- öğretici
UPD. Tek boşluklu biçimlendirmeyi kaldırmak zorunda kaldı. Güzel bir gün, habraparser, ön ve kod etiketlerinin içindeki biçimlendirmeyi algılamayı bıraktı. Bütün metin bir karmaşaya dönüştü. Habr yönetimi bana yardım edemedi. Şimdi düzensiz, ama en azından okunabilir.
Bir jpg dosyasının nasıl çalıştığını hiç merak ettiniz mi? Şimdi çözelim! Favori derleyicinizi ve altıgen düzenleyicinizi ısıtın, hadi şunu çözelim:
Özel olarak daha küçük bir çizim yaptım. Bu, tanıdık ancak yoğun bir şekilde sıkıştırılmış Google favicon'udur:
Açıklamanın basitleştirilmiş olduğu ve verilen bilgilerin tam olmadığı konusunda sizi hemen uyarıyorum, ancak daha sonra spesifikasyonu anlamak kolay olacaktır.
Kodlamanın nasıl gerçekleştiğini bile bilmeden dosyadan bir şeyler çıkartabiliriz.
- işaretleyiciyi başlat. Her zaman tüm jpg dosyalarının başında bulunur.
Bayt tarafından takip edildi
... Bu, yorum bölümünün başlangıcını işaretleyen bir işaretçidir. Sonraki 2 bayt
- bölümün uzunluğu (bu 2 bayt dahil). Yani sonraki iki
- yorumun kendisi. Bunlar ":" ve ")" karakterlerinin kodlarıdır, yani. normal ifade. Bunu hex editörünün sağ tarafındaki ilk satırda görebilirsiniz.
biraz teori
Adımlarda çok kısaca: Bu verilerin kodlanabileceği sırayı düşünelim. Tüm görüntü için önce tamamen Y kanalının kodlandığını, ardından Cb'nin ve ardından Cr'nin kodlandığını varsayalım. Herkes çevirmeli ağda resim yüklemeyi hatırlar. Bu şekilde kodlanmış olsalardı, ekranda görünmeden önce tüm görüntünün yüklenmesini beklememiz gerekirdi. Dosyanın sonunun kaybolması da rahatsız edici olacaktır. Muhtemelen başka iyi sebepler de vardır. Bu nedenle, kodlanmış veriler küçük parçalar halinde dönüşümlü olarak düzenlenir.
Bu verilerin kodlanabileceği sırayı düşünelim. Tüm görüntü için önce tamamen Y kanalının kodlandığını, ardından Cb'nin ve ardından Cr'nin kodlandığını varsayalım. Herkes çevirmeli ağda resim yüklemeyi hatırlar. Bu şekilde kodlanmış olsalardı, ekranda görünmeden önce tüm görüntünün yüklenmesini beklememiz gerekirdi. Dosyanın sonunun kaybolması da rahatsız edici olacaktır. Muhtemelen başka iyi sebepler de vardır. Bu nedenle, kodlanmış veriler küçük parçalar halinde dönüşümlü olarak düzenlenir. 
Her Y ij, Cb ij, Cr ij bloğunun Huffman kodlarıyla kodlanmış bir DCT katsayıları matrisi olduğunu hatırlatmama izin verin. Dosyada şu sırayla düzenlenirler: Y 00 Y 10 Y 01 Y 11 Cb 00 Cr 00 Y 20
Dosya okuma
Yorumu çıkardıktan sonra şunu anlamak kolay olacaktır:- Dosya, önünde işaretleyiciler bulunan sektörlere bölünmüştür.
- İşaretleyiciler, ilk baytla birlikte 2 bayt uzunluğundadır.
- Hemen hemen tüm sektörler, uzunluklarını işaretçiden sonraki 2 baytta saklar.
FF D8 FF FE 00 04 3A 29 FF DB 00 43 00 A0 6E 78
FF FF FF FF FF FF FF FF FF FF FF FF FF FF DB 00
43 01 AA B4 B4 F0 D2 F0 FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01 FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 03 02 FF C4 00 1A
10 01 00 02 03 01 00 00 00 00 00 00 00 00 00 00
00 01 00 12 02 11 31 21 FF C4 00 15 01 01 01 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 FF
C4 00 16 11 01 01 01 00 00 00 00 00 00 00 00 00
00 00 00 00 11 00 01 FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00 AE E7 61 F2 1B D5 22 85 5D 04 3C
82 C8 48 B1 DC BF FF D9
İşaretleyici: DQT - niceleme tablosu.
FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF
Bölüm başlığı her zaman 3 bayttır. Bizim durumumuzda, öyle. Başlık şunlardan oluşur:
Uzunluk: 0x43 = 67 bayt
Tablodaki değerlerin uzunluğu: 0 (0 - 1 bayt, 1 - 2 bayt)
[_0]
Tablo Kimliği: 0
Kalan 64 baytın 8x8 tabloyu doldurması gerekir.
Tablo değerlerinin doldurulduğu sıraya daha yakından bakın. Bu sıraya zikzak sıra denir: 
İşaretleyici: SOF0 - Temel DCT
Bu işaretleyiciye SOF0 adı verilir ve bu, görüntünün temel yöntemle kodlandığı anlamına gelir. Çok yaygın. Ancak internette, önce düşük çözünürlüklü bir görüntü ve ardından normal bir resim yüklendiğinde, size tanıdık gelen aşamalı yöntem daha az popüler değildir. Bu, tam indirmeyi beklemeden orada gösterilenleri anlamanızı sağlar. Spesifikasyon, bana göründüğü gibi, çok yaygın olmayan birkaç yöntem daha tanımlar.FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
Uzunluk: 17 bayt.
Hassasiyet: 8 bit. Temel yöntemde her zaman 8. Anladığım kadarıyla kanal değerlerinin bit genişliği bu.
Resim yüksekliği: 0x10 = 16
Desen Genişliği: 0x10 = 16
Bileşen sayısı: 3. Çoğu zaman bunlar Y, Cb, Cr'dir.
1. bileşen:
Kimlik: 1
Yatay incelme (H 1): 2
[_2]
Dikey desimasyon (V 1): 2
Niceleme tablosu kimliği: 0
2. bileşen:
Kimlik: 2
Yatay incelme (H 2): 1
[_1]
Dikey incelme (V 2): 1
3. bileşen:
Kimlik: 3
Yatay incelme (H 3): 1
[_1]
Dikey incelme (V 3): 1
Niceleme tablosu kimliği: 1
Şimdi görüntünün ne kadar ince olduğunu nasıl belirleyeceğinizi görün. H max = 2 ve V max = 2'yi bulun. Kanal i yatay olarak H max / H i kez ve dikey olarak V max / V i olarak kesilecektir.
İşaretleyici: DHT (Huffman tablosu)
Bu bölüm, Huffman kodlaması ile elde edilen kodları ve değerleri saklar.FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 03 02
uzunluk: 21 bayt.
sınıf: 0 (0 - DC katsayıları tablosu, 1 - AC katsayıları tablosu).
[_0]
tablo kimliği: 0
Huffman kod uzunluğu: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Kod sayısı:
Kod sayısı, o uzunluktaki kod sayısı anlamına gelir. Bölümün, kodların kendilerini değil, yalnızca kodların uzunluklarını kaydettiğini unutmayın. Kodları kendimiz bulmalıyız. Yani 1 uzunluğunda ve bir - 2 uzunluğunda bir kodumuz var. Toplamda 2 kod var, bu tabloda başka kod yok.
Her kodla bir değer ilişkilendirilir ve bunlar dosyanın yanında listelenir. Değerler tek bayt olduğundan 2 bayt okuyoruz.
- 1. kodun değeri.
- 2. kodun değeri.
Huffman kod ağacı oluşturma
DHT bölümünde aldığımız tablodan bir ikili ağaç oluşturmamız gerekiyor. Ve zaten bu ağacın yanında her kodu tanıyoruz. Değerleri tabloda belirtildiği sırayla ekliyoruz. Algoritma basittir: Nerede olursak olalım, her zaman soldaki dala bir değer eklemeye çalışırız. Ve eğer meşgulse, o zaman sağa. Ve orada yer yoksa, o zaman daha yüksek bir seviyeye döner ve oradan deneriz. Kodun uzunluğuna eşit bir seviyede durmanız gerekir. Sol dallar 0, sağ dallar - 1'e karşılık gelir.Yorum Yap:
Her seferinde en tepeden başlamak zorunda değilsiniz. Katma değer - bir seviye yukarı gidin. Doğru şube var mı? Eğer öyleyse, tekrar yukarı çıkın. Değilse, doğru dalı oluşturun ve oraya gidin. Ardından, bir sonraki değeri eklemek için aramanızı buradan başlatın.
Bu örnekteki tüm tablolar için ağaçlar: 
UPD (anarsoul sayesinde): İlk ağacın düğümleri (DC, id = 0) 0x03 ve 0x02 değerlerine sahip olmalıdır.
Dairelerde - kodların değerleri, dairelerin altında - kodların kendileri (üstten her düğüme giderek onları aldığımızı açıklayacağım). Bu tür kodlarla (bunun ve diğer tabloların), şeklin içeriğinin kodlanmasıdır.
İşaretleyici: SOS (Taramanın Başlangıcı)
İşaretleyicideki bayt, “EVET! Son olarak direkt olarak kodlanmış görselin ayrıştırılmasına geçtik! ". Ancak bölüm sembolik olarak SOS olarak adlandırılır.& nbsp FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00
Başlık bölümünün uzunluğu (bölümün tamamı değil): 12 bayt.
Tarama bileşenlerinin sayısı. Y, Cb, Cr için 3 tane var.
1. bileşen:
Resim Bileşen Numarası: 1 (Y)
DC katsayıları için Huffman tablo kimliği: 0
[_0]
AC katsayıları için Huffman tablo kimliği: 0
2. bileşen:
Görüntü Parça Numarası: 2 (Cb)
[_1]
3. bileşen:
Resim Bileşen Numarası: 3 (Cr)
DC katsayıları için Huffman tablo kimliği: 1
[_1]
AC katsayıları için Huffman tablo kimliği: 1
Bu bileşenler döngüsel olarak değişir.
Başlık kısmının bittiği yer burasıdır, buradan kodlanmış verinin sonuna (işaretçi) kadar.
0
DC katsayısını bulma.
1.
Bit dizisini okuma (2 bayt ile karşılaşırsak, bu bir işaretleyici değil, sadece bir bayttır)... Her bitten sonra, okunan bit'e bağlı olarak 0 veya 1 dalları boyunca Huffman ağacı (karşılık gelen tanımlayıcı ile) boyunca hareket ederiz. Son düğümdeysek dururuz.
10
1011101110011101100001111100100
2.
Düğümün değerini alıyoruz. 0'a eşitse, katsayı 0'dır, tabloya yazarız ve diğer katsayıları okumaya devam ederiz. Bizim durumumuzda - 02. Bu değer, katsayının bit cinsinden uzunluğudur. Yani, sonraki 2 biti okuduk, bu katsayı olacak.
10
10
11101110011101100001111100100
3. Binary'deki değerin ilk basamağı 1 ise, olduğu gibi bırakırız: DC_coef = value. Aksi takdirde, şunu dönüştürürüz: DC_coef = değer-2 değeri +1 uzunluğu. Katsayıyı zikzak - sol üst köşenin başında tabloya yazıyoruz.
AC katsayılarını bulma.
1.
Madde 1'e benzer şekilde, DC katsayısını bulma. Sıralamayı okumaya devam ediyoruz:
10
10
1110
1110011101100001111100100
2.
Düğümün değerini alıyoruz. 0'a eşitse, matrisin kalan değerlerinin sıfırlarla doldurulması gerektiği anlamına gelir. Daha fazla kodlanmış sonraki matris... Buraya kadar okuyan ve bana kişisel olarak yazan ilk birkaç kişi karmada bir artı alacak. Bizim durumumuzda düğüm değeri 0x31'dir.
İlk kemirme: 0x3 - bu, matrise kaç tane sıfır eklememiz gerektiğidir. Bunlar 3 sıfır katsayı.
İkinci kemirme: 0x1 - bit cinsinden katsayı uzunluğu. Devamını okuyoruz.
10
10
1110
1
110011101100001111100100
3. DC katsayısını bulmanın 3. maddesine benzer.
Zaten anladığınız gibi, kodun sıfır değerine rastlayana veya matris dolana kadar AC katsayılarını okumanız gerekir.
Bizim durumumuzda, şunu elde ederiz:
10
10
1110
1
1100
11
101
10
0
0
0
1
11110
0
100
ve matris:
Değerlerin aynı zikzak düzende doldurulduğunu fark ettiniz mi?
Bu sırayı kullanmanın nedeni basittir - v ve u değerleri ne kadar büyük olursa, ayrık kosinüs dönüşümünde S vu katsayısı o kadar az önemlidir. Bu nedenle, yüksek sıkıştırma oranlarında önemsiz oranlar sıfırlanarak dosya boyutu küçültülür.
[-4 1 1 1 0 0 0 0] [ 5 -1 1 0 0 0 0 0]
[ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0]
[ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Oh, kodlanmış DC katsayılarının DC katsayılarının kendileri değil, önceki tablonun katsayıları arasındaki farkları olduğunu söylemeyi unuttum (aynı kanal)! Matrisleri düzeltmek gereklidir:
2. için DC: 2 + (-4) = -2
3. için DC: -2 + 5 = 3
4. için DC: 3 + (-4) = -1
[-2 1 1 1 0 0 0 0] [ 3 -1 1 0 0 0 0 0] [-1 2 2 1 0 0 0 0]
………
Şimdi sıra oldu. Bu kural dosyanın sonuna kadar sürer.
... ve Cb ve Cr için matrise göre:
[-1 0 0 0 0 0 0 0]
[ 1 1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Burada sadece bir matris olduğu için DC katsayıları yalnız bırakılabilir.
hesaplamalar
niceleme
Matrisin nicemleme aşamasından geçtiğini hatırlıyor musunuz? Matrisin elemanları, niceleme matrisinin elemanları ile terim terim çarpılmalıdır. İhtiyacınız olanı seçmek için kalır. İlk olarak, görüntü bileşeni = 1 olan ilk bileşeni taradık. Bu tanımlayıcıya sahip görüntü bileşeni, niceleme matrisi 0'ı kullanır (ikisinden ilkine sahibiz). Yani çarptıktan sonra:
[ 0 120 280 0 0 0 0 0]
[ 0 -130 -160 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Benzer şekilde, Y kanalının 3 matrisini daha elde ederiz ...
[-320 110 100 160 0 0 0 0] [ 480 -110 100 0 0 0 0 0]
[ 0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[ 0 -130 0 0 0 0 0 0] [ 0 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-160 220 200 160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
... ve Cb ve Cr için matrise göre.
[-170 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 180 210 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Ters ayrık kosinüs dönüşümü
Formül zor olmamalı *. S vu, sonuçtaki katsayı matrisimizdir. u bir sütun, v bir satırdır. s yx - doğrudan kanal değerleri.
* Genel olarak konuşursak, bu tamamen doğru değildir. 16x16 resmin kodunu çözüp ekranda gösterebildiğimde 600x600 resim çektim (bu arada Mind.In.A.Box'ın favori albümü Lost Alone'un kapağıydı). Hemen işe yaramadı - çeşitli hatalar ortaya çıktı. Yakında doğru yüklenmiş bir resme hayran olabilirim. Sadece indirme hızı çok üzücüydü. 7 saniye sürdüğünü hala hatırlıyorum. Ancak bu şaşırtıcı değil, yukarıdaki formülü düşüncesizce kullanırsanız, o zaman bir pikselin bir kanalını hesaplamak için 128 kosinüs, 768 çarpma ve orada bazı eklemeler bulmanız gerekecektir. Bir düşünün - bir pikselin yalnızca bir kanalında neredeyse bin zor işlem! Neyse ki, optimizasyon için yer var (birçok deneyden sonra, yükleme süresini 15ms'lik zamanlayıcı doğruluğu sınırına indirdim ve bundan sonra görüntüyü 25 kat daha büyük bir fotoğrafla değiştirdim. Belki bunun hakkında yazacağım. ayrı bir makale).
Y kanalının sadece ilk matrisini hesaplamanın sonucunu yazacağım (değerler yuvarlanmıştır):
[ 87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87 -50 6 56 79 72 48 29]
Ve kalan 2:
Cb Cr
[ 60 52 38 20 0 -18 -32 -40] [ 19 27 41 60 80 99 113 120]
[ 48 41 29 13 -3 -19 -31 -37] [ 0 6 18 34 51 66 78 85]
[ 25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[ -4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[ -37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[ -67 -63 -55 -44 -33 -22 -14 -10] [ -5 -9 -17 -28 -39 -50 -58 -62]
[ -90 -84 -71 -56 -39 -23 -11 -4] [ 32 26 14 -1 -18 -34 -46 -53]
[-102 -95 -81 -62 -42 -23 -9 -1] [ 58 50 36 18 -2 -20 -34 -42]
- Oh, hadi gidip yemek yiyelim!
- Evet, hiç girmiyorum, ne hakkında?
- YCbCr renk değerleri alındıktan sonra geriye şu şekilde RGB'ye dönüştürmek kalır: YCbCrToRGB (Y ij, Cb ij, Cr ij), Y ij, Cb ij, Cr ij - sonuçta ortaya çıkan matrislerimiz.
- 4 matris Y ve bir Cb ve bir Cr, kanalları incelttiğimiz için ve 4 piksel Y, bir Cb ve Cr'ye karşılık gelir. Bu nedenle şu şekilde hesaplayın: YCbCrToRGB (Y ij, Cb, Cr)
YCbCr'den RGB'ye dönüştürücü
R = Y + 1.402 * KrG = Y - 0.34414 * Cb - 0.71414 * Cr
B = Y + 1.772 * Cb
128 eklemeyi unutmayın. Değerler aralığın dışındaysa sınır değerlerini atayın. Formül basittir, ancak aynı zamanda CPU zamanının bir kısmını da tüketir.
Örneğimizin sol üst 8x8 karesi için R, G, B kanalları için sonuç tabloları:
255 248 194 148 169 215 255 255
255 238 172 115 130 178 255 255
255 208 127 59 64 112 208 255
255 223 143 74 77 120 211 255
237 192 133 83 85 118 184 222
177 161 146 132 145 162 201 217
56 73 101 126 144 147 147 141
0 17 76 126 153 146 127 108
231 185 117 72 67 113 171 217
229 175 95 39 28 76 139 189
254 192 100 31 15 63 131 185
255 207 115 46 28 71 134 185
255 241 175 125 112 145 193 230
226 210 187 173 172 189 209 225
149 166 191 216 229 232 225 220
72 110 166 216 238 231 206 186
255 255 249 203 178 224 255 255
255 255 226 170 140 187 224 255
255 255 192 123 91 138 184 238
255 255 208 139 103 146 188 239
255 255 202 152 128 161 194 232
255 244 215 200 188 205 210 227
108 125 148 172 182 184 172 167
31 69 122 172 191 183 153 134
Son
Genel olarak, ben bir JPEG uzmanı değilim, bu yüzden tüm soruları zar zor yanıtlayabiliyorum. Sadece kod çözücümü yazarken, genellikle çeşitli anlaşılmaz sorunlarla yüzleşmek zorunda kaldım. Ve görüntü yanlış görüntülendiğinde, nerede hata yaptığımı bilmiyordum. Belki parçaları yanlış yorumladı ya da DCT'yi yanlış kullandı. Kaçırdım adım adım örnek bu yüzden umarım bu makale bir kod çözücü yazarken yardımcı olur. Bence temel yöntemin açıklamasını kapsıyor, ancak yine de tam olarak yapamazsınız. İşte bana yardımcı olan bazı bağlantılar:Tüm DCT katsayıları hesaplandıktan sonra nicelleştirilmeleri gerekir. Bu adımda, bilgilerin bir kısmı atılır (bilgisayardaki hesaplamaların sonlu doğruluğu nedeniyle önceki adımda da küçük kayıplar meydana gelir). DCT katsayı matrislerinden gelen her sayı, "niceleme tablosundan" özel bir sayıya bölünür ve sonuç en yakın tam sayıya yuvarlanır. Daha önce belirtildiği gibi, her renk bileşeni için bu tür üç tabloya sahip olmak gerekir. JPEG standardı, dört tablonun kullanılmasına izin verir ve kullanıcı, renk bileşenlerini nicelemek için bu tablolardan herhangi birini seçebilir. Nicemleme tablosundaki 64 sayının tümü JPEG parametreleridir. Prensip olarak, kullanıcı daha yüksek bir sıkıştırma oranı elde etmek için herhangi bir oranı değiştirebilir. Pratikte, bu kadar çok sayıda parametreyle deney yapmak çok zordur, bu nedenle JPEG yazılımı iki yaklaşım benimser:
1. Varsayılan niceleme tablosu. Biri parlaklık bileşeni (ve gri tonlama için) ve diğeri kromatik bileşenler için olmak üzere bu tür iki tablo, JPEG komitesi tarafından yapılan birçok deneyle yapılan kapsamlı araştırmaların sonucudur. JPEG standardının bir parçasıdırlar ve tabloda yeniden üretilirler. 3.50. Soldan hareket edildiğinde tabloların QC katsayılarının nasıl büyüdüğü görülebilir. üst köşe sağ alt köşede. Bu, yüksek uzaysal frekanslara karşılık gelen DCT katsayılarında bir azalmayı yansıtır.
2. Kullanıcı tarafından belirtilen parametreye bağlı olarak basit bir nicemleme katsayıları tablosu hesaplanır. Basit ifadeler tip ![]() sol üst köşeden sağ alt köşeye doğru katsayılarda bir azalmayı garanti eder.
sol üst köşeden sağ alt köşeye doğru katsayılarda bir azalmayı garanti eder.
parlaklık
Kuantizasyon doğru yapılırsa, matrisin sol üst köşesinde yoğunlaşacak olan DCT katsayıları bloğunda yalnızca birkaç sıfır olmayan katsayı kalacaktır. Bu sayılar JPEG algoritmasının çıktılarıdır, ancak yine de çıktı dosyasına yazılmadan önce sıkıştırılmaları gerekir. JPEG literatüründe, bu sıkıştırmaya "entropi kodlaması" denir ve ayrıntıları § 3.7.5'te tartışılacaktır. 8x8 tamsayı matrislerini sıkıştırmak için entropi kodlamasında üç teknik kullanılır.
3. 64 numara zikzak taramada olduğu gibi arka arkaya sıralanır (bkz. Şekil 3.5a). Sıfır olmayan sayılarla başlar, genellikle uzun bir sıfır kuyruğu izler. Dosyaya yalnızca sıfır olmayan sayılar verilir (uygun kodlamadan sonra), ardından özel kod EOB (blok sonu). Tüm sıfır kuyruğunu yazmak gerekli değildir (EOB'nin uzun bir sıfır serisini kodladığını da söyleyebilirsiniz).
Örnek: Masada. 3.51, yalnızca 4'ü sıfır olmayan varsayımsal DCT katsayılarının bir listesidir. Bu sayıların zikzak sıralamasıyla bir katsayı dizisi elde edilir: ![]()
Sekme. 3.51. Nicelenmiş katsayılar.
Matris öğelerini zikzak biçiminde okumak için bir alt program nasıl yazılır? En basit yol, bu yolu manuel olarak izlemek ve sonucu, her yapının içinden zikzak bir yolun geçtiği bir çift hücre koordinatından oluştuğu bir dizi yapı zz'ye yazmaktır (bkz. Şekil 3.52).
zz yapısının bileşenleri zz.r ve zz.с ile gösteriliyorsa, zikzak boyunca yol aşağıdaki döngü kullanılarak gerçekleştirilebilir.

