Ahojte všetci!
Len včera som našiel knihu od Tariqa Rashida „Vytvorte si vlastnú neurónovú sieť“. Kniha je bestsellerom (prvá v predajnosti) v sekcii „Umelá inteligencia“. Kniha je čerstvá, vyšla minulý rok.
Dojmy z prvých častí sú nádherné. Jeden z najlepších úvodov do neurónových sietí, aké som kedy videl. Kniha sa mi tak páčila, že som sa rozhodol preložiť ju do ruštiny a uverejniť ju tu vo forme článkov. Časť materiálu z knihy sa použije na vylepšenie existujúcich kapitol, časť na ďalšiu.
Už preložil prvé dve časti 1. kapitoly. Môžete použiť tieto sekcie.
Prečítajte si - užite si to!
Kapitola 1. Ako fungujú.
1.1 Ľahko pre mňa, ťažko pre vás
Všetky počítače sú kalkulačky v sprche. Vedia veľmi rýchlo počítať.
Neobviňujte ich z toho. Robia skvelú prácu: vypočítajú cenu s prihliadnutím na zľavu, účtujú úroky z dlhu, kreslia grafy podľa dostupných údajov atď.
Dokonca aj sledovanie televízie alebo počúvanie hudby na počítači zahŕňa vykonávanie obrovského množstva aritmetických operácií znova a znova. Môže to znieť prekvapivo, ale vykreslenie každej snímky obrázka z núl a jednotiek prijatých cez internet zahŕňa výpočty, ktoré nie sú oveľa náročnejšie ako problémy, ktoré sme všetci riešili v škole.
Schopnosť počítača sčítať tisíce a milióny čísel za sekundu však vôbec nie je umelá inteligencia. Pre človeka je ťažké pridať čísla tak rýchlo, ale musíte súhlasiť s tým, že táto práca si nevyžaduje vážne intelektuálne náklady. Je potrebné dodržiavať predtým známy algoritmus na sčítanie čísel a nič viac. To je to, čo robia všetky počítače - dodržiavajú jasný algoritmus.
S počítačmi je všetko jasné. Teraz si povedzme, v čom sme v porovnaní s nimi dobrí.
Pozrite sa na obrázky nižšie a určite, čo je na nich zobrazené:

Na prvom obrázku môžete vidieť tváre ľudí, na druhom tvár mačky a na treťom strom. Spoznali ste predmety na týchto obrázkoch. Všimnite si, že ste mali iba letmý pohľad, aby ste neomylne pochopili, čo je na nich zobrazené. V takýchto veciach sa málokedy mýlime.
Okamžite a bez väčších ťažkostí vnímame obrovské množstvo informácií, ktoré obrázky obsahujú a veľmi presne určujeme objekty na nich. Ale každému počítaču takáto úloha prejde krkom.
Každému počítaču, bez ohľadu na jeho zložitosť a rýchlosť, chýba jedna dôležitá vlastnosť – inteligencia, ktorou disponuje každý človek.
Ale chceme naučiť počítače riešiť takéto problémy, pretože sú rýchle a neunavujú. Umelá inteligencia sa práve týmto problémom zaoberá.
Počítače budú samozrejme aj naďalej tvorené mikroobvodmi. Úlohou umelej inteligencie je nájsť nové algoritmy prácu počítača, ktorá umožní riešiť intelektuálne problémy. Tieto algoritmy nie sú vždy dokonalé, ale plnia svoju úlohu a vyvolávajú dojem, že počítač sa správa ako človek.
Kľúčové body
- Existujú úlohy, ktoré sú pre bežné počítače jednoduché, no ľuďom spôsobujú aj ťažkosti. Napríklad vynásobením milióna čísel medzi sebou.
- Na druhej strane sú tu rovnako dôležité úlohy, ktoré sú pre počítač neskutočne náročné a ľuďom nerobia problémy. Napríklad rozpoznávanie tváre na fotografiách.
1.2 Jednoduchý prediktívny motor
Začnime niečím veľmi jednoduchým. Ďalej budeme stavať na materiáli študovanom v tejto časti.
Predstavte si stroj, ktorý dostane otázku, „rozmýšľa“ nad ňou a potom vydá odpoveď. Vo vyššie uvedenom príklade ste dostali obrázok ako vstup, analyzovali ste ho pomocou mozgu a urobili ste záver o objekte, ktorý je na ňom zobrazený. Vyzerá to asi takto:

Počítače v skutočnosti nič „nevymyslia“. Jednoducho používajú predtým známe aritmetické operácie. Nazvime preto veci pravým menom:

Počítač akceptuje niektoré údaje ako vstup, vykoná potrebné výpočty a vytvorí hotový výsledok. Zvážte nasledujúci príklad. Ak výraz \ (3 \ krát 4 \) príde na vstup počítača, potom sa prevedie na jednoduchšiu postupnosť sčítaní. V dôsledku toho dostaneme výsledok - 12.

