Dan ia menggunakan Pemungut Kunci untuk ini, saya cadangkan menggunakan pangkal kata berhenti untuk membersihkan sampah. Untuk orang lain, saya cadangkan menghubungi saya dan, dan kemudian anda tidak perlu menderita, menyapu dan mengumpulkan ribuan frasa, saya akan melakukan semua ini untuk anda 🙂
Hentikan asas perkataan untuk Pengumpul Kunci
Saya mengumpulkan pangkalan ini dari potongan dan pecahan kata berhenti untuk Kay Collector, yang boleh didapati di Internet. Pada pendapat saya, ini adalah senarai paling lengkap dari semua kata kunci negatif yang ada sekarang, jadi saya sangat mengesyorkan menggunakannya untuk membersihkan inti semantik.
- Hentikan senarai perkataan untuk KeyCollector di semua bandar Rusia, Ukraine dan Belarus.
- Menyaring senarai kata kunci negatif: topik XXX, DIY, pengubahsuaian, humor, dll.
- Senarai nama lelaki dan wanita.
- Hentikan kata-kata untuk Kay Collector, dipecah mengikut topik (!) - sebenarnya tidak banyak topik, namun begitu.
Pangkalan data ini benar-benar cukup untuk membersihkan 95% sampah yang berlaku semasa mengumpulkan semantik, tetapi anda tetap harus bekerja dengan tangan anda. Walaupun begitu, berkat penggunaan kata berhenti ini, saya mula menjimatkan masa untuk membersihkan kernel, sebelum terasa menyakitkan!
Saya mula menulis artikel ini sejak dulu, tetapi sebelum penerbitannya ternyata rakan-rakan saya dalam profesion ini berada di hadapan saya dan memposting bahan yang hampir sama.
Pada mulanya, saya memutuskan bahawa saya tidak akan menerbitkan artikel saya, kerana topik ini sudah diliputi oleh rakan sekerja yang lebih berpengalaman. Mikhail Shakin berbicara mengenai 9 kaedah membersihkan permintaan di KC, dan Igor Bakalov membuat penggambaran video mengenai analisis pendua tersirat ... Namun, setelah beberapa lama, setelah mempertimbangkan semua kebaikan dan keburukan, saya sampai pada kesimpulan bahawa mungkin artikel saya mempunyai hak untuk hidup dan mungkin berguna bagi seseorang - jangan menilai dengan tegas.
Sekiranya anda perlu menyaring pangkalan kata kunci yang besar sebanyak 200k atau 2 juta pertanyaan, maka artikel ini dapat membantu anda. Sekiranya anda menggunakan kernel semantik kecil, kemungkinan besar artikel itu tidak akan berguna untuk anda.
Kami akan mempertimbangkan untuk menyaring inti semantik yang besar menggunakan contoh contoh 1 juta pertanyaan mengenai topik undang-undang.
Apa yang kita perlukan?
- Pemungut Kunci (selepas ini KC)
- Sekurang-kurangnya 8GB RAM (jika tidak, kita akan mempunyai brek yang mengerikan, mood yang manja, kebencian, kemarahan dan aliran darah di kapilari mata)
- Kata Henti Biasa
- Pengetahuan asas mengenai bahasa ekspresi biasa
Sekiranya anda benar-benar baru dalam perniagaan ini dan anda tidak berkawan baik dengan KC, maka saya sangat mengesyorkan agar anda membiasakan diri dengan fungsi dalaman yang dinyatakan di halaman rasmi laman web ini. Banyak soalan akan hilang dengan sendirinya, dan anda juga akan memahami sedikit dalam musim biasa.
Oleh itu, kami mempunyai pangkalan data kunci yang besar yang perlu disaring. Anda boleh mendapatkan asasnya melalui penjelasan sendiri, dan juga dari pelbagai sumber, tetapi hari ini bukan mengenai perkara itu.
Semua yang akan dijelaskan di bawah ini relevan untuk contoh satu ceruk khusus dan bukan aksioma! Di ceruk lain, beberapa tindakan dan peringkat mungkin berbeza secara signifikan! Saya tidak berpura-pura menjadi Guru semantik, tetapi hanya berkongsi pemikiran, perkembangan dan pertimbangan saya mengenai perkara ini.
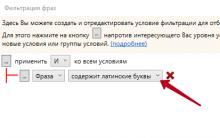
Langkah 1. Keluarkan huruf Latin
Kami memadamkan semua frasa di mana watak Latin dijumpai. Sebagai peraturan, frasa tersebut mempunyai frekuensi yang tidak signifikan (jika ada) dan ia salah atau tidak relevan.
Semua manipulasi dengan pemilihan frasa dilakukan melalui butang yang dihargai ini.

Sekiranya anda mengambil inti ke-10 dan mencapai langkah ini, maka kapilari mata mungkin mula pecah di sini, kerana pada komputer / komputer riba yang lemah, sebarang manipulasi dengan SN yang besar boleh, dan tanpa malu-malu akan menjadi perlahan.
Pilih / tandakan semua frasa dan padam.
Langkah 2. Buang yang istimewa. Simbol
Operasi ini serupa dengan penghapusan watak Latin (anda boleh melakukan kedua-duanya pada masa yang sama), namun, saya cadangkan melakukan semuanya secara berperingkat dan melihat hasilnya dengan mata anda, dan tidak "memotong bahu", kerana kadang-kadang walaupun dalam ceruk yang sepertinya anda tahu segala-galanya, terdapat pertanyaan lazat yang boleh berada di bawah saringan dan yang mungkin tidak anda ketahui.

