Keďže na svete existujú šifry veľké množstvo, potom nie je možné zvážiť všetky šifry nielen v rámci tohto článku, ale aj celej stránky. Preto zvážime najprimitívnejšie šifrovacie systémy, ich aplikáciu, ako aj dešifrovacie algoritmy. Účelom môjho článku je čo najzrozumiteľnejšie vysvetliť princípy šifrovania / dešifrovania širokému okruhu používateľov, ako aj naučiť primitívne šifry.
Aj v škole som používal primitívnu šifru, o ktorej mi rozprávali starší súdruhovia. Uvažujme o primitívnej šifre "Šifra s nahradením písmen číslami a naopak."
Nakreslíme si tabuľku, ktorá je znázornená na obrázku 1. Čísla usporiadame v poradí, počnúc jednotkou, končiac nulou vodorovne. Nižšie pod číslami nahrádzame ľubovoľné písmená alebo symboly.
Ryža. 1 Kľúč k šifre s nahradením písmen a naopak.
Teraz prejdime k tabuľke 2, kde je abeceda očíslovaná. 
Ryža. 2 Korešpondenčná tabuľka písmen a číslic abecedy.
Teraz zašifrujeme slovo K O S T E R:
1) 1. Preveďte písmená na čísla: K = 12, O = 16, C = 19, T = 20, Yo = 7, P = 18
2) 2. Preložme čísla na symboly podľa tabuľky 1.
KP KT KD PSHCH L KL
3) 3. Hotovo.
Tento príklad ukazuje primitívnu šifru. Zoberme si fonty podobné zložitosti.
1. 1. Najjednoduchšia šifra je ŠIFRA S NAHRADENÍM PÍSMEN ČÍSLAMI. Každé písmeno zodpovedá číslu abecedné poradie. A-1, B-2, C-3 atď.
Napríklad slovo „ TOWN “ môže byť napísané ako „20 15 23 14“, ale to nespôsobí veľa tajomstiev a ťažkostí pri dešifrovaní.
2. Správy môžete zašifrovať aj pomocou NUMERICKEJ TABUĽKY. Jeho parametre môžu byť akékoľvek, hlavné je, že si to uvedomuje príjemca aj odosielateľ. Príklad digitálnej tabuľky. 
Ryža. 3 Číselná tabuľka. Prvá číslica v šifre je stĺpec, druhá je riadok alebo naopak. Takže slovo „MYSEL“ môže byť zašifrované ako „33 24 34 14“.
3. 3. KNIŽNÁ ŠIFRA
V takejto šifre je kľúčom určitá kniha, ktorú má odosielateľ aj príjemca. Šifra označuje stranu knihy a riadok, ktorého prvé slovo je kľúčom. Dešifrovanie nie je možné, ak odosielateľ a korešpondent majú knihy z rôznych rokov vydania a vydania. Knihy musia byť identické.
4. 4. CAESAROVÁ ŠIFRA(posunovacia šifra, Caesarov posun)
Známa šifra. Podstatou tejto šifry je nahradenie jedného písmena iným, ktoré sa nachádza na niektorých konštantné číslo pozície vľavo alebo vpravo od neho v abecede. Gaius Julius Caesar používal tento spôsob šifrovania v korešpondencii so svojimi generálmi na ochranu vojenskej komunikácie. Táto šifra sa dá pomerne ľahko prelomiť, preto sa používa len zriedka. Posun o 4. A = E, B= F, C=G, D=H atď.
Príklad Caesarovej šifry: zašifrujme slovo " ODPOČET ".
Získame: GHGXFWLRQ . (posun o 3)
Ďalší príklad:
Šifrovanie pomocou kľúča K=3. Písmeno "C" "posunie" o tri písmená dopredu a stane sa písmenom "F". pevné znamenie, posunuté o tri písmená dopredu, zmení sa na písmeno „E“ atď.:
Zdrojová abeceda: A B C D E F G I J K L M N O P R S T U V W Y Z
Šifrované: D E F G H I J K L M N O P R S T U V W Y Z A B C
Pôvodný text:
Jedzte viac tých mäkkých francúzskych buchiet a dajte si čaj.
Šifrovaný text sa získa nahradením každého písmena pôvodný text zodpovedajúce písmeno šifrovej abecedy:
Fezyya iz zyi akhlsh pvenlsh chugrschtskfnlsh dtsosn, zhg eyutzm gb.
5. ŠIFRUJTE KÓDOVÉ SLOVO
Ďalší jednoduchý spôsob šifrovania aj dešifrovania. Používa sa kódové slovo (akékoľvek slovo bez opakujúcich sa písmen). Toto slovo sa vloží pred abecedu a zvyšné písmená sa pridajú v poradí, s výnimkou tých, ktoré sú už v kódovom slove. Príklad: kódové slovo je NOTEPAD.
Zdroj: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Náhrada: N T E P A D B C F G H I J K L M Q R S U V W X Y Z
6. 6. ATBASH KÓD
Jeden z najviac jednoduchými spôsobmišifrovanie. Prvé písmeno abecedy je nahradené posledným, druhé predposledným atď.
Príklad: "VEDA" = HXRVMXV
7. 7. ŠIFRA FRANTIŠKA BACONA
Jeden z najviac jednoduché metódyšifrovanie. Na šifrovanie sa používa baconova šifrová abeceda: každé písmeno slova je nahradené skupinou piatich písmen „A“ alebo „B“ (binárny kód).
a AAAAA g AABBA m ABABB s BAAAB y BABBA
b AAAAB h AABBB n ABBAA t BAABA z BABBB
c AAABA i ABAAA o ABBAB u BAABB
d AAABB j BBBAA p ABBBA v BBBAB
e AABAA k ABAAB q ABBBB w BABAA
f AABAB l ABABA r BAAAA x BABAB
Zložitosť dešifrovania spočíva v určení šifry. Po zadefinovaní sa správa ľahko zoradí podľa abecedy.
Existuje niekoľko spôsobov kódovania.
Môžete tiež zašifrovať vetu pomocou binárny kód. Parametre sú definované (napríklad "A" - od A do L, "B" - od L po Z). Takže BAABAAAAABAAAABABABB znamená The Science of Deduction! Táto metóda je zložitejšia a únavnejšia, ale oveľa spoľahlivejšia ako abecedná verzia.
8. 8. ŠIFRA MODRÁ VIGENÉRA.
Túto šifru používali Konfederanti počas občianskej vojny. Šifru tvorí 26 Caesarových šifier s rôzne významy posun (26 písmen latinskej abecedy). Na šifrovanie možno použiť Tabula recta (Vigenèrov štvorec). Najprv sa vyberie kľúčové slovo a zdrojový text. Kľúčové slovo sa píše cyklicky, kým nezaplní celú dĺžku pôvodného textu. Ďalej pozdĺž tabuľky sa písmená kľúča a otvorený text pretínajú v tabuľke a tvoria šifrový text.

