeleného sladu. Na prípravu vzoriek sme odobrali na vzduchu suchý (priemerná vlhkosť W = 19 %) a vlhký štvordňový slad (W = 45 %) v súlade s Nová technológia výroba karamelového sladu. Experimenty ukázali, že tepelná vodivosť λ vlhkého sladu je asi 2,5-krát vyššia ako tepelná vodivosť suchého sladu a objemová tepelná kapacita jednoznačne nezávisí od obsahu vlhkosti sladu. Preto sme pomocou F-kritéria overili možnosť sumarizácie údajov o priemerných hodnotách bez zohľadnenia vlhkosti.
Vypočítané údaje sú zhrnuté v tabuľke 5.1.
Tabuľka 5.1
Údaje pre výpočet F-kritéria
Väčšia hodnota rozptylu bola získaná pre W = 45 %, t.j. S245 = S12, S219 = S22 a FP = S12/S22 = 1,35. Z tabuľky 5.2 pre stupeň voľnosti f 1 = N 1 -1 = 5 f 2 = N 2 -1 = 4 pri γ = 0,95 určíme F KP = 6,2. Nulová hypotéza formulovaná ako „V rozsahu vlhkosti zeleného sladu od 19 do 45 % možno jeho vplyv na objemovú tepelnú kapacitu zanedbať“ alebo „S 2 45 = S 2 19“ s hladinou spoľahlivosti 95 %. potvrdené, keďže Fp Príklad testovania hypotézy, že dva rozptyly patria do rovnakej všeobecnej populácie podľa Fisherovho testu pomocou Excelu Uvádzajú sa údaje o dvoch nezávislých vzorkách (tabuľka 5.2) stupňa absorpcie vody zrna pšenice Bola vykonaná štúdia vplyvu nízkofrekvenčných magnetických polí. Tabuľka 5.2 Výsledky výskumu Predtým, než otestujeme hypotézu o rovnosti priemerov týchto vzoriek, je potrebné otestovať hypotézu o rovnosti rozptylov, aby sme vedeli, ktoré z kritérií zvoliť na testovanie. Na obr. 5.1 je príkladom testovania hypotézy, že dve odchýlky patria do rovnakej všeobecnej populácie podľa Fisherovho kritéria pomocou softvérového produktu Microsoft Excel. Obrázok 5.1 Príklad kontroly príslušnosti dvoch rozptylov tej istej všeobecnej populácie podľa Fisherovho kritéria Pôvodné údaje sa nachádzajú v bunkách umiestnených na priesečníku stĺpcov C a D s riadkami 3-10. Urobme nasledovné. 1. Určite, či distribučný zákon prvej a druhej vzorky možno považovať za normálny (stĺpce C a D). Ak nie (aspoň pre jednu vzorku), tak je potrebné použiť neparametrický test, ak áno, pokračujeme. 2. Vypočítajme rozptyly pre prvý a druhý stĺpec. Aby sme to dosiahli, do buniek SP a D11 vložíme funkcie = VAR (SZ: C10) a = VAR (DZ: D10). Výsledkom týchto funkcií je vypočítaná hodnota rozptylu pre každý stĺpec, resp. 3. Nájdite vypočítanú hodnotu pre Fisherovo kritérium. Ak to chcete urobiť, vydeľte väčší rozptyl menším. Do bunky F13 vložíme vzorec = C11 / D11, ktorý vykoná túto operáciu. 