Podľa mňa ako študenta je ekonometria jednou z najaplikovanejších vied zo všetkých, s ktorými som sa stihol zoznámiť v rámci múrov mojej univerzity. S jeho pomocou je skutočne možné riešiť problémy aplikovaného charakteru v meradle podniku. Ako efektívne budú tieto riešenia, je tretia otázka. Pointa je, že väčšina vedomostí zostane teóriou, ale ekonometria a regresná analýza sa stále oplatí študovať s osobitnou pozornosťou.
Čo vysvetľuje regresia?
Skôr ako začneme skúmať funkcie MS Excel, ktoré umožňujú riešenie týchto problémov, rád by som vám na prstoch vysvetlil, čo v podstate znamená regresná analýza. Uľahčí vám to zvládnutie skúšky a hlavne bude zaujímavejšie študovať predmet.
Dúfajme, že ste oboznámení s konceptom funkcie z matematiky. Funkcia je vzťah medzi dvoma premennými. Keď sa zmení jedna premenná, niečo sa stane s druhou. Zmeníme X a Y sa tiež zmení, resp. Funkcie popisujú rôzne zákony. Keď poznáme funkciu, môžeme nahradiť ľubovoľné hodnoty za X a pozrieť sa, ako to zmení Y.
Je to veľmi dôležité, keďže regresia je pokus o vysvetlenie zdanlivo nesystematických a chaotických procesov pomocou určitej funkcie. Takže je napríklad možné identifikovať vzťah medzi kurzom dolára a nezamestnanosťou v Rusku.
Ak sa tento vzor podarí zistiť, potom pomocou funkcie, ktorú sme získali v priebehu výpočtov, budeme schopní urobiť predpoveď, aká bude miera nezamestnanosti pri N-tom výmennom kurze dolára voči rubľu.
Tento vzťah sa bude nazývať korelácia. Regresná analýza zahŕňa výpočet korelačného koeficientu, ktorý vysvetlí tesnosť vzťahu medzi premennými, ktoré zvažujeme (výmenný kurz dolára a počet pracovných miest).
Tento pomer môže byť kladný alebo záporný. Jeho hodnoty sa pohybujú od -1 do 1. Podľa toho môžeme pozorovať vysokú negatívnu alebo pozitívnu koreláciu. Ak bude pozitívny, potom po zvýšení kurzu dolára bude nasledovať vznik nových pracovných miest. Ak je záporná, znamená to, že po zvýšení výmenného kurzu bude nasledovať pokles pracovných miest.
Existuje niekoľko typov regresie. Môže byť lineárny, parabolický, exponenciálny atď. Vyberáme model podľa toho, ktorá regresia bude konkrétne zodpovedať nášmu prípadu, ktorý model sa bude čo najviac približovať našej korelácii. Uvažujme to na príklade problému a vyriešme ho v MS Excel.
Lineárna regresia v MS Excel
Na vyriešenie problémov lineárnej regresie budete potrebovať funkciu Analýza údajov. Nemusí byť pre vás povolená, takže ju musíte aktivovať.
- Kliknite na tlačidlo "Súbor";
- Vyberieme položku "Parametre";
- Kliknite na predposlednú kartu „Doplnky“ na ľavej strane;

- Nižšie uvidíme nápis „Control“ a tlačidlo „Go“. Tlačíme na to;
- Začiarkneme políčko "Analýza";
- Stlačíme "ok".