Ryža. 4 Blaise Vigenère šifra
9. 9. ŠIFRA LESTERA HILLA
Na základe lineárnej algebry. Bol vynájdený v roku 1929.
V takejto šifre každé písmeno zodpovedá číslu (A = 0, B = 1 atď.). Blok n-písmen sa považuje za n-rozmerný vektor a vynásobí sa maticou (n x n) mod 26. Maticou je šifrovací kľúč. Aby bolo možné dešifrovať, musí byť reverzibilné v Z26n.
Aby bolo možné správu dešifrovať, je potrebné previesť šifrovaný text späť na vektor a vynásobiť ho inverzná matica kľúč. Pre detailné informácie- Wikipedia na záchranu.
10. 10. TRITEMIUS ŠIFRA
Vylepšená Caesarova šifra. Pri dešifrovaní je najjednoduchšie použiť vzorec:
L= (m+k) modN , L-číslo zašifrovaného písmena v abecede, m-poradové číslo písmená zašifrovaného textu v abecede, k je číslo posunu, N je počet písmen v abecede.
Ide o špeciálny prípad afinnej šifry.
11. 11. MURÁRSKA CYFER


12. 12. GRONSFELD CYFER
Obsahom tejto šifry je Caesarova šifra a Vigenèrova šifra, no Gronsfeldova šifra používa číselný kľúč. Slovo „THALAMUS“ zašifrujeme kľúčom číslom 4123. Čísla číselného kľúča zadáme v poradí pod každé písmeno slova. Číslo pod písmenom bude označovať počet pozícií, na ktoré je potrebné písmená posunúť. Napríklad namiesto T dostanete X atď.
T H A L A M U S
4 1 2 3 4 1 2 3
T U V W X Y Z
0 1 2 3 4
Výsledok: THALAMUS = XICOENWV
13. 13. PRASA LATIN
Častejšie sa používa ako zábava pre deti, nespôsobuje žiadne zvláštne ťažkosti pri dešifrovaní. Povinné používanie anglického jazyka, latinčina s tým nemá nič spoločné.
V slovách, ktoré začínajú spoluhláskami, sa tieto spoluhlásky presunú späť a pridá sa „prípona“ ay. Príklad: otázka = estionquay. Ak sa slovo začína samohláskou, potom ay, way, yay alebo hay sa jednoducho pridajú na koniec (príklad: pes = aay ogday).
Táto metóda sa používa aj v ruštine. Nazývajú to inak: „modrý jazyk“, „slaný jazyk“, „biely jazyk“, „fialový jazyk“. V modrom jazyku sa teda po slabike obsahujúcej samohlásku pridáva slabika s rovnakou samohláskou, ale s pridaním spoluhlásky „s“ (pretože jazyk je modrý). Príklad: Informácie vstupujú do jadier talamu = Insiforsomasacisia possotusupasesa v jadre rasa tasalasamusususas.
Celkom zaujímavá možnosť.
14. 14. POLYBIOVO NÁMESTIE
Ako digitálny stôl. Existuje niekoľko spôsobov použitia Polybiovho štvorca. Príklad Polybiovho štvorca: urobíme tabuľku 5x5 (6x6 v závislosti od počtu písmen v abecede).
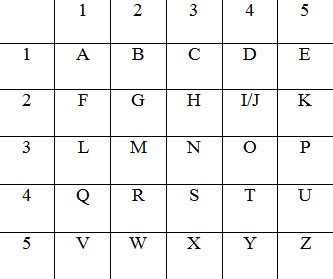
1 METÓDA. Namiesto každého písmena v slove sa používa zodpovedajúce písmeno zdola (A = F, B = G atď.). Príklad: CIPHER - HOUNIW.
2 SPÔSOB. Čísla zodpovedajúce každému písmenu z tabuľky sú označené. Prvé číslo je napísané horizontálne, druhé - vertikálne. (A=11, B=21...). Príklad: CIPHER = 31 42 53 32 51 24
3 SPÔSOB. Na základe predchádzajúcej metódy napíšme spolu výsledný kód. 314253325124. Robíme posun doľava o jednu pozíciu. 142533251243. Kód opäť rozdelíme do dvojíc 14 25 33 25 12 43. Výsledkom je šifra. Dvojice čísel zodpovedajú písmenu v tabuľke: QWNWFO.
Existuje veľa šifier a môžete si tiež vymyslieť svoju vlastnú šifru, ale je veľmi ťažké vymyslieť silnú šifru, pretože veda o dešifrovaní pokročila s príchodom počítačov ďaleko dopredu a každá amatérska šifra bude prelomená. odborníkmi vo veľmi krátkom čase.