4. Určte, či je možné prijať hypotézu o rovnosti rozptylov. V príklade sú uvedené dva spôsoby. Podľa prvej metódy, po nastavení hladiny významnosti napríklad 0,05, sa pre túto hodnotu a zodpovedajúci počet stupňov voľnosti vypočíta kritická hodnota Fisherovho rozdelenia. Do bunky F14 zadajte funkciu = FPACPOBP (0,05; 7; 7) (kde 0,05 je špecifikovaná hladina významnosti; 7 je počet stupňov voľnosti čitateľa a 7 (sekunda) je počet stupňov voľnosti menovateľ). Počet stupňov voľnosti sa rovná počtu pokusov mínus jeden. Výsledok je 3,787051. Keďže táto hodnota je väčšia ako vypočítaných 1,81144, musíme akceptovať nulovú hypotézu o rovnosti rozptylov. Podľa druhej možnosti sa pre získanú vypočítanú hodnotu Fisherovho kritéria vypočíta zodpovedajúca pravdepodobnosť. Ak to chcete urobiť, zadajte do bunky F15 funkciu = FPACP (F13; 7; 7). Keďže získaná hodnota 0,22566 je väčšia ako 0,05, hypotéza o rovnosti rozptylov je prijatá. To je možné vykonať pomocou špeciálnej funkcie. Postupne vyberte položky z ponuky servis
, Analýza dát
... Zobrazí sa okno s nasledovným formulárom (obr. 5.2). Obrázok 5.2 Okno výberu metódy spracovania V tomto okne vyberte „ Dvojvzorkový F-mecm pre disperzie
". Výsledkom je okno vo forme znázornenej na obr. 5.3. Tu nastavíte intervaly (čísla buniek) prvej a druhej premennej, hladinu významnosti (alfa) a miesto, kde sa bude nachádzať výsledok. Zadajte všetky potrebné parametre a kliknite na tlačidlo OK. Výsledok práce je znázornený na obr. 5.4 Treba poznamenať, že funkcia kontroluje jednosmerné kritérium a robí ho správne. V prípade, že je hodnota kritéria väčšia ako 1, vypočíta sa horná kritická hodnota. Obrázok 5.3 Okno nastavenia parametrov Ak je hodnota kritéria menšia ako 1, vypočíta sa nižšia kritická hodnota. Pripomíname, že hypotéza o rovnosti rozptylov sa zamieta, ak je hodnota kritéria väčšia ako horná kritická hodnota alebo menšia ako dolná. Obrázok 5.4 Kontrola rovnosti rozptylov Funkcia FISHER vracia Fisherovu transformáciu pre X argumenty. Táto transformácia vytvára funkciu, ktorá má normálne rozdelenie, nie zošikmené. Funkcia FISHER slúži na testovanie hypotézy pomocou korelačného koeficientu. Pri práci s touto funkciou je potrebné nastaviť hodnotu premennej. Hneď je potrebné poznamenať, že existujú situácie, v ktorých táto funkcia neprinesie výsledky. Je to možné, ak premenná: Rovnica, ktorá sa používa na matematický opis funkcie FISHER, je: Z "= 1/2 * ln (1 + x) / (1-x) Uvažujme o použití tejto funkcie na 3 konkrétnych príkladoch. Príklad 1. Pomocou údajov o činnosti komerčných organizácií je potrebné posúdiť vzťah medzi ziskom Y (mil. rubľov) a nákladmi X (mil. rubľov) použitými na vývoj produktu (uvedené v tabuľke 1). Tabuľka 1 – Počiatočné údaje: Schéma riešenia takýchto problémov je nasledovná: Výsledky riešenia tohto problému pomocou funkcií používaných v balíku Excel sú znázornené na obrázku 1. Obrázok 1 - Príklad výpočtov. S pravdepodobnosťou 0,95 teda lineárny korelačný