Príklad úlohy
Funkcia analýzy šarží je aktivovaná. Poďme vyriešiť nasledujúci problém. Máme vzorku údajov za niekoľko rokov o počte mimoriadnych situácií na území podniku a počte zamestnaných pracovníkov. Musíme identifikovať vzťah medzi týmito dvoma premennými. Existuje vysvetľujúca premenná X - to je počet pracovníkov a vysvetlená premenná - Y - je počet nehôd. Rozdeľme počiatočné údaje do dvoch stĺpcov.
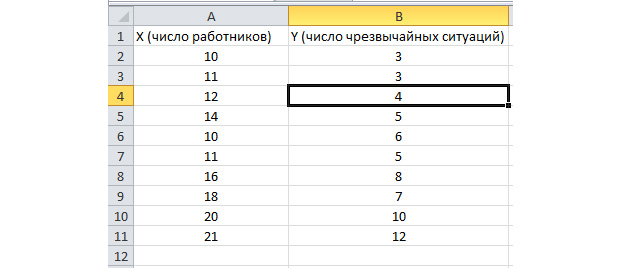
Poďme na kartu "údaje" a vyberte "Analýza údajov"
V zobrazenom zozname vyberte možnosť „Regresia“. Vo vstupných intervaloch Y a X vyberte príslušné hodnoty.
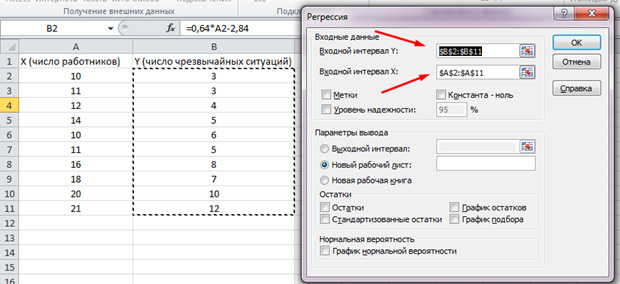
Kliknite na „OK“. Analýza bola vykonaná a výsledky uvidíme v novom hárku.
Pre nás najvýznamnejšie hodnoty sú vyznačené na obrázku nižšie.
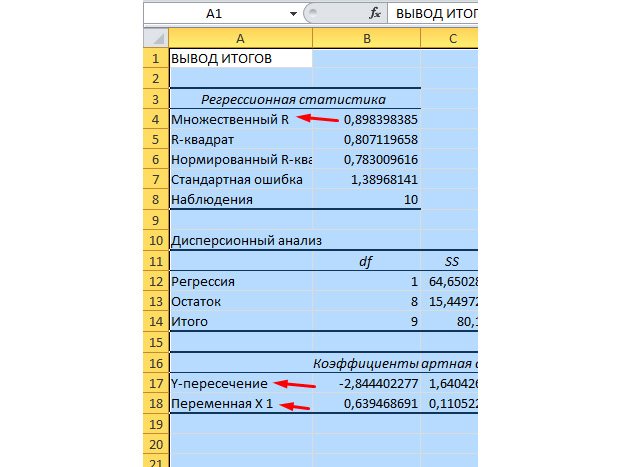
Násobok R je koeficient determinácie. Má zložitý vzorec výpočtu a ukazuje, do akej miery môžete dôverovať nášmu korelačnému koeficientu. Čím väčšia je teda táto hodnota, tým väčšia dôvera, tým úspešnejší je náš model ako celok.
Priesečník Y a priesečník X1 sú koeficienty našej regresie. Ako už bolo spomenuté, regresia je funkcia a má určité koeficienty. Naša funkcia teda bude vyzerať takto: Y = 0,64 * X-2,84.
čo nám to dáva? To nám umožňuje urobiť predpoveď. Povedzme, že chceme prijať 25 pracovníkov do firmy a potrebujeme si zhruba predstaviť, aký bude počet nehôd. Túto hodnotu dosadíme do našej funkcie a dostaneme výsledok Y = 0,64 * 25 - 2,84. U nás vznikne približne 13 mimoriadnych situácií.
Pozrime sa, ako to funguje. Pozrite sa na obrázok nižšie. Funkcia, ktorú sme získali, je nahradená skutočnými hodnotami pre zúčastnených zamestnancov. Pozrite sa, ako blízko sú hodnoty skutočným hrám.

Môžete tiež vytvoriť korelačné pole zvýraznením oblasti hráčov a xs, kliknutím na kartu „vložiť“ a výberom bodového grafu.

Bodky sú roztrúsené, ale vo všeobecnosti sa pohybujú nahor, akoby v strede v priamke. Tento riadok môžete pridať aj tak, že prejdete na kartu „Rozloženie“ v programe MS Excel a vyberiete položku „Trendová čiara“
Dvakrát kliknite na riadok, ktorý sa zobrazí, a uvidíte, čo bolo spomenuté vyššie. Typ regresie môžete zmeniť v závislosti od toho, ako vyzerá vaše korelačné pole.
Možno máte pocit, že body vykresľujú parabolu, nie priamku, a je pre vás vhodnejšie zvoliť si iný typ regresie.

Záver
Dúfajme, že tento článok vám dal lepšie pochopenie toho, čo je regresná analýza a na čo slúži. To všetko má veľký praktický význam.
Štatistické spracovanie údajov je možné vykonávať aj pomocou doplnku BALÍK ANALÝZY(obr. 62).
Z navrhnutých položiek si vyberie položku " REGRESIA„A kliknite naň ľavým tlačidlom myši. Potom kliknite na tlačidlo OK.
Okno znázornené na obr. 63.