Nevyzerá to príliš pôsobivo. Toto je fajn. S týmito triviálnymi príkladmi uvidíte myšlienku implementácie neurónových sietí.
Teraz si predstavte auto, ktoré prepočítava kilometre na míle:

Teraz si predstavte, že nepoznáme vzorec, podľa ktorého sa kilometre prepočítavajú na míle. Vieme len, že vzťah medzi týmito dvoma veličinami lineárne... To znamená, že ak zdvojnásobíme vzdialenosť v míľach, potom sa zdvojnásobí aj vzdialenosť v kilometroch. Je to intuitívne. Vesmír by bol veľmi zvláštny, keby sa toto pravidlo nedodržiavalo.
Lineárny vzťah medzi kilometrami a míľami nám dáva tip, akou formou previesť jednu hodnotu na druhú. Túto závislosť môžeme reprezentovať takto:
\ [\ text (míle) = \ text (kilometre) \ krát C \]
Vo výraze vyššie funguje \ (C \) ako nejaké konštantné číslo - konštanta. Zatiaľ nevieme, čo je \ (C \).
Jediné, čo vieme, je niekoľko vopred nameraných vzdialeností v kilometroch a míľach.
A ako zistíte význam \ (C \)? Poďme na to náhodnýčíslo a povedzme, že naša konštanta sa mu rovná. Nech \ (C = 0,5 \). Čo sa bude diať?

Za predpokladu, že \ (C = 0,5 \) dostaneme 50 míľ zo 100 kilometrov. To je vynikajúci výsledok vzhľadom na skutočnosť, že sme zvolili \ (C = 0,5 \) celkom náhodou! Vieme ale, že naša odpoveď nie je úplne správna, pretože podľa tabuľky správnych meraní sme mali dostať 62 137 míľ.
Minuli sme 12 137 míľ. Toto je náš chyba- rozdiel medzi prijatou odpoveďou a vopred známym správnym výsledkom, ktorý v tomto prípade máme v tabuľke.
\ [\ začiatok (zhromaždiť *) \ text (chyba) = \ text (správna hodnota) - \ text (prijatá odpoveď) \\ = 62,137 - 50 \\ = 12,137 \ koniec (zhromaždiť *) \]

Pozrime sa znova na chybu. Výsledná vzdialenosť je kratšia o 12,137. Pretože vzorec na prevod kilometrov na míle je lineárny ( \ (\ text (míle) = \ text (kilometre) \ krát C \)), Potom zvýšenie hodnoty \ (C \) zvýši aj výkon v míľach.
Predpokladajme teraz, že \ (C = 0,6 \) a uvidíme, čo sa stane.
Keďže \ (C = 0,6 \), potom na 100 kilometrov máme \ (100 \ krát 0,6 = 60 \) míľ. Je to oveľa lepšie ako predchádzajúci pokus (v tom čase to bolo 50 míľ)! Teraz je naša chyba veľmi malá – iba 2,137 míle. Celkom presný výsledok.

Teraz venujte pozornosť tomu, ako sme získanú chybu použili na opravu hodnoty konštanty \ (C \). Potrebovali sme zvýšiť výstupné míle a mierne sme zvýšili hodnotu \ (C \). Všimnite si, že na získanie presného významu \ (C \) nepoužívame algebru, ale mohli by sme. prečo? Pretože svet je plný problémov, ktoré nemajú jednoduchý matematický vzťah medzi prijatým vstupom a vráteným výstupom.
Práve na úlohy, ktoré sa prakticky neriešia jednoduchým počítaním, potrebujeme také sofistikované veci, akými sú neurónové siete.

Môj Bože! Chytili sme príliš veľa a prekročili sme správne skóre. Naša predchádzajúca chyba bola 2,137 a teraz je to -7,863. Mínus znamená, že náš výsledok sa ukázal byť viac ako správna odpoveď, pretože chyba sa počíta ako správna odpoveď - (mínus) prijatá odpoveď.
Ukazuje sa, že pre \ (C = 0,6 \) máme oveľa presnejší výstup. Toto sa mohlo skončiť. Ale poďme ešte zvýšiť \ (C \), ale nie veľa! Nech \ (C = 0,61 \).