4. Sıfır olmayan dönüşüm katsayıları Huffman yöntemiyle sıkıştırılır (bkz. § 3.7.5).
5. Bu sayılardan ilki (DC katsayısı, bkz. sayfa 145) diğer sayılardan (AC katsayıları) ayrı olarak işlenir.

Pirinç. 3.52. Zigzag yolunun koordinatları.
- öğretici
UPD. Tek boşluklu biçimlendirmeyi kaldırmak zorunda kaldı. Güzel bir gün, habraparser, ön ve kod etiketlerinin içindeki biçimlendirmeyi algılamayı bıraktı. Bütün metin bir karmaşaya dönüştü. Habr yönetimi bana yardım edemedi. Şimdi düzensiz, ama en azından okunabilir.
Bir jpg dosyasının nasıl çalıştığını hiç merak ettiniz mi? Şimdi çözelim! Favori derleyicinizi ve altıgen düzenleyicinizi ısıtın, hadi şunu çözelim:
Özel olarak daha küçük bir çizim yaptım. Bu, tanıdık ancak yoğun bir şekilde sıkıştırılmış Google favicon'udur:
Açıklamanın basitleştirilmiş olduğu ve verilen bilgilerin tam olmadığı konusunda sizi hemen uyarıyorum, ancak daha sonra spesifikasyonu anlamak kolay olacaktır.
Kodlamanın nasıl gerçekleştiğini bile bilmeden dosyadan bir şeyler çıkartabiliriz.
- işaretleyiciyi başlat. Her zaman tüm jpg dosyalarının başında bulunur.
Bayt tarafından takip edildi
... Bu, yorum bölümünün başlangıcını işaretleyen bir işaretçidir. Sonraki 2 bayt
- bölümün uzunluğu (bu 2 bayt dahil). Yani sonraki iki
- yorumun kendisi. Bunlar ":" ve ")" karakterlerinin kodlarıdır, yani. normal ifade. Bunu hex editörünün sağ tarafındaki ilk satırda görebilirsiniz.
biraz teori
Adımlarda çok kısaca:Bu verilerin kodlanabileceği sırayı düşünelim. Tüm görüntü için önce tamamen Y kanalının kodlandığını, ardından Cb'nin ve ardından Cr'nin kodlandığını varsayalım. Herkes çevirmeli ağda resim yüklemeyi hatırlar. Bu şekilde kodlanmış olsalardı, ekranda görünmeden önce tüm görüntünün yüklenmesini beklememiz gerekirdi. Dosyanın sonunun kaybolması da rahatsız edici olacaktır. Muhtemelen başka iyi sebepler de vardır. Bu nedenle, kodlanmış veriler küçük parçalar halinde dönüşümlü olarak düzenlenir.
Her Y ij, Cb ij, Cr ij bloğunun Huffman kodlarıyla kodlanmış bir DCT katsayıları matrisi olduğunu hatırlatmama izin verin. Dosyada şu sırayla düzenlenirler: Y 00 Y 10 Y 01 Y 11 Cb 00 Cr 00 Y 20
Dosya okuma
Yorumu çıkardıktan sonra şunu anlamak kolay olacaktır:- Dosya, önünde işaretleyiciler bulunan sektörlere bölünmüştür.
- İşaretleyiciler, ilk baytla birlikte 2 bayt uzunluğundadır.
- Hemen hemen tüm sektörler, uzunluklarını işaretçiden sonraki 2 baytta saklar.
FF D8 FF FE 00 04 3A 29 FF DB 00 43 00 A0 6E 78
FF FF FF FF FF FF FF FF FF FF FF FF FF FF DB 00
43 01 AA B4 B4 F0 D2 F0 FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01 FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 03 02 FF C4 00 1A
10 01 00 02 03 01 00 00 00 00 00 00 00 00 00 00
00 01 00 12 02 11 31 21 FF C4 00 15 01 01 01 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 FF
C4 00 16 11 01 01 01 00 00 00 00 00 00 00 00 00
00 00 00 00 11 00 01 FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00 AE E7 61 F2 1B D5 22 85 5D 04 3C
82 C8 48 B1 DC BF FF D9
İşaretleyici: DQT - niceleme tablosu.
FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF
Bölüm başlığı her zaman 3 bayttır. Bizim durumumuzda, öyle. Başlık şunlardan oluşur:
Uzunluk: 0x43 = 67 bayt
Tablodaki değerlerin uzunluğu: 0 (0 - 1 bayt, 1 - 2 bayt)
[_0]
Tablo Kimliği: 0
Kalan 64 baytın 8x8 tabloyu doldurması gerekir.
Tablo değerlerinin doldurulduğu sıraya daha yakından bakın. Bu sıraya zikzak sıra denir:
İşaretleyici: SOF0 - Temel DCT
Bu işaretleyiciye SOF0 adı verilir ve bu, görüntünün temel yöntemle kodlandığı anlamına gelir. Çok yaygın. Ancak internette, önce düşük çözünürlüklü bir görüntü ve ardından normal bir resim yüklendiğinde, size tanıdık gelen aşamalı yöntem daha az popüler değildir. Bu, tam indirmeyi beklemeden orada gösterilenleri anlamanızı sağlar. Spesifikasyon, bana göründüğü gibi, çok yaygın olmayan birkaç yöntem daha tanımlar.FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
Uzunluk: 17 bayt.
Hassasiyet: 8 bit. Temel yöntemde her zaman 8. Anladığım kadarıyla kanal değerlerinin bit genişliği bu.
Resim yüksekliği: 0x10 = 16
Desen Genişliği: 0x10 = 16
Bileşen sayısı: 3. Çoğu zaman bunlar Y, Cb, Cr'dir.
1. bileşen:
Kimlik: 1
Yatay incelme (H 1): 2
[_2]
Dikey desimasyon (V 1): 2
Niceleme tablosu kimliği: 0
2. bileşen:
Kimlik: 2
Yatay incelme (H 2): 1
[_1]
Dikey incelme (V 2): 1
3. bileşen:
Kimlik: 3
Yatay incelme (H 3): 1
[_1]
Dikey incelme (V 3): 1
Niceleme tablosu kimliği: 1
Şimdi görüntünün ne kadar ince olduğunu nasıl belirleyeceğinizi görün. H max = 2 ve V max = 2'yi bulun. Kanal i yatay olarak H max / H i kez ve dikey olarak V max / V i olarak kesilecektir.
İşaretleyici: DHT (Huffman tablosu)
Bu bölüm, Huffman kodlaması ile elde edilen kodları ve değerleri saklar.FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 03 02
uzunluk: 21 bayt.
sınıf: 0 (0 - DC katsayıları tablosu, 1 - AC katsayıları tablosu).
[_0]
tablo kimliği: 0
Huffman kod uzunluğu: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Kod sayısı:
Kod sayısı, o uzunluktaki kod sayısı anlamına gelir. Bölümün, kodların kendilerini değil, yalnızca kodların uzunluklarını kaydettiğini unutmayın. Kodları kendimiz bulmalıyız. Yani 1 uzunluğunda ve bir - 2 uzunluğunda bir kodumuz var. Toplamda 2 kod var, bu tabloda başka kod yok.
Her kodla bir değer ilişkilendirilir ve bunlar dosyanın yanında listelenir. Değerler tek bayt olduğundan 2 bayt okuyoruz.
- 1. kodun değeri.
- 2. kodun değeri.
Huffman kod ağacı oluşturma
DHT bölümünde aldığımız tablodan bir ikili ağaç oluşturmamız gerekiyor. Ve zaten bu ağacın yanında her kodu tanıyoruz. Değerleri tabloda belirtildiği sırayla ekliyoruz. Algoritma basittir: Nerede olursak olalım, her zaman soldaki dala bir değer eklemeye çalışırız. Ve eğer meşgulse, o zaman sağa. Ve orada yer yoksa, o zaman daha yüksek bir seviyeye döner ve oradan deneriz. Kodun uzunluğuna eşit bir seviyede durmanız gerekir. Sol dallar 0, sağ dallar - 1'e karşılık gelir.Yorum Yap:
Her seferinde en tepeden başlamak zorunda değilsiniz. Katma değer - bir seviye yukarı gidin. Doğru şube var mı? Eğer öyleyse, tekrar yukarı çıkın. Değilse, doğru dalı oluşturun ve oraya gidin. Ardından, bir sonraki değeri eklemek için aramanızı buradan başlatın.
Bu örnekteki tüm tablolar için ağaçlar:
UPD (teşekkürler): İlk ağacın düğümleri (DC, id = 0) 0x03 ve 0x02 değerlerine sahip olmalıdır.
Dairelerde - kodların değerleri, dairelerin altında - kodların kendileri (üstten her düğüme giderek onları aldığımızı açıklayacağım). Bu tür kodlarla (bunun ve diğer tabloların), şeklin içeriğinin kodlanmasıdır.
İşaretleyici: SOS (Taramanın Başlangıcı)
İşaretleyicideki bayt, “EVET! Son olarak direkt olarak kodlanmış görselin ayrıştırılmasına geçtik! ". Ancak bölüm sembolik olarak SOS olarak adlandırılır.& nbsp FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00
Başlık bölümünün uzunluğu (bölümün tamamı değil): 12 bayt.
Tarama bileşenlerinin sayısı. Y, Cb, Cr için 3 tane var.
1. bileşen:
Resim Bileşen Numarası: 1 (Y)
DC katsayıları için Huffman tablo kimliği: 0
[_0]
AC katsayıları için Huffman tablo kimliği: 0
2. bileşen:
Görüntü Parça Numarası: 2 (Cb)
[_1]
3. bileşen:
Resim Bileşen Numarası: 3 (Cr)
DC katsayıları için Huffman tablo kimliği: 1
[_1]
AC katsayıları için Huffman tablo kimliği: 1
Bu bileşenler döngüsel olarak değişir.
Başlık kısmının bittiği yer burasıdır, buradan kodlanmış verinin sonuna (işaretçi) kadar.
0
DC katsayısını bulma.
1.
Bit dizisini okuma (2 bayt ile karşılaşırsak, bu bir işaretleyici değil, sadece bir bayttır)... Her bitten sonra, okunan bit'e bağlı olarak 0 veya 1 dalları boyunca Huffman ağacı (karşılık gelen tanımlayıcı ile) boyunca hareket ederiz. Son düğümdeysek dururuz.
10
1011101110011101100001111100100
2.
Düğümün değerini alıyoruz. 0'a eşitse, katsayı 0'dır, tabloya yazarız ve diğer katsayıları okumaya devam ederiz. Bizim durumumuzda - 02. Bu değer, katsayının bit cinsinden uzunluğudur. Yani, sonraki 2 biti okuduk, bu katsayı olacak.
10
10
11101110011101100001111100100
3. Binary'deki değerin ilk basamağı 1 ise, olduğu gibi bırakırız: DC_coef = value. Aksi takdirde, şunu dönüştürürüz: DC_coef = değer-2 değeri +1 uzunluğu. Katsayıyı zikzak - sol üst köşenin başında tabloya yazıyoruz.
AC katsayılarını bulma.
1.
Madde 1'e benzer şekilde, DC katsayısını bulma. Sıralamayı okumaya devam ediyoruz:
10
10
1110
1110011101100001111100100
2.
Düğümün değerini alıyoruz. 0'a eşitse, matrisin kalan değerlerinin sıfırlarla doldurulması gerektiği anlamına gelir. Ardından bir sonraki matris kodlanır. Buraya kadar okuyan ve bana kişisel olarak yazan ilk birkaç kişi karmada bir artı alacak. Bizim durumumuzda düğüm değeri 0x31'dir.
İlk kemirme: 0x3 - bu, matrise kaç tane sıfır eklememiz gerektiğidir. Bunlar 3 sıfır katsayı.
İkinci kemirme: 0x1 - bit cinsinden katsayı uzunluğu. Devamını okuyoruz.
10
10
1110
1
110011101100001111100100
3. DC katsayısını bulmanın 3. maddesine benzer.
Zaten anladığınız gibi, kodun sıfır değerine rastlayana veya matris dolana kadar AC katsayılarını okumanız gerekir.
Bizim durumumuzda, şunu elde ederiz:
10
10
1110
1
1100
11
101
10
0
0
0
1
11110
0
100
ve matris:
Değerlerin aynı zikzak düzende doldurulduğunu fark ettiniz mi?
Bu sırayı kullanmanın nedeni basittir - v ve u değerleri ne kadar büyük olursa, ayrık kosinüs dönüşümünde S vu katsayısı o kadar az önemlidir. Bu nedenle, yüksek sıkıştırma oranlarında önemsiz oranlar sıfırlanarak dosya boyutu küçültülür.
[-4 1 1 1 0 0 0 0] [ 5 -1 1 0 0 0 0 0]
[ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0]
[ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Oh, kodlanmış DC katsayılarının DC katsayılarının kendileri değil, önceki tablonun katsayıları arasındaki farkları olduğunu söylemeyi unuttum (aynı kanal)! Matrisleri düzeltmek gereklidir:
2. için DC: 2 + (-4) = -2
3. için DC: -2 + 5 = 3
4. için DC: 3 + (-4) = -1
[-2 1 1 1 0 0 0 0] [ 3 -1 1 0 0 0 0 0] [-1 2 2 1 0 0 0 0]
………
Şimdi sıra oldu. Bu kural dosyanın sonuna kadar sürer.
... ve Cb ve Cr için matrise göre:
[-1 0 0 0 0 0 0 0]
[ 1 1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Burada sadece bir matris olduğu için DC katsayıları yalnız bırakılabilir.
hesaplamalar
niceleme
Matrisin nicemleme aşamasından geçtiğini hatırlıyor musunuz? Matrisin elemanları, niceleme matrisinin elemanları ile terim terim çarpılmalıdır. İhtiyacınız olanı seçmek için kalır. İlk olarak, görüntü bileşeni = 1 olan ilk bileşeni taradık. Bu tanımlayıcıya sahip görüntü bileşeni, niceleme matrisi 0'ı kullanır (ikisinden ilkine sahibiz). Yani çarptıktan sonra:
[ 0 120 280 0 0 0 0 0]
[ 0 -130 -160 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Benzer şekilde, Y kanalının 3 matrisini daha elde ederiz ...
[-320 110 100 160 0 0 0 0] [ 480 -110 100 0 0 0 0 0]
[ 0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[ 0 -130 0 0 0 0 0 0] [ 0 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-160 220 200 160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
... ve Cb ve Cr için matrise göre.
[-170 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 180 210 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Ters ayrık kosinüs dönüşümü
Formül zor olmamalı *. S vu, sonuçtaki katsayı matrisimizdir. u bir sütun, v bir satırdır. s yx - doğrudan kanal değerleri.
* Genel olarak konuşursak, bu tamamen doğru değildir. 16x16 resmin kodunu çözüp ekranda gösterebildiğimde 600x600 resim çektim (bu arada Mind.In.A.Box'ın favori albümü Lost Alone'un kapağıydı). Hemen işe yaramadı - çeşitli hatalar ortaya çıktı. Yakında doğru yüklenmiş bir resme hayran olabilirim. Sadece indirme hızı çok üzücüydü. 7 saniye sürdüğünü hala hatırlıyorum. Ancak bu şaşırtıcı değil, yukarıdaki formülü düşüncesizce kullanırsanız, o zaman bir pikselin bir kanalını hesaplamak için 128 kosinüs, 768 çarpma ve orada bazı eklemeler bulmanız gerekecektir. Bir düşünün - bir pikselin yalnızca bir kanalında neredeyse bin zor işlem! Neyse ki, optimizasyon için yer var (birçok deneyden sonra, yükleme süresini 15ms'lik zamanlayıcı doğruluğu sınırına indirdim ve bundan sonra görüntüyü 25 kat daha büyük bir fotoğrafla değiştirdim. Belki bunun hakkında yazacağım. ayrı bir makale).
Y kanalının sadece ilk matrisini hesaplamanın sonucunu yazacağım (değerler yuvarlanmıştır):
[ 87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87 -50 6 56 79 72 48 29]
Ve kalan 2:
Cb Cr
[ 60 52 38 20 0 -18 -32 -40] [ 19 27 41 60 80 99 113 120]
[ 48 41 29 13 -3 -19 -31 -37] [ 0 6 18 34 51 66 78 85]
[ 25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[ -4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[ -37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[ -67 -63 -55 -44 -33 -22 -14 -10] [ -5 -9 -17 -28 -39 -50 -58 -62]
[ -90 -84 -71 -56 -39 -23 -11 -4] [ 32 26 14 -1 -18 -34 -46 -53]
[-102 -95 -81 -62 -42 -23 -9 -1] [ 58 50 36 18 -2 -20 -34 -42]
- Oh, hadi gidip yemek yiyelim!
- Evet, hiç girmiyorum, ne hakkında?
- YCbCr renk değerleri alındıktan sonra geriye şu şekilde RGB'ye dönüştürmek kalır: YCbCrToRGB (Y ij, Cb ij, Cr ij), Y ij, Cb ij, Cr ij - sonuçta ortaya çıkan matrislerimiz.
- 4 matris Y ve bir Cb ve bir Cr, kanalları incelttiğimiz için ve 4 piksel Y, bir Cb ve Cr'ye karşılık gelir. Bu nedenle şu şekilde hesaplayın: YCbCrToRGB (Y ij, Cb, Cr)
YCbCr'den RGB'ye dönüştürücü
R = Y + 1.402 * KrG = Y - 0.34414 * Cb - 0.71414 * Cr
B = Y + 1.772 * Cb
128 eklemeyi unutmayın. Değerler aralığın dışındaysa sınır değerlerini atayın. Formül basittir, ancak aynı zamanda CPU zamanının bir kısmını da tüketir.
Örneğimizin sol üst 8x8 karesi için R, G, B kanalları için sonuç tabloları:
255 248 194 148 169 215 255 255
255 238 172 115 130 178 255 255
255 208 127 59 64 112 208 255
255 223 143 74 77 120 211 255
237 192 133 83 85 118 184 222
177 161 146 132 145 162 201 217
56 73 101 126 144 147 147 141
0 17 76 126 153 146 127 108
231 185 117 72 67 113 171 217
229 175 95 39 28 76 139 189
254 192 100 31 15 63 131 185
255 207 115 46 28 71 134 185
255 241 175 125 112 145 193 230
226 210 187 173 172 189 209 225
149 166 191 216 229 232 225 220
72 110 166 216 238 231 206 186
255 255 249 203 178 224 255 255
255 255 226 170 140 187 224 255
255 255 192 123 91 138 184 238
255 255 208 139 103 146 188 239
255 255 202 152 128 161 194 232
255 244 215 200 188 205 210 227
108 125 148 172 182 184 172 167
31 69 122 172 191 183 153 134
Son
Genelde JPEG konusunda uzman değilim, bu yüzden tüm soruları yanıtlayamıyorum. Sadece kod çözücümü yazarken, genellikle çeşitli anlaşılmaz sorunlarla karşılaşmam gerekiyordu. Ve görüntü yanlış görüntülendiğinde, nerede hata yaptığımı bilmiyordum. Belki parçaları yanlış yorumladı ya da DCT'yi yanlış kullandı. Adım adım bir örneği kaçırdım, bu yüzden bu makalenin kod çözücü yazarken yardımcı olacağını umuyorum. Bence temel yöntemin açıklamasını kapsıyor, ancak yine de tam olarak yapamazsınız. İşte bana yardımcı olan bazı bağlantılar:Eski güzel JPEG, birçok inkar edilemez avantajına rağmen, hala önemli sınırlamalar... Bunları kaldırmak için, gelişimi uzun süredir gerçekleştirilen yeni bir görüntü sıkıştırma yöntemi çağrıldı. JPEG2000 artık resmi olarak tanınan bir format haline geldiğine göre, bu, çeşitli yazılım satıcıları tarafından aktif desteğinin başlangıcı olmalıdır.
Bir bilgisayarda grafiklerle çalışan pek çok kişi şu soruyla ilgileniyor: PC belleğinde çok etkileyici bir yer kaplayan bir görüntü, diskte çok daha küçük bir boyuta nasıl sıkıştırılabilir? Yayıncılık kariyerimin başlangıcında, "sıkıştırma" kelimesinin benim için çok gizemli ve şaşırtıcı olduğunu hatırlıyorum ... Gerçekten de, görüntü sıkıştırma nasıl gerçekleşir - sonuçta, onsuz, ne Web'i hayal etmek imkansız. , ne dijital fotoğrafçılık, ne de renkli baskı?
Yani sıkıştırma. Kalite kaybına neden olabilir veya olmayabilir. İkinci durum, ( gibi çiftlerle sonuçlanan RLE (Çalışma Uzunluğu Kodlaması) gibi yöntemlerdir. atlamak, değer, nerede atlamak Ardışık sıfırların sayısı ve değer- sonraki değer) ve LZW (Lempel-Ziff-Welch yöntemiyle sıkıştırma), PSD biçimleri, GIF ve TIFF. RAR ve ZIP gibi arşivleyiciler tarafından yaygın olarak kullanılırlar. Kayıpsız sıkıştırmanın ortalama sıkıştırma oranı 2-3 katıdır.
Görüntüyü daha fazla sıkıştırmanız gerekiyorsa, kalite kaybı olmadan yapamazsınız. İlkeler nelerdir? İlk olarak, herhangi bir görüntü, kaldırılması resmin kalitesinde gözle görülür bir değişikliğe yol açmayacak belirli bir miktarda fazlalık içerir. İkincisi, insan gözü parlaklıktaki değişikliklere renkten daha duyarlıdır. Bu nedenle, farklı görüntü kanalları için farklı sıkıştırma oranları uygulanır - bilgi kaybolur, ancak görsel olarak fark edilmez. Ek olarak, gözün küçük görüntü öğelerine duyarlılığı düşüktür, bu da kaliteden ödün vermeden çıkarılmasına olanak tanır. Bu şekilde görüntü (kalitedeki bozulma zaten fark edilir olsa bile) kabul edilebilir bir eşiğe kadar sıkıştırılabilir. Her özel durum için kalite bozulma derecesi belirlenir. Basım endüstrisi için, yalnızca minimum düzeyde bozulmalara ve İnternet'te yayınlamak için (amaca bağlı olarak) çok daha fazlasına izin verilir.
Kayıplı sıkıştırma yöntemleri arasında en popüler olanı, otuz kat sıkıştırmada bile yeterli görüntü kalitesini koruyan JPEG'dir. Bu arada, çoğu modern veri sıkıştırma yöntemi (örneğin, mp3 olarak bilinen Katman-4 ve ayrıca MPEG), JPEG'e benzer mekanizmalar uygular. Bu biçime daha yakından bir göz atalım, özellikle de çok uzun zaman önce değil, en son uygulaması olan JPEG2000 nihayet onaylandığından, on yıl boyunca JPEG / MPEG'e yapılan tüm eklemeleri içeriyordu.
JPEG
Sıkıştırma algoritmasının adı, ITU (Uluslararası Telekomünikasyon Birliği) ve ISO (Uluslararası Standartlaştırma Örgütü) uzmanlarından oluşan bir girişim grubu olan Joint Photographic Expert Group'un kısaltmasıdır. Bu nedenle adı Joint önekini içerir. 1992'de JPEG, grafikler için uluslararası standart olarak ilan edildi.
Sıkıştırma yöntemini kullanırken JPEG kalitesi her zaman kaybolur. Bu durumda, her zaman bir seçenek vardır: hacim pahasına kaliteyi tercih etmek (dosya boyutu yaklaşık üç kez sıkıştırılacaktır) veya tam tersine, elde etmek için en küçük beden hala tanınabilir kalacağı görüntü (sıkıştırma derecesi 100'e ulaşabilir). Ortaya çıkan görüntü ile orijinal arasındaki kalite farkının hala algılanamadığı sıkıştırma, dosya boyutunda 10 ila 20 kat azalmaya neden olur.
Uygulama alanı
