Yöntem doğrusal regresyon bir dizi sıralı çift (x, y) ile en yakından eşleşen düz bir çizgiyi tanımlamamıza izin verir. Doğrusal denklem olarak bilinen düz bir çizginin denklemi aşağıda gösterilmiştir:
ŷ, verilen bir x değeri için y'nin beklenen değeridir,
x bağımsız bir değişkendir,
a - düz bir çizgi için y eksenindeki segment,
b - düz bir çizginin eğimi.
Aşağıdaki şekil bu kavramı grafik olarak göstermektedir:
Yukarıdaki şekil, ŷ = 2 + 0,5x denklemi ile tanımlanan çizgiyi göstermektedir. Y eksenindeki doğrunun y ekseniyle kesiştiği nokta; bizim durumumuzda a = 2. Doğrunun eğimi, b, doğrunun yüksekliğinin doğrunun uzunluğuna oranı 0,5 değerindedir. Pozitif eğim, çizginin soldan sağa doğru yükseldiği anlamına gelir. b = 0 ise doğru yataydır, yani bağımlı ve bağımsız değişkenler arasında bir ilişki yoktur. Başka bir deyişle, x değerini değiştirmek y değerini etkilemez.
Ŷ ve y genellikle karıştırılır. Grafik, 6 sıralı nokta çiftini ve bu denkleme göre bir doğruyu göstermektedir.
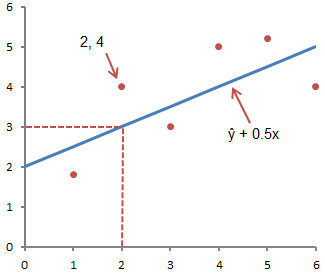
Bu şekil x = 2 ve y = 4 sıralı ikilisine karşılık gelen noktayı göstermektedir. NS= 2, ŷ'dir. Bunu aşağıdaki denklemle doğrulayabiliriz:
ŷ = 2 + 0,5x = 2 +0,5 (2) = 3.
y değeri gerçek noktadır ve ŷ değeri kullanılarak beklenen y değeridir. Doğrusal Denklem verilen bir x değeri için
Bir sonraki adım, sıralı çiftler kümesine en yakın olan lineer denklemi belirlemektir, bunu denklemin şeklini belirlediğimiz bir önceki makalede anlatmıştık.
Doğrusal Regresyonu Tanımlamak için Excel'i Kullanma
aracı kullanmak için regresyon analizi Excel'e gömülü, eklentiyi etkinleştirmeniz gerekir Analiz paketi... Sekmeye tıklayarak bulabilirsiniz Dosya -> Seçenekler(2007+), görünen iletişim kutusunda SeçeneklerExcel sekmeye git Eklentiler. alanında Kontrol Seç EklentilerExcel ve tıklayın Gitmek. Görünen pencerede karşısına bir onay işareti koyun Analiz paketi, basarız TAMAM.

sekmesinde Veri grup içinde analiz görünecek yeni düğme Veri analizi.

Eklentinin nasıl çalıştığını göstermek için, bir erkek ve bir kızın banyoda bir masayı paylaştığı verileri kullanalım. Küvet örneğimiz için verileri boş sayfanın A ve B sütunlarına girin.
sekmeye git Veri, grup içinde analiz Tıklayın Veri analizi. Görünen pencerede Veri analizi Seç regresyon gösterildiği gibi ve Tamam'ı tıklayın.

Pencerede gerekli regresyon parametrelerini ayarlayın regresyon, resimde gösterildiği gibi:

Tıklamak TAMAM. Aşağıdaki şekil elde edilen sonuçları göstermektedir:

Bu sonuçlar, kendi hesaplamalarımızla elde ettiğimiz sonuçlarla tutarlıdır.
Önceki gönderilerde, analiz genellikle yatırım fonu getirileri, Web sayfası yükleme süreleri veya meşrubat tüketimi gibi tek bir sayısal değişkene odaklandı. Bu ve sonraki notlarda, bir veya daha fazla sayısal değişkenin değerlerine bağlı olarak sayısal bir değişkenin değerlerini tahmin etme yöntemlerini ele alacağız.
Materyal çapraz kesen bir örnekle gösterilecektir. Bir giyim mağazasındaki satış hacmini tahmin etmek. Ayçiçekleri indirimli giyim mağazaları zinciri 25 yıldır sürekli genişlemektedir. Ancak, şirketin şu anda yeni satış noktaları seçme konusunda sistematik bir yaklaşımı bulunmamaktadır. Şirketin açılacağı yer yeni dükkan, sübjektif değerlendirmeler temelinde belirlenir. Seçim kriterleri karlı şartlar kiralama veya yöneticinin mağazanın ideal konumu hakkındaki fikri. Özel projeler ve planlama departmanının başında olduğunuzu hayal edin. Yeni mağaza açılışları için stratejik bir plan geliştirmekle görevlendirildiniz. Bu plan, yeni açılan mağazaların yıllık satışları için bir tahmin içermelidir. Alan satışının doğrudan gelir miktarı ile ilgili olduğuna inanıyor ve karar verme sürecinizde bu gerçeği dikkate almak istiyorsunuz. nasıl geliştirilir istatistiksel model Bu, yeni mağaza büyüklüğüne göre yıllık satışları tahmin ediyor mu?
Tipik olarak, bir değişkenin değerlerini tahmin etmek için regresyon analizi kullanılır. Amacı, en az bir bağımsız veya açıklayıcı değişkenin değerlerinden bağımlı değişkenin veya yanıtın değerlerini tahmin eden istatistiksel bir model geliştirmektir. Bu yazıda, bağımlı değişkenin değerlerini tahmin eden istatistiksel bir teknik olan basit doğrusal regresyona bakacağız. Y bağımsız değişkenin değerlerine göre x... Aşağıdaki notlar, bağımsız değişkenin değerlerini tahmin etmek için tasarlanmış bir çoklu regresyon modelini açıklayacaktır. Y birkaç bağımlı değişkenin değerleriyle ( X 1, X 2, ..., Xk).
Bir notu formatta veya formatta örnekler indirin
Regresyon modeli türleri
nerede ρ 1 - otokorelasyon katsayısı; Eğer ρ 1 = 0 (otokorelasyon yok), NS≈ 2; Eğer ρ 1 ≈ 1 (pozitif otokorelasyon), NS≈ 0; Eğer ρ 1 = -1 (negatif otokorelasyon), NS ≈ 4.
Pratikte, Durbin-Watson testinin uygulanması, değerin karşılaştırılmasına dayanır. NS kritik teorik değerlerle d L ve d U için belirli bir sayı gözlemler n, bağımsız sayısı model değişkenleri k(basit doğrusal regresyon için k= 1) ve önem düzeyi α. Eğer NS< d L , rastgele sapmaların bağımsızlığı hipotezi reddedilir (dolayısıyla pozitif bir otokorelasyon vardır); Eğer D> d U, hipotez reddedilmez (yani, otokorelasyon yoktur); Eğer d L< D < d U , bir karar vermek için yeterli bir temel yoktur. Hesaplanan değer ne zaman NS 2'yi aşıyor, ardından d L ve d U katsayının kendisi karşılaştırılmaz NS, ve ifade (4 - NS).
Excel'de Durbin-Watson istatistiklerini hesaplamak için Şekil 1'deki alt tabloya dönüyoruz. on dört Kalanın çekilmesi... (10) ifadesindeki pay, = SUMKVRAZN (dizi1; dizi2) işlevi ve payda = SUMKV (dizi) işlevi kullanılarak hesaplanır (Şekil 16).

Pirinç. 16. Durbin-Watson istatistiklerini hesaplamak için formüller
Örneğimizde NS= 0.883. Asıl soru şudur: Durbin-Watson istatistiğinin hangi değeri, pozitif bir otokorelasyon olduğu sonucuna varmak için yeterince küçük kabul edilmelidir? D değerini kritik değerlerle ilişkilendirmek gerekir ( d L ve d U) gözlem sayısına bağlı olarak n ve anlamlılık düzeyi α (Şekil 17).

Pirinç. 17. Durbin-Watson istatistiklerinin kritik değerleri (tablonun parçası)
Böylece evinize mal teslim eden bir mağazadaki satış hacmi probleminde bir bağımsız değişken vardır ( k= 1), 15 gözlem ( n= 15) ve anlamlılık düzeyi α = 0.05. Buradan, d L= 1.08 ve NSsen= 1.36. kadarıyla NS = 0,883 < d L= 1.08, artıklar arasında pozitif bir otokorelasyon vardır, en küçük kareler yöntemi kullanılamaz.
Eğim ve korelasyon katsayısı ile ilgili hipotezlerin test edilmesi
Yukarıdaki regresyon yalnızca tahmin için kullanılmıştır. Regresyon katsayılarını belirlemek ve bir değişkenin değerini tahmin etmek Y değişkenin belirli bir değeri için x en küçük kareler yöntemi kullanılmıştır. Ek olarak, tahminin ortalama karekök hatasına ve karışık korelasyon katsayısına baktık. Kalıntıların analizi, en küçük kareler yönteminin uygulanabilirlik koşullarının ihlal edilmediğini ve basit doğrusal regresyon modelinin yeterli olduğunu doğrularsa, örnek verilere dayanarak, değişkenler arasında doğrusal bir ilişki olduğu iddia edilebilir. Genel popülasyon.
BaşvuruT - eğim kriteri.β 1 popülasyonunun eğiminin sıfıra eşit olup olmadığını kontrol ederek, değişkenler arasında istatistiksel olarak anlamlı bir ilişki olup olmadığını belirlemek mümkündür. x ve Y... Bu hipotez reddedilirse, değişkenler arasında x ve Y doğrusal bir ilişki vardır. Boş ve alternatif hipotezler formüle edilir Aşağıdaki şekilde: Н 0: β 1 = 0 (doğrusal bağımlılık yoktur), Н1: β 1 ≠ 0 (doğrusal bağımlılık vardır). A-manastırı T-istatistik, örnek eğim ile popülasyonun varsayımsal eğimi arasındaki farkın, eğim tahmininin ortalama karekök hatasına bölünmesine eşittir:
(11) T = (B 1 – β 1 ) / S b 1
nerede B 1
Örnek verilere dayalı regresyon doğrusunun eğimi, β1 düz genel popülasyonun varsayımsal eğimidir, ![]() ve test istatistikleri T sahip T-ile dağıtım n - 2özgürlük derecesi.
ve test istatistikleri T sahip T-ile dağıtım n - 2özgürlük derecesi.
α = 0.05'te mağaza büyüklüğü ile yıllık satışlar arasında istatistiksel olarak anlamlı bir ilişki olup olmadığını kontrol edelim. T-kriter kullanılırken diğer parametrelerle birlikte görüntülenir Analiz paketi(seçenek regresyon). Analiz Paketinin tam sonuçları Şekil 2'de gösterilmektedir. Şekil 4'te, t-istatistikleri ile ilgili bir parça, Şekil 4'te gösterilmektedir. on sekiz.
Pirinç. 18. Başvuru sonuçları T
mağaza sayısından beri n= 14 (bkz. Şekil 3), kritik değer T- α = 0.05 önem düzeyindeki istatistikler şu formülle bulunabilir: t L= ÖĞRENCİ.OBR (0.025; 12) = –2.1788, burada 0.025 anlamlılık düzeyinin yarısıdır ve 12 = n – 2; t U= ÖĞRENCİ.OBR (0.975; 12) = +2.1788.
kadarıyla T-istatistik = 10.64> t U= 2.1788 (Şekil 19), boş hipotez H 0 sapar. Diğer tarafta, r-değer NS= 1 ÖĞRENCİ.DAĞ (D3; 12; DOĞRU) formülüyle hesaplanan = 10.6411, yaklaşık olarak sıfıra eşittir, dolayısıyla hipotez H 0 tekrar sapar. gerçeği r-değerin neredeyse sıfıra eşit olması, mağaza büyüklüğü ile yıllık satışlar arasında gerçek bir doğrusal ilişki olmasaydı, doğrusal regresyon kullanarak bunu tespit etmenin neredeyse imkansız olacağı anlamına gelir. Sonuç olarak, mağazalardaki ortalama yıllık satışlar ile büyüklükleri arasında istatistiksel olarak anlamlı bir doğrusal ilişki vardır.