koeficient leží v rozmedzí od (–0,386) do (–0,990) so štandardnou chybou 0,205. Príklad 2. Skontrolujte štatistickú významnosť viacnásobnej regresnej rovnice pomocou Fisherovho F-testu a vyvodte závery. Na testovanie významnosti rovnice ako celku predkladáme hypotézu H 0 o štatistickej nevýznamnosti koeficientu determinácie a opačnú hypotézu H 1 o štatistickej významnosti koeficientu determinácie: H1: R2 ≠ 0. Otestujme hypotézy pomocou Fisherovho F-testu. Indikátory sú uvedené v tabuľke 2. Tabuľka 2 - Počiatočné údaje Na to používame funkciu v balíku Excel: FDESIGN (α; p; n-p-1) Keď vieme, že α = 0,05, p = 2 an = 53, dostaneme nasledujúcu hodnotu pre F krit (pozri obrázok 2). Obrázok 2 - Príklad výpočtov. Môžeme teda povedať, že F vypočíta > F krit. Výsledkom je prijatie hypotézy H 1 o štatistickej významnosti koeficientu determinácie. Príklad 3. Použitie údajov od 23 podnikov o: X - cena produktu A, tisíc rubľov; Y je zisk komerčného podniku, milióny rubľov, vykonáva sa štúdia ich závislosti. Vyhodnotenie regresného modelu poskytlo nasledovné: ∑ (yi-yx) 2 = 50 000; ∑ (yi-yav) 2 = 130 000. Aký je korelačný index, ktorý možno z týchto údajov určiť? Vypočítajte hodnotu korelačného indexu a pomocou Fisherovho kritéria vyvodte záver o kvalite regresného modelu. Určte F krit z výrazu: F vypočítané = R2/23* (1-R2) kde R je koeficient determinácie rovný 0,67. Odhadovaná hodnota F calc = 46. Na určenie F crit používame Fisherovo rozdelenie (pozri obrázok 3). Obrázok 3 - Príklad výpočtov. Získaný odhad regresnej rovnice je teda spoľahlivý. Vráti inverznú hodnotu (pravostranného) F rozdelenia pravdepodobnosti. Ak p = FDIST (x, ...), potom FDIST (p; ...) = x. F-distribúciu možno použiť v F-teste, ktorý porovnáva rozptyl dvoch súborov údajov. Môžete napríklad analyzovať rozdelenie príjmov v Spojených štátoch a Kanade, aby ste zistili, či sú tieto dve krajiny podobné z hľadiska hustoty príjmu. Dôležité: Táto funkcia bola nahradená jednou alebo viacerými novými funkciami, ktoré poskytujú vyššiu presnosť a lepšie názvy pre svoj účel. Aj keď sa táto funkcia stále používa pre spätnú kompatibilitu, nemusí byť dostupná v budúcich verziách Excelu, preto odporúčame používať nové funkcie. Ďalšie informácie o nových funkciách nájdete v časti Funkcia F.INV a Funkcia F.INV.PX. FREV (pravdepodobnosť, stupne_voľnosti1, stupne_voľnosti2) Argumenty pre funkciu FREVERZIA sú popísané nižšie. Pravdepodobnosť- požadovaný argument. Pravdepodobnosť spojená s kumulatívnou F-distribúciou. Stupne_slobody1- požadovaný argument. Čitateľ stupňov voľnosti. Stupne_slobody2- požadovaný argument. Menovateľ stupňov voľnosti. Ak niektorý z argumentov nie je číselný, FROMINV vráti chybovú hodnotu #HODNOTA!. Ak "pravdepodobnosť"< 0 или "вероятность" >1, FROMINV vráti chybovú hodnotu #NUM!. Ak hodnota „stupeň_slobody1“ alebo „stupeň_slobody2“ nie je celé číslo, bude skrátená. Ak "stupeň_slobody1"< 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. Ak "stupeň_slobody2"< 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. Funkciu FREVERZIA je možné použiť na určenie kritických hodnôt rozdelenia F. Napríklad výsledky ANOVA zvyčajne zahŕňajú údaje pre F štatistiku, F pravdepodobnosti a kritickú hodnotu F distribúcie s hladinou významnosti 0,05. Ak chcete určiť kritickú hodnotu F, musíte použiť hladinu významnosti ako argument pravdepodobnosti funkcie FREVERZIA. Pri danej hodnote pravdepodobnosti funkcia FDIST hľadá hodnotu x, pre ktorú FDIST (x; stupne_voľnosti1; stupne_voľnosti2) = pravdepodobnosť. Presnosť FDIST teda závisí od presnosti FDIST. Funkcia FRONST používa na vyhľadávanie metódu iterácie. Ak sa vyhľadávanie neskončilo po 100 opakovaniach, vráti sa chybová hodnota # N / A. Skopírujte vzorové údaje z nasledujúcej tabuľky a prilepte ich do bunky A1 nového hárka programu Excel. Ak chcete zobraziť výsledky vzorcov, vyberte ich a stlačte kláves F2 a potom stlačte kláves Enter. Zmeňte šírku stĺpcov podľa potreby, aby ste videli všetky údaje.číslo Číslo vzorky
skúsenosti
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075




Ako funguje funkcia FISHER v Exceli
Vyhodnotenie vzťahu medzi ziskom a nákladmi funkciou FISHER
№
X Y
1
210 000 000,00 ₽ 95 000 000,00 ₽
2
1 068 000 000,00 RUB 76 000 000,00 ₽
3
1 005 000 000,00 ₽ 78 000 000,00 ₽
4
610 000 000,00 ₽ 89 000 000,00 ₽
5
768 000 000,00 ₽ 77 000 000,00 ₽
6
799 000 000,00 ₽ 85 000 000,00 RUB
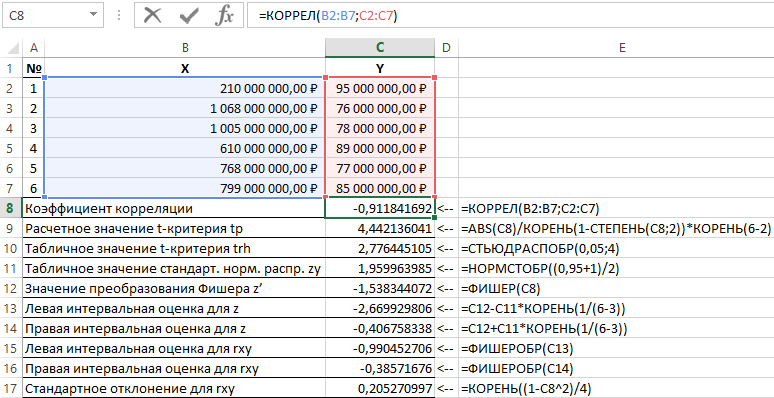
P / p č. Názov indikátora Výpočtový vzorec
1
Korelačný koeficient = CORREL (B2: B7; C2: C7)
2
Vypočítaná hodnota t-testu tp = ABS (C8) / ROOT (1-DEGREE (C8,2)) * ROOT (6-2)
3
Tabuľková hodnota t-testu trh = TYUDRASP (0,05,4)
4
Tabuľková hodnota štandardného normálneho rozdelenia zy = NORMSINV ((0,95 + 1) / 2)
5
Hodnota Fischerovej transformácie z ' = FISHER (C8)
6
Odhad ľavého intervalu pre z = C12-C11 * KOREŇ (1 / (6-3))
7
Pravý odhad intervalu pre z = C12 + C11 * KOREŇ (1 / (6-3))
8
Odhad ľavého intervalu pre rxy = FISHEROBER (C13)
9
Pravý odhad intervalu pre rxy = FISHEROBER (C14)
10
Smerodajná odchýlka pre rxy = ROOT ((1-C8 ^ 2) / 4)
Kontrola štatistickej významnosti regresie pomocou funkcie FRASPINV
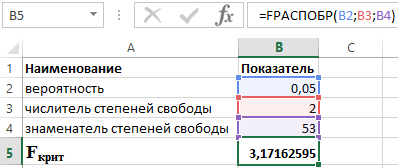
Výpočet hodnoty korelačného indexu v Exceli

Syntax
Poznámky
Príklad








")

Hodnota avatarov v psychológii
Hodnota avatarov v psychológii
Ako zdôrazniť písmeno v MS Word
Čo to znamená, ak je avatar osoby
Ako si vytvoriť svoj vlastný Twitter moment