Nasihat kecil, jika anda mempunyai banyak frasa yang baik dalam contoh anda, tetapi dengan tanda koma atau simbol lain, tambahkan simbol ini kepada pengecualian dan itu sahaja.
Pilihan lain (jalan samurai)
- Muat naik semua frasa yang diperlukan dengan watak khas
- Padamkannya di KC
- Di mana-mana editor teks, ganti watak yang diberikan dengan spasi
- Muat semula.
Sekarang frasa bersih, reputasi mereka telah dikelantang dan pemilihan untuk istimewa. simbol tidak akan mempengaruhi mereka.
Langkah 3. Keluarkan kata pendua
Dan sekali lagi, kami akan menggunakan fungsi yang terdapat di dalam KC dengan menerapkan peraturan
Tidak ada yang boleh ditambahkan di sini - semuanya mudah. Kami membunuh sampah tanpa keraguan.
Sekiranya anda menghadapi tugas untuk melakukan penyaringan yang sukar dan membuang sampah sebanyak mungkin, sambil mengorbankan sebilangan pertanyaan yang baik, maka anda boleh menggabungkan ketiga-tiga langkah pertama menjadi satu.
Ia akan kelihatan seperti ini:

PENTING: Jangan lupa menukar "DAN" ke "ATAU"!
Langkah 4. Keluarkan frasa yang terdiri daripada 1 dan 7+ perkataan
Seseorang mungkin berdebat dan bercakap mengenai kesejukan kata-kata ganjil, tidak ada pertanyaan - tinggalkan, tetapi dalam kebanyakan kes, penyaringan manual odnoslovniks memerlukan masa yang sangat lama, sebagai peraturan, nisbah odnoslovony baik / buruk adalah 1/20, tidak memihak kepada kita. Ya, dan bawa mereka ke TOP menggunakan kaedah yang saya kumpulkan inti dari kategori fiksyen sains. Oleh itu, berderak dengan hati, kami menghantar kata-kata kepada nenek moyang.

Saya menjangkakan banyak pertanyaan, "mengapa hapus frasa panjang?" Jawapan saya adalah bahawa frasa yang terdiri daripada 7 atau lebih perkataan untuk sebahagian besarnya mempunyai struktur spam, tidak mempunyai kekerapan dan pada amnya banyak bentuk pendua, itu adalah pendua tematik. Saya akan memberikan contoh untuk menjadikannya lebih jelas.

Di samping itu, kekerapan soalan sedemikian sangat kecil sehingga selalunya ruang di pelayan lebih mahal daripada ekzos dari permintaan tersebut. Sebagai tambahan, jika anda melihat TOP untuk frasa panjang, maka anda tidak akan menemui kejadian langsung sama ada dalam teks atau tag, jadi penggunaan frasa panjang seperti itu dalam silibus kami tidak masuk akal.
Langkah 5. Membersihkan pendua yang tersirat
Kami melakukan pra-konfigurasi pembersihan, melengkapkannya dengan frasa kami sendiri, yang menunjukkan pautan ke senarai saya, jika ada yang perlu ditambah dengan - tulis, kami akan berusaha untuk kesempurnaan bersama.

Sekiranya anda tidak melakukan ini, dan menggunakan senarai tersebut, dengan baik disediakan dan dipalu ke dalam program oleh pencipta KC secara lalai, maka hasil seperti itu akan tetap ada dalam senarai, dan ini sebenarnya adalah pendua.

Kita boleh melakukan pengelompokan pintar, tetapi agar berfungsi dengan betul, perlu membuang frekuensi. Dan ini, dalam kes kami, bukan pilihan. Kerana Untuk membuang frekuensi dari 1 juta. keev, tetapi walaupun dari 100k - anda memerlukan sebungkus proksi peribadi, anti-captcha dan banyak masa. Kerana malah 20 proksi tidak akan mencukupi - dalam satu jam captcha akan mula muncul, apa sahaja yang boleh dikatakan. Dan perniagaan ini akan memakan banyak masa, omong-omong, anggaran anti-captcha juga akan memakan banyak. Dan mengapa mengeluarkan frekuensi dari frasa sampah yang dapat disaring tanpa banyak usaha?
Sekiranya anda masih mahu menapis frasa dengan pengelompokan pintar, membuang frekuensi dan membuang sampah secara beransur-ansur, maka saya tidak akan menerangkan prosesnya secara terperinci - lihat video yang saya rujuk pada awal artikel.
Berikut adalah tetapan dan langkah pembersihan saya

Langkah 6. Tapis dengan kata berhenti
Pada pendapat saya, ini adalah titik yang paling suram, minum teh, merokok sebatang rokok (ini bukan daya tarikan, lebih baik berhenti merokok dan menggegarkan kuki) dan dengan tenaga segar duduk untuk menapis inti semantik dengan kata berhenti.
Jangan mencipta roda dan mula membina senarai kata berhenti dari awal. Terdapat penyelesaian siap pakai. Khususnya, ini untuk anda, sebagai asas lebih daripada yang akan berlaku.
Saya menasihati anda untuk menyalin piring ke dalam suapan PC anda sendiri, atau bagaimana jika saudara Shestakov memutuskan untuk meninggalkan "daya tarikan anda" kepada diri mereka sendiri dan menutup akses ke fail tersebut? Seperti kata pepatah, "Jika anda paranoid, itu tidak bermaksud anda tidak diikuti ..."
Secara peribadi, saya membongkar kata berhenti menjadi fail berasingan untuk tugas tertentu, lihat contohnya di tangkapan skrin.

Fail "Daftar umum" mengandungi semua kata berhenti sekaligus. Dalam Pengumpul Kunci, buka antara muka kata berhenti dan muatkan senarai dari fail.