Pirinç. 19. Genel popülasyonun eğimi ile ilgili hipotezin 0,05 ve 12 serbestlik derecesi anlamlılık düzeyinde test edilmesi
BaşvuruF - eğim kriteri. Basit doğrusal regresyonun eğim hipotezlerini test etmek için alternatif bir yaklaşım, F-kriter. Hatırlamak F-kriter, iki varyans arasındaki ilişkiyi test etmek için kullanılır (ayrıntılara bakın). Eğim hipotezini test ederken, rastgele hataların ölçüsü hata varyansıdır (karelerinin toplamının serbestlik derecesi sayısına bölümü), bu nedenle F- kriter, regresyon tarafından açıklanan varyans oranını kullanır (yani, değerler SSR bağımsız değişken sayısına bölünmesiyle k), hataların varyansına ( MSE = S Yx 2 ).
A-manastırı F-İstatistikler, regresyona bağlı sapmanın (MSR) ortalama karesinin hatanın varyansına (MSE) bölünmesine eşittir: F = MSR/ MSE, nerede MSR =SSR / k, MSE =SSE/(n- k - 1), k- regresyon modelindeki bağımsız değişkenlerin sayısı. Test istatistikleri F sahip F-ile dağıtım k ve n- k - 1özgürlük derecesi.
NS belirli bir seviyeα anlamlı ise, karar kuralı şu şekilde formüle edilir: F> Fsen, boş hipotez reddedilir; aksi halde reddedilmez. Varyans analizinin bir özet tablosu şeklinde sunulan sonuçlar, Şekil 2'de gösterilmektedir. yirmi.

Pirinç. 20. Hipotezi test etmek için ANOVA tablosu İstatistiksel anlamlılık regresyon katsayısı
aynı şekilde T-kriter F-kriter kullanıldığında tabloda görüntülenir Analiz paketi(seçenek regresyon). Tamamen iş sonuçları Analiz paketiŞekilde gösterilmektedir. 4, ilgili bir parça F-istatistikler - Şek. 21.

Pirinç. 21. Başvuru sonuçları F-Paket kullanılarak elde edilen kriterler Excel analizi
F istatistiği 113.23'tür ve r-değer sıfıra yakın (hücre ÖnemiF). Anlamlılık düzeyi α 0.05 ise kritik değeri belirleyiniz. F-bir ve 12 serbestlik dereceli dağılımlar formülle verilebilir FU= F. OBR (1-0.05; 1; 12) = 4.7472 (Şekil 22). kadarıyla F = 113,23 > FU= 4.7472 ve r-değer 0'a yakın< 0,05, нулевая гипотеза H 0 sapar, yani mağaza büyüklüğü, yıllık satışlarıyla yakından ilgilidir.

Pirinç. 22. Genel popülasyonun eğimi hakkındaki hipotezin 0,05 anlamlılık düzeyinde, bir ve 12 serbestlik derecesiyle test edilmesi
β 1 eğimini içeren güven aralığı. Değişkenler arasında doğrusal bir ilişkinin varlığına ilişkin hipotezi test etmek için β 1 eğimini içeren bir güven aralığı oluşturabilir ve β 1 = 0 varsayımsal değerinin bu aralığa ait olduğundan emin olabilirsiniz. β 1 eğimini içeren güven aralığının merkezi, örnek eğimdir. B 1 , ve sınırları miktarlardır b1 ±t n –2 S b 1
Şekilde gösterildiği gibi. on sekiz, B 1 = +1,670, n = 14, S b 1 = 0,157. T 12 = ÖĞRENCİ.OBR (0.975; 12) = 2.1788. Buradan, b1 ±t n –2 S b 1 = +1.670 ± 2.1788 * 0.157 = +1.670 ± 0.342 veya + 1.328 ≤ β 1 ≤ +2.012. Bu nedenle, 0.95 olasılıkla genel popülasyonun eğimi +1.328 ila +2.012 (yani 1.328.000 ila 2.012.000 ABD Doları) aralığındadır. Bu değerler sıfırdan büyük olduğu için yıllık satışlar ile mağaza alanı arasında istatistiksel olarak anlamlı doğrusal bir ilişki vardır. Güven aralığı sıfırı içeriyorsa, değişkenler arasında bağımlılık olmazdı. Ek olarak, güven aralığı, mağaza alanındaki her artışın 1.000 metrekare olduğu anlamına gelir. fit, ortalama satışlarda 1.328.000 $ ila 2.012.000 $ arasında bir artışa neden olur.
kullanımT - korelasyon katsayısı için kriter. korelasyon katsayısı tanıtıldı r, iki sayısal değişken arasındaki ilişkinin bir ölçüsüdür. İki değişken arasında istatistiksel olarak anlamlı bir fark olup olmadığını belirlemek için kullanılabilir. anlamlı bağlantı... Her iki değişkenin genel popülasyonları arasındaki korelasyon katsayısını ρ sembolü ile gösterelim. Boş ve alternatif hipotezler aşağıdaki gibi formüle edilir: H 0: ρ = 0 (korelasyon yok), H1: ρ ≠ 0 (bir korelasyon var). Bir korelasyonun varlığını kontrol etme:

nerede r = + , Eğer B 1 > 0, r = – , Eğer B 1 < 0. Тестовая статистика T sahip T-ile dağıtım n - 2özgürlük derecesi.
Mağazalar zinciri ile ilgili problemde Ayçiçekleri r 2= 0.904 ve b1- +1.670 (bkz. şekil 4). kadarıyla b1> 0, yıllık satışlar ile mağaza büyüklüğü arasındaki korelasyon katsayısı r= + √0.904 = +0.951. Hadi kontrol edelim sıfır hipotezi kullanarak bu değişkenler arasında bir ilişki olmadığını belirten T-İstatistik:

α = 0.05 anlamlılık düzeyinde, sıfır hipotezi reddedilmelidir çünkü T= 10.64> 2.1788. Dolayısıyla yıllık satışlar ile mağaza büyüklüğü arasında istatistiksel olarak anlamlı bir ilişki olduğu söylenebilir.
Güven aralıkları ve hipotezleri test etme kriterleri, popülasyon eğimi hakkında sonuçlar tartışılırken birbirinin yerine kullanılır. Ancak, korelasyon katsayısını içeren güven aralığını hesaplamak, istatistiğin örnek dağılımının şekli nedeniyle daha zor görünmektedir. r gerçek korelasyon katsayısına bağlıdır.
Matematiksel beklenti tahmini ve bireysel değerlerin tahmini
Bu bölüm, beklenen yanıtı değerlendirme yöntemlerini tartışır Y ve bireysel değerlerin tahminleri Y değişkenin verilen değerlerinde x.
Bir güven aralığı oluşturma.Örnek 2'de (yukarıdaki bölüme bakın en küçük kareler yöntemi) regresyon denklemi, değişkenin değerini tahmin etmeyi mümkün kıldı Y x... Bir perakende satış noktası için yer seçme probleminde, 4000 metrekarelik bir mağazada ortalama yıllık satışlar. ft 7.644 milyon dolara eşitti.Ancak, genel nüfusun matematiksel beklentisinin bu tahmini noktasaldır. genel popülasyonun matematiksel beklentisini değerlendirmek için bir güven aralığı kavramı önerildi. Benzer şekilde, kavramı tanıtabiliriz beklenen yanıt için güven aralığı değişkenin belirli bir değeri için x:
nerede  , =
B 0
+
B 1
X ben- tahmin edilen değer değişkendir Y NS x = X ben, S YX- kök-ortalama-kare hatası, n- örnek boyut, xben- değişkenin set değeri x, µ
Y|x =
xben- bir değişkenin matematiksel beklentisi Y NS NS = X ben, SSX =
, =
B 0
+
B 1
X ben- tahmin edilen değer değişkendir Y NS x = X ben, S YX- kök-ortalama-kare hatası, n- örnek boyut, xben- değişkenin set değeri x, µ
Y|x =
xben- bir değişkenin matematiksel beklentisi Y NS NS = X ben, SSX = 
Formül (13)'ün analizi, güven aralığının genişliğinin birkaç faktöre bağlı olduğunu göstermektedir. Belirli bir önem düzeyinde, ortalama karekök hatası kullanılarak ölçülen regresyon çizgisi etrafındaki salınımların genliğinde bir artış, aralığın genişliğinde bir artışa yol açar. Öte yandan, beklendiği gibi, örneklem büyüklüğündeki artışa aralığın daralması eşlik etmektedir. Ayrıca değerlere bağlı olarak aralığın genişliği değişir. xben... Değişkenin değeri ise Y miktarlar için tahmin edilen x ortalamaya yakın , güven aralığı, ortalamadan uzak değerler için yanıtı tahmin etmekten daha dar olduğu ortaya çıkıyor.
Bir mağaza için yer seçerken 4.000 metrekare alana sahip tüm mağazaların yıllık ortalama satışları için %95 güven aralığı çizmek istediğimizi varsayalım. ayak:

Sonuç olarak, 4.000 metrekare alana sahip tüm mağazalarda yıllık ortalama satışlar. fit, %95 olasılıkla 6.971 ile 8.317 milyon dolar aralığında yer alıyor.
Tahmin edilen değer için güven aralığının hesaplanması. Değişkenin belirli bir değerinde yanıtın matematiksel beklentisi için güven aralığına ek olarak x, genellikle tahmin edilen değer için güven aralığını bilmek gerekir. Bu güven aralığını hesaplama formülü formül (13)'e çok benzer olmasına rağmen, bu aralık parametre tahminini değil tahmin edilen değeri içerir. Öngörülen yanıt aralığı Yx = Xi değişkenin belirli bir değerinde xben formülle belirlenir:

Bir mağaza için yer seçerken, 4000 m2 alana sahip bir mağazanın tahmini yıllık satışları için %95'lik bir güven aralığı çizmek istediğimizi varsayalım. ayak:

Bu nedenle, 4000 m2 alana sahip bir mağaza için öngörülen yıllık satış hacmi. ft, %95 olasılıkla 5.433 ile 9.854 milyon dolar aralığındadır.Gördüğünüz gibi, yanıtın tahmin edilen değeri için güven aralığı, matematiksel beklentisi için güven aralığından çok daha geniştir. Bunun nedeni, bireysel değerleri tahmin etmedeki değişkenliğin, matematiksel beklentiyi değerlendirirken olduğundan çok daha büyük olmasıdır.
Regresyonla İlgili Tuzaklar ve Etik Sorunlar
Regresyon analizi ile ilgili zorluklar:
- En küçük kareler yönteminin uygulanabilirlik koşullarının göz ardı edilmesi.
- En küçük kareler yönteminin uygulanabilirlik koşullarının hatalı değerlendirilmesi.
- En küçük kareler yönteminin uygulanabilirlik koşulları ihlal edildiğinde alternatif yöntemlerin yanlış seçilmesi.
- Araştırma konusu hakkında derin bilgi sahibi olmadan regresyon analizinin uygulanması.
- Açıklayıcı değişken aralığının ötesindeki regresyonun ekstrapolasyonu.
- İstatistiksel ve nedensel ilişkiler arasındaki karışıklık.
Geniş kullanım elektronik tablolar ve istatistiksel yazılımlar, regresyon analizinin kullanılmasını engelleyen hesaplama sorunlarını ortadan kaldırdı. Ancak bu durum regresyon analizinin yeterli nitelik ve bilgiye sahip olmayan kullanıcılar tarafından kullanılmaya başlanmasına neden olmuştur. Pek çoğu, en küçük kareler yönteminin uygulanabilirliği için koşullar hakkında hiçbir fikri yoksa ve uygulamalarını nasıl doğrulayacaklarını bilmiyorsa, kullanıcılar alternatif yöntemleri nasıl bilebilirler?
Araştırmacı, taşlama sayılarına - vardiya, eğim ve karışık korelasyon katsayısının hesaplanmasına kapılmamalıdır. Daha derin bilgiye ihtiyacı var. Bunu ders kitaplarından alınan klasik bir örnekle açıklayalım. Anscombe, Şekil 2'de gösterilen dört veri kümesinin hepsinin olduğunu gösterdi. 23 aynı regresyon parametrelerine sahiptir (Şekil 24).