analytický nástroj " REGRESIA»Používa sa na zostavenie grafu pre súbor pozorovaní pomocou metódy najmenších štvorcov. Regresia sa používa na analýzu vplyvu hodnôt jednej alebo viacerých vysvetľujúcich premenných na individuálnu závislú premennú. Napríklad športový výkon športovca ovplyvňuje niekoľko faktorov vrátane veku, výšky a hmotnosti. Môžete vypočítať vplyv každého z týchto troch faktorov na výkon športovca a potom tieto údaje použiť na predpovedanie výkonu iného športovca.
Funkciu používa nástroj Regresia LINEST.
Dialógové okno REGRESIA
Štítky Začiarknite políčko, ak prvý riadok alebo prvý stĺpec vstupného rozsahu obsahuje hlavičky. Zrušte začiarknutie tohto políčka, ak neexistujú žiadne tituly. V tomto prípade sa príslušné hlavičky pre údaje výstupnej tabuľky vygenerujú automaticky.
Úroveň spoľahlivosti Označte začiarkavacie políčko, ak chcete do tabuľky súčtov výstupov zahrnúť ďalšiu úroveň. Do príslušného poľa zadajte úroveň spoľahlivosti, ktorú chcete použiť, okrem predvolenej úrovne 95 %.
Konštantná - nula Označte začiarkavacie políčko, aby regresná čiara prechádzala počiatkom.
Output Spacing Zadajte odkaz na ľavú hornú bunku výstupného rozsahu. Prideľte aspoň sedem stĺpcov pre výstupnú tabuľku súčtov, ktorá bude obsahovať: výsledky ANOVA, koeficienty, štandardnú chybu výpočtu Y, štandardné odchýlky, počet pozorovaní, štandardné chyby pre koeficienty.
Nový pracovný hárok Vyberte tento prepínač, ak chcete otvoriť nový pracovný hárok v zošite a vložiť výsledky analýzy počnúc bunkou A1. V prípade potreby zadajte názov nového hárku do poľa oproti zodpovedajúcej polohe prepínača.
Nový zošit Kliknutím na prepínač do tejto polohy vytvoríte nový zošit, do ktorého sa výsledky pridajú do nového hárka.
Zvyšky Začiarknutím tohto políčka zahrniete zvyšky do výstupnej tabuľky.
Štandardizované rezíduá Začiarknutím tohto políčka zahrniete štandardizované rezíduá do výstupnej tabuľky.
Vykresliť rezíduá Začiarknutím tohto políčka vykreslíte rezíduá pre každú nezávislú premennú.
Fitting plot Začiarknutím tohto políčka zobrazíte graf predpokladaných hodnôt oproti pozorovaným hodnotám.
Graf normálnej pravdepodobnosti Začiarknutím políčka vykreslíte graf normálnej pravdepodobnosti.
Funkcia LINEST
Ak chcete vykonať výpočty, vyberte kurzorom bunku, v ktorej chceme zobraziť priemernú hodnotu a stlačte kláves = na klávesnici. Ďalej v poli Názov uveďte napríklad požadovanú funkciu PRIEMERNÝ(obr. 22).
Funkcia LINEST vypočíta štatistiku pre sériu pomocou najmenších štvorcov na výpočet rovnej čiary, ktorá najlepšie zodpovedá dostupným údajom, a potom vráti pole, ktoré popisuje výslednú priamku. Funkciu môžete aj kombinovať LINEST s ďalšími funkciami na výpočet iných druhov modelov, ktoré sú lineárne v neznámych parametroch (ktorých neznáme parametre sú lineárne), vrátane polynomických, logaritmických, exponenciálnych a mocninových radov. Keďže sa vracia pole hodnôt, funkcia musí byť špecifikovaná ako vzorec poľa.
Rovnica pre priamku je nasledovná:
y = m 1 x 1 + m 2 x 2 +… + b (v prípade niekoľkých rozsahov hodnôt x),
kde závislá hodnota y je funkciou nezávislej hodnoty x, hodnoty m sú koeficienty zodpovedajúce každej nezávislej premennej x a b je konštanta. Všimnite si, že y, x a m môžu byť vektory. Funkcia LINEST vráti pole (mn; mn-1;…; m 1; b). LINEST môže tiež vrátiť ďalšie regresné štatistiky.
LINEST(známe_y; známe_x; konšt.; štatistiky)
Známe_y je množina hodnôt y, ktoré sú už známe pre vzťah y = mx + b.
Ak má pole známe_y jeden stĺpec, potom sa každý stĺpec v poli známe_x interpretuje ako samostatná premenná.
Ak má parameter známe_y jeden riadok, potom sa každý riadok v poli známe_x interpretuje ako samostatná premenná.
Známe_x sú voliteľnou množinou hodnôt x, ktoré sú už známe pre y = mx + b.
Známe_x môžu obsahovať jednu alebo viac sád premenných. Ak sa použije iba jedna premenná, potom známe_y a známe_x môžu mať akýkoľvek tvar, pokiaľ majú rovnaký rozmer. Ak sa použije viac ako jedna premenná, parameter známe_y musí byť vektor (t. j. jeden riadok vysoký alebo jeden stĺpec široký).
Ak pole pole_ známe_x vynecháte, potom sa predpokladá, že toto pole (1; 2; 3; ...) má rovnakú veľkosť ako pole pole_ známe_y.
Const je boolovská hodnota, ktorá udáva, či sa vyžaduje, aby konštanta b bola 0.
Ak je const PRAVDA alebo sa vynechá, konštanta b sa vyhodnotí obvyklým spôsobom.
Ak je argument "const" FALSE, potom je hodnota b nastavená na 0 a hodnoty m sú zvolené tak, aby bol splnený vzťah y = mx.
Štatistika je logická hodnota, ktorá označuje, či chcete vrátiť ďalšie štatistiky pre regresiu.
Ak má štatistika hodnotu TRUE, funkcia LINEST vráti ďalšie regresné štatistiky. Vrátené pole bude vyzerať takto: (mn; mn-1; ...; m1; b: sen; sen-1; ...; se1; seb: r2; sey: F; df: ssreg; ssresid).
Ak je štatistika FALSE alebo je vynechaná, funkcia LINEST vráti iba koeficienty ma konštantu b.
Ďalšie regresné štatistiky (tabuľka 17)
| Veľkosť | Popis |
| se1, se2, ..., sen | Hodnoty štandardnej chyby pre koeficienty m1, m2, ..., mn. |
| seb | Hodnota štandardnej chyby pre konštantu b (seb = # N / A, ak je const FALSE). |
| r2 | Koeficient determinizmu. Skutočné hodnoty y sa porovnávajú s hodnotami získanými z rovnice priamky; na základe výsledkov porovnania sa vypočíta koeficient determinizmu normalizovaný od 0 do 1. Ak sa rovná 1, potom existuje úplná korelácia s modelom, to znamená, že neexistuje rozdiel medzi skutočným a odhadovaným hodnoty y. V opačnom prípade, ak je koeficient determinizmu 0, nemá zmysel používať regresnú rovnicu na predpovedanie hodnôt y. Ďalšie informácie o spôsobe výpočtu r2 nájdete v časti „Poznámky“ na konci tejto časti. |
| sey | Štandardná chyba pre odhad y. |
| F | F-štatistika alebo F-pozorovaná hodnota. F štatistika sa používa na určenie, či je pozorovaný vzťah medzi závislými a nezávislými premennými náhodný. |
| df | Stupne slobody. Stupne voľnosti sú užitočné pri hľadaní F-kritických hodnôt v štatistickej tabuľke. Ak chcete určiť úroveň spoľahlivosti modelu, porovnajte hodnoty v tabuľke s F-štatistikou vrátenou LINREGRESOM. Ďalšie informácie o výpočte df nájdete v poznámkach na konci tejto časti. Príklad 4 nižšie ukazuje použitie hodnôt F a df. |
| ssreg | Regresný súčet štvorcov. |
| ssresid | Zvyškový súčet štvorcov. Ďalšie informácie o výpočte hodnôt ssreg a ssresid nájdete v časti Poznámky na konci tejto časti. |
Obrázok nižšie ukazuje poradie, v ktorom sa vracajú dodatočné regresné štatistiky (obrázok 64).