Metódy otvárania monoalfabetických systémov (dekódovanie)
Vďaka svojej jednoduchosti implementácie sú systémy jednoabecedného šifrovania ľahko zraniteľné.
Určíme si množstvo rôzne systémy v afinnom systéme. Každý kľúč je plne definovaný dvojicou celých čísel aab, ktoré definujú mapovanie ax+b. Existuje j(n) možných hodnôt pre a, kde j(n) je Eulerova funkcia, ktorá vracia počet prvočíselných čísel s hodnotami n a n pre b, ktoré možno použiť bez ohľadu na a, s výnimkou identity. mapovanie (a=1 b =0), ktoré nebudeme uvažovať.
Existuje teda j(n)*n-1 možných hodnôt, čo nie je až tak veľa: s n=33 môže existovať 20 hodnôt pre a (1, 2, 4, 5, 7, 8, 10, 13, 14 , 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), potom je celkový počet kľúčov 20*33-1=659. Vyčíslenie takého počtu kľúčov nie je pri používaní počítača ťažké.
Existujú však metódy, ktoré toto vyhľadávanie zjednodušujú a ktoré možno použiť pri analýze zložitejších šifier.
frekvenčná analýza
Jednou z takýchto metód je frekvenčná analýza. Rozloženie písmen v kryptotexte sa porovnáva s rozmiestnením písmen v abecede pôvodná správa. Listy s najvyššia frekvencia v kryptotexte sú nahradené písmenom s najvyššou frekvenciou z abecedy. Pravdepodobnosť úspešného otvorenia sa zvyšuje s dĺžkou kryptotextu.
Existuje mnoho rôznych tabuliek o rozdelení písmen v danom jazyku, ale žiadna z nich neobsahuje definitívne informácie – dokonca aj poradie písmen sa môže v rôznych tabuľkách líšiť. Rozdelenie písmen veľmi závisí od typu testu: próza, hovorový, technický jazyk a pod. AT usmernenia do laboratórne práce daný frekvenčné charakteristiky pre rôzne jazyky, z ktorých je zrejmé, že písmená písmena I, N, S, E, A (I, N, C, E, A) sa vyskytujú vo vysokofrekvenčnej triede každého jazyka.
Najjednoduchšiu ochranu pred útokmi na základe frekvenčného počítania poskytuje systém homofónov (HOMOPHONES), jednozvukových substitučných šifier, v ktorých je jeden znak otvoreného textu mapovaný na niekoľko znakov šifrového textu, ich počet je úmerný frekvencii písmena. Zašifrovaním písmena pôvodnej správy náhodne vyberieme jednu z jej náhrad. Jednoduchý výpočet frekvencií preto kryptoanalytikovi nič nedáva. Dostupné sú však informácie o rozdelení dvojíc a trojíc písmen v rôznych prirodzených jazykoch.
Alebo náhrady. Tabuľka vzájomnej zhody medzi abecedou zdrojového textu a kódové symboly a v súlade s touto tabuľkou prebieha kódovanie jedna ku jednej. Na dekódovanie potrebujete poznať tabuľku kódov.
Existuje veľké číslo kódy používané v rôznych oblastiach ľudského života. Známe kódy sa väčšinou používajú na uľahčenie prenosu informácií jedným alebo druhým spôsobom. Ak je kódová tabuľka známa iba vysielajúcim a prijímajúcim, získa sa pomerne primitívna šifra, ktorá je ľahko prístupná frekvenčnej analýze. Ale ak je človek ďaleko od teórie kódovania a nie je oboznámený s frekvenčná analýza textu, je pre neho problematické takéto šifry vyriešiť.
A1Z26
Najjednoduchšia šifra. Volá sa A1Z26 alebo v ruskej verzii A1Ya33. Písmená abecedy sú nahradené ich poradovými číslami.
"NoZDR" môže byť zašifrované ako 14-15-26-4-18 alebo 1415260418.
morseovka