Pirinç. 23. Dört set yapay veri

Pirinç. 24. Dört yapay veri setinin regresyon analizi; ile yapılır Analiz paketi(resmi büyütmek için resme tıklayın)
Dolayısıyla, regresyon analizi açısından tüm bu veri kümeleri tamamen aynıdır. Analiz bitseydi çok şey kaybederdik. kullanışlı bilgi... Bu, bu veri kümeleri için çizilen dağılım grafikleri (Şekil 25) ve kalıntı grafikleri (Şekil 26) ile kanıtlanmıştır.

Pirinç. 25. Dört veri kümesi için dağılım grafikleri
Dağılım grafikleri ve kalıntı grafikleri, bu verilerin birbirinden farklı olduğunu göstermektedir. Düz bir çizgi boyunca dağıtılan tek küme A kümesidir. A kümesinden hesaplanan artıkların grafiğinin hiçbir düzenliliği yoktur. Aynı şey B, C ve D Kümeleri için söylenemez. B Kümesi için çizilen dağılım grafiği, belirgin bir ikinci dereceden modeli göstermektedir. Bu sonuç, parabolik bir şekle sahip olan artıkların grafiği ile doğrulanır. Dağılım grafiği ve artık grafiği, veri kümesi B'nin bir aykırı değer içerdiğini gösterir. Bu durumda aykırı değeri veri setinden çıkarmak ve analizi tekrarlamak gerekir. Gözlemlerdeki aykırı değerleri tespit etmeye ve ortadan kaldırmaya yönelik bir tekniğe etki analizi denir. Aykırı değer ortadan kaldırıldıktan sonra, modelin yeniden değerlendirilmesinin sonucu tamamen farklı olabilir. D veri kümesinden bir dağılım grafiği, ampirik modelin büyük ölçüde bireysel bir yanıta bağlı olduğu olağandışı durumu göstermektedir ( 8 = 19, Y 8 = 12.5). Bu tür regresyon modellerinin özel bir dikkatle hesaplanması gerekir. Bu nedenle, saçılım ve artık parseller son derece gerekli araç regresyon analizi ve bunun ayrılmaz bir parçası olmalıdır. Onlar olmadan regresyon analizi güvenilir değildir.

Pirinç. 26. Dört veri kümesi için artık grafikleri
Regresyon analizinde tuzaklardan nasıl kaçınılır:
- Değişkenler arasındaki olası ilişkinin analizi x ve Y her zaman bir dağılım grafiği çizerek başlayın.
- Regresyon analizinin sonuçlarını yorumlamadan önce uygulanabilirlik koşullarını kontrol edin.
- Artıkları bağımsız değişkene karşı çizin. Bu, ampirik modelin gözlem sonuçlarıyla nasıl tutarlı olduğunu belirlemenize ve varyans sabitliğinin ihlalini saptamanıza olanak tanır.
- Normal hata varsayımını test etmek için histogramları, gövde ve yaprak grafiklerini, kutu grafiklerini ve normal dağılım grafiklerini kullanın.
- En küçük kareler yönteminin uygulanabilirlik koşulları karşılanmıyorsa, alternatif yöntemler(örneğin, ikinci dereceden veya çoklu regresyon modelleri).
- En küçük kareler yönteminin uygulanabilirliği için koşullar karşılanıyorsa, regresyon katsayılarının istatistiksel anlamlılığına ilişkin hipotezin test edilmesi ve matematiksel beklenti ile tahmin edilen yanıt değerini içeren güven aralıklarının oluşturulması gerekir.
- Bağımlı değişkenin değerlerini bağımsız değişken aralığı dışında tahmin etmekten kaçının.
- İstatistiksel ilişkilerin her zaman nedensel olmadığını unutmayın. Değişkenler arasındaki korelasyonun, aralarında nedensel bir ilişki olduğu anlamına gelmediğini unutmayın.
Özet. Blok şemada gösterildiği gibi (Şekil 27), not basit doğrusal regresyon modelini, uygulanabilirliği için koşulları ve bu koşulların nasıl kontrol edileceğini açıklamaktadır. Dikkate alınan T- regresyon eğiminin istatistiksel önemini kontrol etmek için kriter. Bağımlı değişkenin değerlerini tahmin etmek için kullandık Regresyon modeli... Yıllık satış hacminin mağaza alanına bağımlılığının araştırıldığı bir perakende satış noktası için yer seçimi ile ilgili bir örnek düşünülmüştür. Elde edilen bilgiler, mağazanın yerini daha doğru seçmenize ve yıllık satışlarını tahmin etmenize olanak tanır. Aşağıdaki notlarda, regresyon analizi tartışmamıza devam edeceğiz ve ayrıca çoklu regresyon modellerine bakacağız.

Pirinç. 27. Notun blok şeması
Yöneticiler için Levin ve diğer İstatistikler kitabının kullanılmış materyalleri. - E.: Williams, 2004 .-- s. 792-872
Bağımlı değişken kategorik ise lojistik regresyon uygulanmalıdır.
içinde regresyon analizi Microsoft Excel- en tam kılavuzlar iş zekası alanında regresyon analizi problemlerini çözmek için MS Excel kullanımı hakkında. Konrad Karlberg net bir şekilde açıklıyor teorik sorular Hem kendi başınıza regresyon analizi yaparken hem de başkaları tarafından yapılan analiz sonuçlarını değerlendirirken birçok hatadan kaçınmanıza yardımcı olacaktır. Basit korelasyonlar ve t-testlerinden çoklu analiz kovaryansına kadar tüm materyaller, gerçek örnekler ve eşlik Detaylı Açıklama uygun adım adım prosedürler.
Kitap, Excel'in regresyon işlevleriyle ilişkili özellikleri ve çelişkileri tartışıyor, seçeneklerin her birini ve her bir argümanı kullanmanın sonuçlarını inceliyor ve çoğu durumda regresyon yöntemlerinin güvenilir bir şekilde nasıl uygulanacağını açıklıyor. farklı bölgeler, tıbbi araştırmalardan finansal analizlere kadar.
Konrad Karlberg. Microsoft Excel'de regresyon analizi. - M.: Diyalektik, 2017 .-- 400 s.
Bir notu formatta veya formatta örnekler indirin
Bölüm 1. Veri Değişkenliğini Tahmin Etme
İstatistikçilerin emrinde birçok varyasyon (değişkenlik) göstergesi vardır. Bunlardan biri, bireysel değerlerin ortalamadan sapmalarının karelerinin toplamıdır. Excel, bunun için KARE () işlevini kullanır. Ancak varyans daha yaygın olarak kullanılır. Varyans, sapmaların ortalama karesidir. Varyans, incelenen veri kümesindeki değerlerin sayısına duyarsızdır (boyut sayısı arttıkça sapmaların karelerinin toplamı artar).
Excel, varyans döndüren iki işlev sunar: VAR.G () ve VAR.V ():
- İşlenecek değerler bir popülasyon oluşturuyorsa DISP.G () işlevini kullanın. Yani aralıkta yer alan değerler sizi ilgilendiren tek değerlerdir.
- İşlenecek değerler daha büyük bir popülasyondan bir örnek oluşturuyorsa VAR.In () işlevini kullanın. Varyansını da tahmin edebileceğiniz ek değerler olduğu varsayılır.
Popülasyona dayalı olarak ortalama veya korelasyon katsayısı gibi bir miktar hesaplanırsa buna parametre denir. Bir örnek temelinde hesaplanan benzer bir değere istatistik denir. Sapmaları sayma ortalamadan v bu set, başka herhangi bir değerden saydığınızdan daha az büyüklükteki sapmaların karelerinin toplamını alacaksınız. Benzer bir ifade varyans için de geçerlidir.
Örnek boyutu ne kadar büyük olursa, hesaplanan istatistik değeri o kadar doğru olur. Ancak, istatistik değerinin parametre değeriyle çakıştığından emin olabileceğiniz, genel popülasyonun boyutundan daha küçük bir boyuta sahip tek bir örnek yoktur.
Diyelim ki, ortalamaları popülasyon ortalamasından farklı olan, ancak fark ne kadar küçük olursa olsun, 100 büyüme değerine sahip bir kümeniz var. Örnek için varyansı hesaplayarak, örneğin 4 gibi bir değer elde edersiniz. Bu değer, örnek ortalama dışındaki herhangi bir değere göre 100 büyüme değerinin her birinin sapmasını hesaplayarak elde edilebilecek diğerlerinden daha küçüktür. , genel nüfusun gerçek ortalaması dahil ve buna göre. Bu nedenle, hesaplanan varyans, örnek ortalamayı değil, genel popülasyonun bir parametresini bir şekilde bilip kullansaydınız elde edeceğiniz varyanstan daha az ölçüde farklı olacaktır.
Örnek ortalama kareler toplamı, popülasyonun varyansının daha düşük tahminini verir. Bu şekilde hesaplanan varyansa denir. yerinden edilmiş değerlendirme. Sapmayı ortadan kaldırmak ve yansız bir tahmin elde etmek için sapmaların karelerinin toplamını ikiye bölmenin yeterli olduğu ortaya çıktı. n, nerede nörnek boyutudur ve n - 1.
Miktar n - 1 serbestlik derecesi sayısı (sayısı) olarak adlandırılır. var Farklı yollar Bu miktarın hesaplanması, hepsi ya örneklem büyüklüğünden bir sayının çıkarılmasını ya da gözlemlerin düştüğü kategorilerin sayısını saymayı içeriyor olsa da.
DISP.G () ve DISP.B () işlevleri arasındaki farkın özü aşağıdaki gibidir:
- VARP.G'de (), karelerin toplamı gözlem sayısına bölünür ve bu nedenle varyansın taraflı bir tahminini, yani gerçek ortalamayı temsil eder.
- VAR işlevinde. ()'de, karelerin toplamı gözlem sayısı eksi 1'e bölünür, yani. Bu örneğin çıkarıldığı genel popülasyonun varyansına ilişkin daha doğru, tarafsız bir tahmin veren serbestlik derecesi sayısı ile.
Standart sapma (rus. standart sapma, SD) - evet Kare kök varyanstan:
Sapmaların karesini alma, ölçüm ölçeğini orijinalin karesi olan başka bir metriğe dönüştürür: metre - in metrekare, dolar - kare dolar vb. Standart sapma, varyansın kare köküdür ve bu nedenle bizi orijinal birimlerimize döndürür. Hangisi daha uygun.
Verilerin bazı manipülasyonlarından sonra standart sapmayı hesaplamak genellikle gereklidir. Ve bu durumlarda sonuçlar şüphesiz standart sapmalar olsa da, genellikle denir. standart hatalar... Standart ölçüm hatası, standart orantı hatası, ortalamanın standart hatası dahil olmak üzere çeşitli standart hata türleri vardır.
50 eyaletin her birinde rastgele seçilmiş 25 yetişkin erkekten boy verilerini topladığınızı varsayalım. Ardından, her eyaletteki yetişkin erkeklerin ortalama boyunu hesaplarsınız. Elde edilen 50 ortalama değer de gözlem olarak kabul edilebilir. Bundan, standart sapmalarını hesaplayabilirsiniz, ki bu ortalamanın standart hatası... Pirinç. 1. 1250 temel bireysel değerlerin dağılımını (50 eyaletin her birinde 25 erkeğin boyuna ilişkin veriler) 50 eyaletin ortalama değerlerinin dağılımıyla karşılaştırır. Ortalamanın standart hatasını tahmin etmek için formül (yani, bireysel gözlemler değil, ortalamaların standart sapması):
![]()
ortalamanın standart hatası nerede; s- temel gözlemlerin standart sapması; n- örneklemdeki gözlem sayısı.