JPEG, fotoğraf kalitesinde tam renkli ve tek renkli görüntüleri sıkıştırmada en iyisidir. Bir resmi indeks paleti ile kaydetmeniz gerekiyorsa, önce tam renge dönüştürülür. JPEG yöntemini kullanarak sıkıştırırken, her şeyin görüntülerin doğasına bağlı olduğunu unutmamalısınız: renk değişikliklerinin önemsiz olduğu ve keskin renk geçişlerinin olmadığı yerlerde çok daha küçük bir hacim işgal edilecektir. JPEG, fotoğrafik görüntüleri depolamanız gereken her yerde kullanılır: dijital kameralarda, baskıda (EPS DCS 2.0), İnternet onsuz düşünülemez.
Birkaç JPEG sıkıştırma türü vardır, ancak standart pakette raster ile çalışmak için kullanılan bunlardan yalnızca ikisini ele alacağız. Adobe görüntüleri Photoshop, - temel ve ilerici... Diğer iki yöntem - aritmetik ve kayıpsız - egzotiktir ve bir dizi nedenden dolayı yaygınlaşmamıştır.
Sıkıştırma nasıl çalışır?
1. İlk adım dönüştürme renk modeli görüntüleri (genellikle RGB) parlaklık ve renk bileşenlerinin ayrıldığı (örneğin, YCbCr veya YUV) bir modele dönüştürür, bu da her kanal için sıkıştırma seviyelerini en iyi şekilde seçmeyi mümkün kılar (göz algısının özelliklerini dikkate alarak). Dönüşüm şu şekilde gerçekleşir:
Y = 0.299xR + 0.587 * G + 0.114xB Cb = (B-Y) / 0.866 / 2 + 128 Cr = (R-Y) / 0.701 / 2 + 128
2. Bir sonraki aşama sözde. ön filtreleme Cb ve Cr kanallarının her birinde ayrı ayrı komşu piksellerin yatay ve dikey yönlerde çiftler halinde gruplandığı ve Y parlaklık kanalının değişmeden bırakıldığı . Bundan sonra, dört piksellik grubun tamamı, ilgili Cb ve Cr bileşenlerinin ortalama değerini alır. Kısalık için, böyle bir şema 4: 1: 1 olarak belirlenebilir (DRAW - jpeg penceresine dışa aktarmada aynı sunum şekli benimsenmiştir). Her pikselin 3 bayt (üç kanalın her biri için 256 seviye) ile kodlandığı dikkate alındığında, sonuç olarak veri hacmi otomatik olarak 2 kat azaltılır (12 bayt yerine 4 piksel aktarmak için yeterlidir. sadece 4 + 1 + 1 = 6 bayt aktarın) ... Matematik açısından, böyle bir dönüşüm önemli bir bilgi kaybına yol açar, ancak sıradan fotoğraf görüntülerinde önemli bir fazlalık olduğu için insan gözü kaybı algılamaz.
3. Birincil "temizlik" aşamasını geçen alınan bilgiler, her kanalda tekrar bloklara ayrı ayrı gruplandırılır, ancak zaten 8x8 bloklarda, bundan sonra ana sıkıştırma onlara uygulanır - sözde. ayrık kosinüs dönüşümü, kısaca - DCT (ayrık kosinüs dönüşümü). Sonuç olarak, bilgi dağıtımda piksellerin parlaklığı, bir dağılımla tanımlandığı başka bir forma dönüştürülür. oluşma sıklığı belirli bir piksel parlaklığı. DCT'nin diğer dönüşümlere göre (örneğin, Fourier dönüşümüne göre) çeşitli avantajları vardır. daha iyi iyileşme bilgi.
Görüntüyü oluşturan her blok için 64 değerlik bir dizi (8x8 piksel) yerine 64 frekanslık bir dizi elde ediyoruz. DCT'nin nasıl çalıştığına bir örnekle bakalım. Resmimizin bir bloğundaki piksellerin parlaklığının Şekil 1'de gösterilene benzediğini varsayalım. 1 solda, ardından dönüşüm sonucu sağda gösterildiği gibi olacaktır.
| 1 |
Önemli doğruluğa rağmen, bu aşamada hala bazı bilgi kayıpları meydana gelir - bu nedenle JPEG her zaman kalite kaybına yol açar. Dönüşümün temel amacı, daha sonra önemsiz bilgileri ortadan kaldırırken faydalı olacak büyük (şekilde - sol üstte) ve küçük (sağ altta) nesnelerin dağılımının genel resmini bulmaktır.
4. Bir sonraki adım, gözle neredeyse hiç fark edilmeyen bilgileri bloktan çıkarmak veya nicemleme(kuantizasyon). Tüm bileşenler, her birinin önemini belirleyen çeşitli katsayılara bölünmüştür. kaliteli restorasyon orijinal görüntü ve sonuç yuvarlak bir tamsayı değerine Görüntünün son hacmini azaltarak en büyük kalite kaybını ortaya çıkaran bu prosedürdür. Yüksek frekanslı bileşenler kabaca nicelenir ve düşük frekanslı bileşenler en belirgin oldukları için daha kesin olarak nicelenir. Kalitedeki bozulmayı biraz yumuşatmak için luma kanalı, kroma kanallarından daha küçük bölme oranları kullanır. Ancak daha sık (bu, hesaplamaları hızlandırmak için yapılır), özel olarak seçilen değerler yerine, yalnızca bir tane alınır - kullanıcının sıkıştırma seviyesini seçerken girdiği.
Örneğin, işlemi kullanarak bir görüntüyü kaydederken Photoshop penceresi şöyle görünür: için kaydet web, burada Kalite parametresi (veya daha doğrusu ondan türetilmiştir) aynı yuvarlama faktörü(incir. 2).
Kuantizasyon sonucunda, orijinal görüntünün belirli bir doğrulukla yeniden oluşturulduğu bir dizi bileşen elde edilir (Şekil 3).
 |
| 4 |
İncirde. Şekil 4, sırasıyla bir, dört ve on beş bileşenli siyah-beyaz bir kareyi geri yüklemenin sonucunu gösterir.
5. Görüntü sıkıştırma üzerindeki ana çalışmayı tamamladıktan sonra, diğer dönüşümler ikincil görevlere indirgenir: kalan bileşenler sırayla toplaöyle bir şekilde ki, önce büyük parçalardan sorumlu olanlar, sonra - tüm küçük parçalar için. Resme bakarsanız, kodlayıcının hareketi zikzak bir çizgi gibi görünüyor. Aşama ZigZag olarak adlandırılır (Şekil 5).
 |
| 5 |
Daha sonra elde edilen dizi sıkıştırılır: önce normal RLE ile, sonra Huffman yöntemiyle.
6. Son olarak, temiz teknik aşama- veriler, görüntünün geri yüklenebilmesi için tüm sıkıştırma parametrelerini gösteren bir başlık ile sağlanan bir kabuk içine alınır. Ancak bazen bu bilgiler başlıklarda yer almaz, bu da sıkıştırmada ek bir kazanç sağlar, ancak bu durumda dosyayı okuyacak uygulamanın bunları bildiğinden emin olmanız gerekir.
Genel olarak, tüm dönüşümler budur. Şimdi örneğimizde ne kadar sıkıştırma yapıldığını hesaplayalım. Orijinal 8x8 görüntüyü geri yüklemek için kullanılacak 7 değerimiz var. Böylece, her iki renk kanalında da DCT-dönüştürme kullanımından kaynaklanan sıkıştırma 8x8 / 7 9 kat olmuştur. Kanala parlaklığı yedi değil, 8x8 / 11 verecek 11 katsayı atayalım. Her üç kanal için de (9 + 9 + 6) / 3 = 8 kez çıkacaktır. İkinci aşamada meydana gelen görüntünün "kırılması" sırasında kalitenin düşürülmesi, ek bir çift artış sağlar (parlaklık bileşeninin kodlamasının özelliklerini dikkate alarak şema 4-1-1), nihai sonuç - 16 kez. Bu, bazı yönleri dikkate almayan, ancak gerçek resmi yansıtan kaba bir tahmindir. Dosya boyutunda otuz kat azalma elde etmek için yalnızca 3-4 bileşen bırakmanız gerekir.
Görüntü yeniden oluşturma işlemi ters sırada ilerler: ilk olarak, bileşenler niceleme tablosundaki değerlerle çarpılır ve ters kosinüs dönüşümü için yaklaşık katsayılar elde edilir. Sıkıştırma sırasında kalite ne kadar iyi seçilirse, orijinal oranlara yakınlık derecesi o kadar yüksek olur, bu da görüntünün daha doğru şekilde geri yükleneceği anlamına gelir. Geriye sadece bir eylem eklemek kalıyor: bitişten hemen önce, aralarındaki keskin farkları ortadan kaldırmak için komşu bloklardan kenar piksellerinde bazı ayarlamalar (gürültü) yapın.
JPEG'in dezavantajları
- Blok boyutu sınırlaması (sadece 8x8) nedeniyle yüksek sıkıştırma oranlarına ulaşılamaması.
- Yüksek sıkıştırma oranlarında bloklu yapı.
- Bir görüntüdeki keskin köşeleri yuvarlama ve ince öğeleri bulanıklaştırma.
- Yalnızca RGB görüntüleri desteklenir (CMYK görüntüleri için JPEG yalnızca EPS formatı DCS aracılığıyla).
- Resim tamamen yüklenene kadar görüntülenemez.
JPEG'in standart olarak onaylanmasından bu yana on yıl geçti. Bu süre zarfında, araştırma ekipleri orijinal versiyona bir dizi önemli eklemeler önerdiler ve bu da geçen yılın sonunda yeni bir standardın ortaya çıkmasıyla sonuçlandı.
JPEG2000
1997 yılından itibaren iş yaratmaya başlamıştır. evrensel sistem JPEG tarafından dayatılan tüm kısıtlamaları ortadan kaldıracak ve her tür görüntüyle etkili bir şekilde çalışabilecek kodlama: siyah beyaz, gri tonlamalı, tam renkli ve çok bileşenli ve içerikten bağımsız olarak (fotoğraflar, yeterince küçük metin veya çizimler olsun) . Gelişiminde, uluslararası standardizasyon kuruluşları ile birlikte Agfa, Canon, Fujifilm, Hewlett-Packard, Kodak, LuraTech, Motorola, Ricoh, Sony vb.
Yeni algoritmanın evrensel olduğu iddia edildiğinden, özellikle multimedya uygulamalarında, örneğin İnternet üzerinden gerçek zamanlı yayınlarda kritik olan çeşitli veri iletimi yöntemlerini (gerçek zamanlı ve dar bir bant genişliğiyle) kullanmakla görevlendirildi. .
JPEG2000 formatı için temel gereksinimler:
- JPEG'e kıyasla daha yüksek bir sıkıştırma derecesinin elde edilmesi.
- Görüntüleri metinle sıkıştırmak için kullanılmasına izin verecek tek renkli görüntüler için destek.
- Sıkıştırma olasılığı genellikle kayıpsızdır.
- Görüntüleri aşamalı olarak iyileştirilmiş ayrıntılarla çıktılayın (aşamalı GIF gibi).
- Kalitenin görüntünün geri kalanından daha yüksek ayarlanabileceği görüntüde öncelikli alanların kullanılması.
- Gerçek zamanlı kod çözme (gecikme yok).
Sıkıştırma prensibi
JPEG2000'deki ana sıkıştırma mekanizması, JPEG'den farklı olarak, tüm görüntüye uygulanan bir filtre sistemi olan bir dalgacık dönüşümü kullanır. Sıkıştırmanın ayrıntılarına girmeden sadece ana noktalara değineceğiz.
 |
| 6 |
Örneğin, satırlar ve satırlar (sol üst) tarafından düşük frekanslı filtrelemeden sonra elde edilen bir görüntü en fazla miktarda bilgiyi taşır ve yüksek frekanslı filtrelemeden sonra elde edilen görüntü minimum bilgiyi taşır. Satırların alçak geçiren filtrelemesinden ve sütunlar için yüksek geçiren filtrelemeden (ve tersi) sonra elde edilen görüntülerin bilgi içeriği ortalamadır. En bilgilendirici görüntü yeniden filtrelenir ve elde edilen bileşenler jpeg sıkıştırmasında olduğu gibi nicelenir. Bu birkaç kez olur: kayıpsız sıkıştırma için, döngü genellikle kayıplarla 3 kez tekrarlanır - 10 yineleme boyut, kalite ve açma hızı arasında makul bir uzlaşma olarak kabul edilir. Sonuç, küçük bir görüntü ve ince ayrıntılara sahip bir dizi resim, sırayla ve belirli bir doğrulukla, normal boyutuna geri yüklenir. Açıkçası, daha fazla döngü ayarlanabildiğinden, en büyük sıkıştırma büyük görüntülerde elde edilir.
Pratik uygulama
JPEG2000 sıkıştırmasının temelleri atıldığından beri, bir dizi şirket uygulanması için oldukça etkili algoritmalar geliştirdi.
Başlıca yazılım geliştiricileri arasında Corel'in not edilebilir (bu arada, onur ve övüldüğü paketlerinde dalga dönüşümlerine dayalı wi formatı desteğini ilk sunanlardan biriydi) - tüm görüntüler CD'lerde sağlandı. CorelDRAW paketi ile dokuzuncu sürüme kadar bu şekilde sıkıştırılmıştır.
Daha sonra, Adobe onu çekti. JPEG2000'de bulunan bazı fikirler, Photoshop 6 geliştiricileri tarafından bir görüntüyü JPEG formatında kaydederken (geleneksel, kosinüs dönüşümüne dayalı) gelişmiş seçenekler şeklinde uygulandı. Bunların arasında aşamalı JPEG (Kaydet penceresindeki Aşamalı parametre Web için). Bu algoritma öncelikle gerçek zamanlı sistemler için tasarlanmıştır ve aşamalı GIF ile aynı şekilde çalışır. İlk olarak, yalnızca birkaç büyük bloktan oluşan görüntünün kaba bir kopyası belirir ve zamanla, verilerin geri kalanı yüklendiğinde, yapı giderek daha net bir şekilde görüntülenmeye başlar, sonunda nihai görüntü elde edilene kadar. tamamen restore edildi. GIF'den farklı olarak, bu algoritma, iletilen her sürüm için tüm dönüştürme döngüsünü tamamlaması gerekeceğinden görüntüleyici üzerinde ağır bir yük oluşturur.
Diğer eklemeler arasında, değişen derecelerde sıkıştırma, çözünürlük ve hatta renk modelleri olan birkaç JPEG sıkıştırılmış görüntünün dosyasına dahil edilmesi yer alır. Buna göre, Photoshop 6'da görüntüdeki tek tek alanları seçmek ve onlar için diğer sıkıştırma ayarlarını uygulamak mümkün hale geldi ( İlgi Alanı, ilk kez böyle bir mekanizma 1995'te önerildi), daha fazlasını kullanarak düşük değerler nicemleme tablosunda. Bunu yapmak için gerekli alanı ayarlayın (örneğin, görüntüde yeni bir kanal şeklinde) ve Kalite öğesinin yanındaki maske simgesine tıklayın. Görünen pencerede, kaydırıcıları hareket ettirerek görüntü ile deney yapabilirsiniz - bitmiş sonuç ekranda görüntülenerek kalite ve boyut arasında gerekli uzlaşmayı hızlı bir şekilde bulmanızı sağlar.
Özel dönüştürücüler ve görüntüleyiciler
Standart, sıkıştırma/açma yöntemlerinin belirli uygulamalarını şart koşmadığından, bu, üçüncü taraf geliştiriciler sıkıştırma algoritmaları Aslında, basitleştirilmiş bir dalga dönüştürme algoritması kullanabilir ve böylece sıkıştırma işlemini hızlandırabilir veya tersine daha karmaşık bir tane uygulayabilirsiniz ve buna bağlı olarak daha fazla sistem kaynağı gerektirir.
Diğer şirketlerden özelleştirilmiş çözümler şu şekilde mevcuttur: ticari gelişmeler... Bazıları şu şekilde uygulanmaktadır: bireysel programlar(Aware tarafından geliştirilen JPEG 2000), diğerleri - en yaygın bitmap düzenleyicileri için ek modüller şeklinde (Pegasus Imaging tarafından geliştirilen ImagePress JPEG2000 ve LEAD Technologies'den LEAD JPEG2000 modülü). Bu konuyla uzun süredir uğraşan LuraTech, arka planlarında öne çıkıyor. LuraWave teknolojisini bağımsız ürün LuraWave SmartCompress'te (üçüncü sürüm zaten mevcuttur) teşvik eder ve Photoshop, Paintshop, Photopaint için modüller sunar. Ayırt edici özellik- daha fazla yüksek hız birkaç megabayt boyutunda resimlerle bile çalışır (neredeyse anında dönüştürme). Buna göre, bu modülün fiyatı en yüksek - 79 dolar.
JPEG2000 görüntülerini tarayıcılarda görüntülemek için özel bir görüntüleme modülü yüklemeniz gerekir (tüm geliştiriciler bunu ücretsiz olarak sunar). Herhangi bir eklenti gibi bir html belgesine bir resim eklemek, EMBED yapısını (ek parametrelerle) kullanmaya gelir. Örneğin, aşamalı bir görüntü aktarım yönteminin kullanılacağı anlamına gelir. Yani, örneğimizde (139 KB boyutunda bir dosya), ilk önce kaba bir görüntünün oluşturulacağı yalnızca 250 bayt aktarılır, ardından 500 bayt yüklendikten sonra görüntü güncellenir ( bu, LIMIT değerine ulaşılana kadar devam eder).
Daha iyi bir görüntü elde etmek istiyorsanız sağ tuş ile açılan menüden İyileştir seçeneğini seçmeniz gerekmektedir (Şekil 9). Dört indirmede, görüntünün tamamı tam olarak yüklenecektir.
 |
| 9 |
sonuçlar
Bu nedenle, JPEG2000, yalnızca yüksek sıkıştırma oranlarında objektif olarak JPEG'den daha iyi sonuçlar verir. 10-20 kez sıkıştırıldığında pek bir fark yoktur. Yaygın formatın yerini alabilecek mi yoksa basitçe rekabet edebilecek mi? Yakın gelecekte - pek olası değil, çoğu durumda JPEG tarafından sağlanan kalite / boyut oranı oldukça kabul edilebilir. Ve JPEG2000'in görsel olarak aynı kalitede sağladığı %10-20'lik ek sıkıştırmanın popülaritesini artırması pek olası değildir.
Öte yandan, ışığa duyarlı matrislerin boyutu her yıl düzenli olarak arttığından ve görüntüleri belleğe yerleştirmek giderek zorlaştığından, dijital kamera üreten şirketler yeni formata büyük ilgi gösteriyor. Ve sonra yeni format daha yaygın hale gelecek ve kim bilir, belki bir süre sonra JPEG2000, JPEG'e eşit olacak. Her neyse, Analog Micro Devices yakın zamanda sıkıştırma/açma işlemi yapan özel bir çip yayınladı. yeni teknoloji donanım düzeyinde uygulandı ve ABD Savunma Bakanlığı, casus uydulardan alınan fotoğrafları kaydetmek için yeni formatı aktif olarak kullanıyor.
Gerçekler ve varsayımlar
1.JPEG açıldığında kalitesini kaybeder ve yeniden kaydetme dosya.
Doğru değil. Kalite, yalnızca görüntünün kaydedildiği sıkıştırma oranından daha düşük bir sıkıştırma oranı seçildiğinde kaybolur.
2. JPEG, bir dosyayı düzenlerken kalitesini kaybeder.
Hakikat. Değiştirilen dosyayı kaydettiğinizde, tüm dönüştürmeler yeniden gerçekleştirilir - bu nedenle sık sık görüntü düzenlemesinden kaçının. Bu sadece dosya kapatıldığında geçerlidir; dosya açık kalırsa endişeye mahal yoktur.
3. Farklı programlarda aynı parametrelerle sıkıştırmanın sonucu aynı olacaktır.
Doğru değil. Farklı programlar, kullanıcı tarafından girilen değerleri farklı yorumlar. Örneğin, bir programda kaydedilen görüntünün kalitesi (örneğin Photoshop'ta olduğu gibi), diğerinde - sıkıştırma derecesi (karşılıklı) belirtilir.
4. Maksimum kaliteye ayarlandığında, görüntü kalitesinde herhangi bir kayıp olmadan kaydedilir.
Doğru değil. JPEG her zaman kayıpla sıkıştırır. Ancak, örneğin %100 yerine %90 kalite ayarı, algılanan kalite düşüşünden daha büyük bir dosya boyutu küçültmesiyle sonuçlanır.
5. Herhangi bir JPEG dosyası, JPEG formatını anlayan herhangi bir düzenleyicide açılabilir.
Doğru değil. Bu tür JPEG, aşamalı olarak (JPEG) bazı editörler tarafından anlaşılmamaktadır.
6. JPEG şeffaflığı desteklemez.
Hakikat. Bazen görüntünün bir kısmı saydam gibi görünebilir, ancak aslında rengi html sayfasındaki arka plan rengiyle eşleşecek şekilde seçilir.
7. JPEG, GIF'den daha iyi sıkıştırır.
Doğru değil. Farklı uygulama alanlarına sahiptirler. Genel olarak, JPEG'e dönüştürdükten sonra tipik bir GIF görüntüsü daha büyük bir boyuta sahip olacaktır.
JPEG2000 ve JPEG
| 7 |
2. Daha yüksek sıkıştırma ile, JPEG2000'in kalitesi, JPEG'den önemli ölçüde daha yüksektir, bu da fazla kayıp olmadan 50 kata kadar ve biraz kayıpla (İnternet için görüntülerden bahsediyoruz) - 100'e kadar ve hatta daha fazla sıkıştırmasına izin verir. 200'e kadar.
3. Düzgün bir renk değişiminin olduğu alanlarda yüksek sıkıştırma oranları ile görüntü, basit bir JPEG için tipik olan bloklu yapıyı elde etmez. JPEG2000 ayrıca keskin kenarları hafifçe lekeliyor ve yuvarlatıyor - fotoğraflara bakın (Şek. 7 ve 8).
Farklı sıkıştırma derecelerine sahip bir test dosyasının sıkıştırma sonuçlarını gösterir (solda - Photoshop'ta JPG formatı, sağda - JPEG2000 formatında). Şekildeki görüntü için 7, 20, 40, 70 ve 145 sıkıştırma oranları seçilmiştir (JPEG2000'de kaydedilirken açıkça belirtilebilirler), derece JPG sıkıştırma dosya boyutu JPEG2000 tarafından sıkıştırıldıktan sonrakiyle aynı olacak şekilde seçildi. Dedikleri gibi, sonuçlar açıktır. Netlik için, görüntü üzerinde daha keskin ayrıntılara sahip (10, 20, 40 ve 80 sıkıştırma oranlarıyla) ikinci bir deney yapıldı. Avantaj yine JPEG2000 tarafındadır (Şekil 8).
 |
| 8 |
4. Aslında, farklı çözünürlükteki kopyalar tek bir JPEG2000 dosyasında saklandığından
Yani internette resim galerileri oluşturanlar için küçük resimler oluşturmaya gerek yoktur.
5. Bozulma olmadan sıkıştırma (kayıpsız mod) özellikle ilgi çekicidir. Böylece, Photoshop'tan LZW sıkıştırmalı test dosyası 827 KB ve sıkıştırılmış JPEG2000 - 473 KB aldı.
6. JPEG ile karşılaştırıldığında, daha gelişmiş adaşı, önemli ölçüde daha fazla sistem kaynağı tüketir. Ancak son birkaç yılda önemli ölçüde artan bilgisayarların gücü, görüntü sıkıştırma sorunlarını yeni bir yöntemle başarılı bir şekilde çözmeyi mümkün kılıyor.
7. Tarayıcılarda JPEG2000 desteği eksikliği. Bu tür görüntüleri görüntülemek için oldukça büyük bir eklenti modülü (1.2 MB) indirmeniz gerekir.
8. Görüntüleri yeni biçimde kaydetmek için ücretsiz yazılım eksikliği.
Serbestçe erişilebilen dergiler.
Aynı konuda:
.jpg)
- öğretici