Saya meletakkan hanya sebahagian kejadian dan tanda centang di kotak "Cari padanan hanya pada awal kata." Tetapan ini sangat relevan dengan sebilangan besar kata berhenti, kerana banyak perkataan terdiri daripada 3-4 aksara. Dan jika anda menetapkan tetapan lain, maka anda mungkin menyaring banyak perkataan yang berguna dan perlu.
Sekiranya kita tidak mencentang kotak di atas, maka perkataan "fuck" yang tidak senonoh akan dijumpai dalam frasa seperti "nasihat kepada insurans negara", "cara menginsuranskan deposit", dll. dan lain-lain. Inilah contoh lain, pada kata berhenti "rb" (Republik Belarus) sebilangan besar frasa akan ditandai, seperti "ganti rugi untuk perundingan kerosakan", "mengemukakan tuntutan dalam proses timbang tara", dll. dan lain-lain.
Dalam kata lain - kita memerlukan program untuk memilih frasa sahaja di mana kata berhenti berlaku pada awal kata.Kata-kata itu menyakitkan telinga, tetapi anda tidak dapat menghapus kata-kata dari lagu tersebut.
Secara berasingan, saya perhatikan bahawa tetapan ini menyebabkan peningkatan masa yang ketara untuk memeriksa kata berhenti. Dengan senarai yang besar, prosesnya boleh memakan masa 10 dan 40 minit, dan semuanya disebabkan oleh kotak pilihan ini, yang meningkatkan masa pencarian untuk 100 perkataan dalam frasa sepuluh atau lebih banyak kali. Walau bagaimanapun, ini adalah pilihan penapisan yang paling mencukupi ketika bekerja dengan inti semantik yang besar.
Setelah kami membaca senarai asas, saya cadangkan untuk melihat apakah ada ungkapan yang perlu ada di bawah pengedaran, dan saya yakin ia akan berlaku, tk. senarai umum kata berhenti asas tidak universal dan harus dikendalikan secara berasingan untuk setiap ceruk. Di sinilah bermulanya "menari dengan rebana".
Kami hanya meninggalkan kata berhenti yang dipilih di tetingkap kerja, ia dilakukan seperti ini.

Kemudian kita klik pada "analisis kumpulan", pilih mod "dengan kata yang terpisah" dan lihat apa yang berlebihan dalam senarai kami kerana kata berhenti yang tidak sesuai.

Keluarkan kata berhenti yang tidak sesuai dan ulangi kitaran. Oleh itu, setelah beberapa saat kita akan "mempertajam" senarai umum sejagat untuk keperluan kita. Tetapi bukan itu sahaja.
Sekarang kita perlu memilih kata berhenti yang terdapat secara khusus dalam pangkalan data kami. Ketika datang ke pangkalan data kata kunci yang besar, selalu ada semacam "sampah berjenama", seperti yang saya sebut. Lebih-lebih lagi, ini mungkin satu set kecelaruan yang tidak dijangka dan anda harus menyingkirkannya secara individu.
Untuk menyelesaikan masalah ini, kita akan menggunakan fungsi Analisis Kumpulan, tetapi kali ini kita akan melalui semua frasa yang tersisa di dalam pangkalan data setelah manipulasi sebelumnya. Mari kita susun mengikut bilangan frasa dan dengan mata, ya, ya, ya, dengan pen dan mata, mari kita perhatikan semua frasa, sehingga 30-50 dalam satu kumpulan. Maksud saya lajur kedua "bilangan frasa dalam kumpulan".
Saya akan bersegera untuk memberi amaran kepada orang yang lemah hati, bar tatal yang nampaknya tidak berkesudahan "tidak akan memaksa anda menghabiskan seminggu menyaring, menatalnya sebanyak 10% dan anda sudah menjangkau kumpulan yang tidak mengandungi lebih daripada 30 permintaan, dan penapisan seperti itu harus dilakukan hanya oleh mereka yang tahu banyak dalam penyelewengan.
Dari tetingkap yang sama, kita dapat menambahkan semua sampah ke kata berhenti (ikon perisai di sebelah kiri kotak pilih).

Daripada menambahkan semua kata berhenti ini (dan ada banyak lagi, saya tidak mahu menambah tangkapan skrin panjang menegak), kami dengan anggun menambahkan akar penapis dan memotong semua variasi sekaligus. Akibatnya, senarai kata berhenti kami tidak akan bertambah besar dan, yang paling penting, kami kami tidak akan membuang masa tambahan untuk mencari mereka... Dan dalam jumlah yang banyak, ini sangat penting.
Langkah 7. Keluarkan 1 dan 2 "perkataan" simbolik
Saya tidak dapat mencari definisi yang tepat untuk jenis kombinasi simbol ini, jadi saya menyebutnya "kata-kata". Mungkin seseorang yang telah membaca artikel itu akan mencadangkan istilah mana yang lebih baik, dan saya akan menggantikannya. Di sini saya sangat terikat dengan lidah.
Ramai yang akan bertanya, "mengapa melakukan ini sama sekali?" Jawapannya mudah, selalunya susunan kata kunci seperti itu mengandungi sampah jenisnya:

Ciri umum frasa tersebut adalah 1 atau 2 aksara yang tidak masuk akal (dalam tangkapan skrin, contoh dengan 1 watak). Inilah yang akan kami tapiskan. Terdapat perangkap di sini, tetapi perkara pertama adalah yang pertama.
Bagaimana cara membuang semua perkataan 2 watak?
Untuk ini kami menggunakan biasa