Pirinç. 1. Durumdan duruma ortalama değerlerdeki varyasyon, bireysel gözlemlerdeki varyasyondan önemli ölçüde daha azdır.
Yunanca ve Türkçenin kullanımına ilişkin istatistiklerde bir anlaşma vardır. Latin harfleri istatistiksel miktarları belirtmek için. Genel popülasyonun parametrelerini Yunan harfleriyle ve örnek istatistikleri Latince olarak belirtmek gelenekseldir. Bu nedenle, eğer gelir popülasyonun standart sapması hakkında, onu σ olarak yazıyoruz; örneğin standart sapması dikkate alınırsa, s gösterimini kullanırız. Ortalamaları ifade eden sembollere gelince, birbirleriyle pek uyuşmuyorlar. Nüfus ortalaması, Yunanca μ harfi ile gösterilir. Bununla birlikte, X̅ sembolü geleneksel olarak örnek ortalamasını temsil etmek için kullanılır.
z-puanı standart sapma birimlerindeki dağılımda gözlemin konumunu ifade eder. Örneğin, z = 1.5, gözlemin daha yüksek değerler yönünde ortalamadan 1.5 standart sapma olduğu anlamına gelir. Terim z-puanı bireysel değerlendirmeler için kullanılır, ör. atfedilen ölçümler için bireysel elemanlarörnekleme. Bu tür istatistikçiler için (örneğin, durum ortalaması) terimini kullanın. z değeri:

burada X̅ numunenin ortalamasıdır, μ genel popülasyonun ortalamasıdır, numune setinin ortalamasının standart hatasıdır:
![]()
burada σ genel popülasyonun standart hatasıdır (bireysel ölçümler), nÖrnek boyutudur.
Diyelim ki bir golf kulübünde eğitmensiniz. Uzun süredir menzil ölçme imkanınız var ve biliyorsunuz ki ortalama 205 yard ve standart sapma 36 yard. Menzilinizi 10 yarda artıracağını iddia eden yeni bir sopa teklif edildi. Sonraki 81 kulüp müdaviminin her birinden yeni bir kulüple bir deneme vuruşu denemesini ve menzillerini kaydetmesini istersiniz. Yeni kulübün ortalama vuruş aralığının 215 yard olduğu ortaya çıktı. 10 yard (215 - 205) arasındaki farkın yalnızca örnekleme hatasından kaynaklanma olasılığı nedir? Ya da başka bir deyişle: Daha büyük testlerde, yeni kulübün mevcut uzun vadeli ortalama 205 yarda göre vuruş aralığında bir artış göstermeme olasılığı nedir?
Bunu bir z değeri üreterek test edebiliriz. Ortalamanın standart hatası:
![]()
O zaman z değeri:

Örnek ortalamasının popülasyon ortalamasından 2.5σ olma olasılığını bulmamız gerekiyor. Olasılık küçükse, farklılıklar şanstan değil, yeni kulübün kalitesinden kaynaklanmaktadır. Excel, bir z puanı olasılığını belirlemek için hazır bir işleve sahip değildir. Ancak, = 1-NORM.ST.DAĞ (z-değeri; DOĞRU) formülünü kullanabilirsiniz; burada NORM.S.DAĞ () z-değerinin solundaki normal eğrinin altındaki alanı döndürür (Şekil 2) .

Pirinç. 2. NORM.S.DAĞ () işlevi, z değerinin solundaki eğrinin altındaki alanı döndürür; resmi büyütmek için üzerine tıklayın sağ tık fare ve seç Resmi yeni sekmede aç
NORM.ST.DIST () işlevinin ikinci argümanı iki değer alabilir: DOĞRU - işlev, ilk argüman tarafından belirtilen noktanın solundaki eğrinin altındaki alanın alanını döndürür; YANLIŞ - işlev, ilk bağımsız değişken tarafından belirtilen noktada eğrinin yüksekliğini döndürür.
Popülasyonun ortalaması (μ) ve standart sapması (σ) bilinmiyorsa, t değeri kullanılır (ayrıntılara bakın). z- ve t-değer yapıları, popülasyon parametresinin σ bilinen değeri yerine t-değerini bulmak için numune sonuçlarından elde edilen standart sapma s'nin kullanılması bakımından farklılık gösterir. Normal eğri tek bir şekle sahiptir ve t-değerlerinin dağılımının şekli, df serbestlik derecesi sayısına bağlı olarak değişir (İngilizce'den. özgürlük derecesi) temsil ettiği örneklemdir. Numunenin serbestlik derecesi sayısı n - 1, nerede n- örnek boyutu (Şekil 3).

Pirinç. 3. σ parametresinin bilinmediği durumlarda ortaya çıkan t-dağılımlarının şekli, normal dağılımın şeklinden farklıdır.
Excel'in t-dağılımı için Öğrencinin t-dağılımı olarak da adlandırılan iki işlevi vardır: ÖĞRENCİ.DAĞ () verilen t değerinin solundaki eğrinin altındaki alanı döndürür ve ÖĞRENCİ.DAĞ.PX () alanı döndürür sağdaki eğrinin altında.
Bölüm 2. Korelasyon
Korelasyon, bir sıralı çiftler kümesinin öğeleri arasındaki ilişkinin bir ölçüsüdür. Korelasyon ile karakterize edilir Pearson korelasyon katsayıları- r. Katsayı –1.0 ila +1.0 aralığında değerler alabilir.

nerede Sx ve S y- değişkenlerin standart sapmaları NS ve Y, S xy- kovaryans:

Bu formülde kovaryans, değişkenlerin standart sapmalarına bölünür. NS ve Y böylece kovaryanstan birim ölçekleme etkilerini ortadan kaldırır. Excel, CORREL () işlevini kullanır. Bu işlevin adı, STDEV (), DISP () veya COVARIATION () gibi işlevlerin adlarında kullanılan niteleyici Г ve В öğelerini içermez. Numune için korelasyon katsayısı yanlı bir tahmin olmasına rağmen, yanlılığın nedeni, varyans veya standart sapma durumundan farklıdır.
Genel korelasyon katsayısının değerine bağlı olarak (genellikle Yunan harfi ile gösterilir) ρ ), korelasyon katsayısı r azalan örneklem büyüklüğü ile artan yanlılık etkisi ile yanlı bir tahmin verir. Bununla birlikte, bu önyargıyı, örneğin standart sapmayı hesaplarken yaptığımız, gözlem sayısını değil, karşılık gelen formüle serbestlik derecesi sayısını koyduğumuzda yaptığımız gibi düzeltmeye çalışmıyoruz. Gerçekte, kovaryansı hesaplamak için kullanılan gözlem sayısının büyüklük üzerinde hiçbir etkisi yoktur.
Standart korelasyon katsayısı, doğrusal olarak ilişkili değişkenlerle kullanılmak üzere tasarlanmıştır. Verilerdeki (aykırı değerler) doğrusal olmama ve/veya hatalar korelasyon katsayısının yanlış hesaplanmasına yol açar. Veri sorunlarını tanılamak için dağılım grafiklerinin kullanılması önerilir. Hem yatay hem de dikey eksenleri değer eksenleri olarak değerlendiren Excel'deki tek grafik türüdür. Bir çizgi grafik ise, sütunlardan birini, verilerin resmini bozan bir kategori ekseni olarak tanımlar (Şekil 4).

Pirinç. 4. Regresyon çizgileri aynı görünüyor, ancak denklemlerini karşılaştırın
Çizgi grafiği çizmek için kullanılan gözlemler, yatay eksen boyunca eşit uzaklıktadır. Bu eksendeki onay işaretleri, sayısal değerler değil, yalnızca etiketlerdir.
Korelasyon genellikle nedensellik anlamına gelse de, bunun kanıtı olarak kullanılamaz. İstatistikler, bir teorinin doğru mu yanlış mı olduğunu göstermek için kullanılmaz. Gözlem sonuçlarının rakip açıklamalarını hariç tutmak için, planlı deneyler... İstatistikler, bu tür deneyler sırasında toplanan bilgileri özetlemek ve mevcut kanıtlara dayanarak verilen bir kararın yanlış olma olasılığını ölçmek için kullanılır.
Bölüm 3. Basit Gerileme
İki değişken birbiriyle ilişkiliyse, böylece korelasyon katsayısının değeri, örneğin 0,5'i aşıyorsa, bu durumda, bir değişkenin bilinmeyen değerini diğerinin bilinen değerinden (bir miktar doğrulukla) tahmin etmek mümkündür. . Şekil 2'de gösterilen verilere dayanarak tahmini fiyat değerlerini elde etmek. 5, herhangi biri kullanılabilir olası yollar, ancak neredeyse kesinlikle Şekil 1'de gösterileni kullanmayacaksınız. 5. Yine de buna aşina olmalısınız, çünkü başka hiçbir yöntem korelasyon ve tahmin arasındaki ilişkiyi bu kadar açık bir şekilde gösteremez. İncirde. 5, B2: C12 aralığında, on evden rastgele bir örnek sunulur ve her evin taban alanı (feet kare olarak) ve satış fiyatı verilir.