Bunun JPEG algoritmasının tamamen sıradan bir açıklaması olmadığını başlıktan doğru anladınız (dosya formatını "aptallar için JPEG kod çözme" makalesinde ayrıntılı olarak açıkladım). Her şeyden önce, materyali sunmanın seçilen yolu, yalnızca JPEG hakkında değil, aynı zamanda Fourier dönüşümü ve Huffman kodlaması hakkında da hiçbir şey bilmediğimizi varsayar. Ve genel olarak, derslerden pek bir şey hatırlamıyoruz. Sadece bir fotoğraf çektiler ve nasıl sıkıştırılabileceğini düşünmeye başladılar. Bu nedenle, yalnızca özü erişilebilir bir şekilde ifade etmeye çalıştım, ancak okuyucunun algoritma hakkında yeterince derin ve en önemlisi sezgisel bir anlayış geliştireceği. Formüller ve matematiksel hesaplamalar - en azından, sadece neler olduğunu anlamak için önemli olanlar.
JPEG algoritmasını bilmek, görüntüleri sıkıştırmaktan daha fazlası için çok yararlıdır. Dijital sinyal işleme teorisini kullanır, matematiksel analiz, lineer cebir, bilgi teorisi, özellikle Fourier dönüşümü, kayıpsız kodlama vb. Bu nedenle, kazanılan bilgiler her yerde faydalı olabilir.
Dilerseniz yazıya paralel olarak aynı adımları tek başınıza da uygulamanızı öneririm. Yukarıdaki mantığın farklı görüntüler için ne kadar uygun olduğunu kontrol edin, algoritmada kendi değişikliklerinizi yapmaya çalışın. Çok ilginç. Araç olarak harika bir Python + NumPy + Matplotlib + PIL (Yastık) kombinasyonu önerebilirim. Neredeyse tüm çalışmalarım (grafikler ve animasyon dahil) bunları kullanarak yapıldı.
Dikkat, trafik! Çok sayıda illüstrasyon, grafik ve animasyon (~ 10Mb). İronik olarak, JPEG ile ilgili makalede elliden bu formatta sadece 2 resim var.
Bilgi sıkıştırma algoritması ne olursa olsun, prensibi her zaman aynı olacaktır - kalıpları bulma ve tanımlama. Daha fazla desen, daha fazla fazlalık, daha az bilgi. Arşivciler ve kodlayıcılar genellikle belirli bir bilgi türü için "keskinleştirilir" ve bunları nerede bulacaklarını bilirler. Bazı durumlarda, mavi gökyüzü deseni gibi desen hemen görünür. Dijital temsilinin her satırı, düz bir çizgi ile oldukça doğru bir şekilde tanımlanabilir.
Rakun kedileri üzerinde eğitim vereceğiz. Yukarıdaki gri resim örnek olarak alınmıştır. Hem homojen hem de zıt alanları iyi bir şekilde birleştirir. Ve griyi sıkıştırmayı öğrenirsek, renkle ilgili herhangi bir sorun olmayacaktır.
vektör gösterimi
İlk olarak, komşu iki pikselin ne kadar bağımlı olduğunu kontrol edelim. Büyük olasılıkla çok benzer olacaklarını varsaymak mantıklıdır. Bunu görüntünün tüm çiftleri için kontrol edelim. Onları koordinat düzleminde noktalarla işaretleyelim, böylece X ekseni boyunca noktanın değeri, Y ekseni boyunca ilk pikselin değeri - ikincisi. 256 x 256 resmimiz için 256 * 256/2 puan alıyoruz:
Noktaların çoğunun y = x doğrusu üzerinde veya yakınında olduğu tahmin edilebilir (ve tekrar tekrar birbirinin üzerine bindirildiklerinden ve ayrıca yarı saydam olduklarından, şekilde görebileceğinizden çok daha fazlası vardır) . Eğer öyleyse, onları 45 ° döndürerek çalışmak daha kolay olurdu. Bunu yapmak için onları farklı bir koordinat sisteminde ifade etmeniz gerekir.