Petua bonus: Sentiasa menjaga corak biasa! Mereka tidak disimpan dalam projek, tetapi dalam KC secara amnya... Jadi mereka akan sentiasa berada di tangan.
(^ | \\ s +) (..) (\\ s + | $) atau (^ | \\ s) (1,2) (\\ s | $)
(st | fz | uk | na | rf | li | oleh | st | bukan | un | hingga | dari | untuk | hingga | dari | tentang)
Inilah versi saya, sesuaikan untuk memenuhi keperluan anda.
Baris kedua mengandungi pengecualian, jika anda tidak memasukkannya, maka semua frasa yang mengandungi kombinasi aksara dari baris kedua formula akan dimasukkan dalam senarai calon penghapusan.
Baris ketiga tidak termasuk frasa yang diakhiri dengan "рф", kerana ini adalah frasa berguna yang biasa.
Saya juga ingin menjelaskan bahawa pilihan (^ | \\ s +) (..) (\\ s + | $) akan memilih semuanya - termasuk nilai berangka... Manakala yang biasa (^ | \\ s) (1,2) (\\ s | $) - hanya akan mempengaruhi huruf abjad, terima kasih khas kepada Igor Bakalov untuk itu.
Kami menggunakan reka bentuk kami dan membuang frasa sampah.
Bagaimana saya membuang semua perkataan 1 watak?
Segala-galanya di sini agak menarik dan tidak begitu jelas.
Pada mulanya saya cuba mengaplikasikan dan memodenkan versi sebelumnya, tetapi akibatnya saya tidak berjaya membersihkan semua sampah - namun skema ini akan sesuai dengan banyak orang, cubalah.

(^ | \\ s +) (.) (\\ s + | $)
(s | v | u | i | k | y | o)
Secara tradisinya, baris pertama adalah regex itu sendiri, yang kedua adalah pengecualian, yang ketiga tidak termasuk frasa-frasa di mana watak-watak yang disenaraikan berlaku pada awal frasa. Nah, itu logik, kerana tidak ada ruang di hadapan mereka, oleh itu, baris kedua tidak mengecualikan kehadiran mereka dalam sampel.
Dan inilah pilihan kedua dengan mana saya memadamkan semua frasa dengan sampah satu watak, sederhana dan tanpa belas kasihan, yang dalam kes saya membantu menyingkirkan sejumlah besar frasa kidal.

(y | ts | e | n | g | w | w | z | x | b | f | s | a | p | r | l | d | w | e | h | m | t | b | b | y )
Saya mengecualikan dari contoh semua frasa di mana "Moscow" berlaku, kerana terdapat banyak frasa jenis:

dan saya memerlukannya anda sendiri meneka mengapa.
Sergey Arsentiev
KeyCollector (Key Collector): penyusunan profesional inti semantik.
Inti semantik adalah asas untuk kejayaan promosi mana-mana projek Internet. Oleh itu, adalah penting untuk memerhatikan tahap ini. Untuk melakukan ini, anda boleh menggunakan program yang paling popular untuk mengumpulkan pertanyaan carian utama - KeyCollector.
KeyCollector adalah program berbayartetapi bernilai setiap dolar yang dibelanjakan untuknya.
Ini adalah penghurai yang sangat baik dan hebat untuk pelbagai petunjuk, mulai dari kata kunci, tawaran di Yandex.Direct dan Google.Adwords, memeriksa ketergantungan geo dan kebenaran bentuk kata, tahap persaingan, dan diakhiri dengan analisis data lanjutan agregator SEO terkemuka.
Sangat mustahil untuk menggambarkan semua ciri program dalam satu artikel, jadi sekarang saya akan memberi tumpuan kepada yang paling penting - penyusunan profesional inti semantik.
Terdapat banyak kaedah untuk memilih, menyaring dan mengelompokkan permintaan, tetapi saya akan menerangkan proses memilih kunci menggunakan Pengumpul Kunci tepat seperti yang saya "terbiasa" melakukannya dengan jumlah masa minimum dan dengan pencapaian hasil yang diinginkan. Biasanya saya mengambil masa sekitar 10-15 minit untuk mencari kunci untuk satu topik yang dipromosikan. Oleh itu, mari kita mulakan.
Sejurus selepas dibuka, Key Collector akan menawarkan untuk membuat projek baru atau membuka yang lama. Dalam satu projek, disarankan untuk memilih dan menyimpan pertanyaan utama untuk keseluruhan laman web jika agak kecil, misalnya, hingga 1000 halaman. Oleh itu, nama projek saya biasanya adalah nama laman web.
Oleh itu, kami membuat projek baru, simpan dengan nama apa pun dan pertama sekali kami menunjukkan alamat laman web di bahagian atas halaman di medan URL.
Seterusnya, kami menunjukkan wilayah tempat anda ingin mengumpulkan permintaan. Untuk melakukan ini, klik di bahagian bawah program pada setiap butang Kawasan (ada 4 daripadanya) dan pilih kawasan yang diinginkan di tetingkap yang muncul. Kami memerlukan butang pertama untuk mengumpulkan statistik dan bentuk perkataan dari Yandex.Wordstat, yang kedua - untuk mendapatkan frekuensi dari Yandex.Direct, yang ketiga - untuk menganalisis tahap persaingan, dan yang terakhir untuk mengumpulkan statistik dari Google.
Tetapan asas.
Sekarang anda perlu mengkonfigurasi koleksi statistik dari Yandex. Ia dikonfigurasikan secara lalai, tetapi anda perlu membuat perubahan kecil bergantung pada tugas khusus menyusun inti semantik.
Pertama, tentukan had frekuensi yang lebih rendah untuk frasa tambahan. Ini dilakukan dalam item "Tambahkan frasa dengan frekuensi dari" ke jadual. Sekiranya matlamat anda adalah mengumpulkan ribuan pertanyaan frekuensi rendah, tetapkan julat anggaran 5-50 ... Sekiranya anda perlu mengumpulkan pertanyaan frekuensi tinggi, maka tetapkan had frekuensi yang lebih rendah dari 50... Dalam semua kes lain, parameter lalai sesuai - dari 10.
Masuk akal untuk mencentang kotak "Rakam 0 secara automatik". Dalam kes ini, semasa mengumpulkan beberapa pertanyaan frekuensi rendah, tidak akan ada hasil kosong.
Anda mungkin menyedari bahawa kami membiarkan kedalaman penguraian sama dengan 0. Tidak masuk akal untuk menggunakan kedalaman yang lebih besar ketika mengumpulkan pertanyaan wilayah biasa, kerana pertanyaan biasanya kurang dari 40 halaman, yang ditetapkan secara lalai. Adalah masuk akal untuk menetapkan kedalaman 1 hanya jika tugasnya adalah mengumpulkan maksimum kunci yang relevan untuk pertanyaan frekuensi tinggi dan pada masa yang sama anda mesti menentukan nilai yang layak, misalnya, 100 dalam item "Jangan tambahkan frasa untuk penyelidikan mendalam dengan frekuensi dasar sama dengan atau lebih rendah daripada".
Saya biasanya meningkatkan kependaman antara permintaan sedikit. Dengan nilai 8000-15000, captcha saya tidak pernah muncul tanpa pelayan proksi, dan kelajuan kerja lebih daripada yang boleh diterima.
Tetapi jika captcha muncul terlalu kerap, tentu saja pilihan yang paling munasabah adalah menggunakan pelayan proksi, di sini terdapat proksi khusus untuk Keycollector https://proxy-sale.com
Hanya tinggal membuka tab Yandex.Direct dalam tetapan yang sama dan tambahkan 5-6 akaun palsu yang dibuat khas dalam bentuk alamat: kata laluan.
Program ini disediakan dan siap mengumpulkan kata kunci.
Koleksi frasa utama.
Secara peribadi, saya merasa paling senang mengumpulkan kata kunci untuk halaman tertentu... Walaupun sebilangan SEO lebih suka mengumpulkan ribuan frasa terlebih dahulu dan kemudian menyebarkannya ke seluruh halaman menggunakan penapis.
Dalam artikel ini, saya akan mempertimbangkan pilihan pertama, kerana lebih mudah dan, pada pendapat saya, lebih tepat dan lebih baik ketika menyusun inti untuk mempromosikan laman web perniagaan biasa atau blog yang sama.
Klik pada ikon pengumpulan statistik Yandex.WordStat dan masukkan senarai kunci yang sesuai untuk bahagian halaman atau laman web yang dipromosikan. Di sini anda perlu menunjukkan sedikit imaginasi dan mengemukakan pelbagai jenis kata yang dapat mencerminkan intipati halaman anda dan dengan mana calon pelawat dapat mencari laman web yang dipromosikan dalam carian.
Sekiranya imaginasi anda ketat, cari secara manual contoh pertanyaan carian serupa di Yandex yang sama ,.
Sudah tentu, anda dapat mengumpulkan petunjuk menggunakan program KeyCollector yang sama, tetapi ketika menyusun inti semantik untuk bahagian atau halaman tertentu, biasanya tidak perlu dan lebih cepat untuk hanya memandu dengan beberapa kata umum, biasanya tidak banyak dari mereka, hanya 5-10 untuk setiap halaman yang dipromosikan.
Anda tidak perlu risau tentang akhiran atau bentuk kata, program ini akan menemui semua pilihan - hanya memandu dengan kata yang paling umum yang sesuai dengan makna dan tidak termasuk tafsiran lain.
Untuk artikel mengenai tinjauan pertukaran pautan kekal, saya pada asalnya menggunakan kata-kata berikut:
Sekiranya saya hanya menggunakan kata "pertukaran", maka program akan memberikan banyak sampah yang tidak sesuai dengan artikel saya dari segi kandungan, misalnya, mengenai stok, spekulasi stok, pertukaran pekerja, dll. Dan untuk pertanyaan "pertukaran pautan" terdapat pelbagai kombinasi, yang sesuai untuk halaman saya, termasuk "pertukaran pautan terbaik", "pertukaran pautan kekal", dll.
Pada masa yang sama, kata umum "miralinks" paling baik digunakan sendiri untuk mencari sebilangan besar pilihan untuk pertanyaan dengan perkataan ini: bagaimanapun, ia hanya ditaip oleh mereka yang, pada prinsipnya, berminat dengan topik ini dan bukan yang lain.
Kami menapis lebihan.
Setelah mengumpulkan kata kunci menggunakan program KeyCollector, senarai semua frasa yang terdapat dalam statistik carian yang sesuai dengan parameter yang dikonfigurasi akan muncul di tab semasa.
Antaranya, terdapat dua jenis kunci yang tidak sesuai untuk promosi:
- Kekunci dengan beberapa kejadian langsung.
- Kekunci yang mengandungi kata kunci negatif.
Kekunci dengan sebilangan kecil kejadian langsung.
Saya sudah menulis lebih awal apa itu, sekarang saya akan mengulang sedikit. Pada mulanya, program ini mengumpulkan pertanyaan utama dengan frekuensi asas... Ini bermaksud bahawa jumlah permintaan yang diberikan setiap bulan akan merangkumi semua bentuk kata dengan permintaan ini.
Contohnya, pertanyaan "pertukaran beli pautan" \u003d 55 tera setiap bulan. Tetapi tera ini akan merangkumi banyak variasi pertanyaan ini, misalnya, "ulasan pertukaran pertukaran pautan" atau "pertukaran beli pautan sape", dll.
