1. Önem düzeyi α = 0.05 için F-F-test değerleri tablosu
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 12 | 24 | ∞ | |
| 1 | 161,45 | 199,50 | 215,72 | 224,57 | 230,17 | 233,97 | 238,89 | 243,91 | 249,04 | 254,32 |
| 2 | 18,51 | 19,00 | 19,16 | 19,25 | 19,30 | 19,33 | 19,37 | 19,41 | 19,45 | 19,50 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,84 | 8,74 | 8,64 | 8,53 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,04 | 5,91 | 5,77 | 5,63 |
| 5 | 6,61 | 5,79 | 5,41 | 5, 19 | 5,05 | 4,95 | 4,82 | 4,68 | 4,53 | 4,36 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,15 | 4,00 | 3,84 | 3,67 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,73 | 3,57 | 3,41 | 3,23 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,44 | 3,28 | 3,12 | 2,93 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,23 | 3,07 | 2,90 | 2,71 |
| 10 | 4,96 | 4,10 | 3,71 | 3,48 | 3,33 | 3,22 | 3,07 | 2,91 | 2,74 | 2,54 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3, 20 | 2,95 | 2,79 | 2,61 | 2,40 |
m = 1 olduğunda 1 sütun seçin.
k 2 = n-m = 7 - 1 = 6 - yani 6. sıra - Fisher'ın tablo değerini alın
F sekmesi = 5,99, bkz. = toplam: 7
x'in y üzerindeki etkisi orta ve negatif
ŷ - model değeri.
| F kalk. = | 28,648: 1 | = 0,92 |
| 200,50: 5 |
A = 1/7 * 398,15 * %100 = %8,1< 10% -
kabul edilebilir değer
Model yeterince doğru.
F kalk. = 1 / 0,92 = 1,6
F kalk. = 1,6< F табл. = 5,99
F hesabı olmalıdır. > F sekmesi
ihlal edildi bu model, bu nedenle, bu denklem istatistiksel olarak anlamlı değildir.
Hesaplanan değer tablo değerinden küçük olduğu için önemsiz bir modeldir.
| 1 | Σ | (y - ŷ) | *100% | |
| n | y |
Yaklaşım hatası.
A = 1/7 * 0,563494 * %100 = %8.04991 %8.0
Ortalama yaklaşım hatası %10'dan az ise modelin doğru olduğunu varsayıyoruz.
Bir çiftin parametrik tanımlaması Olumsuz doğrusal regresyon
Model y = a * x b - güç fonksiyonu
İyi bilinen formülü uygulamak için logaritma yapmanız gerekir. doğrusal olmayan model.
log y = log a + b log x
Y = C + b * X -doğrusal model.
C = 1.7605 - (- 0.298) * 1.7370 = 2.278
Orijinal modele dönüş
Ŷ = 10 sn * x b = 10 2.278 * x -0.298
| Yok | Sahip olmak | x | Y | x | Y * X | Sahip olmak | ben (y-ŷ) / yI | |
| 1 | 68,80 | 45,10 | 1,8376 | 1,6542 | 3,039758 | 2,736378 | 60,9614643 | 0,113932 |
| 2 | 61, 20 | 59,00 | 1,7868 | 1,7709 | 3,164244 | 3,136087 | 56,2711901 | 0,080536 |
| 3 | 59,90 | 57, 20 | 1,7774 | 1,7574 | 3,123603 | 3,088455 | 56,7931534 | 0,051867 |
| 4 | 56,70 | 61,80 | 1,7536 | 1,7910 | 3,140698 | 3, 207681 | 55,4990353 | 0,021181 |
| 5 | 55,00 | 58,80 | 1,7404 | 1,7694 | 3,079464 | 3,130776 | 56,3281590 | 0,024148 |
| 6 | 54,30 | 47, 20 | 1,7348 | 1,6739 | 2,903882 | 2,801941 | 60,1402577 | 0,107555 |
| 7 | 49,30 | 55, 20 | 1,6928 | 1,7419 | 2,948688 | 3,034216 | 57,3987130 | 0,164274 |
| Toplam | 405, 20 | 384,30 | 12,3234 | 12,1587 | 21,40034 | 21,13553 | 403,391973 | 0,563493 |
| Ortalama | 57,88571 | 54,90 | 1,760486 | 1,736957 | 3,057191 | 3,019362 | 57,62742 | 0,080499 |
EXCEL'e "Start" -programından giriyoruz. Verileri tabloya giriyoruz. "Servis" - "Veri Analizi" - "Regresyon" - Tamam
"Servis" menüsünde "Veri Analizi" satırı eksik ise "Servis" - "Ayarlar" - "Veri Analiz Paketi" üzerinden kurulum yapılmalıdır.