Yeni sistemin temel vektörleri açıkça aşağıdaki gibidir: Bir ortonormal sistem elde etmek için ikiye bölmeye zorlanırlar (temel vektörlerin uzunlukları bire eşittir). Burada bir p = (x, y) noktasının yeni sistem bir nokta (a 0, a 1) olarak temsil edilecektir. Yeni katsayıları bilerek, eskileri ters döndürme ile kolayca elde edebiliriz. Açıkçası, ilk (yeni) koordinat ortalamadır ve ikincisi x ve y arasındaki farktır (ancak 2'nin köküne bölünür). Değerlerden yalnızca birini bırakmanızın istendiğini düşünün: 0 veya 1 (yani, diğerini sıfıra eşitleyin). 1'in değeri muhtemelen sıfıra yakın olacağından 0 seçmek daha iyidir. Görüntüyü yalnızca 0 ile geri yüklersek olan budur:

4x büyütme:

Dürüst olmak gerekirse, bu tür bir sıkıştırma çok etkileyici değil. Resmi aynı şekilde üçlü piksellere bölmek ve onları üç boyutlu uzayda temsil etmek daha iyidir.


Aynı grafik, ancak farklı bakış açılarından. Kırmızı çizgiler kendilerini öneren eksenlerdir. Vektörlere karşılık gelirler:. Vektörlerin uzunluklarının bire eşit olması için bazı sabitlere bölmeniz gerektiğini hatırlatmama izin verin. Böylece, böyle bir temelde genişleyerek, 0, 1, 2 ve 0, 1'den daha önemli ve 1, 2'den daha önemli 3 değer elde ederiz. 2 atarsak, grafik e 2 vektörü yönünde "düzleşir". Zaten oldukça ince olan bu üç boyutlu tabaka düz hale gelecektir. O kadar kaybetmeyecek ama değerlerin üçte birinden kurtulacağız. Üçüzler tarafından yeniden oluşturulan görüntüleri karşılaştıralım: (a 0, 0, 0), (a 1, a 2, 0) ve (a 0, a 1, a 2). V son seçenek Hiçbir şeyi atmadık, o yüzden orijinalini alacağız.

4x büyütme:

İkinci çizim zaten iyi. Keskin alanlar biraz düzeldi, ancak genel olarak resim çok iyi korunuyor. Şimdi de aynı şekilde dörde bölelim ve temeli dört boyutlu uzayda görsel olarak tanımlayalım... Ah, peki, evet. Ancak temel vektörlerden birinin ne olacağını tahmin edebilirsiniz: (1,1,1,1) / 2. Bu nedenle, diğerlerini ortaya çıkarmak için dört boyutlu uzayın vektöre (1,1,1,1) dik olan uzaya izdüşümüne bakabilirsiniz. Ama bu en iyi yol değil.
Amacımız (x 0, x 1, ..., x n-1)'in (a 0, a 1, ..., a n-1)'e nasıl dönüştürüleceğini öğrenmektir, böylece ai'nin her bir değeri daha az önemli olur. öncekilerden.... Bunu yapabilirsek, belki de dizinin son değerleri tamamen atılabilir. Yukarıdaki deneyimler bunun mümkün olduğunu ima ediyor. Ancak matematiksel bir aparat olmadan yapılamaz.
Yani, puanları yeni bir temele dönüştürmeniz gerekiyor. Ama önce uygun bir temel bulmanız gerekiyor. İlk eşleştirme deneyine geri dönelim. Genel hatlarıyla ele alacağız. Temel vektörleri tanımladık:

Onlar aracılığıyla ifade edilen vektör P:
veya koordinatlarda:

0 ve 1 bulmak için yansıtmanız gerekir Püzerinde e 0 ve e 1 sırasıyla. Ve bunun için nokta çarpımını bulmanız gerekiyor.
benzer şekilde:
Koordinatlarda:

Dönüşümü matris biçiminde gerçekleştirmek genellikle daha uygundur.

O zaman A = EX ve X = E T A. Bu güzel ve kullanışlı bir form. E matrisi dönüşüm matrisi olarak adlandırılır ve ortogonaldir, onunla daha sonra buluşacağız.
Vektörlerden fonksiyonlara geçiş.
Küçük boyutlu vektörlerle çalışmak uygundur. Bununla birlikte, desenleri büyük bloklarda bulmak istiyoruz, bu nedenle N boyutlu vektörler yerine görüntüyü temsil eden dizilerle çalışmak daha uygundur. Aşağıdaki akıl yürütme sürekli işlevlere uygulanabilir olduğundan, bu tür dizileri ayrık işlevler olarak adlandıracağım.Örneğimize dönersek, sadece iki noktada tanımlanan f(i) fonksiyonunu hayal edin: f (0) = x ve f (1) = y. Benzer şekilde, e 0 (i) ve e 1 (i) temel fonksiyonlarını da bazlara göre tanımlarız. e 0 ve e 1. Alırız:

Bu çok önemli sonuç... Şimdi "bir vektörün ortonormal vektörler cinsinden genişlemesi" ifadesinde "vektör" kelimesini "fonksiyon" ile değiştirebilir ve "bir fonksiyonun ortonormal fonksiyonlar cinsinden genişlemesi" tamamen doğru bir ifade elde edebiliriz. Bu kadar yetersiz bir fonksiyona sahip olmamızın bir önemi yok, çünkü aynı mantık N-boyutlu bir vektör için işe yarar, bu N değerleri ile ayrık bir fonksiyon olarak gösterilebilir. Ve fonksiyonlarla çalışmak, N-boyutlu vektörlerden daha açıktır. Tersine, böyle bir işlevi vektör olarak temsil edebilirsiniz. Ayrıca, sıradan bir sürekli fonksiyon, artık Öklidyen'de değil, Hilbert uzayında olsa da, sonsuz boyutlu bir vektörle temsil edilebilir. Ama oraya gitmeyeceğiz, sadece ayrık fonksiyonlarla ilgileneceğiz.
Ve bir temel bulma görevimiz, uygun bir ortonormal fonksiyonlar sistemi bulma görevine dönüşür. Aşağıdaki akıl yürütmede, bir şekilde genişleyeceğimiz bir dizi temel fonksiyon tanımladığımız varsayılmaktadır.
Diyelim ki, diğerlerinin toplamı olarak temsil etmek istediğimiz (örneğin değerlerle temsil edilen) bir fonksiyonumuz var. Bu işlemi vektör formunda gösterebilirsiniz. Bir işlevi ayrıştırmak için, onu sırayla temel işlevlere "yansıtmanız" gerekir. Vektör anlamında, izdüşüm hesaplaması, orijinal vektörün mesafe olarak diğerine minimum yaklaşımını verir. Mesafenin Pisagor teoremi kullanılarak hesaplandığı akılda tutularak, fonksiyonlar şeklinde benzer bir temsil, bir fonksiyonun diğerine en iyi ortalama kare yaklaşımını verir. Böylece, her katsayı (k), fonksiyonun "yakınlığını" belirler. Daha resmi olarak, k * e (x), l * e (x) arasında f (x)'e en iyi rms yaklaşımıdır.
Aşağıdaki örnek, sadece iki nokta kullanarak bir fonksiyona yaklaşma sürecini göstermektedir. Sağda vektör temsilidir.

Çiftlere ayırma deneyimize ilişkin olarak, bu iki noktanın (apsis üzerinde 0 ve 1) bir çift komşu piksel (x, y) olduğunu söyleyebiliriz.
Aynı, ancak animasyonlu:

3 puan alırsak, üç boyutlu vektörleri dikkate almamız gerekir, ancak yaklaşıklık daha doğru olacaktır. Ve N değerleri olan ayrık bir fonksiyon için N boyutlu vektörleri dikkate almak gerekir.
Bir dizi elde edilen katsayıya sahip olmak, kolayca elde edilebilir orijinal işlev ilgili katsayılarla alınan temel fonksiyonları toplayarak. Bu katsayıların analizi çok şey verebilir kullanışlı bilgi(temellere bağlı olarak). Bu hususların özel bir durumu, Fourier serisi genişleme ilkesidir. Sonuçta, akıl yürütmemiz herhangi bir temele uygulanabilir ve bir Fourier serisinde genişletilirken tamamen özel bir tane alınır.
Ayrık Fourier Dönüşümleri (DFT)
Bir önceki bölümde, işlevi bileşik işlevlere ayırmanın güzel olacağı sonucuna vardık. 19. yüzyılın başlarında Fourier de bunu düşündü. Doğru, rakunlu bir resmi yoktu, bu yüzden metal halka boyunca ısı dağılımını araştırmak zorunda kaldı. Daha sonra, halkanın her noktasındaki sıcaklığı (ve değişimini) farklı periyotlara sahip sinüzoidlerin toplamı olarak ifade etmenin çok uygun olduğunu buldu. "Fourier (okumanızı tavsiye ederim, ilginç) ikinci harmoniğin birinciden 4 kat daha hızlı bozulduğunu ve daha yüksek dereceli harmoniklerin daha da büyük bir hızla bozulduğunu buldu."Genel olarak, kısa süre sonra periyodik fonksiyonların dikkate değer bir şekilde sinüzoidlerin toplamına ayrıştığı ortaya çıktı. Ve doğada periyodik fonksiyonlarla tanımlanan birçok nesne ve süreç olduğundan, bunların analizi için güçlü bir araç ortaya çıkmıştır.
Belki de en görünür periyodik süreçlerden biri sestir.

- 1. grafik - 2500 hertz'de saf ton.
- 2. - Beyaz gürültü... Yani, tüm aralıkta eşit olarak dağıtılmış frekanslara sahip gürültü.
- 3 - ilk ikisinin toplamı.
Neden sinüzoidleri temel almayı denemiyorsunuz? Aslında, aslında zaten yaptık. 3 temel vektöre ayrıştırmamızı hatırlayalım ve bunları grafikte gösterelim:

Evet, evet, uygun göründüğünü biliyorum ama üç vektörle daha fazlasını beklemek zor. Ancak şimdi örneğin 8 temel vektörün nasıl elde edileceği açık:

Basit bir kontrol, bu vektörlerin ikili olarak dik, yani ortogonal olduğunu gösterir. Bu, temel olarak kullanılabilecekleri anlamına gelir. Böyle bir temelde dönüşüm yaygın olarak bilinir ve ayrık kosinüs dönüşümü (DCT) olarak adlandırılır. Verilen grafiklerden DCT dönüşüm formülünün nasıl elde edildiğinin açık olduğunu düşünüyorum:
Hâlâ aynı formül: A = EX, ikame esaslı. Belirtilen DCT'nin temel vektörleri (aynı zamanda E matrisinin satır vektörleridir) ortogonaldir, ancak ortonormal değildir. Ters dönüşüm sırasında bu hatırlanmalıdır (bunun üzerinde durmayacağım, ancak kimin ilgileneceği - sıfır temel vektörü diğerlerinden daha büyük olduğu için ters DCT'de 0,5 * a 0 terimi görünür).
Aşağıdaki örnek, değişen toplamları orijinal değerlere yaklaştırma sürecini göstermektedir. Her yinelemede, bir sonraki temel bir sonraki katsayı ile çarpılır ve ara toplama eklenir (yani, rakun üzerindeki erken deneylerde olduğu gibi - değerlerin üçte biri, üçte ikisi).