Untuk mempromosikan laman web, tidak mungkin menggunakan semua pilihan ini sekaligus, kerana pertanyaan utama perlu ditulis dalam tag meta, yang jumlahnya sangat kecil, ditambahkan pada tajuk dan tajuk utama halaman, yang juga tidak bersifat getah dan tanpa terlalu banyak spam dengan kepadatan normal, masukkan teks.
Oleh itu, adalah logik untuk memilih permintaan yang paling biasa dan mengoptimumkan halaman khusus untuk mereka, sehingga seberapa banyak orang yang mungkin mengunjungi laman web yang dipromosikan. Dan berapa banyak kesan yang terdapat di "pertukaran beli pautan" tanpa penambahan dan variasi? Untuk melakukan ini, anda perlu mengumpulkan data dengan frekuensi yang disebut "!".
Mari kita mulakan.
Klik pada ikon Langsung, centang kotak di sebelah "! Word" dan klik "Dapatkan data".
Seperti yang anda lihat, jumlah permintaan langsung untuk kunci "pertukaran beli pautan" agak kecil - hanya 3 (!) Permintaan per bulan, dan bukannya 55. Oleh itu, saya secara peribadi tidak melihat maksud mengoptimumkan halaman untuk permintaan ini.
Oleh itu, adalah mustahak untuk menyaring semua pertanyaan yang mempunyai beberapa kejadian tepat langsung dalam carian, misalnya, kurang dari 5. Untuk melakukan ini dengan cepat, cukup urutkan semua kunci yang dikumpulkan mengikut frekuensi tepat "!".
Kemudian pilih baris yang mengandungi perkataan dengan frekuensi yang tidak mencukupi dan hapuskannya.
10 saat, dan senarai ratusan perkataan biasanya dipendekkan 3-5 kali. Kini masuk akal untuk membuang kunci yang tidak berkaitan.
Kekunci dengan kata kunci negatif.
Apa ini? Ini adalah pertanyaan carian yang digunakan untuk mencari halaman yang tidak dipromosikan dan jelas bukan bakal pelanggan.
Sebagai contoh, untuk sebuah kedai yang menjual pembersih vakum, permintaan yang tidak berkaitan seperti kunci "tertera arahan", "ulasan",
Maksudnya, permintaan "arahan untuk pembersih vakum samsung" tidak mungkin berguna bagi pemilik kedai dalam talian biasa, kerana walaupun banyak orang mengalaminya, maksimum yang akan mereka lakukan adalah memuat turun arahan ini, dan sama sekali tidak membeli pembersih vakum baru.
Dalam kes saya, masuk akal untuk menghapus kunci dengan perkataan "skrip", "www", dll.
Mari kita mulakan.
Klik pada butang Berhenti Perkataan. Pada tetingkap yang muncul, masukkan kata kunci negatif, pastikan bahawa di bahagian bawah jenis carian untuk kejadian adalah "Hentikan kata bebas daripada bentuk kata". Ini diperlukan agar tidak menulis setiap kata kunci negatif dalam padanan tepat, tetapi untuk menggunakan kata kunci negatif yang lebih umum.
Dalam kes ini, apabila menggunakan, misalnya, kata negatif "instruktor", pertanyaan carian "arahan pembersih vakum", "arahan muat turun untuk pembersih vakum", dan lain-lain akan dihapuskan, iaitu pertanyaan dengan bentuk perkataan apa pun.
Klik "Tandai dalam jadual" dan hasilnya, semua kata kunci yang mengandungi kata kunci negatif menjadi kotak centang.
Sekarang yang tinggal hanyalah menghapusnya.
Buka tab "Data" di bahagian atas, pilih "Hapus frasa yang ditandai" dan hanya itu - sekarang anda mempunyai senarai kunci tanpa permintaan lain.
Kami menentukan tahap persaingan.
Ciri yang sangat baik dari program KeyCollector adalah menguraikan data mengenai jumlah halaman yang diindeks yang dijumpai untuk setiap pertanyaan carian, jumlah laman dalam TOP-10 yang mengandungi frasa kunci ini dalam tajuk halaman Judul, dan juga berapa banyak halaman dari sepuluh teratas untuk permintaan ini adalah halaman utama.
Sudah jelas bahawa semakin banyak halaman yang diindeks, tajuk yang dioptimumkan dan halaman utama di SERP, semakin sukar untuk bersaing dengannya.
Walau bagaimanapun, adalah sangat biasa bagi pertanyaan frekuensi tinggi yang baik untuk mempunyai persaingan yang sedikit. Oleh itu, sangat penting untuk menganalisis semua pertanyaan utama yang dikumpulkan untuk tahap persaingan untuk memilih dan mempromosikan kunci yang paling menguntungkan dan tidak diduduki.
Untuk melakukan ini, klik pada ikon "KEI" dan pilih "Dapatkan data untuk Yandex PS".
Anda tentu saja dapat menjelaskan tahap persaingan di mesin pencari lain, itu bergantung pada tugas promosi, tetapi dalam kebanyakan kes Yandex sudah cukup untuk mendapatkan gambaran objektif mengenai kesukaran mempromosikan pertanyaan tertentu.
Sudah tentu tahap definisi persaingan ini tidak sempurna. Sangat sesuai jika program ini dapat menguraikan setiap permintaan:
- Rata-rata laman TCI dan PR di TOP-10.
- Ukuran halaman purata.
- Purata bilangan pautan masuk ke pesaing, dll.
Dalam kes ini, hasilnya akan lebih tepat.
Tetapi seperti yang ditunjukkan oleh praktik, analisis persaingan "sepintas" cukup untuk berjaya mencari kunci yang menguntungkan dan bergerak dengan cepat, kerana banyak pengoptimum tidak melaksanakannya sama sekali dan sebagai hasilnya, banyak laman web dipromosikan sesuai dengan pertanyaan persaingan yang kompleks, walaupun mereka "berbohong" permintaan dengan frekuensi tidak kurang dan dengan ketiadaan pesaing yang dioptimumkan.
Cara mengumpulkan kata kunci negatif untuk Yandex Direct, serta semantik paling bersih dan paling laris untuk kempen iklan anda.
Terdapat 2 pendekatan untuk mengumpulkan kata kunci dan frasa negatif:
Kaedah ekspres
Banyak pakar direktorat mencadangkan kaedah memilih dalam 20 minit, 10 minit atau kurang.
Maksudnya ialah anda mengumpulkan output dari Wordstat, membawanya ke Excel atau analog dan mengeluarkan kunci dan kata tambahan yang relevan dari sana, pada akhirnya anda mempunyai senarai tolak.
Mengapa kaedah ini tidak baik dan mengapa saya akan mengajar anda kaedah yang berbeza:
- Kekangan.
Wordstat memungkinkan untuk mengumpulkan permintaan hanya untuk 40 halaman pertama. Walaupun anda tidak mengumpulkan setiap permintaan dengan pen, tetapi dengan bantuan beberapa plugin, anda akan duduk seperti orang bodoh dan membalikkan empat puluh halaman.
- Ketidakupayaan untuk mengumpulkan senarai lengkap kata berhenti.
Oleh kerana keterbatasan statistik perkataan, anda akan membina senarai yang baik, tetapi tidak lengkap. Hal ini terutama berlaku untuk semantik luas seperti pangsapuri di Moscow. Di sana, permintaan untuk halaman terakhir datang dengan frekuensi 300 permintaan. Dan anda harus pergi pada harga 30 atau kurang, kerana jika anda menunjukkan permintaan yang tidak sesuai, walaupun frekuensi rendah, anda akan mencurahkan banyak wang dan jumlah air mata yang sama, niche itu mahal.
Di samping itu, dalam banyak ceruk, hasil carian mudah alih adalah penting, dan Yandex selalu bijak dengan geo di telefon - Nizhny Novgorod sentiasa mentakrifkan saya dan bukannya Saratov. Agar SERP relevan dengan geo, anda harus mengaktifkan penyasaran geografi yang diperluas, tetapi pada masa yang sama tolak semua bandar di mana anda tidak mahu ditunjukkan.
Kaedah ekspres tidak akan memberi anda peluang seperti itu, anda harus menambahkannya sendiri.
- DAN PALING PENTING: dengan bantuan kaedah saya, anda akan mengumpulkan selain senarai minus SEMUA kata kunci sasaran!
Kumpulkan kata kunci negatif diPemungut Kay
Adalah lebih mudah dan senang digunakan untuk menguraikan semantik dan kata-kata "buruk" kepadanya dalam perkhidmatan khas. Anda boleh menggunakan Slovoebom, Magadan parser percuma (ada versi percuma), dan lain-lain, terdapat beberapa program.
Saya akan menunjukkan kepada anda cara menyaring kata berhenti di Pengumpul Kunci dan mendapatkan semantik penukaran bersih untuk iklan pada masa yang sama.
Semuanya bermula dengan fakta bahawa anda mengumpulkan topeng utama (arahan untuk menghuraikan) dari halaman perkataan atau anggaran anggaran kempen iklan, kemudian gandakan dan bawa ke Pemungut Kunci.
Sebagai contoh, tugasnya adalah membersihkan semantik untuk penjualan trampolin di Moscow. Kami mengumpulkan semua permintaan, kami melihat gambar:

1. Pergi ke tetingkap kata berhenti.
2. Di dalamnya, pilih jenis carian untuk kejadian: Tidak bergantung pada bentuk kata berhenti. Oleh itu, kami akan merebut semua varian satu perkataan (sewa, sewa, sewa).
3. Klik pada tanda tambah hijau.
4. Di tetingkap pop timbul, tetapkan kata-kata berbahaya (dipisahkan dengan koma, anda boleh menggunakan baris baru).

Apakah kata kunci negatif untuk ditulis di sini?
Sebagai permulaan, yang paling jelas adalah yang menunjukkan niat untuk tidak membeli, tetapi, sebagai contoh, untuk menonton ulasan atau mengatasi sendiri: bagaimana, bagaimana, lebih baik, percuma, dengan tangan anda sendiri, jenis pembaikan, foto, dan video. Sekiranya anda menjual produk baru dan tidak menggunakan papan pesanan, tambahkan "avito". Dan lain-lain.
Di sini adalah perlu untuk menyelidiki niche, untuk memahami keunikan proses penjualan dan pemikiran pelanggan ketika mencari. Apa yang penting semasa memilih ciri apa, syarat pembelian, penghantaran, jaminan atau perkhidmatan.
5. Tekan butang "Tandakan frasa dalam jadual".
6. 15-20 kata yang paling jelas memberi saya 396 pertanyaan sampah. Kami membawa mereka ke bakul.
Pilih "Pindahkan frasa ke kumpulan lain", di tetingkap drop-down, klik "Sampah" dan kemudian "OK". Mengagumi hasilnya (dilingkari hijau):