Poznámky:
Akákoľvek priamka môže byť opísaná jej sklonom a priesečníkom s osou y:
Sklon (m): na určenie sklonu priamky, zvyčajne označovanej m, musíte zobrať dva body priamky (x 1, y 1) a (x 2, y 2); sklon bude (y 2 -y 1) / (x 2 -x 1).
Priesečník Y (b): Priesečník y úsečky, zvyčajne označovaný písmenom b, je hodnota y bodu, v ktorom priamka pretína os y.
Rovnica s priamkou má tvar y = mx + b. Ak poznáte hodnoty m a b, môžete vypočítať ľubovoľný bod na priamke nahradením hodnôt y alebo x v rovnici. Využiť môžete aj funkciu TREND.
Ak existuje iba jedna nezávislá premenná x, môžete získať sklon a priesečník y priamo pomocou nasledujúcich vzorcov:
Sklon: INDEX (LINEST (známe_y; známe_x); 1)
Priesečník Y: INDEX (LINEST (známe_y; známe_x); 2)
Presnosť aproximácie čiary LINEST závisí od stupňa rozptylu v údajoch. Čím bližšie sú údaje k priamke, tým presnejší je model LINEST. Funkcia LINEST používa metódu najmenších štvorcov na určenie najvhodnejšieho prispôsobenia údajom. Ak existuje iba jedna nezávislá premenná x, m a b sa vypočítajú pomocou nasledujúcich vzorcov:

kde x a y sú vzorové priemery, napríklad x = AVERAGE (známe_x) a y = AVERAGE (známe_y).
Funkcie LINREGRESE a LOGLINREGRESE dokážu vypočítať priamu alebo exponenciálnu krivku, ktorá najlepšie popisuje údaje. Neodpovedajú však na otázku, ktorý z dvoch výsledkov je vhodnejší na riešenie danej úlohy. Môžete tiež vypočítať TREND (známe_y; známe_x) pre priamku alebo GROWTH (známe_y; známe_x) pre exponenciálnu krivku. Ak tieto funkcie nezadáte new_x_values, vrátia pole vypočítaných hodnôt y pre skutočné hodnoty x pozdĺž priamky alebo krivky. Vypočítané hodnoty potom možno porovnať so skutočnými hodnotami. Môžete tiež zostaviť grafy na vizuálne porovnanie.
Pomocou regresnej analýzy Microsoft Excel vypočíta pre každý bod druhú mocninu rozdielu medzi predpokladanou hodnotou y a skutočnou hodnotou y. Súčet týchto štvorcových rozdielov sa nazýva zvyškový súčet druhých mocnín (ssresid). Microsoft Excel potom vypočíta celkový súčet štvorcov (sstotal). Ak const = TRUE alebo vynechané, celkový súčet druhých mocnín sa rovná súčtu druhých mocnín rozdielu medzi skutočnými hodnotami y a priemernými hodnotami y. Keď const = FALSE, celkový súčet druhých mocnín sa bude rovnať súčtu druhých mocnín skutočných hodnôt y (bez odčítania strednej hodnoty y od hodnoty kvocientu y). Regresný súčet štvorcov sa potom môže vypočítať takto: ssreg = sstotal - ssresid. Čím menší je zvyškový súčet štvorcov, tým väčšia je hodnota koeficientu determinizmu r2, ktorý ukazuje, ako dobre rovnica získaná pomocou regresnej analýzy vysvetľuje vzťah medzi premennými. Koeficient r2 je ssreg / sstotal.
V niektorých prípadoch jeden alebo viac stĺpcov X (nech sú hodnoty Y a X v stĺpcoch) nemajú žiadnu ďalšiu predikatívnu hodnotu v ostatných stĺpcoch X. Inými slovami, odstránenie jedného alebo viacerých stĺpcov X môže viesť k hodnotám Y vypočítané s rovnakou presnosťou. V tomto prípade budú z regresného modelu vylúčené nadbytočné X stĺpce. Tento jav sa nazýva "kolinearita", pretože redundantné X stĺpce môžu byť reprezentované ako súčet viacerých neredundantných stĺpcov. LINEST skontroluje kolinearitu a odstráni všetky nadbytočné X stĺpce z regresného modelu, ak ich nájde. Vymazané X stĺpce možno identifikovať vo výstupe funkcie LINREGRESE podľa faktora 0 a hodnoty SE 0. Odstránenie jedného alebo viacerých stĺpcov ako nadbytočných zmení hodnotu df, pretože závisí od počtu X stĺpcov skutočne použitých na prediktívne účely. Ďalšie informácie o výpočte df nájdete nižšie v príklade 4. Keď sa df zmení v dôsledku odstránenia nadbytočných stĺpcov, zmenia sa aj sey a F. Kolinearita sa často neodporúča. Mal by sa však použiť, ak niektoré zo stĺpcov X obsahujú 0 alebo 1 ako indikátor, ktorý označuje, či je subjekt experimentu v samostatnej skupine. Ak const = TRUE alebo vynechané, LINREGRESE vloží ďalší stĺpec X na simuláciu priesečníka. Ak existuje stĺpec s hodnotami 1 pre mužov a 0 pre ženy a existuje aj stĺpec s hodnotami 1 pre ženy a 0 pre mužov, potom sa posledný stĺpec odstráni, pretože jeho hodnoty môžu byť získané zo stĺpca s „ukazovateľom mužského pohlavia“.
Výpočet df pre prípady, keď stĺpce X nie sú z modelu odstránené z dôvodu kolinearity, je nasledujúci: ak existuje k stĺpcov známych_x a hodnota const = TRUE alebo nie je špecifikovaná, potom df = n - k - 1. const = FALSE, potom df = n - k. V oboch prípadoch odstránenie X stĺpcov v dôsledku kolinearity zvýši hodnotu df o 1.
Vzorce, ktoré vracajú polia, musia byť zadané ako vzorce poľa.
Pri zadávaní poľa konštánt, napríklad známych_x, použite bodkočiarku na oddelenie hodnôt na rovnakom riadku a dvojbodku na oddelenie riadkov. Oddeľovacie znaky sa líšia v závislosti od možností nastavených v okne Jazyk a štandardy na ovládacom paneli.
Treba poznamenať, že hodnoty y predpovedané regresnou rovnicou nemusia byť správne, ak sú mimo rozsahu hodnôt y, ktoré boli použité na definovanie rovnice.
Hlavný algoritmus použitý vo funkcii LINEST, sa líši od hlavného algoritmu funkcií INCLINE a ODDIEL... Rozdiely medzi algoritmami môžu viesť k rôznym výsledkom pre nedefinované a kolineárne údaje. Napríklad, ak dátové body známeho_y sú 0 a dátové body známych_x sú 1, potom:
Funkcia LINEST vráti hodnotu rovnajúcu sa 0. Algoritmus funkcie LINEST sa používa na vrátenie platných hodnôt pre kolineárne dáta, v takom prípade je možné nájsť aspoň jednu odpoveď.
Funkcie SLOPE a INTERCEPT vrátia # DIV / 0! Chyba. Algoritmus funkcií SLOPE a INTERCEPT sa používa na vyhľadávanie iba jednej odpovede, v tomto prípade ich môže byť niekoľko.
Okrem výpočtu štatistík pre iné typy regresie možno funkciu LINREGRESE použiť na výpočet rozsahov pre iné typy regresie zadaním funkcií x a y ako radov x a y pre funkciu LINEST. Napríklad nasledujúci vzorec:
LINEST (hodnoty y, hodnoty x ^ COLUMN ($ A: $ C))
funguje tak, že má jeden stĺpec hodnôt Y a jeden stĺpec hodnôt X na výpočet aproximácie ku kocke (polynóm 3. stupňa) nasledujúceho tvaru:
y = m1 x + m2 x 2 + m3 x 3 + b
Vzorec je možné zmeniť na výpočet iných typov regresie, ale v niektorých prípadoch sú potrebné úpravy výstupných hodnôt a iných štatistík.
Regresná analýza je jednou z najžiadanejších metód štatistického výskumu. Môže sa použiť na stanovenie miery vplyvu nezávislých premenných na závislú premennú. Vo funkcionalite Microsoft Excel sú nástroje určené pre tento typ analýzy. Poďme sa pozrieť na to, čo sú a ako ich používať.
Aby ste však mohli použiť funkciu, ktorá vám umožňuje vykonávať regresnú analýzu, musíte najskôr aktivovať analytický balík. Až potom sa na páse s nástrojmi Excelu objavia nástroje potrebné na tento postup.