Pirinç. 5. Öngörülen satış fiyatı değerleri düz bir çizgi oluşturur
Ortalamaları, standart sapmaları ve korelasyon katsayısını bulun (aralık A14: C18). Alan için z puanlarını hesaplayın (E2: E12). Örneğin, EZ hücresi şu formülü içerir: = (B3- $ B $ 14) / $ B $ 15. Tahmini fiyatın z puanlarını hesaplayın (F2: F12). Örneğin, F3 hücresi şu formülü içerir: = EZ * $ B $ 18. Z puanlarını dolar fiyatlarına dönüştürün (H2: H12). НЗ hücresinde formül şudur: = F3 * $ C $ 15 + $ C $ 14.
Lütfen tahmin edilen değerin her zaman 0'a eşit ortalamaya doğru hareket etme eğiliminde olduğuna dikkat edin. Korelasyon katsayısı sıfıra ne kadar yakınsa, tahmin edilen z-puanı da sıfıra o kadar yakın olur. Örneğimizde alan ile satış fiyatı arasındaki korelasyon katsayısı 0.67, tahmini fiyat 1.0 * 0.67 yani. 0.67. Bu, standart sapmanın üçte ikisine eşit, ortalamanın üzerindeki değerin fazlalığına karşılık gelir. Korelasyon katsayısı 0,5'e eşit olsaydı, tahmin edilen fiyat 1,0 * 0,5 olur, yani. 0,5. Bu, standart sapmanın sadece yarısına eşit, ortalamanın üzerindeki değerin fazlalığına karşılık gelir. Korelasyon katsayısının değeri idealden farklı olduğunda, yani. -1.0'dan büyük ve 1.0'dan küçükse, tahmin edilen değişkenin tahmini, tahmin edici (bağımsız) değişkenin tahmininden kendi ortalamasına daha yakın olmalıdır. Bu fenomene ortalamaya gerileme veya basitçe gerileme denir.
Excel'in, regresyon çizgisi denkleminin katsayılarını belirlemek için çeşitli işlevleri vardır (Excel'de buna eğilim çizgisi denir) y =kx + B... belirlemek için k işlev görür
= EĞİM (bilinen_y'ler, bilinen_x'ler)
Buraya NS Tahmin edilen değişken mi ve NS Bağımsız değişkendir. Bu değişken sırasını kesinlikle takip etmelisiniz. Regresyon eğimi, korelasyon katsayısı, değişkenlerin standart sapmaları ve kovaryans yakından ilişkilidir (Şekil 6). INTERCEPT (), dikey eksende regresyon çizgisi tarafından kırpılan değeri döndürür:
= KESİNTİSİZ (bilinen_y'ler, bilinen_x'ler)

Pirinç. 6. Standart sapmalar arasındaki oran, kovaryansı korelasyon katsayısına ve regresyon doğrusu eğimine dönüştürür.
SLOPE() ve INTERCEPT() fonksiyonlarına argüman olarak verilen x ve y değerlerinin sayısının aynı olması gerektiğini unutmayın.
Regresyon analizi bir tane daha kullanır önemli gösterge- R 2 (R-kare) veya belirleme katsayısı. arasındaki ilişkinin nasıl olduğunu belirler. NS ve NS... Excel, bunun için CORREL () işleviyle tamamen aynı bağımsız değişkenleri alan KVPIRSON () işlevine sahiptir.
Aralarında sıfır olmayan bir korelasyon katsayısına sahip iki değişkenin varyansı açıkladığı veya açıklanmış bir varyansa sahip olduğu söylenir. Genellikle açıklanan varyans yüzde olarak ifade edilir. Yani r 2 = 0.81, iki değişkenin varyansının (yayılımının) %81'inin açıklandığı anlamına gelir. Kalan %19 ise rastgele dalgalanmalardan kaynaklanmaktadır.
Excel, hesaplamaları kolaylaştıran bir TREND işlevine sahiptir. TREND () işlevi:
- verdiğiniz bilinen değerleri alır NS ve bilinen değerler NS;
- regresyon doğrusu ve bir sabitin (segment) eğimini hesaplar;
- tahmin edilen değerleri döndürür NS bilinen değerlere regresyon denklemi uygulanarak belirlenir NS(şek. 7).
TREND () işlevi bir dizi işlevidir (daha önce bu tür işlevlerle karşılaşmadıysanız tavsiye ederim).

Pirinç. 7. TREND () işlevini kullanmak, bir çift EĞME () ve KESME () işlevini kullanmaya kıyasla hesaplamaları hızlandırmanıza ve basitleştirmenize olanak tanır.
TREND () işlevini G3: G12 hücrelerinde dizi formülü olarak girmek için G3: G12 aralığını seçin, TREND formülünü girin (SZ: C12; OZ: B12), tuşları basılı tutun
TREND () işlevinin iki bağımsız değişkeni daha vardır: new_x'ler ve const... İlki, gelecek için bir tahmin yapmanıza izin verirken, ikincisi regresyon çizgisini Orijinden geçmeye zorlayabilir (DOĞRU, Excel'e hesaplanan sabiti kullanmasını söyler, YANLIŞ, sabiti = 0'ı söyler). Excel, bir grafik üzerinde orijinden geçmesi için bir regresyon çizgisi çizmenize olanak tanır. Bir dağılım grafiği çizerek başlayın ve ardından veri serisi işaretçilerinden birine sağ tıklayın. Açılanda seçin bağlam menüsü paragraf Trend çizgisi ekle; seçeneği seç Doğrusal; gerekirse paneli aşağı kaydırın, kutuyu işaretleyin Kavşağı yapılandır; ilişkili metin kutusunun 0.0 olarak ayarlandığından emin olun.
Üç değişkeniniz varsa ve üçüncünün etkisi hariç ikisi arasındaki korelasyonu belirlemek istiyorsanız, kullanabilirsiniz. kısmi korelasyon... Üniversiteden mezun olan şehir sakinlerinin yüzdesi ile şehir kütüphanelerindeki kitap sayısı arasındaki ilişkiyle ilgilendiğinizi varsayalım. 50 şehir için veri topladınız, ancak ... Sorun şu ki, bu parametrelerin her ikisi de belirli bir şehrin sakinlerinin refahına bağlı olabilir. Tabii ki, diğer 50 şehri tam olarak aynı refah düzeyine sahip bulmak çok zor.
Başvurarak istatistiksel yöntemler Refahın hem kütüphaneler için mali destek hem de kolejlerin mevcudiyeti üzerindeki etkisini ortadan kaldırmak için, ilgilenilen değişkenler, yani kitap sayısı ve mezun sayısı arasındaki ilişkiyi daha iyi ölçebilirsiniz. İki değişken arasındaki bu koşullu korelasyona, diğer değişkenlerin değerleri sabitlendiğinde kısmi korelasyon denir. Bunu hesaplamanın bir yolu denklemi kullanmaktır:

Nereye rCB . W- Zenginlik değişkeninin hariç tutulan etkisi (sabit değer) ile Kolej ve Kitap değişkenleri arasındaki korelasyon katsayısı; rCB- Kolej ve Kitaplar değişkenleri arasındaki korelasyon katsayısı; rCW Kolej ve Refah değişkenleri arasındaki korelasyon katsayısıdır; rSB Kitaplar ve Refah değişkenleri arasındaki korelasyon katsayısıdır.
Öte yandan, kısmi korelasyon artıkların analizine dayalı olarak hesaplanabilir, yani. tahmin edilen değerler ile ilişkili gerçek gözlemler arasındaki farklar (her iki yöntem de Şekil 8'de gösterilmiştir).

Pirinç. 8. Artıkların korelasyonu olarak kısmi korelasyon
Korelasyon katsayıları matrisinin (B16: E19) hesaplanmasını basitleştirmek için Excel analiz paketini kullanın (menü Veri –> analiz –> Veri analizi). Varsayılan olarak, bu paket Excel'de etkin değildir. Yüklemek için menüden gidin Dosya –> Seçenekler –> Eklentiler... Açılan pencerenin alt kısmında SeçeneklerExcel alanı bul Kontrol, Seçme EklentilerExcel, Tıklayın git... Eklentinin yanındaki kutuyu işaretleyin Analiz paketi... A'yı tıklayın veri analizi, bir seçenek seçin korelasyon... Giriş aralığı olarak $ B $ 2: $ D $ 13 girin, kutuyu işaretleyin İlk satırdaki etiketler, çıktı aralığı olarak $ B $ 16: $ E $ 19 girin.
Başka bir olasılık, yarı özel bir korelasyon tanımlamaktır. Örneğin, boy ve yaşın kilo üzerindeki etkisini araştırıyorsunuz. Yani iki öngörücü değişkeniniz var, boy ve yaş ve bir öngörücü değişken, ağırlık. Bir tahmin değişkeninin diğeri üzerindeki etkisini ortadan kaldırmak istiyorsunuz, ancak tahmin edilen değişken üzerinde değil:
![]()
nerede Н - Boy (Boy), W - Ağırlık (Ağırlık), A - Yaş (Yaş); yarı-kısmi korelasyon katsayısı indeksi kullanır yuvarlak parantez, bunun yardımıyla, hangi değişkenin etkisinin ortadan kaldırıldığı ve hangi değişkenden etkilendiği. V bu durum W (NA) notasyonu, Yaş etkisinin Boydan kaldırıldığını, ancak Ağırlıktan kaldırılmadığını gösterir.
Tartışılan konunun önemli olmadığı izlenimi edinilebilir. Sonuçta, en önemli şey genel regresyon denkleminin ne kadar doğru çalıştığıdır, bireysel değişkenlerin toplam açıklanan varyansa göreli katkıları sorunu ikincil öneme sahip görünmektedir. Ancak durum böyle değil. Çoklu regresyon denkleminizde bir değişken kullanmanız gerekip gerekmediğini merak etmeye başladığınızda, sorun önemli hale gelir. Analiz için model seçiminin doğruluğunun değerlendirilmesini etkileyebilir.
Bölüm 4. SATIR () işlevi
DOT () 10 regresyon istatistiği döndürür. DOT () bir dizi işlevidir. Girmek için beş satır ve iki sütun içeren bir aralık seçin, formülü yazın ve
DOĞRU (B2: B21; A2: A21; DOĞRU; DOĞRU)

Pirinç. 9. SATIR () işlevi: a) D2 aralığını seçin: E6, b) formülü formül çubuğunda gösterildiği gibi girin, c) tuşuna basın
SATIR () döndürür:
- regresyon katsayısı (veya eğim, hücre D2);
- segment (veya sabit, hücre E3);
- standart hatalar regresyon katsayısı ve sabitler (aralık D3: E3);
- regresyon için R2 belirleme katsayısı (hücre D4);
- tahminin standart hatası (hücre E4);
- Tam gerileme için F testi (hücre D5);
- kalan kareler toplamı için serbestlik derecesi sayısı (hücre E5);
- karelerin regresyon toplamı (hücre D6);
- kalan kareler toplamı (hücre E6).
Şimdi bu istatistiklerin her birine ve nasıl etkileşime girdiklerine bir göz atalım.
Standart hata bizim durumumuzda, örnekleme hataları için hesaplanan standart sapmadır. Yani bu, genel popülasyonun bir istatistiğe sahip olduğu ve örneklemin başka bir istatistiğe sahip olduğu bir durumdur. Regresyon katsayısını standart hataya bölerek 2.092 / 0.818 = 2.559 elde edersiniz. Başka bir deyişle, 2.092'lik bir regresyon katsayısı sıfırdan iki buçuk standart hatadır.
Regresyon katsayısı sıfır ise, o zaman en iyi derece tahmin edilen değişken onun ortalamasıdır. İki buçuk standart hata oldukça büyük bir sayıdır ve popülasyon için regresyon katsayısının sıfırdan farklı olduğunu güvenle varsayabilirsiniz.
Popülasyondaki gerçek değeri 0.0 ise, işlevi kullanarak 2.092'lik bir örnek regresyon katsayısı elde etme olasılığını belirleyebilirsiniz.
ÖĞRENCİ.DAĞ.RF (t-testi = 2.559; serbestlik derecesi sayısı = 18)
V toplam sayısı serbestlik derecesi = n - k - 1, burada n, gözlem sayısı ve k, öngörücü değişkenlerin sayısıdır.
Bu formül 0,00987 veya %1 yuvarlanmış olarak döndürür. Bize, popülasyon için regresyon katsayısı %0 ise, o zaman, regresyon katsayısının hesaplanan değeri 2.092 olan 20 kişilik bir örneklem alma olasılığının mütevazı bir %1 olduğunu söyler.
F-testi (Şekil 9'daki D5 hücresi), basit çift regresyon katsayısına göre t-testi ile tam regresyona göre aynı işlevi yerine getirir. F-testi, regresyon için R2 belirleme katsayısının, genel popülasyonda, tahmin edici ve tahmin edilen değişken tarafından açıklanan varyansın olmadığını gösteren 0.0 değerine sahip olduğu hipotezini reddetmek için yeterince büyük olup olmadığını test etmek için kullanılır. . Yalnızca bir tahmin değişkeni varsa, F testi, t testinin karesine tam olarak eşittir.
Şimdiye kadar aralık değişkenlerine baktık. Birkaç değer alabilen değişkenleriniz varsa, bunlar basit isimler, örneğin, Erkek ve Kadın veya Sürüngen, Amfibi ve Balık, onları formda temsil eder. sayısal kod... Bu tür değişkenlere nominal denir.
İstatistik R 2 açıklanan varyans oranını ölçer.
Tahminin standart hatası.İncirde. 4.9, Yükseklik değişkeni ile ilişkisi temelinde elde edilen Ağırlık değişkeninin tahmini değerlerini gösterir. E2: E21 aralığı, Ağırlık değişkeni için artık değerleri içerir. Daha doğrusu, bu artıklara hata denir - dolayısıyla tahminin standart hatası terimi.