Písmená, čísla a niektoré znaky sú spojené so súborom bodiek a pomlčiek, ktoré možno prenášať rádiom, zvukom, klopaním, svetelným telegrafom a vlajkami. Viac o morzeovke si môžete prečítať na stránke.
Braillovo písmo
Braillovo písmo je systém hmatového čítania pre nevidomých, ktorý pozostáva zo šesťbodových znakov nazývaných bunky. Bunka pozostáva z tri body na výšku a dva body na šírku.
Rôzne Braillovo písmo sa vytvára umiestnením bodiek na rôzne miesta v bunke.
Pre pohodlie sú body pri čítaní popísané nasledujúcim spôsobom: 1, 2, 3 zhora vľavo dole a 4, 5, 6 zhora vpravo dole.

Pri zostavovaní textu sa dodržiavajú tieto pravidlá:
medzi slovami sa preskakuje jedna bunka (medzera);
za čiarkou a bodkočiarkou sa bunka nepreskočí;
pomlčka sa píše spolu s predchádzajúcim slovom;
Pred číslom je číselný znak.

Kódové stránky
V počítačových úlohách a hádankách môžu byť písmená zakódované podľa ich kódov v rôznych kódových stránkach – tabuľkách používaných na počítačoch. Pre texty v azbuke je najlepšie použiť najbežnejšie kódovania: Windows-1251, KOI8, CP866, MacCyrillic. Aj keď pre zložité šifrovanie si môžete vybrať niečo exotickejšie.
Môžete kódovať hexadecimálne čísla a môžete ich previesť na desatinné číslo. Napríklad písmeno Yo v KOI8-R je B3 (179), v CP866 je to F0 (240) a vo Windows-1251 je to A8 (168). A je možné, že písmená v pravých tabuľkách hľadajú zhodu v ľavých, potom sa ukáže, že text je napísaný „bláznivým“ typom èαᬫº∩íαδ (866→437) alebo Êðàêîçÿáðû (1251→Latin-1).
Tu https://www.artlebedev.ru/tools/decoder/advanced/ na takéto šifrové texty existuje dobrý dekodér :)



Slobodomurárska šifra
Slobodomurárska šifra je známa aj ako Pigpen alebo Tic-Tac-Toe. Táto šifra je jednoduchá substitučná šifra, v ktorej každé písmeno abecedy zodpovedá grafickému symbolu vypočítanému z jednej z nižšie uvedených mriežok.

Na šifrovanie určité písmeno pomocou tejto šifry musíte najskôr určiť miesto, kde sa toto písmeno nachádza v jednej zo štyroch mriežok, a potom nakresliť časť mriežky, ktorá toto písmeno obklopuje. Teda niečo takéto:
Ak poznáte kľúč (ako sú písmená usporiadané v mriežkach), potom je celkom ľahké rozlúštiť takýto nápis. Ak sú však písmená v mriežkach pôvodne usporiadané podľa nejakého neznámeho pravidla (s kľúčové slovo, striedavo alebo aj náhodou), potom v tejto situácii môže vždy pomôcť
Použitie grafické symboly namiesto písmen nie je veľkou prekážkou pre kryptoanalýzu a tento systém je identický s ostatnými jednoduché obvody monoalfabetická substitúcia. Pre svoju jednoduchosť sa táto šifra často spomína v detských knihách o šifrovaní, kryptografii a všelijakých iných špionážnych veciach.
Presný čas vzniku šifry nie je známy, no niektoré nájdené záznamy o tomto systéme siahajú až do 18. storočia. Variácie tejto šifry používali rosenkruciánsky rád a slobodomurári. Títo ju používali vo svojich tajných dokumentoch a korešpondencii pomerne často, a tak sa šifra začala nazývať slobodomurárskou šifrou. Dokonca aj na náhrobných kameňoch slobodomurárov môžete vidieť nápisy používajúce túto šifru. Podobný systém šifrovania používala počas americkej občianskej vojny armáda Georga Washingtona, ako aj väzni vo federálnych väzniciach v Konfederačných štátoch USA.
Nižšie sú uvedené dve (modrá a červená) možnosti na vyplnenie mriežky takýchto šifier. Písmená sú usporiadané do párov, druhé písmeno z páru je nakreslené ako symbol s bodkou:

Autorské šifry
Bola vynájdená široká škála šifier, kde jeden znak abecedy (písmeno, číslo, interpunkčné znamienko) zodpovedá jednému (menej často viac) grafickému znaku. Väčšina z nich je určená na použitie v sci-fi filmoch, karikatúrach a počítačové hry. Tu sú niektoré z nich:
tancujúcich mužov
Jednou z najznámejších autorových substitučných šifier je "". Vymyslel a opísal ho anglický spisovateľ Arthur Conan Doyle v jednom zo svojich diel o Sherlockovi Holmesovi. Písmená abecedy sú nahradené symbolmi, ktoré vyzerajú ako malí muži v rôznych pózach. V knihe neboli malí muži vymyslení na všetky písmená abecedy, takže fanúšikovia kreatívne dotvorili a prepracovali postavičky a toto je šifra:

Abeceda Thomasa Morea
Ale takáto abeceda bola opísaná vo svojom pojednaní „Utópia“ Thomasom Moreom v roku 1516:

Bill Cipher Cipher z Gravity Falls

Abeceda Jedi zo Star Wars

Mimozemská abeceda z Futuramy

Supermanova kryptónska abeceda

Bionikové abecedy

Sémantika(francúzsky sémantique z iného gréckeho σημαντικός - označenie) - veda o pochopení určitých znakov, sekvencií znakov a iných symbolov. Táto veda sa používa v mnohých oblastiach: lingvistika, proxemika, pragmatika, etymológia atď. Netuším, čo tieto slová znamenajú a čo všetko tieto vedy robia. A to je jedno, zaujíma ma otázka uplatnenia sémantiky pri rozvrhnutí stránok.
Poznámka
Nebudem sa tu dotýkať pojmu sémantický web. Na prvý pohľad by sa mohlo zdať, že témy sémantického webu a sémantického HTML sú takmer to isté. Ale v skutočnosti je koncept sémantického webu dosť filozofický a so súčasnou realitou má len málo spoločného.
Sémantické rozloženie - čo to je?
V jazyku má každé slovo špecifický význam, účel. Keď hovoríte „klobása“, máte na mysli potravinový výrobok, ktorým je mleté mäso (zvyčajne mäso) v podlhovastej škrupine. V skratke máte na mysli klobásu, nie mlieko alebo zelený hrášok.
HTML je tiež jazyk, jeho „slová“, nazývané tagy, majú tiež určitý logický význam a účel. Pre toto v prvom rade sémantický kód HTML je rozvrhnutý správne pomocou HTML značky, ktoré ich používajú na zamýšľaný účel tak, ako ich navrhli vývojári jazyk HTML a webové štandardy.
microformats.org je komunita, ktorá sa snaží oživiť idealistické myšlienky sémantického webu tým, že približuje rozloženie stránky týmto sémantickým ideálom.
Prečo a kto vôbec potrebuje sémantické rozloženie?
Ak sú informácie na mojej stránke zobrazené rovnako ako na dizajne, prečo by som si inak mal lámať hlavu a rozmýšľať nad nejakou sémantikou?! Toto je naozaj extra práca! Kto to potrebuje?! Kto to ocení okrem iného kódera?
Často počúvam takéto otázky. Poďme na to.
Sémantické HTML pre vývojárov webu
Sémantický kód pre používateľov
Zvyšuje dostupnosť informácií na stránke. V prvom rade je to dôležité pre alternatívnych agentov, ako sú:
- sémantický kód priamo ovplyvňuje množstvo HTML kódu. Menej kódu -> ľahšie stránky -> rýchlejšie sa načítavajú, menej potrebné Náhodný vstup do pamäťe na strane používateľa menšia návštevnosť, menšie databázy. Stránka sa stáva rýchlejšou a lacnejšou.
- hlasové prehliadače pre ktorých sú tagy a ich atribúty dôležité, aby obsah vyslovovali správne a so správnou intonáciou, alebo naopak, aby nevyslovovali príliš veľa.
- mobilné zariadenia ktorí nie sú na plný výkon podporujú CSS a preto sa zameriavajú hlavne na HTML kód, zobrazujúc ho na obrazovke podľa použitých značiek.
- tlačové zariadenia aj bez dodatočného CSS sa informácie vytlačia lepšie (bližšie k dizajnu) a vytvorenie dokonalej tlačovej verzie sa zmení na niekoľko jednoduchých manipulácií s CSS.
- okrem toho existujú zariadenia a zásuvné moduly, ktoré umožňujú rýchlu navigáciu v dokumente – napríklad cez nadpisy Opery.
Sémantické HTML pre stroje
Vyhľadávače neustále zdokonaľujú svoje metódy vyhľadávania tak, aby výsledky obsahovali informácie, ktoré naozaj hľadá užívateľ. Sémantické HTML k tomu prispieva, pretože požičiava veľa lepšia analýza- kód je čistejší, kód je logický (jasne vidíte, kde sú nadpisy, kde je navigácia, kde je obsah).
Dobrý obsah plus kvalita sémantické rozloženie je už vážna ponuka dobré pozície vo výsledkoch vyhľadávačov.
sémantický kód. Jeho ciele. Účel. Konštrukčný princíp. Schopnosti.
Účelom je udelené povolenie yavl:
Vygenerujte najbežnejšieho princa vytvorenia tohto kódu
Ukázať v všeobecný pohľad na príkladoch jeho možností
Detekovať cesty Článok 100 000 Slovník
Vytvorte skúšobný systém Prevádzkujeme slovník s približne 400 slovami a výrazmi. A naz odpovedať na otázku do textu na stránke nebolo ťažké.
Podobne system mb post lingvisticky 2-3 mesiace, 2 mesiace bol odladeny softverom. V tomto prípade môžete vylúčiť rovnaký text v RL aj v AL
Pri všetkej umelosti textu a prakticky obsahuje prebytok informácií v reálnych textoch, takéto informácie neexistujú. Táto práca je analógiou systému hrubého porozumenia pod jednou podmienkou: ak sa rozhodneme, čo je strojové porozumenie?