Şirketin ürünlerine olan talebi tahmin etmek. MS Excel'de "Trend" işlevini kullanma
A, ürüne olan taleptir. B - zaman, günler
| P / p No. | A | |
| 1 | 11 | 1 |
| 2 | 14 | 2 |
| 3 | 13 | 3 |
| 4 | 15 | 4 |
| 5 | 17 | 5 |
| 6 | 17,9 | |
| 7 | 18,4 | 7 |
Adım 1. İlk verilerin hazırlanması
Adım 2. Zaman eksenini uzatın, 6.7'ye ayarlayın; verilerin 1/3'ünü tahmin etme hakkımız var.
Adım 3. Altında A6: A7 aralığını seçin. gelecek tahmini.
Adım 4. İşlevi yerleştirin
Grafik özel düzgün grafikler ekle
aralık hazır.

Zaman eksenimizin sonraki her değeri birkaç yüzde değil, birkaç kez farklılık gösterecekse, "Trend" işlevini değil, "Büyüme" işlevini kullanmanız gerekir.
bibliyografya
1. Eliseeva "Ekonometri"
2. Eliseeva "Ekonometri Çalıştayı"
3. Carlsberg "Analiz Amacıyla Excel"
Başvuru
| SONUÇLARIN SONUÇLARI | ||||||||
| Kayıt istatistikleri | ||||||||
| Çoklu R | 0,947541801 | |||||||
| R Meydanı | 0,897835464 | |||||||
| Normalleştirilmiş R-kare | 0,829725774 | |||||||
| Standart hata | 0,226013867 | |||||||
| gözlemler | 6 | |||||||
| ANOVA | ||||||||
| F'nin Önemi | ||||||||
| regresyon | 2 | 1,346753196 | 0,673376598 | 13,18219855 | 0,032655042 | |||
| kalan | 3 | 0,153246804 | 0,051082268 | |||||
| Toplam | 5 | 1,5 | ||||||
| oranlar | Standart hata | t-istatistikleri | P-değeri | Alt %95 | En yüksek %95 | Alt %95 | En yüksek %95 |
|
| Y-kavşak | 4,736816539 | 0,651468195 | 7,27098664 | 0,005368842 | 2,66355399 | 6,810079088 | 2,66355399 | 6,810079088 |
| Değişken X1 | 0,333424008 | 0,220082134 | 1,51499807 | 0,227014505 | -0,366975566 | 1,033823582 | -0,366975566 | |





Açık bu örnek Ortaya çıkan regresyon denkleminin güvenilirliğinin nasıl tahmin edildiğini düşünün. Aynı test, regresyon katsayılarının aynı anda sıfıra, a = 0, b = 0'a eşit olduğu hipotezini test etmek için kullanılır. Başka bir deyişle, hesaplamaların özü şu soruyu cevaplamaktır: daha fazla analiz ve tahmin için kullanılabilir mi?
İki örnekteki varyanslardaki benzerliği veya farkı belirlemek için bu t-testini kullanın.
Bu nedenle, analizin amacı, belirli bir α seviyesinde elde edilen regresyon denkleminin istatistiksel olarak güvenilir olduğunu iddia etmenin mümkün olacağı bir tahmin elde etmektir. Bunun için belirleme katsayısı R 2 kullanılır.
Regresyon modelinin öneminin kontrol edilmesi, hesaplanan değeri, çalışılan göstergenin ilk gözlem serisinin varyansının oranı ve kalıntının varyansının tarafsız tahmini olarak bulunan Fisher's F-testi kullanılarak gerçekleştirilir. Bu model için sıra.
k 1 = (m) ve k 2 = (n-m-1) serbestlik derecesi ile hesaplanan değer, belirli bir önem düzeyi için tablo değerinden büyükse, model anlamlı kabul edilir.
burada m, modeldeki faktör sayısıdır.