Teraz, keď prejdeme na kartu "údaje", na páske v skrinke s nástrojmi "analýza" uvidíme nové tlačidlo - "Analýza dát".

Typy regresnej analýzy
Existuje niekoľko typov regresií:
- parabolický;
- mocenské právo;
- logaritmický;
- exponenciálny;
- orientačné;
- hyperbolický;
- lineárna regresia.
Povieme si podrobnejšie o výkone posledného typu regresnej analýzy v Exceli.
Lineárna regresia v Exceli
Nižšie je ako príklad uvedená tabuľka, ktorá ukazuje priemernú dennú teplotu vzduchu vonku a počet kupujúcich v obchodoch pre príslušný pracovný deň. Zistime pomocou regresnej analýzy, ako presne môžu poveternostné podmienky v podobe teploty vzduchu ovplyvniť návštevnosť predajne.
Všeobecná rovnica lineárnej regresie vyzerá takto: Y = a0 + a1x1 +… + akhk. V tomto vzorci Y znamená premennú, vplyv faktorov, ktoré sa snažíme študovať. V našom prípade ide o počet kupujúcich. Význam X Sú rôzne faktory, ktoré ovplyvňujú premennú. možnosti a sú regresné koeficienty. To znamená, že sú to oni, ktorí určujú význam tohto alebo toho faktora. Index k označuje celkový počet rovnakých faktorov.


Analýza výsledkov analýzy
Výsledky regresnej analýzy sa zobrazia vo forme tabuľky na mieste určenom v nastaveniach.