Pirinç. 10. Hem R 2 hem de tahminin standart hatası, regresyonla elde edilen tahminlerin doğruluğunu ifade eder.
Tahminin standart hatası ne kadar küçük olursa, regresyon denklemi o kadar doğru olur ve denklemle yapılan herhangi bir tahmin, beklediğiniz gerçek gözlemle o kadar yakından eşleşir. Bir tahminin standart hatası, bu beklentileri ölçmek için bir yol sağlar. Belli bir boydaki kişilerin %95'inin kilosu şu aralıkta olacaktır:
(yükseklik * 2.092 - 3.591) ± 2.092 * 21.118
F-istatistikleri Gruplar arası varyansın grup içi varyansa oranıdır. Bu isim, istatistikçi George Snedecor tarafından 20. yüzyılın başlarında Varyans Analizi'ni (ANOVA) geliştiren Efendi'nin onuruna verildi.
Belirleme katsayısı R 2 payı ifade eder toplam tutar regresyon ile ilişkili kareler. (1 - R 2) değeri, artıklar - tahmin hataları ile ilişkili toplam kareler toplamının kesirini ifade eder. F testi, varyans fraksiyonları (aralık G14: J15) kullanılarak, kareler toplamları (aralık G10: J11) kullanılarak DOĞRU (Şekil 11'deki F5 hücresi) kullanılarak elde edilebilir. Formüller ekteki Excel dosyasında incelenebilir.

Pirinç. 11. F-kriterinin hesaplanması
Nominal değişkenler kullanılırken kukla kodlama kullanılır (Şekil 12). Değerleri kodlamak için 0 ve 1 değerlerini kullanmak uygundur. F olasılığı şu fonksiyon kullanılarak hesaplanır:
F.DAĞ.RF (K2; I2; I3)
Burada F.DAĞ.RT () işlevi, değeri aynı olan I2 ve I3 hücrelerinde verilen serbestlik derecelerine sahip iki veri kümesi için merkezi F dağılımına (Şekil 13) uyan bir F ölçütü elde etme olasılığını döndürür. K2 hücresinde verilen değer olarak.

Pirinç. 12. Kukla değişkenleri kullanan regresyon analizi

Pirinç. 13. λ = 0'da merkezi F-dağılımı
Bölüm 5. Çoklu Regresyon
Bir tahmin değişkeni ile basit ikili regresyondan çoklu regresyona geçtiğinizde, bir veya daha fazla tahmin değişkeni eklersiniz. Tahmin değişkenlerinin değerlerini bitişik sütunlarda saklayın, örneğin iki tahmin için A ve B sütunları veya üç tahmin için A, B ve C. DOT () işlevini içeren bir formül girmeden önce, beş satır ve tahmini değişken sayısı kadar sütun ve ayrıca sabit için bir tane daha seçin. İki öngörücü değişkenli bir regresyon durumunda, aşağıdaki yapı kullanılabilir:
DOĞRU (A2: A41; B2: C41 ;; DOĞRU)
Aynı şekilde üç değişken durumunda:
DOĞRU (A2: A61; B2: D61 ;; DOĞRU)
Aterotromboza neden olan aterosklerotik plaktan sorumlu olduğu düşünülen düşük yoğunluklu bir lipoprotein olan LDL üzerindeki yaş ve diyetin olası etkilerini incelemek istediğinizi varsayalım (Şekil 14).

Pirinç. on dört. Çoklu regresyon
Çoklu regresyonun R2'si (F13 hücresinde yansıtılır) herhangi bir basit regresyonun (E4, H4) R2'sinden büyüktür. Çoklu regresyon, aynı anda birden fazla tahmin değişkeni kullanır. Bu durumda, R2 hemen hemen her zaman artar.
Bir öngörücü değişkene sahip herhangi bir basit doğrusal regresyon denklemi için, tahmin edilen değerler ile tahmin edici değişken değerleri arasında her zaman mükemmel bir korelasyon olacaktır, çünkü böyle bir denklemde tahmin edici değerler bir sabitle çarpılır ve başka bir sabit eklenir. her ürüne. Bu etki çoklu regresyonda kalıcı değildir.
Çoklu regresyon için DOT () tarafından döndürülen sonuçları görüntüler (Şekil 15). Regresyon katsayıları, DOT () tarafından döndürülen sonuçların bir parçası olarak görüntülenir. değişkenlerin ters sırasına göre(G – H – I, C – B – A'ya karşılık gelir).

Pirinç. 15. Katsayılar ve bunların standart hataları çalışma sayfasında ters sırada gösterilir.
Bir tahmin değişkeni ile regresyon analizinde kullanılan ilke ve prosedürler, birden fazla tahmin değişkenini hesaba katmak için kolayca uyarlanabilir. Bu uyarlamanın çoğunun, tahmin değişkenlerinin birbirleri üzerindeki etkisinin ortadan kaldırılmasına bağlı olduğu ortaya çıktı. İkincisi, kısmi ve yarı özel korelasyonlarla ilişkilidir (Şekil 16).

Pirinç. 16. Çoklu regresyon, artıkların ikili regresyonu ile ifade edilebilir (Excel dosyasındaki formüllere bakın)
Excel'de t ve F dağılımları hakkında bilgi sağlayan işlevler vardır. STUDENT.DAĞ () ve F.DAĞ () gibi adları DIST'in bir parçasını içeren işlevler, bağımsız değişken olarak bir t- veya F-testi alır ve belirtilen değeri görme olasılığını döndürür. STUDENT.OBR() ve F.OBR() gibi adları bir OBR parçası içeren işlevler, argüman olarak bir olasılık değeri alır ve belirtilen olasılığa karşılık gelen bir kriter değeri döndürür.
aradığımız gibi kritik değerler Kuyruk bölgelerinin kenarlarını kesen t-dağılımları, bu olasılığa karşılık gelen bir değer döndüren STUDENT.OBR () işlevlerinden birine argüman olarak %5'i geçiyoruz (Şekil 17, 18).

Pirinç. 17. İki kuyruklu t testi

Pirinç. 18. Tek kuyruklu t testi
Tek kuyruklu alfa bölgesi durumunda bir karar kuralı oluşturarak testin istatistiksel gücünü artırırsınız. Denemeye başladığınızda, pozitif (veya negatif) bir regresyon katsayısı beklemek için her türlü nedeniniz olduğundan eminseniz, tek uçlu bir test yapmalısınız. Bu durumda, alma olasılığınız doğru çözüm, genel popülasyonda sıfır regresyon katsayısı hipotezini reddetmek daha yüksek olacaktır.
İstatistikçiler terimi kullanmayı tercih ediyor yön testi terim yerine tek kuyruklu test ve terim yönlendirilmemiş test terim yerine çift kuyruklu test... Yönlü ve yönsüz terimleri, dağılım kuyruklarının doğasından ziyade hipotezin türünü vurguladıkları için tercih edilir.
Tahmin edicilerin etkisini değerlendirmek için model tabanlı bir yaklaşım.İncirde. 19, Diyet değişkeninin regresyon denklemine katkısını test eden bir regresyon analizinin sonuçlarını gösterir.

Pirinç. 19. Sonuçlarındaki farklılıkları kontrol ederek iki modelin karşılaştırılması
LINEST () sonuçları (aralık H2: K6), LDL'yi Diyet, Yaş ve HDL'ye göre gerileyen tam model dediğim şeyle ilgilidir. H9: J13 aralığında, hesaplamalar Diyet tahmin değişkeni dikkate alınmadan sunulur. Ben buna sınırlı model diyorum. Tam modelde LDL bağımlı değişkenin varyansının %49,2'si yordayıcı değişkenler tarafından açıklanmaktadır. Sınırlı modelde LDL'nin sadece %30,8'i Yaş ve HDL değişkenleri tarafından açıklanmaktadır. Diyet değişkeninin modelden çıkarılması nedeniyle R2 kaybı 0.183'tür. G15: L17 aralığında, Diyet değişkeninin etkisinin yalnızca 0,0288 olasılıkla rastgele olduğunu gösteren hesaplamalar yapılır. Kalan %97,1'inde Diyet LDL üzerinde etkilidir.
Bölüm 6. Regresyon Analizi Varsayımları ve Uyarıları
"Varsayım" terimi kesin olarak tanımlanmamıştır ve kullanım şekli, varsayım karşılanmazsa, tüm analizin sonuçlarının en azından şüpheli veya muhtemelen geçersiz olduğunu gösterir. Aslında, durum böyle değil, elbette, varsayımın ihlal edilmesinin resmi kökten değiştirdiği durumlar var. Temel varsayımlar: a) Y değişkeninin artıkları normal olarak regresyon çizgisi boyunca herhangi bir X noktasında dağıtılır; b) Y değerleri lineer olarak X değerlerine bağlıdır; c) artıkların varyansı her X noktasında yaklaşık olarak aynıdır; d) kalıntılar arasında bağımlılık yoktur.
Varsayımlar önemli bir rol oynamıyorsa, istatistikçiler varsayımın ihlaliyle ilgili olarak analizin sağlamlığı hakkında konuşurlar. Özellikle, grup ortalamaları arasındaki farkları test etmek için regresyon kullandığınızda, Y değerlerinin - ve dolayısıyla artıkların - normal dağıldığı varsayımı gerekli değildir: testler normallik varsayımını kırmaya karşı dayanıklıdır. Bununla birlikte, çizelgeleri kullanarak verileri analiz etmek önemlidir. Örneğin eklentiye dahil Veri analizi alet regresyon.
Verileriniz doğrusal regresyon varsayımlarına uymuyorsa, doğrusal regresyondan başka yaklaşımlarınız vardır. Bunlardan biri lojistik regresyondur (Şekil 20). Tahmin değişkeninin üst ve alt sınırlarına yakın, doğrusal regresyon gerçekçi olmayan tahminlere yol açar.