Ancak, yine de, böyle bir temeli seçmenin tavsiye edilebilirliği hakkında bazı tartışmalara rağmen, hala gerçek bir argüman yoktur. Gerçekten de, sesten farklı olarak, bir görüntüyü periyodik fonksiyonlara ayırmanın yararı çok daha az açıktır. Bununla birlikte, görüntü küçük bir alanda bile gerçekten çok tahmin edilemez olabilir. Bu nedenle, resim yeterince küçük parçalara bölünür, ancak ayrıştırmanın bir anlam ifade etmesi için çok da küçük değildir. V JPEG resmi 8x8 kareler halinde "Kes". Böyle bir parça içinde, fotoğraflar genellikle çok tekdüzedir: arka plan artı hafif dalgalanmalar. Bu tür alanlara sinüzoidler tarafından akıllıca yaklaşılır.
Bu gerçeğin az çok sezgisel olduğunu varsayalım. Ancak keskin renk geçişleri konusunda kötü bir his var çünkü yavaş değişen işlevler bizi kurtarmaz. İşlerini yapan, ancak tek tip bir arka planda yan olarak görünen çeşitli yüksek frekanslı işlevler eklememiz gerekiyor. İki zıt alanla 256x256 bir görüntü çekin:

Her satırı DCT kullanarak ayrıştıralım, böylece satır başına 256 katsayı elde edelim.
O zaman sadece ilk n katsayıları bırakacağız ve gerisini sıfıra eşitleyeceğiz ve bu nedenle görüntü sadece ilk harmoniklerin toplamı olarak sunulacak:

Resimdeki sayı kalan bahis sayısıdır. İlk resimde sadece ortalama kaldı. İkinciye bir düşük frekanslı sinüzoid zaten eklendi, vb. Bu arada, sınıra dikkat edin - tüm daha iyi yaklaşımlara rağmen, diyagonalin yanında 2 şerit açıkça görülebilir, biri daha hafif, diğeri daha koyu. Bölüm son resim 4 kat arttı:
Ve genel olarak, sınırdan uzakta ilk düzgün arka planı görürsek, ona yaklaşırken genlik büyümeye başlar, sonunda minimum değere ulaşır ve sonra keskin bir şekilde maksimum olur. Bu fenomen Gibbs etkisi olarak bilinir.

Fonksiyonun süreksizliklerinin yakınında ortaya çıkan bu tümseklerin yüksekliği, fonksiyonlardaki terim sayısı arttıkça azalmayacaktır. Kesikli bir dönüşümde, yalnızca hemen hemen tüm katsayılar korunursa kaybolur. Daha doğrusu görünmez olur.
Bir sonraki örnek, yukarıdaki üçgen ayrışmasına tamamen benzer, ancak gerçek bir rakun üzerinde:

DCT çalışırken, yalnızca birkaç ilk (düşük frekans) katsayısının her zaman yeterli olduğu gibi yanlış bir izlenim edinebilirsiniz. Bu, değerleri önemli ölçüde değişmeyen birçok fotoğraf için geçerlidir. Bununla birlikte, zıt alanların sınırında, değerler hızlı bir şekilde "atlayacak" ve son katsayılar bile büyük olacaktır. Bu nedenle, DCT'nin enerji tasarrufu özelliğini duyduğunuzda, bunun karşılaşılan birçok sinyal türü için geçerli olduğu, ancak tümü için geçerli olmadığı gerçeğini dikkate alın. Örneğin, genişleme katsayıları sonuncusu hariç sıfıra eşit olan ayrık bir fonksiyonun nasıl görüneceğini düşünün. İpucu: Ayrışmayı vektör biçiminde hayal edin.
Eksikliklere rağmen, seçilen temel, gerçek fotoğrafların en iyilerinden biridir. Biraz sonra diğerleriyle küçük bir karşılaştırma göreceğiz.
DCT vs her şey
Ortogonal dönüşümler konusunu incelediğimde, dürüst olmak gerekirse, etraftaki her şeyin harmonik salınımların toplamı olduğu argümanlarına pek ikna olmadım, bu nedenle resimleri sinüzoidlere ayırmak gerekiyor. Ya da belki bazı adım işlevleri daha iyidir? Bu nedenle, gerçek görüntüler üzerinde DCT'nin optimalliği ile ilgili çalışmaların sonuçlarını arıyordum. "Enerji yoğunlaştırma" özelliğinden dolayı pratik uygulamalarda en sık bulunanın DCT olduğu gerçeği her yerde yazılmıştır. Bu özellik şu anlama gelir en yüksek miktar bilgiler ilk katsayılarda bulunur. Ve neden? Bir araştırma yapmak zor değil: Kendimizi bir sürü farklı resim, bilinen çeşitli temellerle donatıyoruz ve gerçek görüntüden standart sapmayı hesaplamaya başlıyoruz. farklı miktarlar katsayılar. Bu teknikle ilgili makalede (kullanılan resimler) küçük bir araştırma buldum. Depolanan enerjinin farklı bazlarda ilk genişleme katsayılarının sayısına bağımlılığının grafiklerini gösterir. Tablolara bakarsanız, DCT'nin sürekli olarak onurlu ... um ... 3. sırayı aldığına ikna oldunuz. Nasıl yani? KLT dönüşümü nedir? DCT'yi övüyordum, ama burada ...KLT
KLT dışındaki tüm dönüşümler sabit tabanlı dönüşümlerdir. Ve KLT'de (Karunen-Loeve dönüşümü) birkaç vektör için en uygun temel hesaplanır. İlk katsayılar tüm vektörler için toplamda en küçük ortalama karekök hatasını verecek şekilde hesaplanır. Benzer bir çalışmayı daha önce manuel olarak yaparak temeli görsel olarak tanımladık. İlk başta mantıklı bir fikir gibi görünüyor. Örneğin, görüntüyü küçük bölümlere ayırabilir ve her biri için farklı bir temel hesaplayabiliriz. Ancak sadece bu temeli saklama endişesi ortaya çıkmakla kalmıyor, aynı zamanda onu hesaplama işlemi de oldukça zahmetli. Ve DCT sadece biraz kaybeder ve ayrıca DCT'nin hızlı dönüştürme algoritmaları vardır.DFT
DFT (Ayrık Fourier Dönüşümü) - Ayrık Fourier Dönüşümü. Bu ad bazen yalnızca belirli bir dönüşüme değil, aynı zamanda tüm ayrık dönüşümler sınıfına da atıfta bulunur (DCT, DST ...). DFT formülüne bakalım:
Tahmin edebileceğiniz gibi, bu bir tür karmaşık temele sahip ortogonal bir dönüşümdür. Böyle karmaşık bir form her zamankinden biraz daha sık meydana geldiğinden, sonucunu incelemek mantıklıdır.
DCT ayrıştırıldığında herhangi bir saf harmonik sinyalin (bir tamsayı frekansı ile) bu harmoniğe karşılık gelen yalnızca bir sıfır olmayan katsayı vereceği görünebilir. Durum böyle değil, çünkü frekansa ek olarak bu sinyalin fazı da önemlidir. Örneğin, sinüsün kosinüs cinsinden genişlemesi (ayrık genişlemeye benzer şekilde) aşağıdaki gibi olacaktır:
Saf bir armonika için çok fazla. Bir sürü başkalarını doğurdu. Animasyon, bir sinüzoidin DCT katsayılarını farklı fazlarda gösterir.
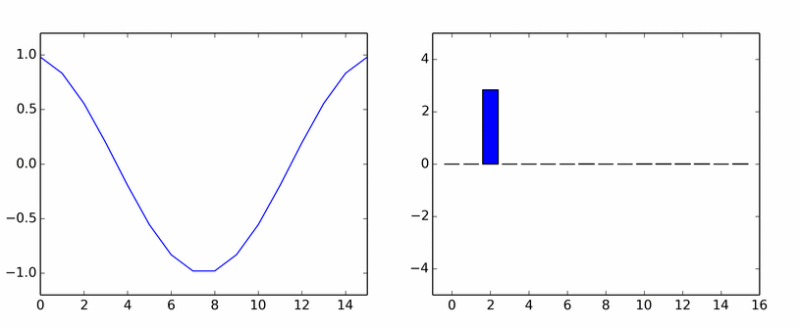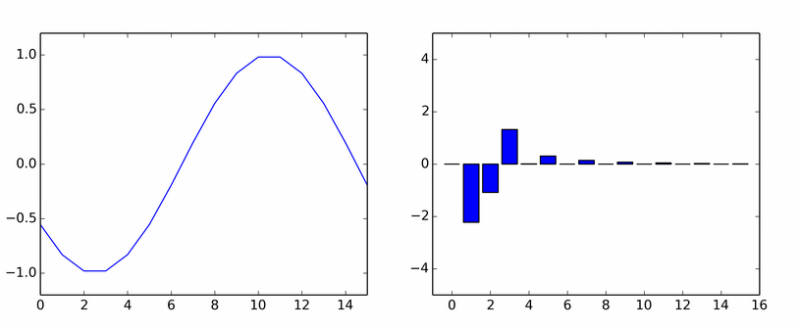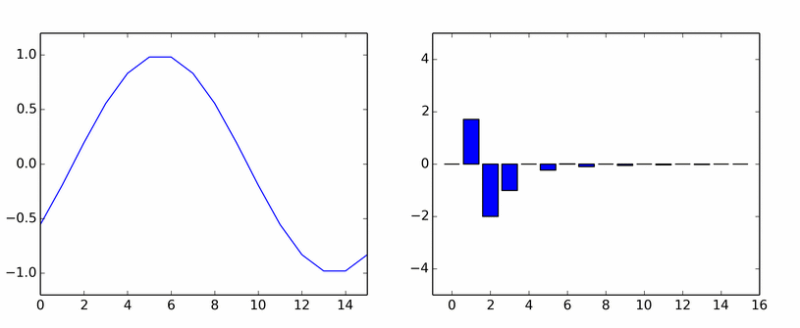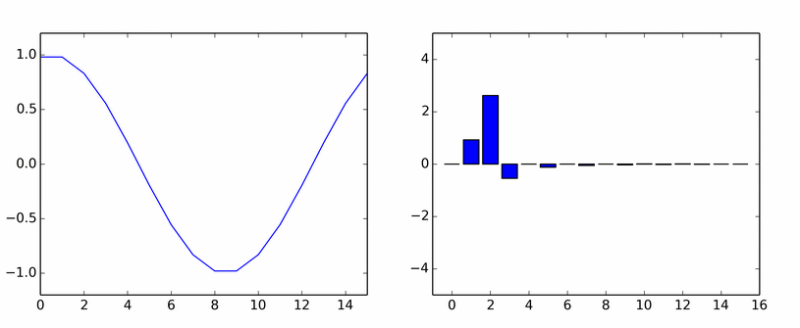
Sütunların eksen etrafında döndüğü size göründüyse, o zaman size görünmüyordu.
Şimdi fonksiyonu, sadece farklı frekanslardaki değil, aynı zamanda bazı fazlarda kaydırılan sinüzoidlerin toplamına ayrıştıracağız. Bir kosinüs örneğini kullanarak faz kaymasını düşünmek daha uygun olacaktır:
Basit bir trigonometrik özdeşlik önemli bir sonuç verir: faz kayması, cos (b) ve sin (b) katsayıları ile alınan sinüs ve kosinüs toplamı ile değiştirilir. Bu, fonksiyonları sinüs ve kosinüs toplamına (fazsız) ayırabileceğiniz anlamına gelir. Bu yaygın bir trigonometrik formdur. Bununla birlikte, karmaşık çok daha sık kullanılır. Bunu elde etmek için Euler formülünü kullanmanız gerekir. Sinüs ve kosinüs için formülün türevlerini yerine koyarsak şunu elde ederiz:

Şimdi küçük bir yedek. Alt çizgi bir eşlenik sayıdır.
Son eşitliği elde ederiz:
c - gerçek kısmı kosinüs katsayısına eşit olan karmaşık katsayı ve hayali kısım sinüs katsayısına eşittir. Ve (cos (b), sin (b)) noktaları kümesi bir dairedir. Böyle bir kayıtta, her harmonik hem pozitif hem de negatif frekanslarla ayrışmaya girer. Bu nedenle, Fourier analizinin çeşitli formüllerinde, toplama veya entegrasyon genellikle eksiden artı sonsuza kadar gerçekleşir. Bu karmaşık biçimde hesaplamalar yapmak genellikle daha uygundur.
Dönüştürme, sinyali sinyal alanında birden fazla salınım frekansına sahip harmoniklere ayrıştırır. Ancak sinyal alanında örnekleme oranı N'dir. Ve Kotelnikov teoremine göre (diğer adıyla Nyquist - Shannon teoremi), örnekleme frekansı, sinyal frekansının en az iki katı olmalıdır. Durum böyle değilse, yanlış frekanslı bir sinyalin görünümünün etkisi elde edilir:

Kesikli çizgi, yanlış yeniden oluşturulmuş bir sinyali gösterir. Hayatınızda sık sık böyle bir fenomenle karşılaştınız. Örneğin, bir videoda bir arabanın tekerleklerinin komik bir hareketi veya hare efekti.
Bu, N karmaşık genliklerinin ikinci yarısının diğer frekanslardan oluştuğunu gösterir. İkinci yarının bu sahte harmonikleri yansıtma ilk ve ek bilgi taşımayın. Böylece elimizde N / 2 kosinüs ve N / 2 sinüs (dik bir temel oluşturan) kalır.
Tamam, bir temeli var. Bileşenleri, sinyal bölgesinde tam sayıda salınımlara sahip harmoniklerdir, bu, harmoniklerin aşırı değerlerinin eşit olduğu anlamına gelir. Daha doğrusu, son değer tam olarak kenardan alınmadığından neredeyse eşittirler. Ayrıca, her harmonik, merkezi etrafında neredeyse ayna simetriktir. Tüm bu fenomenler, kodlama yaparken bizim için önemli olan düşük frekanslarda özellikle güçlüdür. Bu da kötü çünkü sıkıştırılmış görüntü blokların sınırları görünür olacaktır. DFT tabanını N = 8 ile göstereceğim. İlk 2 satır kosinüs bileşenleridir, sonuncusu sinüs bileşenleridir:

Artan sıklıkta bileşenlerin kopyalarının görünümüne dikkat edin.
Değerleri başlangıçtaki maksimum değerden sonunda minimum değere yumuşak bir şekilde düşen bir sinyalin nasıl ayrıştırılabileceğini zihinsel olarak düşünebilirsiniz. Sadece sona daha yakın olan harmonikler, bizim için pek büyük olmayan, aşağı yukarı yeterli bir yaklaşım yapabilir. Soldaki şekil, tek uçlu bir sinyalin bir tahminidir. Sağda - simetrik: 
İlkinde, işler son derece kötü.
Yani DCT'de olduğu gibi yapılabilir - frekansları 2 veya daha fazla kez azaltmak, böylece bazı salınımların sayısı kesirli ve sınırlar farklı fazlarda mı? O zaman bileşenler ortogonal olmayacak. Ve bu konuda yapabileceğin hiçbir şey yok.
DST
DCT'de kosinüsler yerine sinüsler kullanılırsa ne olur? Ayrık Sinüs Dönüşümü (DST) elde ederiz. Ancak bizim problemimiz için, sinüslerin periyotlarının tamamı ve yarısı sınırlarda sıfıra yakın olduğu için hepsi ilginç değil. Yani, DFT'dekiyle yaklaşık olarak aynı uygunsuz ayrıştırmayı elde ederiz.DCT'ye dönüş
Sınırlarda durumu nasıl? İyi. Antifazlar var ve sıfır yok.Tüm kalan
Fourier olmayan dönüşüm. tarif etmeyeceğim.WHT - Matris, yalnızca -1 ve 1 değerlerine sahip kademeli bileşenlerden oluşur.
Haar aynı zamanda bir ortogonal dalgacık dönüşümüdür.
DCT'den daha düşüktürler, ancak hesaplanması daha kolaydır.
Yani, kendi dönüşümünüzü yaratmak için bir fikriniz var. Hatırla bunu:
- Temel ortogonal olmalıdır.
- Sabit bir taban çizgisiyle, sıkıştırma kalitesinde KLT'yi geçemezsiniz. Bu arada, gerçek fotoğraflarda DCT neredeyse elde ettiği kadar iyidir.
- Örnek olarak DFT ve DST ile sınırları hatırlamanız gerekir.
- Ve DCT'nin başka bir iyi avantajı olduğunu unutmayın - bileşenlerinin sınırlarına yakın, türevleri sıfıra eşittir, bu da bitişik bloklar arasındaki geçişin oldukça düzgün olacağı anlamına gelir.
- Fourier dönüşümleri, kafa kafaya hesaplamanın aksine O (N * logN) karmaşıklığına sahip hızlı algoritmalara sahiptir: O (N 2).
İki boyutlu dönüşümler
Şimdi böyle bir deney yapmaya çalışalım. Örneğin, bir görüntü dilimi alın.
3D grafiği:

Her satır için DCT'yi (N = 32) inceleyelim:

Şimdi, elde edilen katsayıların her bir sütununda, yani yukarıdan aşağıya doğru gözlerinizi gezdirmenizi istiyorum. Unutmayın ki amacımız mümkün olduğunca ayrılmak daha az değer, önemsiz olanları kaldırarak. Muhtemelen elde edilen katsayıların her bir sütununun değerlerinin, orijinal görüntünün değerleriyle aynı şekilde ayrıştırılabileceğini tahmin etmişsinizdir. Ortogonal dönüşüm matrisi seçiminde bizi kimse sınırlamaz, ancak bunu DCT (N = 8) ile tekrar yapacağız:

Katsayının (0,0) çok büyük olduğu ortaya çıktı, bu nedenle grafikte 4 kat azaldı.
Peki ne oldu?
Sol üst köşe, en önemli katsayıların en önemli genişleme katsayılarıdır.
Sol alt köşe, en önemli katsayıların en önemsiz genişleme katsayılarıdır.
Sağ üst köşe, en önemsiz katsayıların en önemli genişleme katsayılarıdır.
Sağ alt köşe, en önemsiz katsayıların en önemsiz genişleme katsayılarıdır.
Sol üst köşeden sağ alt köşeye çapraz hareket ederseniz katsayıların öneminin azaldığı açıktır. Hangisi daha önemli: (0, 7) veya (7, 0)? Ne anlama geliyorlar?
İlk olarak, satırlara göre: A 0 = (EX T) T = XE T (transpoze, çünkü A = EX formülü sütunlar içindir), ardından sütunlara göre: A = EA 0 = EXE T. Dikkatlice hesaplarsanız, formülü elde edersiniz:
Böylece, vektör sinüzoidlere ayrıştırılırsa, matris cos (ax) * cos (by) biçimindeki fonksiyonlara ayrılır. JPEG'deki her 8x8 blok, formun 64 işlevinin toplamı olarak temsil edilir:

Wikipedia ve diğer kaynaklar bu tür işlevleri daha uygun bir biçimde sağlar:

Bu nedenle, (0, 7) veya (7, 0) katsayıları eşit derecede faydalıdır.
Ancak, aslında bu, 64 64-boyutlu tabana sıradan bir tek-boyutlu ayrıştırmadır. Yukarıdakilerin tümü yalnızca DCT için değil, aynı zamanda herhangi bir ortogonal ayrıştırma için de geçerlidir. Analojiyle, genel durumda N boyutlu bir ortogonal dönüşüm elde ederiz.
Ve işte rakunun 2 boyutlu dönüşümü (DCT 256x256). Yine sıfır değerlerle. Sayılar - hepsinin sıfırlanmamış katsayılarının sayısı (en önemli değerler, sol üst köşedeki üçgen alanda bulunan bırakıldı).

(0, 0) katsayısının DC, diğer 63'ün AC olarak adlandırıldığını unutmayın.
Bir blok boyutu seçme
Bir arkadaş soruyor: JPEG'de neden 8x8 bölümleme kullanılıyor. Gönderilen cevaptan:DCT, bloğa periyodikmiş gibi davranır ve sınırlarda ortaya çıkan sıçramayı yeniden yapılandırması gerekir. 64x64 blok alırsanız, "büyük olasılıkla sınırlarda büyük bir sıçrama yapacaksınız ve" bunu tatmin edici bir hassasiyetle yeniden yapılandırmak için çok sayıda yüksek frekanslı bileşene ihtiyacınız olacak.Örneğin, DCT yalnızca periyodik işlevlerde iyi çalışır ve büyük bir boyut alırsanız, büyük olasılıkla bloğun sınırlarında dev bir sıçrama yapacaksınız ve onu kapatmak için çok sayıda yüksek frekanslı bileşene ihtiyacınız olacak. Bu doğru değil! Bu açıklama DFT'ye çok benzer, ancak DCT'ye değil, çünkü bu tür atlamaları zaten ilk bileşenlerle mükemmel bir şekilde kapsıyor.
Aynı sayfa, büyük bloklara karşı ana argümanlarla birlikte MPEG SSS'den bir cevap sağlar:
- Büyük bloklara bölündüğünde az kâr.
- Artan hesaplama karmaşıklığı.
- Bir blokta Gibbs etkisine neden olacak çok sayıda keskin kenar olma olasılığı yüksektir.

Yatay eksen, sıfır olmayan ilk katsayıların kesridir. Dikey - piksellerin orijinalden standart sapması. Mümkün olan maksimum sapma birim olarak alınır. Tabii ki, bir karar için bir fotoğraf açıkça yeterli değil. Ayrıca tam olarak doğru hareket etmiyorum, sadece sıfırlıyorum. Gerçek JPEG'de, niceleme matrisine bağlı olarak, yüksek frekanslı bileşenlerin yalnızca küçük değerleri sıfırlanır. Bu nedenle, aşağıdaki deneyler ve sonuçlar, ilke ve kalıpları yüzeysel olarak ortaya koymayı amaçlamaktadır.
Katsayıların kalan yüzde 25'i ile farklı bloklara ayırmayı karşılaştırabilirsiniz (soldan sağa, sonra sağdan sola):

Görsel olarak 32x32'den neredeyse ayırt edilemez olduklarından büyük bloklar gösterilmemiştir. Şimdi mutlak farka bakalım orijinal görüntü(iki katına çıktı, aksi takdirde hiçbir şey gerçekten görünmez): 
8x8 verir en iyi sonuç 4x4'ten daha fazla. Boyutta daha fazla artış artık açıkça görülebilir bir avantaj sağlamaz. 8x8 yerine 16x16'yı ciddi olarak düşünsem de: zorluğu %33 arttırmak (bir sonraki paragraftaki zorluk hakkında), küçük ama yine de görünür gelişme aynı sayıda katsayı ile. Bununla birlikte, 8x8 seçimi yeterince makul görünüyor ve belki de altın ortalamadır. JPEG 1991'de yayınlandı. O zamanlar işlemciler için bu tür bir sıkıştırmanın çok zor olduğunu düşünüyorum.
İkinci argüman. Blok boyutunu artırmanın daha fazla hesaplama gerektireceğini unutmayın. Ne kadar olduğunu tahmin edelim. Alnına dönüşümün karmaşıklığı, zaten nasıl olduğunu bildiğimiz gibi: O (N 2), çünkü her katsayı N terimden oluşur. Ancak pratikte verimli bir Hızlı Fourier Dönüşümü (FFT) algoritması kullanılır. Açıklaması bu makalenin kapsamı dışındadır. Karmaşıklığı O'dur (N * logN). İki boyutlu bir ayrıştırma için iki kez, N kez kullanmanız gerekir. Dolayısıyla 2D DCT'nin karmaşıklığı O'dur (N 2 logN). Şimdi bir görüntü hesaplamanın karmaşıklığını bir blok ve birkaç küçük blokla karşılaştıralım:
- Bir blok (kN) x (kN): O ((kN) 2 log (kN)) = O (k 2 N 2 log (kN))
- k * k blok N * N: O (k 2 N 2 logN)
Üçüncü argüman. resimde varsa keskin sınır renkler, bu tüm bloğu etkileyecektir. Belki de bu bloğun yeterince küçük olması daha iyidir, çünkü birçok komşu blokta böyle bir sınır muhtemelen artık mevcut olmayacaktır. Ancak, sınırlardan uzaklaşmak yeterince hızlıdır. Ayrıca, sınırın kendisi daha iyi görünecek. Katsayıların yalnızca dörtte biri ile yine çok sayıda kontrast geçişli bir örnekle kontrol edelim: 
16x16 blokların distorsiyonu 8x8'den daha fazla uzansa da, harfler daha pürüzsüz. Bu nedenle, yalnızca ilk iki argüman beni ikna etti. Ama 16x16 bölümünü daha çok seviyorum.
niceleme
Bu aşamada, kosinüs dönüşüm katsayılarına sahip bir grup 8x8 matrisimiz var. Önemsiz katsayılardan kurtulmanın zamanı geldi. Yukarıda yaptığımız gibi son oranları sıfırlamaktan daha zarif bir çözüm var. Sıfır olmayan değerler aşırı hassasiyetle saklandığı için bu yöntemden memnun değiliz ve şanssız olanlar arasında oldukça önemli olanlar olabilir. Çıkış yolu, bir niceleme matrisi kullanmaktır. Kayıplar tam olarak bu aşamada meydana gelir. Her Fourier katsayısı, niceleme matrisindeki karşılık gelen sayıya bölünür. Bir örneğe bakalım. Rakunumuzdan ilk bloğu alıp nicelleştirelim. JPEG özelliği standart bir matris sağlar:
FastStone ve IrfanView'da standart matris %50 kalitedir. Bu tablo kalite ve sıkıştırma oranı dengesi açısından seçilmiştir. DCT'nin normalize edilmemesi ve ilk değerin olması gerekenden daha büyük olması nedeniyle DC katsayısının değerinin komşu olanlardan daha büyük olduğunu düşünüyorum. Daha az önemli oldukları için yüksek frekans katsayıları daha pürüzlüdür. Artık kalitedeki bozulma açıkça fark edildiğinden, bu tür matrislerin nadiren kullanıldığını düşünüyorum. Hiç kimse masasını kullanmayı yasaklamaz (1'den 255'e kadar değerlerle)
Kod çözme sırasında, tersi işlem gerçekleşir - nicelleştirilmiş katsayılar, niceleme matrisinin değerleri ile terim terimle çarpılır. Ancak değerleri yuvarladığımız için orijinal Fourier katsayılarını doğru bir şekilde yeniden oluşturamayacağız. Kuantizasyon sayısı ne kadar büyük olursa, hata o kadar büyük olur. Bu nedenle, yeniden oluşturulan katsayı yalnızca en yakın kattır.
Başka bir örnek:

Tatlı olarak da %5 kaliteyi göz önünde bulundurun (Fast Stone'da kodlama yaparken). 
Bu bloğu geri yüklerken, yalnızca ortalama değer artı dikey eğimi elde ederiz (korunan değer -1 nedeniyle). Ancak bunun için yalnızca iki değer saklanır: 7 ve -1. Diğer bloklarda durum daha iyi değil, işte yeniden oluşturulmuş resim:

Bu arada, yaklaşık% 100 kalite. Tahmin edebileceğiniz gibi, bu durumda nicemleme matrisi tamamen birlerden oluşur, yani nicemleme gerçekleşmez. Ancak katsayıların tam sayıya yuvarlanmasından dolayı orijinal görüntüyü tam olarak geri yükleyemiyoruz. Örneğin, bir rakun piksellerin %96'sını doğru tuttu ve %4'ü 1/256 oranında farklılık gösterdi. Tabii ki, bu tür "bozulmalar" görsel olarak görülemez.
Ve çeşitli kameraların niceleme matrislerini görebilirsiniz.
kodlama
Devam etmeden önce elde edilen değerlerin nasıl sıkıştırılabileceğini daha basit örneklerle anlamamız gerekiyor.Örnek 0(ısınma için)
Bir arkadaşınızın evinizde listeli bir kağıt parçasını unuttuğunu ve şimdi sizden bunu telefonda dikte etmenizi istediğini (başka bir iletişim yolu yoktur) bir durumu düşünün.
Liste:
- d9rg3
- wfr43gt
- wfr43gt
- d9rg3
- d9rg3
- d9rg3
- wfr43gt
- d9rg3
A, B, C ... gibi kelimeleri belirleyeceğiz ve onlara semboller diyeceğiz. Ayrıca, sembolün altında her şey gizlenebilir: alfabenin bir harfi, bir kelime veya hayvanat bahçesindeki bir su aygırı. Ana şey, aynı kavramların aynı sembollere, farklı olanların da farklı olanlara karşılık gelmesidir. Görevimiz verimli kodlama (sıkıştırma) olduğundan, bunlar bilgi temsilinin en küçük birimleri olduğundan bitlerle çalışacağız. Bu nedenle listeyi ABBAAAABA olarak yazacağız. “Birinci kelime” ve “ikinci kelime” yerine 0 ve 1 bitleri kullanılabilir, ardından ABBAAAABA 01100010 (8 bit = 1 bayt) olarak kodlanır. 
örnek 1
ABC'yi kodlayın.
3m farklı semboller(A, B, C) 2 olası bit değerini (0 ve 1) eşleştirmenin bir yolu yoktur. Ve eğer öyleyse, karakter başına 2 bit kullanabilirsiniz. Örneğin:
- bir: 00
- B: 01
- C: 10

Örnek 2
AAAAAABC'yi kodlayın.
A karakteri başına 2 bit kullanmak biraz savurgan görünüyor. Bunu denerseniz ne olur:
- Saat: 00

Kodlanmış sıra: 000000100.
Açıkçası, bu seçenek uygun değildir, çünkü bu dizinin ilk iki bitinin nasıl çözüleceği açık değildir: AA olarak mı yoksa C olarak mı? Kodlar arasında bir çeşit ayırıcı kullanmak çok israftır, bu engeli farklı bir şekilde nasıl aşacağımızı düşüneceğiz. Yani başarısızlık, C kodunun A koduyla başlamasından kaynaklanıyordu ama B ve C iki olsa bile A'yı bir bit ile kodlamaya kararlıyız. Bu dilekten yola çıkarak A'ya 0 kodunu veriyoruz. O zaman B ve C kodları 0 ile başlayamaz. Ancak 1 ile başlayabilirler:
- B: 10
- C: 11

Sıra şu şekilde kodlanmıştır: 0000001011. Zihinsel olarak deşifre etmeye çalışın. Bunu yapmanın tek bir yolu var.
İki kodlama gereksinimi geliştirdik:
- Bir karakterin ağırlığı ne kadar büyükse, kodu o kadar kısa olmalıdır. Ve tam tersi.
- Belirsiz kod çözme için, bir karakter kodu başka bir karakter koduyla başlayamaz.
Örnek 3
Düşünmek Genel dava herhangi bir ağırlığa sahip 4 karakter için.
- bir: baba
- B: pb
- C: bilgisayar
- D: ben

Hangisi tercih edilir? Bunu yapmak için, alınan kodlanmış mesajların uzunluklarını hesaplamanız gerekir:
W1 = 2 * pa + 2 * pb + 2 * bilgisayar + 2 * pd
W2 = pa + 2 * pb + 3 * bilgisayar + 3 * pd
W1, W2'den küçükse (W1-W2<0), то лучше использовать первый вариант:
W1-W2 = pa - (pc + pd)< 0 =>baba< pc+pd.
C ve D diğerlerinden daha sık birlikte ortaya çıkarsa, ortak tepe noktaları bir bitlik en kısa kodu alır. Aksi takdirde, bir bit A sembolüne gider. Bu, sembollerin birleşiminin bağımsız bir sembol gibi davrandığı ve gelen sembollerin toplamına eşit bir ağırlığa sahip olduğu anlamına gelir.
Genel olarak, eğer p, bir karakterin meydana gelme kesriyle (0'dan 1'e) temsil edilen ağırlığıysa, o zaman en iyi kod uzunluğu s = -log 2 p'dir.
Bunu göz önünde bulundurun basit durum(bir ağaç olarak düşünmek kolaydır). Bu nedenle, 2 s karakteri eşit ağırlıkta (1/2 s) kodlamanız gerekir. Ağırlıkların eşitliğinden dolayı kodların uzunlukları da aynı olacaktır. Her karakterin s bitine ihtiyacı vardır. Bu nedenle, bir sembolün ağırlığı 1/2 s ise, uzunluğu s'dir. Ağırlık p ile değiştirilirse, s = -log 2 p kodunun uzunluğunu elde ederiz. Bu, bir karakter diğerinden iki kat daha az sıklıkta ortaya çıkarsa, kodunun uzunluğunun bir bit daha uzun olacağı anlamına gelir. Bununla birlikte, bir bit eklemenin olası seçeneklerin sayısını iki katına çıkarmanıza izin verdiğini hatırlarsanız, bu sonucu çıkarmak kolaydır.
Ve bir gözlem daha - en küçük ağırlığa sahip iki sembol her zaman en büyük fakat eşit kod uzunluklarına sahiptir. Dahası, sonuncusu hariç bitleri aynıdır. Bu doğru değilse, önek bozulmadan en az bir kod 1 bit kısaltılabilir. Bu, kod ağacında en düşük ağırlığa sahip iki karakterin daha yüksek düzeyde ortak bir ebeveyne sahip olduğu anlamına gelir. Bunu yukarıdaki örnek C ve D'de görebilirsiniz.
Örnek 4
Önceki örnekte elde edilen sonuçlara dayanarak aşağıdaki örneği çözmeye çalışalım.
- Tüm semboller azalan ağırlık sırasına göre sıralanmıştır.
- Son iki karakter bir grup halinde birleştirilir. Bu gruba, bu elemanların ağırlıklarının toplamına eşit bir ağırlık atanır. Bu grup, semboller ve diğer gruplarla birlikte algoritmaya katılır.
Bu algoritmaya Huffman kodlaması denir.
Resimde 5 karakterli bir örnek gösterilmektedir (A: 8, B: 6, C: 5, D: 4, E: 3). Sembolün (veya grubun) ağırlığı sağda gösterilir.