Jedným z hlavných ukazovateľov je R-štvorec... Označuje kvalitu modelu. V našom prípade je tento pomer 0,705 alebo približne 70,5 %. Toto je prijateľná úroveň kvality. Závislosť menšia ako 0,5 je zlá.
Ďalší dôležitý ukazovateľ sa nachádza v bunke na priesečníku riadku. "Priesečník Y" a stĺpec "pravdepodobnosť"... Označuje, akú hodnotu bude mať Y, a v našom prípade je to počet kupujúcich, pričom všetky ostatné faktory sú rovné nule. V tejto tabuľke je táto hodnota 58,04.
Hodnota na priesečníku grafu "Premenná X1" a "pravdepodobnosť" ukazuje úroveň závislosti Y na X. V našom prípade je to úroveň závislosti počtu zákazníkov predajne od teploty. Pomer 1,31 sa považuje za pomerne vysoký ukazovateľ vplyvu.
Ako vidíte, je celkom jednoduché vytvoriť tabuľku regresnej analýzy pomocou programu Microsoft Excel. S dátami získanými na výstupe však môže pracovať a pochopiť ich podstatu len vyškolený človek.
28 okt
Dobré popoludnie, milí čitatelia blogu! Dnes budeme hovoriť o nelineárnych regresiách. Riešenie lineárnych regresií nájdete na ODKAZE.
Táto metóda sa používa najmä v ekonomickom modelovaní a prognózovaní. Jeho účelom je sledovať a identifikovať vzťah medzi týmito dvoma ukazovateľmi.
Hlavné typy nelineárnych regresií sú:
- polynóm (kvadratický, kubický);
- hyperbolický;
- mocenské právo;
- orientačné;
- logaritmický.
Môžu sa použiť aj rôzne kombinácie. Napríklad pre analytikov časových radov v bankovníctve, poisťovníctve a demografických štúdiách sa používa Gompzerova krivka, čo je druh logaritmickej regresie.
Pri prognózovaní pomocou nelineárnych regresií ide predovšetkým o zistenie korelačného koeficientu, ktorý nám ukáže, či medzi dvoma parametrami existuje úzky vzťah alebo nie. Spravidla, ak je korelačný koeficient blízky 1, potom existuje spojenie a predpoveď bude celkom presná. Ďalším dôležitým prvkom nelineárnych regresií je stredná relatívna chyba ( A ), ak je v intervale<8…10%, значит модель достаточно точна.
Týmto možno dokončíme teoretický blok a prejdeme k praktickým výpočtom.
Máme tabuľku predajov áut za interval 15 rokov (označíme X), počet krokov merania bude argument n, za tieto obdobia je aj tržba (označíme Y), treba predpovedať, aké budú výnosy v budúcnosti. Zostavme si nasledujúcu tabuľku:
Pre výskum potrebujeme vyriešiť rovnicu (závislosť Y na X): y = ax 2 + bx + c + e. Toto je párová kvadratická regresia. Aplikujme v tomto prípade metódu najmenších štvorcov, aby sme zistili neznáme argumenty - a, b, c. Povedie to k systému algebraických rovníc v tvare:

Na vyriešenie tohto systému použijeme napríklad Cramerovu metódu. Vidíme, že sumy zahrnuté v systéme sú koeficienty s neznámymi. Pre ich výpočet pridajte do tabuľky niekoľko stĺpcov (D, E, F, G, H) a podpíšte ich podľa významu výpočtov - v stĺpci D odmocníme x, v E v kocke, v F v 4. mocnina, v G vynásobíme exponenty x a y, v H odmocninu x a vynásobíme y.

Dostanete tabuľku formulára vyplnenú potrebnými na riešenie rovnice.


Vytvorme matricu A systém pozostávajúci z koeficientov s neznámymi na ľavej strane rovníc. Umiestnite ho do bunky A22 a nazvite ho „ A =". Postupujeme podľa sústavy rovníc, ktoré sme si zvolili na riešenie regresie.

To znamená, že do bunky B21 musíme umiestniť súčet stĺpca, kde bol exponent X zvýšený na štvrtú mocninu - F17. Pozrime sa len na bunku - "= F17". Ďalej potrebujeme súčet stĺpca, kde bolo X zvýšené na kocku - E17, potom ideme striktne podľa systému. Preto budeme musieť vyplniť celú maticu.
V súlade s Cramerovým algoritmom napíšeme maticu A1, podobnú A, do ktorej by sa namiesto prvkov prvého stĺpca mali umiestniť prvky pravých strán rovníc systému. To znamená, že súčet stĺpca X na druhú krát Y, súčet stĺpca XY a súčet stĺpca Y.

Potrebujeme tiež dve ďalšie matice – nazvime ich A2 a A3, v ktorých druhý a tretí stĺpec budú pozostávať z koeficientov pravých strán rovníc. Obrázok bude takýto.

