Správa údajov je proces, ktorý zahŕňa zhromažďovanie, ukladanie, spracovanie a interpretáciu nahromadených údajov. Správa dát je dnes pre mnoho spoločností vynikajúcou príležitosťou na pochopenie už zhromaždených údajov, „poznanie“ konkurencie, vytváranie prediktívnych analýz (prognóz) a odpovedanie na mnohé obchodné otázky.
Správa údajov
Čo obsahuje správa údajov? Vymenujme hlavné procesy:
- Správa databáz
- Procesy ETL (extrakcia, transformácia a načítanie údajov)
- Zber dát
- Ochrana údajov a šifrovanie
- Dátové modelovanie
- Samotná analýza dát
Na základe vyššie uvedeného je zrejmé, že úspešná správa údajov si vyžaduje:
- Vyriešte technické problémy (vyberte si databázu, určte, kam sa budú údaje ukladať - v cloude, na serveri atď.)
- Nájdite kompetentné ľudské zdroje 🙂
Kľúčové výzvy v správe údajov
Medzi najčastejšie chyby a ťažkosti, ktoré vznikajú pri zhromažďovaní, ukladaní a interpretácii údajov, patria:
- Neúplné údaje
- „Duplikácia“ údajov (a často si navzájom odporujú)
- Zastarané údaje
V mnohých otázkach vo fáze zhromažďovania údajov môže pomôcť produkt, ktorý pomáha kombinovať údaje z rôznych zdrojov, obohatiť ich a pripraviť na použitie v systémoch Business Intelligence.
Analýza dát
Máte už správne množstvo relevantných a dôležitých údajov? Teraz je ich potrebné okrem úložiska aj analyzovať. Analýza dát pomôže odpovedať na mnohé obchodné otázky, robiť informované rozhodnutia, „vidieť“ vášho zákazníka, optimalizovať skladové a logistické procesy. Všeobecne je analýza údajov dôležitá a potrebná v akejkoľvek oblasti, spoločnosti a na akejkoľvek úrovni.
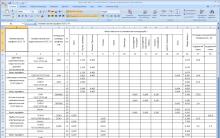
Riešenie analýzy údajov sa skladá z troch hlavných blokov:
- Uloženie údajov;
- Postupy ETL (extrakcia, transformácia a načítanie údajov);
- Systém podávania správ a vizuálnej analýzy.
To všetko sa zdá byť dosť komplikované, ale v skutočnosti to nie je až také strašidelné.
Moderné analytické riešenia
Čo by mali robiť spoločnosti, ktoré nemajú zamestnancov analytikov? A neexistuje žiadny vývojársky programátor? Existuje však túžba robiť analytiku!
Samozrejme, existuje riešenie. Na trhu je teraz dostatok automatizovaných systémov na analýzu a - čo je dôležité! - vizualizácia vašich údajov.
Aké sú výhody takýchto systémov (typu):
- Schopnosť rýchlej implementácie (stiahnite si program a nainštalujte ho aspoň na svoj laptop)
- Nie sú potrebné žiadne zložité IT alebo matematické znalosti
- Nízke náklady (od 2 000 rubľov za mesiac za licenciu na marec 2018)
Akákoľvek spoločnosť tak môže implementovať taký analytický produkt: bez ohľadu na to, koľko zamestnancov v ňom pracuje. Tableau je vhodný pre individuálnych podnikateľov aj pre veľké spoločnosti. V apríli 2018 si OSN vybrala Tableau ako analytickú platformu pre všetky svoje kancelárie po celom svete!
Spoločnosti, ktoré pracujú s takýmito automatizovanými analytickými systémami, si uvedomujú, že tabuľkové prehľady, ktoré sa predtým vytvorili za 6 hodín, sa v tablo zhromažďujú doslova za 10 - 15 minút.
Neverte mi? Vyskúšajte to sami - stiahnite si bezplatnú skúšobnú verziu Tableau a získajte návody, ako program používať:
Stiahnite si tablo








Problémy so sivým iPhone počas prevádzky
Čo je „sivý“ iPhone a stojí za to si takéto zariadenie kúpiť
Linka pomoci - čo to je, prečo je to potrebné, ako to funguje, čo je regulované?
Prečo potrebujete linku dôvery Dôvody kontaktovať linku dôvery
Prečo potrebujete linku pomoci Čo sa myslí pod linkou dôvery