Princípy sú uložené v dvoch hlavných bodoch:
Po prvé, holistický obraz sveta ... na jednotlivé časti v pluralite. Pr0th. Preto je učenie často o „mozaikových“ vedomostiach. Takže v monografii francúzskeho výskumu A. Mola je mozaikovej kultúre a masovej komunikácii venovaná celá jedna časť, ktorá vytvára presne mozaikový obraz sveta
Najčastejšie tieto Pr0-i nie sú navzájom prepojené a kvôli nedostatku spoločného terminologického systému. Toto rozdelenie bráni formalizácii aj nominálneho poznania sveta. Je to spôsobené tým, že v rámci Pr0 opäť čelili deleniu na podobné poznatky.
Keď sa o nich hovorí a pokúša sa ich formovať, samotný izmus sa neučí prírastku vedomostí na úkor ich mozheriz-I. Vedomosti sa získavajú len vypĺňaním IGF, a nie odvodzovaním nových poznatkov zo starých. Medzitým dieťa, ktoré ovláda svet, modeluje a modernizuje.
Dôvody na vytvorenie takéhoto vedeckého systému sú úplne iné. Jedným z nich je nedostatok matového aparátu a empirizmu a diktátu praxe. Samotná absencia podložky MB prístroja a nevedomosť, že túto aplikáciu máte vo svojich rukách, ale nevidíte.
Účel sémantického kódu. Termín "význam".
Význam označuje tie záhadné javy, ktoré sa považujú za všeobecne známe, pretože sa neustále objavujú vo vedeckej aj každodennej komunikácii. V skutočnosti nielenže nemá žiadnu striktnú všeobecne akceptovanú definíciu, ale na deskriptívnej úrovni existuje široká škála úsudkov o tom, čo to je. Niekedy sa predpokladá, že význam patrí k tým najvšeobecnejším kategóriám, ktoré nepodliehajú definícii a treba ich brať ako danosť. V súčasnosti z dôvodu potreby riešiť množstvo skutočné úlohy teoretických aj aplikovaných, kde kľúčovú úlohu zohráva pojem významu, sú potrebné určité objasnenia tohto pojmu.
Ontológia významu nadobúda mimoriadny význam v súvislosti s tými zmenami v chápaní predmetu, predmetu a úloh lingvistiky, ktoré už nastali a vyskytujú sa v súčasnosti. Ak v období, keď dominovala absolutizácia jazyka ako sebestačnej autonómnej entity, význam často vystupoval len ako nejaký fakultatívny jav, ktorý bol na periférii záujmu bádateľov, tak pri odvolávaní sa na reč, text, diskurz význam postava ako jedna z najzákladnejších kategórií.
S.A. Vasiliev rozlišuje medzi subjektívnym a textovým významom. Subjektový význam je spojený s mechanizmom izolácie, uvedomenia si objektov reality. V tomto ohľade je základom významu podľa autora schopnosť určiť identitu a odlišnosť.„Veci sú nerozoznateľné, ak majú pre človeka rovnaký význam, tak ako sú nerozoznateľné opečiatkované kópie toho istého detailu“ (Vasiliev 1988 , 96).
S.A. Vasiliev vyčleňuje niekoľko zložiek významu. Jednou z týchto zložiek je objektívna objektivizácia ľudskej skúsenosti v podobe poznatkov o danom subjekte. Ale podľa autora tvorí len najvšeobecnejšiu zložku významu, intersubjektívnu vo svojom zdroji, majúcu univerzálnu hodnotu. Okrem toho význam obsahuje aj také zložky, ktoré vyjadrujú životné postoje jeho nositeľov, ich osobitný vzťah k objektívnemu svetu. Tieto dve zložky významu sú základom interindividuálnej komunikácie, a preto sú uložené v ich mysliach a fixované ako stabilné, opakujúce sa zložky, ktoré sa neustále reprodukujú v reči.
Okrem toho skladba významu zahŕňa individuálnu skúsenosť, hlboko osobný vzťah jednotlivca k objektu a z toho vyplývajúce očakávania, pripútanosti, emócie, zapamätateľné asociácie, ktoré odlišujú tento objekt od mnohých podobných.
To všetko tvorí podľa autorovej terminológie „významovú hodnotu“, ktorá súvisí nielen s objektívnym svetom, ale realizuje sa aj na úrovni textu, tvoriacej jednu z jeho sémantických rovín. Ďalšou rovinou textu je „význam-posolstvo“ t.j. čo chcel autor povedať.
To všetko umožňuje autorovi dospieť k záveru, že „zmyslové posolstvo“ obsiahnuté v texte je špecifickou vlastnosťou, ktorá ho odlišuje od všetkých ostatných predmetov, ktoré nie sú textami, ale „zmyslovou hodnotou“, ktorú text získava vďaka svojmu začleneniu do systém života ľudskú spoločnosť ju naopak približuje k iným objektom, robí z nej prvok objektívneho vesmíru, v ktorom sa odvíja všetok ľudský život.