Podľa zvoleného algoritmu budeme musieť vypočítať hodnoty determinantov (determinanty, D) výsledných matíc. Použime vzorec MOPRED. Výsledky umiestnite do buniek J21: K24.

Výpočet koeficientov rovnice podľa Kramera sa uskutoční v bunkách oproti zodpovedajúcim determinantom podľa vzorca: a(v bunke M22) - "= K22 / K21"; b(v bunke M23) - "= K23 / K21"; s(v bunke M24) - "= K24 / K21".
Získame našu požadovanú párovú kvadratickú regresnú rovnicu:
y = -0,074 x 2 + 2,151 x + 6,523
Odhadnime tesnosť lineárneho spojenia pomocou korelačného indexu.

Pre výpočet pridajte do tabuľky ďalší stĺpec J (nazvime ho y *). Výpočet bude nasledovný (podľa nami získanej regresnej rovnice) - "= $ M $ 22 * B2 * B2 + $ M $ 23 * B2 + $ M $ 24". Umiestnite ho do bunky J2. Zostáva natiahnuť značku automatického dopĺňania nadol do bunky J16.

Na výpočet súčtu (priemer Y-Y) 2 pridajte stĺpce K a L do tabuľky so zodpovedajúcimi vzorcami. Priemer pre stĺpec Y sa vypočíta pomocou funkcie AVERAGE.

Do bunky K25 umiestnite vzorec na výpočet korelačného indexu - "= ROOT (1- (K17 / L17)".

Vidíme, že hodnota 0,959 je veľmi blízka 1, čo znamená, že medzi predajom a rokmi existuje úzky nelineárny vzťah.
Zostáva zhodnotiť kvalitu prispôsobenia získanej kvadratickej regresnej rovnice (index determinácie). Vypočíta sa pomocou vzorca druhej mocniny indexu korelácie. To znamená, že vzorec v bunke K26 bude veľmi jednoduchý - "= K25 * K25".

Faktor 0,920 je blízko 1, čo naznačuje vysokú kvalitu prispôsobenia.
Posledným krokom je výpočet relatívnej chyby. Pridajte stĺpec a pridajte tam vzorec: „= ABS ((C2-J2) / C2), ABS - modul, absolútna hodnota. Potiahnite značku nadol a v bunke M18 zobrazte priemernú hodnotu (AVERAGE), priraďte bunkám percentuálny formát. Získaný výsledok - 7,79 % je v rámci prípustných hodnôt chyby<8…10%. Значит вычисления достаточно точны.
V prípade potreby môžeme na základe získaných hodnôt zostaviť graf.
Príklad súboru je priložený - LINK!
Kategórie:/ / zo dňa 28.10.2017Regresná čiara je grafickým odrazom vzťahu medzi javmi. V Exceli môžete veľmi prehľadne zostaviť regresnú čiaru.
To si vyžaduje:
1. Otvorte program Excel
2. Vytvorte stĺpce s údajmi. V našom príklade vybudujeme regresnú líniu alebo vzťah medzi agresivitou a pochybnosťami o sebe u prvákov. Experimentu sa zúčastnilo 30 detí, údaje sú uvedené v tabuľke programu Excel:
1 stĺpec - Číslo predmetu
2 stĺpec - agresivita v bodoch
3 stĺpec - sebapochybnosť v bodoch

3.Potom musíte vybrať oba stĺpce (bez názvu stĺpca), kliknite na kartu vložiť , vybrať bod a z navrhovaných rozložení vyberte úplne prvé miesto so značkami .

4.Máme teda prázdne miesto pre regresnú priamku - tzv. bodový diagram... Ak chcete prejsť na regresnú čiaru, musíte kliknúť na výsledný obrázok a kliknúť na kartu konštruktér, nájsť na paneli rozloženia grafov a vyberte si M a ket9 , hovorí tiež f (x)

5. Máme teda regresnú priamku. V grafe je znázornená aj jeho rovnica a druhá mocnina korelačného koeficientu

6. Zostáva doplniť názov grafu, názov osí. Ak chcete, môžete tiež odstrániť legendu, znížiť počet vodorovných čiar mriežky (záložka rozloženie , potom net ). Základné zmeny a nastavenia sa vykonávajú v záložke Rozloženie

Regresná priamka bola zostavená v MS Excel. Teraz ho možno doplniť do textu práce.








Pomer strán 1440 x 900
Rozlíšenia obrazovky monitora
Kedy potrebujem aktualizovať firmvér
Ako premeniť smartfón s Androidom na bezpečnostnú kameru
Ako vyzerá čínska klávesnica (história a fotografie)