Seviye İstatistiksel anlamlılık eşleştirilmiş doğrusal regresyon, aşağıdaki algoritmaya göre gerçekleştirilir:
1. Dışarı kayar sıfır hipotezi denklemin bir bütün olarak istatistiksel olarak önemsiz olduğunu: α anlamlılık düzeyinde H 0: R 2 = 0.
2. Ardından, F kriterinin gerçek değeri belirlenir: ![]()
![]()
burada m = 1 eşleştirilmiş regresyon için.
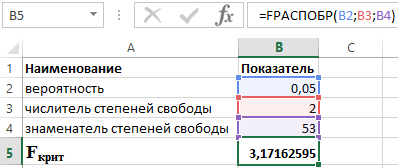
3. Tablo değeri, aşağıdakiler için Fisher dağılım tablolarından belirlenir: verilen seviye serbestlik derecelerinin sayısı dikkate alındığında, toplam tutar kareler (daha büyük varyans) 1'dir ve doğrusal regresyon için kalan kareler toplamının (daha küçük varyans) serbestlik derecesi sayısı n-2'dir (veya Excel işlevi FDISP (olasılık; 1; n-2)).
F tablosu, belirli bir serbestlik derecesi ve α anlamlılık düzeyi için rastgele faktörlerin etkisi altında kriterin mümkün olan maksimum değeridir. Önem düzeyi α, doğru olması koşuluyla doğru bir hipotezi reddetme olasılığıdır. Genellikle α 0.05 veya 0.01'e eşit olarak alınır.
4. F-kriterinin gerçek değeri tablodaki değerden küçükse, sıfır hipotezini reddetmek için bir neden olmadığını söylerler.
Aksi takdirde, boş hipotez reddedilir ve bir bütün olarak denklemin istatistiksel önemi hakkında alternatif bir hipotez olasılıkla (1-α) ile kabul edilir.
Kriterin serbestlik dereceli tablo değeri k 1 = 1 ve k 2 = 48, F sekmesi = 4
sonuçlar: Gerçek değer F>F tablosu olduğundan, tespit katsayısı istatistiksel olarak anlamlıdır ( regresyon denkleminin bulunan tahmini istatistiksel olarak güvenilirdir) .
ANOVA
.Regresyon Denklemi Kalite Göstergeleri
Bir örnek. 25 ticari işletmenin toplamı için, özellikler arasındaki ilişki incelenmektedir: X - A ürününün fiyatı, bin ruble; Y - kar ticari işletme, milyon ruble değerlendirirken Regresyon modeli aşağıdaki ara sonuçlar elde edildi: ∑ (y ben -y x) 2 = 46000; ∑ (y i -y ort) 2 = 138000. Bu verilerden belirlenebilecek korelasyon indeksi nedir? Bu sonuca göre bu göstergenin değerini hesaplayın ve Fisher'ın F testi regresyon modelinin kalitesi hakkında bir sonuç çıkarmak.
Çözüm. Bu verilere dayanarak, ampirik korelasyon oranını belirlemek mümkündür:  , burada ∑ (y av -y x) 2 = ∑ (y ben -y av) 2 - ∑ (y ben -y x) 2 = 138000 - 46000 = 92000.
, burada ∑ (y av -y x) 2 = ∑ (y ben -y av) 2 - ∑ (y ben -y x) 2 = 138000 - 46000 = 92000.
η 2 = 92 000/138000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
Fisher'ın F testi: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0,67, F = 0,67 / (1-0,67) x (25 - 1 - 1) = 46. F sekmesi (1; 23) = 4,27
Gerçek değer F> Ftabl olduğundan, regresyon denkleminin bulunan tahmini istatistiksel olarak güvenilirdir.
S: Bir regresyon modelinin önemini test etmek için hangi istatistikler kullanılır?
Cevap: Tüm modelin bir bütün olarak anlamlılığı için F-istatistikleri (Fisher testi) kullanılır.
Randevu.İki varyansın aynı genel popülasyona ait olduğu ve dolayısıyla eşitliklerinin olduğu hipotezinin test edilmesi.
Sıfır hipotezi. S 2 2 = S 1 2
Alternatif hipotez... var aşağıdaki seçenekler HA, kritik alanların farklılık gösterdiğine bağlı olarak:
1.S 1 2> S 2 2. HA'nın en sık kullanılan çeşidi Kritik bölge F dağılımının üst kuyruğudur.