S.A. Vasiliev pri opise „významu-posolstva“ upozorňuje na jednu jeho veľmi významnú črtu. Kladie si otázku: prečo je význam celého výroku vždy väčší ako súčet významov tvoriacich jeho slová? V tejto súvislosti analyzuje fragment románu M. Yu. Lermontova „Hrdina našej doby“, najmä Maksimychove slová charakterizujúce Pechorinovo správanie: ...“ Autor poznamenáva, že vyššie uvedené slová samy osebe neobnovujú význam. o správaní hrdinu. Verí, že samotné správanie, samotný akt tu „hovorí“: bojazlivosť, odvaha... Nech už tieto slová skombinujeme akokoľvek, význam nesmelosti, odvahy nedostaneme. Spojenie „a“ tu kontrastuje s významom nie dvoch častí frázy, ale dvoch spôsobov správania, ktoré chápeme na základe našej individuálnej a naučenej kolektívnej skúsenosti. V dôsledku toho autor vyvodzuje mimoriadne dôležitý záver pre pochopenie podstaty významu: „Tu dochádza k použitiu neverbálnych prostriedkov vo verbálnom texte“ (Vasiliev 1988, 98). To po prvé naznačuje mimojazykovú povahu významu a po druhé, že je vo vzťahu k textu vonkajší, keďže sa spája s aktualizáciou minulých skúseností, poznatkov a hodnotiacich-emocionálnych zložiek vedomia jednotlivca. Navyše z toho môžeme usudzovať, že význam nie je obsiahnutý priamo v texte, ale je odvodený od procesu porozumenia, v ktorom vlastne vzniká ako akási substancia. Tento záver vyplýva ako objektívny dôsledok vyplývajúci z úvahy autora, hoci je v rozpore s niektorými jeho ďalšími ustanoveniami.
Sémantika HTML kódu je vždy horúcou témou. Niektorí vývojári sa snažia vždy písať sémantický kód. Iní kritizujú dogmatických prívržencov. A niektorí ani netušia, čo to je a prečo je to potrebné. Sémantika je v HTML definovaná v značkách, triedach, ID a atribútoch, ktoré popisujú účel, ale nešpecifikujú presný obsah, ktorý obsahujú. Teda rozprávame sa o oddelení obsahu a jeho formátu.
Začnime jasným príkladom.
Zlá sémantika kódu
Dobrá sémantika kódu
Text článku napísaného niekým. Inko Gnito- jej autor.Názov článku
Či už si myslíte, že HTML5 je pripravené na použitie alebo nie, je isté, že použitie značky Ale nie všetko je tak jasne reprezentované HTML5 tagmi. Pozrime sa na súbor názvov tried a uvidíme, či spĺňajú sémantické požiadavky. Nie sémantický kód. Toto je klasický príklad. Každý Pracovné prostredie CSS pre modulárna mriežka používa tento typ názvov tried na definovanie prvkov mriežky. Či už je to „yui-b“, „mriežka-4“ alebo „spanHalf“ – takéto názvy sú bližšie k definovaniu značiek ako k popisu obsahu. Ich použitiu sa však vo väčšine prípadov pri práci s modulárnymi mriežkovými vzormi nedá vyhnúť. sémantický kód. Päta ( footer ) sa stala trvalou hodnotou vo webdizajne. Toto je spodná časť stránky, ktorá obsahuje prvky ako opakovaná navigácia, práva na používanie, informácie o autorovi atď. Táto trieda definuje skupinu pre všetky tieto prvky bez toho, aby ich opísal. Ak ste prešli na používanie HTML5, potom je lepšie použiť prvok Nie sémantický kód. Presne definuje obsah. Prečo však musí byť text veľký? Odlíšiť sa od ostatného menšieho textu? „standOut“ (výber) je v tomto prípade vhodnejší. Môžete sa rozhodnúť zmeniť štýl textu výberu, ale nerobiť nič s jeho veľkosťou, v takom prípade vás názov triedy môže zmiasť. sémantický kód. V tomto prípade hovoríme o určení úrovne dôležitosti prvku v rozhraní aplikácie (napríklad odseku alebo tlačidla). Prvok s viac vysoký stupeň môžu mať svetlé farby a väčšia veľkosť a prvky s nízky level môže obsahovať viac obsahu. Ale v tomto prípade neexistuje presná definícia štýlov, takže kód je sémantický. Táto situácia veľmi podobné používaniu značiek sémantický kód. Keby len každý názov triedy mohol byť tak jasne definovaný! V tomto prípade máme popis sekcie s obsahom, ktorého účel sa dá ľahko opísať, ako aj „tweety“, „stránkovanie“ alebo „admin-nav“. Nie sémantický kód. V tomto prípade hovoríme o nastavení štýlu pre prvý odsek na stránke. Táto technika sa používa na pritiahnutie pozornosti čitateľov k materiálu. Je lepšie použiť názov "intro", ktorý