Katsayıları kodluyoruz
Geri geliyoruz. Şimdi her birinde bir şekilde kaydedilmesi gereken 64 katsayılı birçok bloğumuz var. En basit çözüm, faktör başına sabit sayıda bit kullanmaktır - açıkçası talihsizlik. Elde edilen tüm değerlerin bir histogramını oluşturalım (yani, katsayı sayısının değerlerine bağımlılığı):
Dikkat edin - ölçek logaritmiktir! 200'ü aşan değerlerin birikmesinin sebebini açıklar mısınız? Bunlar DC katsayılarıdır. Diğerlerinden çok farklı oldukları için ayrı ayrı kodlanmaları şaşırtıcı değildir. İşte sadece DC:

Grafiğin şeklinin, çok eski piksel çiftlerine ve üçlülerine bölme deneylerinden elde edilen grafiklerin şekline benzediğini unutmayın.
Genel olarak, DC katsayılarının değerleri 0 ila 2047 arasında değişebilir (daha kesin olarak, -1024 ila 1023 arasında, çünkü JPEG'de 128, DC'den 1024'ün çıkarılmasına karşılık gelen tüm orijinal değerlerden çıkarılır) ve oldukça dağıtılır. küçük tepe noktaları ile eşit olarak. Yani Huffman kodlaması burada pek yardımcı olmaz. Ayrıca kodlama ağacının ne kadar büyük olacağını da hayal edin! Ve kod çözme sırasında, içindeki değerleri aramanız gerekecek. Bu çok pahalı. Devamını düşünüyoruz.
DC faktörü, 8x8'lik bir bloğun ortalama değeridir. Fotoğraflarda sıklıkla bulunan bir degrade geçişi (mükemmel olmasa da) hayal edin. DC değerlerinin kendileri farklı olacak, ancak aritmetik bir ilerlemeyi temsil edecekler. Bu, farklarının az çok sabit olacağı anlamına gelir. Bir farklılıklar histogramı oluşturalım:

Bu daha iyidir, çünkü değerler genellikle sıfır civarında yoğunlaşır (ancak Huffman algoritması yine çok büyük bir ağaç verecektir). Küçük değerler (mutlak değerde) yaygındır, büyük olanlar nadirdir. Ve küçük değerler birkaç bit aldığından (baştaki sıfırları kaldırırsanız), sıkıştırma kurallarından biri iyi yürütülür: büyük ağırlıklı karakterler atanır kısa kodlar(ve tersi). Hala başka bir kurala uymamakla sınırlıyız: açık kod çözmenin imkansızlığı. Genel olarak, bu sorun şu şekillerde çözülebilir: ayırıcı kodla karıştır, kodun uzunluğunu belirt, önek kodlarını kullan (bunları zaten biliyorsun - bu, hiçbir kodun diğeriyle başlamadığı durumdur). Hadi devam edelim basit saniye seçeneği, yani her katsayı (daha doğrusu komşu olanlar arasındaki fark) şu şekilde yazılacaktır: (uzunluk) (değer), bu plakaya göre:

Yani, pozitif değerler doğrudan onlar tarafından kodlanır. ikili gösterim, ve negatif - aynı, ancak baştaki 1'in 0 ile değiştirilmesiyle. Geriye uzunlukların nasıl kodlanacağına karar vermek kalıyor. 12 olası değer olduğundan, uzunluğu saklamak için 4 bit kullanılabilir. Ancak burası Huffman kodlamasını kullanmanın daha iyi olduğu yerdir.

4 ve 6 uzunluğundaki değerler en fazla olduğu için en kısa kodları (00 ve 01) aldılar.
Soru ortaya çıkabilir: örneğin, neden 9 değeri 111111 değil de 111111 koduna sahip? Sonuçta, "0" ın yanında "9" u daha yüksek bir seviyeye güvenle yükseltebilirsiniz? Gerçek şu ki, JPEG'de yalnızca bunlardan oluşan bir kod kullanamazsınız - bu kod ayrılmıştır.
Bir özellik daha var. Tanımlanan Huffman algoritması ile elde edilen kodlar, uzunlukları aynı olmasına rağmen, bit olarak JPEG'deki kodlarla çakışmayabilir. Huffman algoritmasını kullanarak, kodların uzunlukları elde edilir ve kodların kendileri üretilir (algoritma basittir - kısa kodlarla başlarlar ve öneki koruyarak bunları mümkün olduğunca sola tek tek ağaca eklerler. Emlak). Örneğin, yukarıdaki ağaç için şu liste saklanır: 0,2,3,1,1,1,1,1,1. Ve elbette, bir değerler listesi saklanır: 4,6,3,5,7,2,8,1,0,9. Kod çözme sırasında kodlar aynı şekilde üretilir.
Şimdi sıra oldu. DC'lerin nasıl depolandığını anladık:
[DC fark uzunluğu için Huffman kodu (bit olarak)]
DC farkı = DC akımı - DC önceki
AC'yi izlemek:

Çizim, DC farklılıkları grafiğine çok benzer olduğundan, ilke aynıdır: [AC uzunluğu için Huffman kodu (bit olarak)]. Ama gerçekten değil! Grafikteki ölçek logaritmik olduğundan, sıfır değerlerinin 2 - sonraki frekans değerlerinden yaklaşık 10 kat daha büyük olduğu hemen fark edilmez. Bu anlaşılabilir bir durumdur - herkes nicelemeden sağ çıkmamıştır. Niceleme aşamasında elde edilen değerlerin matrisine geri dönelim (FastStone niceleme matrisini kullanarak, %90).

Ardışık birçok sıfır grubu olduğundan, fikir ortaya çıkıyor - gruptaki yalnızca sıfır sayısını kaydetmek. Bu sıkıştırma algoritmasına RLE (Çalışma uzunluğu kodlaması) adı verilir. "Ardışık" baypasın yönünü bulmak için kalır - kim kimin arkasında? Sıfırdan farklı katsayılar sol üst köşeye yakın bir yerde toplandığından ve sağ alta ne kadar yakınsa sıfır o kadar fazla olduğundan, soldan sağa ve yukarıdan aşağıya yazma çok etkili değildir.

Bu nedenle JPEG, soldaki şekilde gösterildiği gibi "Zig-zag" adlı bir düzen kullanır. Bu yöntem, sıfır gruplarını iyi ayırt eder. Sağdaki resimde - alternatif yol baypas, JPEG ile ilgili değil, ilginç bir adla (kanıt). Geçmeli videoyu sıkıştırırken MPEG'de kullanılabilir. Bypass algoritmasının seçimi görüntü kalitesini etkilemez, ancak kodlanmış sıfır gruplarının sayısını artırabilir, bu da sonuçta dosya boyutunu etkileyebilir.
Kaydımızı değiştirelim. Her sıfır olmayan AC - katsayısı için:
[AC'den önceki sıfır sayısı] [AC uzunluğu için Huffman kodu (bit olarak)]
Sanırım hemen anlayacaksınız - sıfırların sayısı da Huffman tarafından mükemmel bir şekilde kodlanmıştır! Bu çok yakın ve fena olmayan bir cevap. Ama biraz optimize edebilirsiniz. Daha önce 7 sıfır olan belirli bir AC katsayımız olduğunu hayal edin (tabii ki, zikzak düzeninde yazarsak). Bu sıfırlar, nicelemeden kurtulamayan değerlerin ruhudur. Büyük olasılıkla, katsayımız da kötü bir şekilde hırpalandı ve küçüldü, bu da uzunluğunun kısa olduğu anlamına geliyor. Bu, AC'den önceki sıfırların sayısının ve AC'nin uzunluğunun bağımlı nicelikler olduğu anlamına gelir. Bu nedenle, şöyle yazarlar:
[Huffman kodu (AC'den önceki sıfır sayısı, AC uzunluğu (bit olarak)]
Kodlama algoritması aynı kalır: Sıklıkla meydana gelen bu çiftler (AC'nin önündeki sıfırların sayısı, AC'nin uzunluğu) kısa kodları alır ve bunun tersi de geçerlidir.
Bu çiftler ve bir Huffman ağacı için miktarın bağımlılığının bir histogramını oluşturuyoruz. 
Uzun "dağ silsilesi" varsayımımızı doğrular.
JPEG'de uygulamanın özellikleri:
Böyle bir çift 1 bayt alır: sıfır sayısı için 4 bit ve AC'nin uzunluğu için 4 bit. 4 bit 0'dan 15'e kadar olan değerlerdir. AC'nin uzunluğu için fazlasıyla var ama 15'ten fazla sıfır olabilir mi? Daha sonra kullanılan daha fazla çift... Örneğin, 20 sıfır için: (15, 0) (5, AC). Yani 16. sıfır sıfır olmayan bir katsayı olarak kodlanmıştır. Bloğun sonuna daha yakın her zaman sıfırlarla dolu olduğundan, son sıfır olmayan katsayıdan sonra (0,0) çifti kullanılır. Kod çözme sırasında karşılaşılırsa, kalan değerler 0'a eşittir.
Kodlanan her bloğun aşağıdaki gibi bir dosyada saklandığını öğrendik:
[DC fark uzunluğu için Huffman kodu]
[Huffman kodu (AC 1'den önceki sıfır sayısı, uzunluk AC 1]
…
[Huffman kodu (AC n'den önceki sıfır sayısı, AC n uzunluğu]
AC ben - sıfır olmayan AC katsayıları.
Renkli görüntü
Renkli bir görüntünün sunulma şekli, seçilen renk modeline bağlıdır. Basit bir çözüm, RGB kullanmak ve görüntünün her bir renk kanalını ayrı ayrı kodlamaktır. O zaman kodlama gri görüntü kodlamasından farklı olmayacak, sadece iş 3 kat daha fazla. Ancak gözün parlaklıktaki değişikliklere renkten daha duyarlı olduğunu hatırlarsanız, görüntünün sıkıştırması artırılabilir. Bu, rengin parlaklıktan daha fazla kayıpla saklanabileceği anlamına gelir. RGB'nin ayrı bir parlaklık kanalı yoktur. Her kanalın değerlerinin toplamına bağlıdır. Bu nedenle, bir RGB küpü (bu, tüm olası değerlerin bir temsilidir) köşegen üzerine basitçe "koyulur" - ne kadar yüksek olursa, o kadar parlak olur. Ancak bu bunlarla sınırlı değildir - küp kenarlardan hafifçe sıkılır ve oldukça paralel bir şekilde ortaya çıkar, ancak bu sadece gözün özelliklerini dikkate almak içindir. Örneğin, yeşile maviden daha duyarlıdır. YCbCr modeli bu şekilde ortaya çıktı.
(Intel.com üzerinden görüntü)
Y parlaklık bileşeni, Cb ve Cr mavi ve kırmızı renk farkı bileşenleridir. Bu nedenle, görüntüyü daha güçlü bir şekilde sıkıştırmak isterlerse, RGB YCbCr'ye dönüştürülür ve Cb ve Cr kanalları kırılır. Yani, örneğin 2x2, 4x2, 1x2 gibi küçük bloklara bölünürler ve bir bloğun tüm değerlerinin ortalaması alınır. Veya başka bir deyişle, bu kanal için görüntü boyutunu dikey ve/veya yatay olarak 2 veya 4 kat küçültün.

Her 8x8 blok kodlanır (DCT + Huffman) ve kodlanan diziler şu sırayla yazılır:
JPEG spesifikasyonunun model seçimini sınırlamaması ilginçtir, yani kodlayıcı uygulaması görüntüyü keyfi olarak renk bileşenlerine (kanallara) bölebilir ve her biri ayrı ayrı kaydedilecektir. Gri Tonlamalı (1 kanal), YCbCr (3), RGB (3), YCbCrK (4), CMYK (4) kullandığımın farkındayım. İlk üçü hemen hemen herkes tarafından destekleniyor ancak son 4 kanallı olanlarda sorunlar var. FastStone, GIMP onları doğru bir şekilde destekliyor ve standart Windows programları, paint.net tüm bilgileri doğru bir şekilde çıkarıyor, ancak daha sonra 4 siyah kanal atıyorlar, bu nedenle (Antelle onu atmadıklarını söyledi, yorumlarını okuyun) daha fazla göster hafif görüntü... Sol - klasik YCbCr JPEG, sağ CMYK JPEG:


Renkleri farklıysa veya yalnızca bir resim görünüyorsa, büyük olasılıkla IE'niz (herhangi bir sürüm) var (UPD. Yorumlarda “veya Safari” diyorlar). Makaleyi farklı tarayıcılarda açmayı deneyebilirsiniz.
Ve başka bir şey
Özetle, ek özellikler hakkında.Aşamalı mod
Elde edilen DCT katsayı tablolarını tabloların toplamına ayıralım (yaklaşık olarak (DC, -19, -22, 2, 1) = (DC, 0, 0, 0, 0) + (0, -20, -20, 0, 0) + (0, 1, -2, 2, 1)). İlk önce tüm ilk terimleri kodluyoruz (zaten öğrendiğimiz gibi: Huffman ve zikzak geçişi), ardından ikincisini vb. yavaş internet, çünkü ilk başta sadece 8x8 "piksel" ile kaba bir resmin oluşturulduğu DC katsayıları yüklenir. Ardından, şekli iyileştirmek için yuvarlatılmış AC katsayıları. Sonra onlara kaba düzeltmeler, ardından daha kesin düzeltmeler. Ve bunun gibi. Katsayılar yuvarlanır, çünkü yüklemenin ilk aşamalarında doğruluk çok önemli değildir, ancak yuvarlama, her aşama için ayrı bir Huffman tablosu kullanıldığından, kodların uzunluğu üzerinde olumlu bir etkiye sahiptir.kayıpsız mod
Kayıpsız sıkıştırma. DCT numarası Üç komşudan 4. noktanın tahmini kullanılır. Tahmin hataları Huffman tarafından kodlanmıştır. Benim düşünceme göre, hiç olmadığı kadar biraz daha sık kullanılıyor.hiyerarşik mod
Görüntüden birkaç katman oluşturulur. farklı izinler... İlk kaba katman her zamanki gibi kodlanır ve ardından yalnızca katmanlar arasındaki fark (görüntü iyileştirme) (bir Haar dalgacığı gibi görünür) kodlanır. Kodlama için DCT veya Kayıpsız kullanılır. Benim düşünceme göre, hiç olmadığı kadar az kullanılıyor.aritmetik kodlama
Huffman algoritması, karakterlerin ağırlığı için en uygun kodları üretir, ancak bu yalnızca karakterlerin kodlarla sabit bir eşleşmesi için geçerlidir. Aritmetik, kodları olduğu gibi kullanmanıza izin veren böyle katı bir bağlamaya sahip değildir. kesirli sayı biraz. Huffman'a kıyasla dosya boyutunu ortalama %10 oranında küçülttüğü iddia ediliyor. Patent sorunları nedeniyle yaygın değil, herkes tarafından desteklenmiyor.Umarım şimdi JPEG algoritmasını sezgisel olarak anlamışsınızdır. Okuduğunuz için teşekkürler!
UPD
vanwin, kullanılan yazılımı belirtmeyi teklif etti. Her şeyin mevcut ve ücretsiz olduğunu duyurmaktan memnuniyet duyuyorum:
- Python + NumPy + Matplotlib + PIL (Yastık)... Ana araç. "Matlab ücretsiz alternatif" yayınlayarak bulundu. Önermek! Python'a aşina olmasanız bile, birkaç saat içinde hesaplama yapmayı ve güzel grafikler oluşturmayı öğreneceksiniz.
- JpegSnoop... Şovlar detaylı bilgi jpeg dosyası hakkında.
- yEd... Grafik düzenleyici.
- Inkscape... İçinde Huffman algoritmasının bir örneği gibi illüstrasyonlar yaptı. Birkaç ders okudum, çok havalı olduğu ortaya çıktı.
- Daum Denklem Editörü... Lateks ile pek arkadaş canlısı olmadığım için görsel bir formül düzenleyici arıyordum. Daum Equation, Chrome için bir eklenti, çok uygun buldum. Fareyle toplamanın yanı sıra Latex'i düzenleyebilirsiniz.
- Hızlı Taş... Onu tanıtmaya gerek olduğunu düşünmüyorum.
- seçim. Ücretsiz alternatif SnagIt. Tepsiye oturur, ne dediklerini nerede söylerlerse ekran görüntüsü alır. Ayrıca cetvel, pipet, iletki vb. gibi her türlü güzellikler.
Etiketler: Etiket Ekle









Taramalı Atomik Kuvvet Mikroskobu Laboratuvar raporu şunları içermelidir:
Havai iletişim ağı desteklerinin raflarının seçimi
AC katener tasarımı ve hesaplanması
Mikroişlemci sistemlerinin geliştirilmesi Mikroişlemci sistemlerinin tasarım aşamaları
mcs51 ailesinin mikrodenetleyicileri