Pirinç. 20. Lojistik regresyon
İncirde. 6.8, yıllık gelir ile bir ev satın alma olasılığı arasındaki ilişkiyi araştırmayı amaçlayan iki veri analizi yönteminin sonuçlarını göstermektedir. Açıkçası, bir satın alma olasılığı, artan gelirle birlikte artacaktır. Grafikler, doğrusal regresyon kullanarak bir ev satın alma olasılığını tahmin eden sonuçlar ile farklı bir yaklaşım kullanarak elde edebileceğiniz sonuçlar arasındaki farkı söylemeyi kolaylaştırır.
İstatistikçi dilde, gerçekten doğru olduğunda boş bir hipotezi atmak, Tip I hata olarak adlandırılır.
üst yapıda Veri analizi teklif edildi kullanışlı araç kullanıcıya dağılımın istenen şeklini (örneğin, Normal, Binom veya Poisson) ve ayrıca ortalama ve standart sapmayı belirleme yeteneği veren rastgele sayılar üretmek için.
STUDENT.DIST() ailesinin işlevleri arasındaki farklar. Excel 2010'dan başlayarak, üç farklı şekiller belirli bir t-test değerinin soluna ve/veya sağına dağılımın oranını döndüren bir işlev. STUDENT.DIST () işlevi, belirttiğiniz t-test değerinin solundaki dağılım eğrisi altındaki alanın kesirini döndürür. 36 vakanız olduğunu varsayalım, bu nedenle analiz edilecek serbestlik derecesi sayısı 34 ve t testi 1,69'dur. Bu durumda formül
ÖĞRENCİ DIST (+1.69; 34; DOĞRU)
0,05 veya %5 döndürür (Şekil 21). STUDENT.DIST () işlevinin üçüncü bağımsız değişkeni DOĞRU veya YANLIŞ olabilir. TRUE olarak ayarlanırsa, işlev, bir kesir olarak ifade edilen, belirtilen t-testinin solundaki eğrinin altındaki kümülatif alanı döndürür. YANLIŞ ise, işlev, t-testini karşılayan noktadaki eğrinin göreli yüksekliğini döndürür. ÖĞRENCİ.DAĞ () - ÖĞRENCİ.DAĞ.PX () ve ÖĞRENCİ.DAĞ.2X () işlevinin diğer sürümleri - bağımsız değişken olarak yalnızca t-ölçütünün değerini ve serbestlik derecesi sayısını alır ve belirtmeyi gerektirmez üçüncü argüman.

Pirinç. 21. Dağılımın sol kuyruğundaki koyu gölgeli alan, büyük pozitif t-test değerinin solundaki eğrinin altındaki alanın kesrine karşılık gelir.
T kriterinin sağındaki alanı belirlemek için aşağıdaki formüllerden birini kullanın:
1 - SHOODENT.DAĞ (1, 69; 34; DOĞRU)
ÖĞRENCİ.DAĞ.PH (1.69; 34)
Eğrinin altındaki tüm alan %100 olmalıdır, bu nedenle t-testinin solundaki alanın kesrinin 1'den çıkarılması, fonksiyonun döndürdüğü alanın t-testinin sağındaki alanın kesirini verir. daha fazlasını bulabilirsin tercih edilen seçenek STUDENT.DIST.PX () işlevini kullanarak ilgilendiğiniz alan fraksiyonunu doğrudan elde etmek, burada PX, dağılımın sağ kuyruğunu temsil eder (Şekil 22).

Pirinç. Yön testi için %22,5 alfa alanı
STUDENT.DIST () veya STUDENT.DIST.PX () işlevlerinin kullanılması, yönlendirilmiş bir çalışma hipotezi seçtiğinizi varsayar. %5'lik bir alfa ayarıyla birleştirilmiş bir yönlü çalışma hipotezi, %5'in tamamını dağılımların sağ kuyruğuna koymanız anlamına gelir. Yalnızca t-testi değerinizin olasılığı %5 veya daha az ise boş hipotezi reddetmeniz gerekecektir. Yönlü hipotezler genellikle daha hassas istatistiksel testlere yol açar (bu daha büyük hassasiyete daha büyük istatistiksel güç de denir).
Yönlendirilmemiş bir testte, alfa değeri aynı %5 düzeyinde kalır, ancak dağılım farklı olacaktır. İki sonuca izin vermeniz gerektiğinden, yanlış pozitif olasılığı dağılımın iki kuyruğu arasında dağıtılmalıdır. Bu olasılığın eşit olarak dağıtılması genel olarak kabul edilir (Şekil 23).

Önceki örnekte olduğu gibi elde edilen aynı t-testi değerini ve aynı sayıda serbestlik derecesini kullanarak, formülü kullanın.
ÖĞRENCİ.DAĞ 2X (1.69; 34)
Belirli bir neden olmaksızın, STUDENT.DIST.2X (), ilk bağımsız değişkeni olarak negatif bir t-testi verilirse #SAYI!
Örnekler farklı miktarlarda veri içeriyorsa, pakette bulunan farklı varyanslarla iki örnekli t-testini kullanın. Veri analizi.
Bölüm 7. Grup Ortalamaları Arasındaki Farkları Test Etmek İçin Regresyonu Kullanma
Daha önce tahmin değişkenleri olarak adlandırılan değişkenler bu bölümde sonuç değişkenleri olarak anılacaktır ve tahmin değişkenleri yerine faktör değişkenleri terimi kullanılacaktır.
Nominal bir değişkeni kodlamak için en basit yaklaşım, kukla kodlama(şek. 24).

Pirinç. 24. Sahte kodlamaya dayalı regresyon analizi
Herhangi bir türden sahte kodlama kullanırken aşağıdaki kurallara uyulmalıdır:
- Yeni veriler için ayrılmış sütun sayısı, faktör düzeyi sayısı eksi eksiye eşit olmalıdır.
- Her vektör bir faktör seviyesini temsil eder.
- Genellikle bir kontrol grubu olan bir seviyenin denekleri, tüm vektörlerde 0 kodunu alır.
F2: H6 = DOĞRU (A2: A22; C2: D22 ;; DOĞRU) hücrelerindeki formül, regresyon istatistiklerini döndürür. Karşılaştırma için, Şek. 24, araç tarafından döndürülen geleneksel varyans analizinin sonuçlarını gösterir Tek yönlü ANOVAüst yapılar Veri analizi.
Efekt kodlaması. denilen başka bir kodlama türünde kodlama efektleri, her grubun ortalaması, grup ortalamalarının ortalaması ile karşılaştırılır. Efekt kodlamanın bu yönü, tüm kod vektörlerinde aynı kodu alan bir grup için kod olarak 0 yerine -1 kullanılmasından kaynaklanmaktadır (Şekil 25).

Pirinç. 25. Kodlama efektleri
Sahte kodlama kullanıldığında, DOT () tarafından döndürülen sabit değer, tüm vektörlerde (genellikle kontrol grubu) sıfır kodlarının atandığı grubun ortalamasıdır. Kodlama etkileri durumunda, sabit toplam ortalamaya (J2 hücresi) eşittir.
Genel doğrusal model - faydalı yol ortaya çıkan değişkenin değerinin bileşenlerini kavramsallaştırma:
Y ij = μ + α j + ε ij
Bu formülde kullanım Yunan harfleri Latince yerine, örneklerin alındığı popülasyonu ifade ettiğini vurgular, ancak yayınlanan genel popülasyondan çıkarılan örnekleri ifade ettiğini belirten bir biçimde yeniden yazılabilir:
Y ij = Y̅ + bir j + e ij
Buradaki fikir, her bir Y ij gözleminin aşağıdaki üç bileşenin toplamı olarak görülebileceğidir: genel ortalama, μ; işleme etkisi j, bir j; bireysel nicel gösterge Y ij'nin toplam ortalamanın birleşik değerinden sapmasını temsil eden e ij değeri ve j-th etkisi işleme (şek. 26). Regresyon denkleminin amacı, artıkların karelerinin toplamını minimize etmektir.

Pirinç. 26. Genel doğrusal modelin bileşenlerine ayrıştırılan gözlemler
Faktor analizi. Etkili değişken ile iki veya daha fazla faktör arasındaki ilişki aynı anda araştırılırsa, bu durumda faktör analizinin kullanımından bahsederler. Tek değişkenli ANOVA'ya bir veya daha fazla faktör eklemek istatistiksel gücü artırabilir. Tek değişkenli ANOVA'da, bir faktöre atfedilemeyen bir sonuç değişkenindeki varyasyon, artık ortalama kareye dahil edilir. Ancak bu varyasyonun başka bir faktörle örülmüş olması iyi olabilir. Daha sonra bu varyasyon, F-kriterinin değerlerinde bir artışa ve dolayısıyla testin istatistiksel gücünde bir artışa yol açan bir azalma olan kök-ortalama-kare hatasından çıkarılabilir. üst yapı Veri analizi iki faktörün aynı anda işlenmesini sağlayan bir araç içerir (Şekil 27).

Pirinç. 27. Analiz Paketinin tekrarlarını içeren İki Yönlü ANOVA Aracı
Bu şekilde kullanılan ANOVA aracı, plana dahil edilen her grup için sonuç değişkeninin ortalamasını ve varyansını ve ayrıca sayaç değerini döndürmesi açısından yararlıdır. Masada ANOVA tek yönlü ANOVA aracının çıktısında bulunmayan iki parametre görüntülenir. Varyasyon kaynaklarına dikkat edin Örneklem ve Sütunlar 27 ve 28. satırlarda. Varyasyon kaynağı Sütunlar cinsiyete atıfta bulunur. Varyasyon kaynağı Örneklem değerleri farklı satırlarda olan herhangi bir değişkeni ifade eder. İncirde. KursLech1 grubu için 27 değer 2-6 satırlarında, KursLech2 grubu - 7-11 satırlarında ve KursLechZ grubu - 12-16 satırlarındadır.
Buradaki kilit nokta, hem Cinsiyet (E28 hücresindeki Sütunlar başlığı) hem de Tedavinin (E27 hücresindeki Örnek başlık) varyasyon kaynakları olarak ANOVA tablosuna dahil edilmesidir. Erkeklerin ortalamaları, kadınların ortalamalarından farklıdır ve bu bir çeşitlilik kaynağı yaratır. Üç tedavinin araçları da farklıdır - işte başka bir varyasyon kaynağı. Cinsiyet ve Tedavi değişkenlerinin birleşik etkisine atıfta bulunan üçüncü bir kaynak olan Etkileşim de vardır.
Bölüm 8. Kovaryans Analizi
Kovaryasyon Analizi (ANCOVA), yanlılığı azaltır ve istatistiksel gücü artırır. Güvenilirliği değerlendirmenin yollarından birinin regresyon denklemi F testleri:
F = MS Regresyonu / MS Kalıntısı
burada MS (Ortalama Kare) ortalama karedir ve Regresyon ve Kalıntı endeksleri regresyonu gösterir ve artık bileşenler sırasıyla. MS Residual'ın hesaplanması aşağıdaki formüle göre yapılır:
MS Kalıntı = SS Kalıntı / df Kalıntı
burada SS (Kareler Toplamı) karelerin toplamıdır ve df serbestlik derecesi sayısıdır. Bir regresyon denklemine kovaryans eklediğinizde, toplam kareler toplamının bir kısmı SS Kalıntısına değil, SS Regresyonuna dahil edilir. Bu, SS Kalıntı l'de bir azalmaya ve dolayısıyla MS Kalıntısına yol açar. MS Rezidü ne kadar düşükse, F-skoru o kadar yüksek ve ortalamalar arasında hiçbir fark olmadığı sıfır hipotezini reddetme olasılığınız o kadar yüksek olur. Sonuç olarak, ortaya çıkan değişkenin değişkenliğini yeniden dağıtırsınız. ANOVA'da kovaryans dikkate alınmadığında oynaklık hata olur. Ancak ANCOVA'da daha önce hataya atfedilen değişkenliğin bir kısmı ortak değişkene atanır ve SS Regresyonunun bir parçası olur.
Aynı veri setinin önce ANOVA ve ardından ANCOVA ile analiz edildiği bir örnek düşünün (Şekil 28).