vynecháva zmienku o prvku. Pre takéto odseky je však ešte lepšie použiť selektor, napríklad článok p:prvý typ alebo h1 + p . Nie sémantický kód. Toto je veľmi všeobecný názov triedy, ktorý sa používa na organizáciu formátovania prvkov. Ale nie je v ňom nič, čo by sa týkalo popisu obsahu. Rôzni sémantickí teoretici odporúčajú v takýchto prípadoch použiť názov triedy ako „skupina“. Je pravdepodobné, že majú pravdu. Keďže tento prvok nepochybne slúži na zoskupenie niekoľkých ďalších prvkov a odporúčaný názov bude lepšie vystihovať jeho účel bez toho, aby sme sa ponorili do detailov. Nie sémantický kód. Príliš podrobný popis formátu obsahu. Je lepšie zvoliť iný názov, ktorý bude popisovať obsah, než jeho formát. sémantický kód. Trieda veľmi dobre popisuje stav obsahu. Napríklad správa o úspechu môže mať úplne iný štýl ako chybová správa. Nie sémantický kód. Tento príklad sa pokúša špecifikovať definíciu formátu obsahu, nie jeho účel. „plain-jane“ je veľmi podobný výrazu „normálny“ alebo „bežný“. Ideálny CSS kód by mal byť napísaný tak, že nie sú potrebné názvy tried ako „regular“, ktoré popisujú formát obsahu. Nie sémantický kód. Tieto typy tried sa zvyčajne používajú na definovanie prvkov lokality, ktoré by nemali byť zahrnuté v reťazci odkazov. V tomto prípade je lepšie použiť niečo ako rel=nofollow pre odkazy, ale nie triedu pre všetok obsah. Nie sémantický kód. Toto je pokus popísať formát obsahu, nie jeho účel. Povedzme, že máte na svojom webe dva články. A chcete sa ich spýtať rôzne štýly. Filmové recenzie budú mať modré pozadie, zatiaľ čo Breaking News bude mať červené pozadie a väčšie písmo. Jedným zo spôsobov, ako vyriešiť problém, je tento: Ďalší spôsob je tento: Ak sa spýtate niekoľkých vývojárov, ktorý kód je viac v súlade s požiadavkami sémantiky, väčšina ukáže na prvú možnosť. Perfektne ladí s materiálom. túto lekciu: Popis účelu bez odkazov na formátovanie. A druhá možnosť označuje formát ("blueBg" je názov triedy, ktorý je vytvorený z dvoch anglických slov, ktoré znamenajú "modré pozadie"). Ak sa náhle rozhodne zmeniť dizajn filmových recenzií - napríklad urobiť zelené pozadie, potom sa názov triedy "blueBg" zmení na nočnú moru vývojára. A názov „filmová recenzia“ umožní úplne jednoducho zmeniť štýly dizajnu pri zachovaní vynikajúcej úrovne podpory kódu. Ale nikto netvrdí, že prvý príklad je lepší vo všetkých prípadoch bez výnimky. Povedzme, že na mnohých miestach stránky je použitý určitý odtieň modrej. Napríklad je to pozadie pre nejakú časť päta a oblasti na bočnom paneli. Môžete použiť nasledujúci selektor: Recenzia filmu, päta > div:nth-of-type(2), stranou > div:nth-of-type(4) (pozadie: #c2fbff; ) Efektívne riešenie, pretože farba je určená iba na jednom mieste. Takýto kód sa však ťažko udržiava, pretože má dlhý selektor, ktorý je ťažké vizuálne vnímať. Tiež by to vyžadovalo, aby iné selektory definovali jedinečné štýly, čo by viedlo k opakovaniu kódu. Alebo môžete použiť iný prístup a nechať ich oddelené: Recenzia filmu ( pozadie: #c2fbff; /* Definícia farieb */ ) päta > div:nth-of-type(2) (pozadie: #c2fbff; /* A ešte jeden */ ) bokom > div:nth-of- typ(4) ( pozadie: #c2fbff; /* A ešte jeden */ ) Tento štýl pomáha udržiavať css súbor organizovanejšie ( rôznych oblastiach definované v rôznych častiach). Ale cena je opakovanie definícií. V prípade veľkých stránok môže definícia rovnakej farby dosiahnuť niekoľko tisíckrát. Strašné! Možným riešením by bolo použiť triedu ako "blueBg" na definovanie farby raz a vložiť ju do HTML, keď je potrebné použiť dizajn. Samozrejme, že je lepšie ho nazvať „mainBrandColor“ alebo „secondaryFont“, aby ste sa zbavili popisu formátovania. Môžete obetovať sémantiku kódu v prospech šetrenia zdrojov. Súvisiace články ,
,
, a tak ďalej, ale na iné prvky rozhrania.
Ale...







Zlaté čísla Ako predať krásne telefónne číslo
Ťažba kryptomien: čo to je jednoduchými slovami
Najlepší operačný systém pre laptop: Kompletná recenzia
Programy na sťahovanie hudby od spolužiakov Stiahnite si smutnú pesničku od spolužiakov zo sociálnej siete
Mobilná verzia prehliadača Yandex