2.S 1 2< S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. Çift taraflı S 1 2 ≠ S 2 2. İlk ikisinin birleşimi.
Önkoşullar. Veriler bağımsızdır ve normal yasaya göre dağıtılır. İki normal genel popülasyonun varyanslarının eşitliği hakkındaki hipotez, daha büyük varyansın daha küçük olana oranı daha küçükse kabul edilir. kritik Fisher dağıtımı.
F P = S 1 2 / S 2 2
Not. Tarif edilen test yöntemi ile Fsc değeri birden büyük olmalıdır. Kriter, normallik varsayımının ihlaline karşı hassastır.
İki taraflı alternatif S 1 2 ≠ S 2 2 için, koşul sağlanırsa boş hipotez kabul edilir:
F l - α / 2< Fрасч < F α /2
Örnek
Termofiziksel olanlar karmaşık termometrik yöntemle belirlendi. yeşil maltın özellikleri (TFH). Numuneleri hazırlamak için havada kuru (ortalama nem W = %19) ve ıslak dört günlük malt (W = %45) aldık. yeni teknoloji karamel malt yapımı. Deneyler, ıslak maltın termal iletkenliğinin (λ) kuru malttan yaklaşık 2,5 kat daha yüksek olduğunu ve hacimsel ısı kapasitesinin maltın nem içeriğine açık bir bağımlılığa sahip olmadığını göstermiştir. Bu nedenle, F kriterini kullanarak, nemi hesaba katmadan ortalama değerlerdeki verileri özetleme olasılığını kontrol ettik.
Hesaplanan veriler tablo 5.1'de özetlenmiştir.
Tablo 5.1
F kriterinin hesaplanması için veriler
W = %45 için daha büyük bir varyans değeri elde edildi, yani. S 2 45 = S 1 2, S 2 19 = S 2 2 ve F P = S 1 2 / S 2 2 = 1.35. γ = 0.95'te f 1 = N 1 -1 = 5 f 2 = N 2 -1 = 4 serbestlik derecesi için tablo 5.2'den F KP = 6.2'yi belirleriz. “Yeşil malt nem içeriği %19 ile %45 aralığında, hacimsel ısı kapasitesi üzerindeki etkisi ihmal edilebilir” veya “S 2 45 = S 2 19” olarak formüle edilen sıfır hipotezi %95 güven seviyesi ile doğrulanmıştır. , Fp'den beri Fisher'in Excel kullanarak testine göre iki varyansın aynı genel popülasyona ait olduğu hipotezini test etmeye bir örnek Buğday tanesinin su emme derecesinin iki bağımsız örneğine (Tablo 5.2) ilişkin veriler verilmiştir.Düşük frekanslı manyetik alanların etkisi üzerine bir çalışma yapılmıştır. Tablo 5.2 Araştırma sonuçları Bu örneklerin ortalamalarının eşitliği hakkındaki hipotezi test etmeden önce, onu test etmek için hangi kriterlerin seçileceğini bilmek için varyansların eşitliği hakkındaki hipotezi test etmek gerekir. İncirde. 5.1, Microsoft Excel yazılım ürününü kullanarak Fisher'in kriterine göre iki varyansın aynı genel popülasyona ait olduğu hipotezini test etmenin bir örneğini gösterir. Şekil 5.1 Fisher testi ile aynı genel popülasyonun iki varyansının üyeliğini kontrol etme örneği Orijinal veriler, C ve D sütunlarının 3-10. satırlarla kesiştiği yerde bulunan hücrelerde bulunur. Aşağıdakileri yapalım. 1. Birinci ve ikinci örneklerin dağılım yasasının normal kabul edilip edilemeyeceğini belirleyin (sırasıyla C ve D sütunları). Değilse (en azından bir örnek için), parametrik olmayan bir test kullanmak gerekir, evet ise devam ederiz. 2. Birinci ve ikinci sütunlar için varyansları hesaplayalım. Bunu yapmak için, SP ve D11 hücrelerinde sırasıyla = VAR (SZ: C10) ve = VAR (DZ: D10) fonksiyonlarını koyduk. Bu fonksiyonların sonucu, sırasıyla her sütun için hesaplanan varyans değeridir. 3. Fisher kriteri için hesaplanan değeri bulun. Bunu yapmak için, büyük varyansı küçük olana bölün. F13 hücresine, bu işlemi gerçekleştiren = C11 / D11 formülünü koyduk. 