Pirinç. 28. ANOVA, Regresyon Denklemi Sonuçlarının Güvenilmez Olduğunu Gösterir
Çalışma, kas gücünü oluşturan egzersizin ve beyin aktivitesini uyaran bilişsel egzersizin (çapraz bulmaca çözme) göreli etkilerini karşılaştırdı. Konular rastgele deney başlangıcında her iki grup da aynı koşullarda olacak şekilde iki gruba ayrıldı. Üç ay sonra deneklerin bilişsel özellikleri ölçüldü. Bu ölçümlerin sonuçları B sütununda gösterilmektedir.
A2: C21 aralığı, kodlama efektlerini kullanarak analiz gerçekleştirmek için DOĞRU () işlevine iletilen ilk verileri içerir. DOĞRU () işlevinin sonuçları E2: F6 aralığında gösterilir; burada E2 hücresi, uyaran vektörüyle ilişkili regresyon katsayısını gösterir. E8 hücresi bir t-testi = 0.93 içerir ve E9 hücresi bu t-testinin güvenilirliğini test eder. E9 hücresindeki değer, genel popülasyonda grup ortalamaları eşitse, bu deneyde gözlemlenen grup ortalamaları arasında bir farkla karşılaşma olasılığının %36 olduğunu gösterir. Çok azı bu sonucun istatistiksel olarak anlamlı olduğunu düşünüyor.
İncirde. 29, analize ortak değişkenler eklendiğinde ne olduğunu gösterir. Bu durumda, her konunun yaşını veri setine ekledim. Ortak değişkeni kullanan regresyon denklemi için R2 belirleme katsayısı 0.80'dir (hücre F4). Ortak değişkeni kullanmadan elde edilen ANOVA sonuçlarını yeniden ürettiğim F15: G19 aralığındaki R2 değeri yalnızca 0,05'tir (hücre F17). Bu nedenle, bir ortak değişken içeren bir regresyon denklemi, Bilişsel Puan değişkeninin değerlerini tek başına Etki vektörünü kullanmaktan çok daha doğru bir şekilde tahmin eder. ANCOVA için olasılık rastgele makbuz F5 hücresinde görüntülenen F puanı %0.01'den az.

Pirinç. 29. ANCOVA tamamen farklı bir tabloyu geri getiriyor
Korelasyon-REGRESYON ANALİZİHANIM mükemmel
1. MS Excel'de bir kaynak veri dosyası oluşturun (örneğin, tablo 2)
2. Korelasyon alanının oluşturulması
Korelasyon alanını oluşturmak için Komut satırı menüyü seç Ekle / Grafik... Görüntülenen iletişim kutusunda, grafik türünü seçin: Puan; görüş: Dağılım çizelgesi bu, değer çiftlerini karşılaştırmanıza izin verir (Şekil 22).
Şekil 22 - Bir grafik türü seçme
Şekil 23– Aralık ve satır seçerken pencere görünümü
Şekil 25 - Pencere görünümü, 4. adım
2. Bağlam menüsünde komutu seçin Bir eğilim çizgisi ekleyin.
3. Görünen iletişim kutusunda, Şekil 26'da gösterildiği gibi grafiğin türünü (örneğimizde doğrusal) ve denklemin parametrelerini seçin.
Tamam'ı tıklayın. Sonuç Şekil 27'de gösterilmektedir.
Şekil 27 - Emek verimliliğinin sermaye-emek oranına bağımlılığının korelasyon alanı
Benzer şekilde, işgücü verimliliğinin ekipman değiştirme oranına bağımlılığının korelasyon alanını oluşturuyoruz. (Şekil 28).
 |
Şekil 28 - Emek verimliliği bağımlılığının korelasyon alanı
ekipman değiştirme oranından
3. Korelasyon matrisinin oluşturulması.
Menüde bir korelasyon matrisi oluşturmak için Hizmet Seç Veri analizi.
Bir veri analiz aracı kullanma regresyon, regresyon istatistikleri, varyans analizi ve güven aralıklarının sonuçlarına ek olarak, regresyon çizgisi, artıklar ve normal olasılığın uydurulması için artıklar ve grafikler elde etmek mümkündür. Bunu yapmak için analiz paketine erişimi kontrol etmeniz gerekir. Ana menüden seçin Hizmet / Eklentiler... Kutuyu kontrol et Analiz paketi(Şekil 29)
Şekil 30 - İletişim kutusu Veri analizi
Tamam'a tıkladıktan sonra, görünen iletişim kutusunda, Şekil 31'de gösterildiği gibi giriş aralığını (örneğimizde, A2: D26), gruplamayı (bizim durumumuzda sütunlara göre) ve çıkış parametrelerini belirtin.
 |
Şekil 31 - İletişim kutusu korelasyon
Hesaplama sonucu Tablo 4'te sunulmuştur.
Tablo 4 - Korelasyon matrisi
Sütun 1 | 2. sütun | Sütun 3 |
|
Sütun 1 | |||
2. sütun | |||
Sütun 3 |
TEK Faktörlü Regresyon Analizi
REGRESYON ARACI UYGULAMASI İLE
Menüde emek verimliliğinin sermaye-emek oranına bağımlılığına ilişkin bir regresyon analizi yapmak Hizmet Seç Veri analizi ve analiz aracını belirtin regresyon(Şekil 32).
Şekil 33 - İletişim kutusu regresyon
V Excel lineer regresyonu (ve hatta aşağıda tartışıldığı gibi, lineer olmayan regresyonların temel türlerini) çizmenin daha da hızlı ve daha uygun bir yolu vardır. Bu şöyle yapılabilir:
1) veri içeren sütunları seçin x ve Y(bu sırayla olmalılar!);
2) aramak Grafik Sihirbazı ve grupta seçin Bir çeşit – Puan ve hemen basın Hazır;
3) diyagramdan seçimi bırakmadan, ana menünün görünen öğesini seçin Diyagram, öğeyi seçmeniz gereken Trend çizgisi ekle;
4) görünen iletişim kutusunda eğilim çizgisi sekmede Bir çeşit Seçme Doğrusal;
5) sekmesinde Seçenekler anahtar etkinleştirilebilir Denklemi Grafikte Göster katsayıların (4.5) hesaplanacağı lineer regresyon denklemini (4.4) görmenizi sağlayacaktır.
6) Aynı sekmede anahtarı etkinleştirebilirsiniz Yaklaşık güven değerini (R ^ 2) diyagrama yerleştirin... Bu nicelik, korelasyon katsayısının (4.3) karesidir ve hesaplanan denklemin deneysel bağımlılığı ne kadar iyi tanımladığını gösterir. Eğer r 2 birliğe yakındır, o zaman teorik regresyon denklemi deneysel bağımlılığı iyi tanımlar (teori deneyle iyi bir uyum içindedir) ve eğer r 2 sıfıra yakınsa, bu denklem deneysel bağımlılığı tanımlamak için uygun değildir (teori deneyle aynı fikirde değildir).
Açıklanan eylemleri gerçekleştirmenin bir sonucu olarak, bir regresyon grafiği ve denklemi içeren bir diyagram elde edeceksiniz.
§4.3. Ana türler doğrusal olmayan regresyon
Parabolik ve Polinom Regresyon.
Parabolik miktar bağımlılığı Y değerde NS ikinci dereceden bir fonksiyonla ifade edilen bağımlılık olarak adlandırılır (2. dereceden parabol):
Bu denklem denir parabolik regresyon denklemi Yüzerinde NS... Seçenekler a, B, ile birlikte arandı parabolik regresyon katsayıları... Parabolik regresyon katsayılarını hesaplamak her zaman zahmetlidir, bu nedenle hesaplamalar için bir bilgisayar kullanılması önerilir.
Parabolik regresyonun (4.8) denklemi, polinom adı verilen daha genel bir regresyonun özel bir halidir. Polinom miktar bağımlılığı Y değerde NS polinom tarafından ifade edilen bağımlılık denir n-inci sıra:
sayılar nerede ve ben (ben=0,1,…, n) arandı polinom regresyon katsayıları.
Güç regresyonu.
üstel miktar bağımlılığı Y değerde NS formun bağımlılığı denir:
Bu denklem denir güç regresyon denklemi Yüzerinde NS... Seçenekler a ve B arandı güç regresyon katsayıları.
ln = ln a+B içinde x. (4.11)
Bu denklem, logaritmik koordinat eksenleri ln olan bir düzlemde düz bir çizgiyi tanımlar. x ve ln. Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, ampirik verilerin logaritmalarının noktalarının ln olması şartıdır. x ben ve ln ben düz çizgiye (4.11) en yakın olanlardır.
Üstel regresyon.
gösterge(veya üstel) miktarın bağımlılığı ile Y değerde NS formun bağımlılığı denir:
(veya ). (4.12)
Bu denklem denir üstel denklem(veya üstel) regresyon Yüzerinde NS... Seçenekler a(veya k) ve B arandı üstel(veya üstel) gerilemeler.
Güç regresyon denkleminin her iki tarafının logaritmasını alırsak, denklemi elde ederiz.
ln = x içinde a+ ln B(veya ln = kx+ ln B). (4.13)
Bu denklem, bir ln niceliğinin logaritmasının başka bir niceliğe lineer bağımlılığını tanımlar. x... Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, aynı nicelikteki ampirik veri noktalarının gerekliliğidir. x ben ve başka bir niceliğin logaritmaları ln ben düz çizgiye en yakındı (4.13).
Logaritmik regresyon.
Logaritmik miktar bağımlılığı Y değerde NS formun bağımlılığı denir:
=a+B içinde x. (4.14)
Bu denklem denir logaritmik regresyon denklemi Yüzerinde NS... Seçenekler a ve B arandı logaritmik regresyon katsayıları.
Hiperbolik regresyon.
hiperbolik miktar bağımlılığı Y değerde NS formun bağımlılığı denir:
Bu denklem denir hiperbolik regresyon denklemi Yüzerinde NS... Seçenekler a ve B arandı hiperbolik regresyon katsayıları ve en küçük kareler yöntemi ile belirlenir. Bu yöntemin uygulanması aşağıdaki formüllere yol açar:
Formüllerde (4.16-4.17), toplama indeks üzerinden yapılır. ben birden gözlem sayısına n.
maalesef Excel hiperbolik regresyon katsayılarını hesaplayan bir fonksiyon yoktur. Ölçülen büyüklüklerin ters orantılı olarak ilişkili olduğunun önceden bilinmediği durumlarda, hiperbolik regresyon denklemi yerine, aşağıdaki gibi güç regresyon denkleminin aranması önerilir. Excel bulmak için bir prosedür var. Ölçülen değerler arasında hiperbolik bir bağımlılık varsayılırsa, bunun regresyon katsayılarının yardımcı hesaplama tabloları ve formüller (4.16-4.17) kullanılarak toplama işlemleri kullanılarak hesaplanması gerekecektir.









Taramalı Atomik Kuvvet Mikroskobu Laboratuvar raporu şunları içermelidir:
Havai iletişim ağı için destek seçimi
AC katener tasarımı ve hesaplanması
Mikroişlemci sistemlerinin geliştirilmesi Mikroişlemci sistemlerinin tasarım aşamaları
mcs51 ailesinin mikrodenetleyicileri