TETAPI! Kami belum selesai dengan permintaan ini. Kami pergi ke keranjang belanja dan melihat permintaan untuk ketersediaan komersial. Kami melihat kunci seperti "beli harga gambar trampolin":

Kami menekan Ctrl + klik padanya, program memindahkan kami ke Yandex dengan masalah permintaan ini. Tinjau, ikuti pautan dan lihat bahawa kuncinya adalah komersial:

Seret ke belakang.
7. Di atas senarai di medan "penapis cepat", tulis perkataan "harga" dan analisis:

Begitu juga, anda menapis dengan kata jual lain (beli, pesanan, bandar, harga) dan ambil semula kunci yang anda perlukan. Di ceruk ini, orang mencari trampolin tanpa jaring, dan mereka juga berakhir di bakul, saya akan membawanya ke kumpulan kerja.
8. Langkah seterusnya adalah membuang kunci yang tidak lengkap.
Ini adalah pertanyaan yang mempunyai bilangan yang layak dalam frekuensi dasar, dan angka nol dalam petikan (apabila frasa merangkumi bentuk kata, tetapi tidak termasuk kata lain) frekuensi.
Dengan kata lain, dalam bentuk ini tidak ada yang mencari mereka, dan mereka dapat memiliki entri dalam pertanyaan dengan semantik yang lebih luas, atau sekadar maklumat. Orang tidak menulis: "trampolin dengan jaring cm" - mungkin bermaksud trampolin dengan diameter tertentu. Dan ini sudah menjadi kunci maklumat.
Prosedur: klik pada medan "Frekuensi" "dan dengan itu urutkan frekuensi dengan tanda kutip dalam urutan menurun. Tatal ke frekuensi 0 dan lihat. Kami melihat perkara berikut:

Kami memadamkan semuanya seperti itu, jika tidak, kami akan dibiarkan tanpa wang.
9. Pembersihan bandar.
Kami sudah menulis bagaimana secara bebas membina teras semantik ... Tetapi sebelum anda mengkategorikan pertanyaan anda, anda perlu membersihkannya. Bagaimana untuk menghilangkan lapan tahap terak dan meninggalkan perak tulen? Perlu mengambil akaun dengan Pengumpul Kunci dan 12 minit untuk membaca siaran ini.
1. Membersihkan inti semantik dengan kata-kata penanda
Anda juga boleh menambahkan semua perkataan yang tidak diperlukan terus dari senarai pertanyaan yang lengkap. Dalam kes ini, kami membuat kumpulan yang berasingan - terutamanya untuk kata-kata berhenti.
Algoritma tindakan:

5. Bersihkan kernel menggunakan fungsi analisis kumpulan kata


Kumpulan yang ditandakan dalam jadual ditandai secara automatik dalam senarai permintaan utama. Setelah semua perkataan yang tidak sesuai ditandai, tutup jadual dan padam semua pertanyaan yang tidak perlu.
6. Mencari dan membuang pendua tersirat
Untuk menggunakan kaedah ini, anda mesti terlebih dahulu mengumpulkan maklumat mengenai kekerapan permintaan. Selepas itu, pergi ke tab "Data" - "Analisis pendua tersirat":



Program ini secara automatik akan menandakan semua pendua tersirat, frekuensi yang lebih rendah pada enjin carian yang ditentukan.
7. Pencarian manual mengikut kumpulan pertanyaan
Akhirnya, anda boleh menandakan semua perkataan yang tidak perlu dalam inti semantik secara manual: slang, perkataan yang salah eja, dan sebagainya. Susunan utama permintaan yang tidak relevan telah dibersihkan lebih awal, jadi pembersihan manual tidak akan memakan banyak masa.
8. Membersihkan pertanyaan mengikut kekerapan
Dengan menggunakan penapis lanjutan di KeyCollector, kami menetapkan parameter frekuensi permintaan dan menandakan semua frasa frekuensi rendah. Tahap ini diperlukan tidak selalu.

kesimpulan
Untuk membersihkan inti sampah semantik secara kualitatif, anda harus melakukan lapan langkah di KeyCollector:
- Pembersihan inti semantik dengan kata-kata penanda.
- Mengeluarkan kata ganda.
- Mengeluarkan huruf Latin, watak khas, pertanyaan dengan nombor.
- Pembersihan kernel menggunakan fungsi analisis kumpulan kata.
- Cari dan buang pendua tersirat.
- Pencarian manual mengikut kumpulan permintaan.
- Mengosongkan pertanyaan mengikut kekerapan.
Pada setiap tahap, disarankan untuk memeriksa kata-kata yang ditandai untuk dihapus, kerana ada risiko menghapus pertanyaan yang berkualiti tinggi dan relevan.
Daripada membuang pertanyaan yang tidak perlu, lebih baik membuat kumpulan yang terpisah dan memindahkannya ke sana. Dalam kemas kini terbaru kepada Key Collector, kumpulan lalai yang sesuai telah ditambahkan - "Recycle Bin".
Setelah membersihkan inti semantik secara menyeluruh, anda boleh melangkah ke peringkat seterusnya - pengelompokan dan pengelompokan pertanyaan.
Perhatikan bahawa selalu ada risiko kehilangan beberapa permintaan yang tidak relevan semasa pembersihan kernel. Mereka sangat mudah dikenali dan dikeluarkan pada peringkat pengelompokan, tetapi lebih banyak lagi pada masa berikutnya.







Hitung formula langkah demi langkah di Excel
Menggunakan lapisan pelarasan di Photoshop
Formula untuk mengira fungsi z dalam excel
Kekunci panas TOP untuk bekerja di Excel
Cara memeriksa LED, lampiran multimeter