4. Varyansların eşitliği hipotezini kabul etmenin mümkün olup olmadığını belirleyin. Örnekte sunulan iki yol vardır. Birinci yönteme göre, örneğin 0.05 gibi bir anlamlılık düzeyi verildiğinde, bu değer ve karşılık gelen serbestlik derecesi sayısı için Fisher dağılımının kritik değeri hesaplanır. = FPACPOBP (0.05; 7; 7) fonksiyonunu F14 hücresine girin (0,05 belirtilen anlamlılık düzeyidir; 7, payın serbestlik derecesi sayısıdır ve 7 (saniye) serbestlik derecesi sayısıdır). payda). Serbestlik derecesi sayısı, eksi bir deney sayısına eşittir. Sonuç 3.787051'dir. Bu değer hesaplanan 1.81144'ten büyük olduğu için varyansların eşitliği sıfır hipotezini kabul etmeliyiz. İkinci seçeneğe göre, Fisher kriterinin elde edilen hesaplanan değeri için karşılık gelen olasılık hesaplanır. Bunu yapmak için, F15 hücresine = FPACP (F13; 7; 7) işlevini girin. Elde edilen 0.22566 değeri 0.05'ten büyük olduğu için varyansların eşitliği hipotezi kabul edilir. Bu, özel bir işlevle yapılabilir. Öğeleri sırayla menüden seçin Hizmet
, Veri analizi
... Aşağıdaki formun bir penceresi görünecektir (Şekil 5.2). Şekil 5.2 İşleme yöntemi seçim penceresi Bu pencerede “ Dispersiyonlar için iki örnekli F-mecm
". Sonuç olarak, Şekil 2'de gösterilen formun bir penceresi. 5.3. Burada birinci ve ikinci değişkenlerin aralıklarını (hücre numaraları), önem düzeyini (alfa) ve sonucun bulunacağı yeri ayarlarsınız. Gerekli tüm parametreleri belirtin ve Tamam'a tıklayın. Çalışmanın sonucu Şekil 1'de gösterilmektedir. 5.4 Unutulmamalıdır ki, fonksiyon tek yönlü bir kriteri kontrol eder ve doğru yapar. Kriter değerinin 1'den büyük olması durumunda üst kritik değer hesaplanır. Şekil 5.3 Parametre ayar penceresi Kriter değeri 1'den küçük olduğunda alt kritik değer hesaplanır. Kriter değerinin üst kritik değerden büyük veya alt kritik değerden küçük olması durumunda varyansların eşitliği hipotezinin reddedildiğini hatırlatırız. Şekil 5.4 Varyansların eşitliğinin kontrol edilmesi FISHER işlevi, X bağımsız değişkenleri için bir Fisher dönüşümü döndürür. Bu dönüşüm, normal, çarpık olmayan bir dağılıma sahip bir işlev oluşturur. FISHER işlevi, korelasyon katsayısını kullanarak hipotezi test etmek için kullanılır. Bu fonksiyonla çalışırken değişkenin değerini ayarlamalısınız. Bu fonksiyonun sonuç vermediği bazı durumlar olduğu hemen belirtilmelidir. Bu, değişken ise mümkündür: FISHER işlevini matematiksel olarak tanımlamak için kullanılan denklem şudur: Z "= 1/2 * ln (1 + x) / (1-x) Bu işlevin uygulamasını 3 özel örnek üzerinde ele alalım. Örnek 1. Ticari kuruluşların faaliyetlerine ilişkin verileri kullanarak, ürün geliştirme için kullanılan kar Y (milyon ruble) ve maliyetler X (milyon ruble) arasındaki ilişkiyi değerlendirmek gerekir (Tablo 1'de gösterilmiştir). Tablo 1 - İlk veriler: Bu tür sorunları çözme şeması aşağıdaki gibidir: Excel paketinde kullanılan fonksiyonlarla bu problemin çözülmesinin sonuçları Şekil 1'de gösterilmiştir. Şekil 1 - Hesaplama örneği. Bu nedenle, 0,95 olasılıkla, doğrusal korelasyon katsayısı 0,205 standart hatayla (-0,386) ila (-0,990) aralığındadır. Örnek 2. Fisher's F-testini kullanarak çoklu regresyon denkleminin istatistiksel anlamlılığını kontrol edin, sonuçlar çıkarın. Denklemin bir bütün olarak önemini test etmek için, belirleme katsayısının istatistiksel önemsizliği hakkında H 0 hipotezini ve belirleme katsayısının istatistiksel önemi hakkında karşıt hipotez H 1'i ortaya koyduk: H 1: R2 ≠ 0. Fisher's F-testini kullanarak hipotezleri test edelim. Göstergeler tablo 2'de gösterilmiştir. Tablo 2 - İlk veriler Bunu yapmak için Excel paketindeki işlevi kullanın: FDESIGN (α; p; n-p-1) α = 0.05, p = 2 ve n = 53 olduğunu bilerek, F crit için aşağıdaki değeri elde ederiz (bkz. Şekil 2). Şekil 2 - Hesaplama örneği. Böylece F calc> F crit diyebiliriz. Sonuç olarak, belirleme katsayısının istatistiksel anlamlılığına ilişkin H 1 hipotezi kabul edilmiştir. Örnek 3. Aşağıdakilerle ilgili 23 işletmenin verilerini kullanmak: X - A ürününün fiyatı, bin ruble; Y, ticari bir işletmenin kârıdır, milyon ruble; bağımlılıkları incelenir. Regresyon modelinin değerlendirmesi aşağıdakileri verdi: ∑ (yi-yx) 2 = 50.000; ∑ (yi-yav) 2 = 130.000 Bu verilerden belirlenebilecek korelasyon indeksi nedir? Korelasyon indeksinin değerini hesaplayın ve Fisher kriterini kullanarak regresyon modelinin kalitesi hakkında bir sonuç çıkarın. İfadeden F kritiğini belirleyin: F hesap = R 2/23 * (1-R 2) burada R, 0.67'ye eşit belirleme katsayısıdır. Böylece hesaplanan F calc değeri = 46 olur. F kritiğini belirlemek için Fisher dağılımını kullanırız (bkz. Şekil 3). Şekil 3 - Hesaplama örneği. Böylece, elde edilen regresyon denklemi tahmini güvenilirdir. (sağ elini kullanan) F olasılık dağılımının tersini verir. p = FDAĞ (x, ...) ise, o zaman FDAĞ (p; ...) = x. F-dağılımı, iki veri setinin dağılımını karşılaştıran F-testinde kullanılabilir. Örneğin, iki ülkenin gelir yoğunluğu açısından benzer olup olmadığını belirlemek için Amerika Birleşik Devletleri ve Kanada'daki gelir dağılımını analiz edebilirsiniz. Önemli: Bu işlevin yerini, daha kesin olan ve amaçlarına göre daha iyi adlara sahip bir veya daha fazla yeni işlev almıştır. Bu özellik hala geriye dönük uyumluluk için kullanılsa da, Excel'in gelecekteki sürümlerinde bulunmayabilir, bu nedenle yeni özellikleri kullanmanızı öneririz. Yeni işlevler hakkında daha fazla bilgi edinmek için bkz. İşlev F.INV ve İşlev F.INV.PX. FREV (olasılık, serbestlik derecesi1, serbestlik derecesi2) FRESIST işlevinin bağımsız değişkenleri aşağıda açıklanmıştır. olasılık- gerekli argüman. Kümülatif F dağılımıyla ilişkili olasılık. Derece_özgürlük1- gerekli argüman. Serbestlik derecesinin payı. Derece_özgürlük2- gerekli argüman. Serbestlik derecelerinin paydası. Argümanlardan herhangi biri sayısal değilse, FROMINV, #DEĞER!Hata değerini döndürür. "olasılık" ise< 0 или "вероятность" >1, FROMINV, #SAYI!Hata değerini döndürür. "liberty_degree1" veya "liberty_degree2" değeri bir tamsayı değilse, kesilir. "derece_özgürlük1" ise< 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. "derece_özgürlük2" ise< 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. FREVERSION işlevi, F dağılımının kritik değerlerini belirlemek için kullanılabilir. Örneğin, ANOVA sonuçları tipik olarak F istatistiği, F olasılıkları ve F dağılımının kritik değeri için 0,05 anlamlılık düzeyiyle ilgili verileri içerir. F'nin kritik değerini belirlemek için, DÖNDÜRME işlevinin olasılık argümanı olarak önem düzeyini kullanmanız gerekir. Bir olasılık değeri verildiğinde, FDAĞ işlevi, FDIST (x; serbestlik derecesi1; serbestlik derecesi2) = olasılık olan bir x değerini arar. Bu nedenle, FDIST'in doğruluğu, FDIST'in doğruluğuna bağlıdır. FRONST işlevi, arama yapmak için yineleme yöntemini kullanır. 100 iterasyondan sonra arama bitmezse, # N / A hata değeri döndürülür. Aşağıdaki tablodan örnek verileri kopyalayın ve yeni bir Excel çalışma sayfasının A1 hücresine yapıştırın. Formüllerin sonuçlarını görüntülemek için bunları seçin ve F2'ye ve ardından Enter'a basın. Tüm verileri görmek için sütunların genişliğini gerektiği gibi değiştirin.Sayı Örnek numarası
tecrübe etmek
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075




FISHER işlevi Excel'de nasıl çalışır?
FISHER fonksiyonu ile kar ve maliyet arasındaki ilişkinin değerlendirilmesi
№
x Y
1
210.000.0000,00 ₽ 95.000.0000,00 ₽
2
1.068.000.0000,00 ₽ 76.000.0000,00 ₽
3
1,005,000,000,00 ₽ 78.000.0000,00 ₽
4
610.000.0000,00 ₽ 89.000.000,00 ₽
5
768.000.0000,00 ₽ 77.000.0000,00 ₽
6
799,0000,000,00 ₽ 85.000.0000,00 ₽
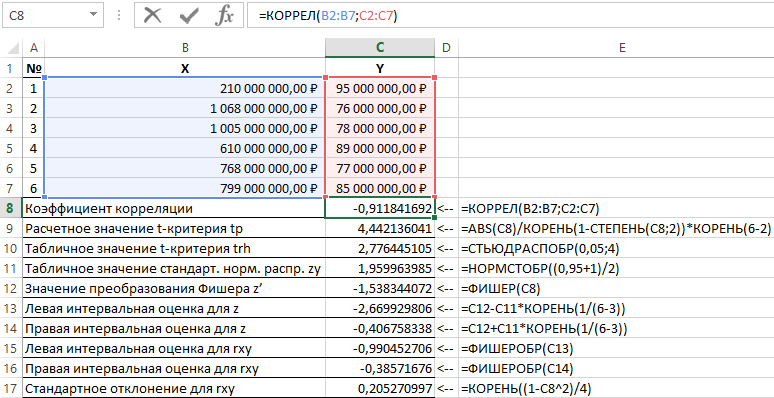
P / p No. Gösterge adı Hesaplama formülü
1
Korelasyon katsayısı = KOREL (B2: B7; C2: C7)
2
t-testi tp'nin hesaplanan değeri = ABS (C8) / KÖK (1-DEGREE (C8,2)) * KÖK (6-2)
3
t-test trh'nin tablo değeri = TYUDRASPOBR (0,05,4)
4
Standart normal dağılımın tablo değeri zy = NORMSINV ((0.95 + 1) / 2)
5
Fischer dönüşüm değeri z' = BALIKÇI (C8)
6
z için Sol Aralık Tahmini = C12-C11 * KÖK (1 / (6-3))
7
z için doğru aralık tahmini = C12 + C11 * KÖK (1 / (6-3))
8
rxy için Sol Aralık Tahmini = BALIKÇIĞI (C13)
9
rxy için doğru aralık tahmini = BALIKÇIĞI (C14)
10
rxy için standart sapma = KÖK ((1-C8 ^ 2) / 4)
FRASPINV işleviyle regresyonun istatistiksel önemini kontrol etme
Excel'de korelasyon indeksinin değerini hesaplama

Sözdizimi
Uyarılar
Örnek







Arkadaşlarınızı VKontakte'de ücretsiz olarak aldatın
Yeni başlayanlar için yatırım yapmadan İnternetten gerçekten nasıl para kazanılır Yatırım yapmadan İnternetten para kazanmanın gerçek yolları
Terfide davranışsal faktörler ve bunları geliştirmek için çalışma yöntemleri
VKontakte sayfasına trafik nasıl bulunur ve artırılır
Honor Phone'da Hızlı Şarj Uygulaması