To je lepšie! Naše auto prejde 61 míľ, čo je len o 1,137 míle menej ako správna odpoveď (62,137).
Z tejto situácie prekročenia správnej odpovede si treba vziať dôležité ponaučenie. Ako sa približujete k správnej odpovedi, parametre auta by sa mali meniť čoraz slabšie. To pomôže vyhnúť sa nepríjemným situáciám, ktoré vedú k prekročeniu správnej odpovede.
Výška našej korekcie \ (C \) závisí od chyby. Čím väčšia je naša chyba, tým výraznejšie meníme hodnotu \ (C \). Ale keď je chyba malá, je potrebné trochu zmeniť \ (C \). Dáva to zmysel, nie?
Verte či nie, práve ste pochopili samotnú podstatu fungovania neurónových sietí. Trénujeme „stroje“, aby postupne produkovali stále presnejšie výsledky.
Je tiež dôležité pochopiť, ako sme tento problém vyriešili. Nevyriešili sme to na jeden záťah, aj keď v tomto prípade sa to dalo zvládnuť. Namiesto toho sme dospeli k správnej odpovedi. krok za krokom aby sa naše výsledky každým krokom zlepšovali.
Nie je vysvetlenie veľmi jednoduché a priamočiare? Osobne som sa nestretol so stručnejším spôsobom, ako vysvetliť, čo je neurónová sieť.
Ak niečomu nerozumiete, pýtajte sa na fóre.
Váš názor je pre mňa dôležitý - zanechajte komentár 🙂
Tento článok obsahuje materiály – väčšinou rusky hovoriace – pre základné štúdium umelých neurónových sietí.
Umelá neurónová sieť alebo ANN je matematický model, rovnako ako jeho softvérová alebo hardvérová implementácia, postavená na princípe organizácie a fungovania biologických neurónových sietí – sietí nervových buniek živého organizmu. Veda o neurónových sieťach existuje už dlho, no práve v súvislosti s najnovšími výdobytkami vedecko-technického pokroku si táto oblasť začína získavať na popularite.
knihy
Začnime našu zbierku klasickým spôsobom učenia – pomocou kníh. Vybrali sme knihy v ruskom jazyku s veľkým počtom príkladov:
- F. Wasserman, Neurocomputer Engineering: Theory and Practice. 1992 rok
Kniha načrtáva základy budovania neuropočítačov verejnou formou. Je popísaná štruktúra neurónových sietí a rôzne algoritmy na ich ladenie. Samostatné kapitoly sú venované implementácii neurónových sietí. - S. Khaikin, Neurónové siete: Kompletný kurz. rok 2006
Tu sú diskutované hlavné paradigmy umelých neurónových sietí. Predkladaný materiál obsahuje dôsledné matematické zdôvodnenie všetkých paradigiem neurónových sietí, ilustrované príkladmi, popismi počítačových experimentov, obsahuje množstvo praktických problémov, ako aj rozsiahlu bibliografiu.
D. Forsyth, Počítačové videnie. Moderný prístup. 2004 r.
Počítačové videnie je jednou z najžiadanejších oblastí v tejto fáze vývoja globálnych digitálnych počítačových technológií. Vyžaduje sa vo výrobe, pri riadení robotov, pri automatizácii procesov, v medicínskych a vojenských aplikáciách, pri pozorovaní zo satelitov a pri práci s osobnými počítačmi, najmä pri vyhľadávaní digitálnych obrazov.
Video
Nie je nič prístupnejšie a zrozumiteľnejšie ako vizuálny tréning pomocou videa:
- Ak chcete pochopiť, o čom je strojové učenie, pozrite sa sem. tieto dve prednášky od SHAD Yandex.
- Úvod k základným princípom návrhu neurónových sietí – skvelé na pokračovanie v oboznámení sa s neurónovými sieťami.
- Prednáškový kurz na tému „Počítačové videnie“ z VMK MsÚ. Počítačové videnie je teória a technológia na vytváranie umelých systémov, ktoré detekujú a klasifikujú objekty na obrázkoch a videozáznamoch. Tieto prednášky možno klasifikovať ako úvod do tejto zaujímavej a komplexnej vedy.
Vzdelávacie zdroje a užitočné odkazy
- Portál umelej inteligencie.
- Laboratórium „Ja som intelekt“.
- Neurónové siete v Matlabe.
- Neurónové siete v Pythone:
- Klasifikácia pomocou textu;
- Jednoduché .
- Neurónová sieť zapnutá.
Naša séria publikácií na túto tému
Už predtým sme kurz zverejnili #[e-mail chránený] cez neurónové siete. V tomto zozname sú publikácie zoradené podľa poradia štúdia pre vaše pohodlie.
Podľa toho berie neurónová sieť dve čísla ako vstup a na výstupe musí dať ďalšie číslo – odpoveď. Teraz o samotných neurónových sieťach.Čo je to neurónová sieť?

Neurónová sieť je sekvencia neurónov spojených synapsiami. Štruktúra neurónovej siete prišla do programovacieho sveta priamo z biológie. Vďaka tejto štruktúre stroj získava schopnosť analyzovať a dokonca si zapamätať rôzne informácie. Neurónové siete sú tiež schopné prichádzajúce informácie nielen analyzovať, ale aj reprodukovať zo svojej pamäte. Pre záujemcov si určite pozrite 2 videá z TED Talks: Video 1 , Video 2). Inými slovami, neurónová sieť je strojová interpretácia ľudského mozgu, ktorá obsahuje milióny neurónov, ktoré prenášajú informácie vo forme elektrických impulzov.
Čo sú neurónové siete?
Zatiaľ budeme uvažovať o príkladoch na najzákladnejšom type neurónových sietí – ide o doprednú sieť (ďalej len FNS). Aj v nasledujúcich článkoch predstavím viac pojmov a poviem vám o rekurentných neurónových sieťach. DSS, ako už názov napovedá, je sieť so sériovým spojením neurónových vrstiev, v ktorej informácie idú vždy len jedným smerom.Na čo slúžia neurónové siete?
Neurónové siete sa používajú na riešenie zložitých problémov, ktoré si vyžadujú analytické výpočty podobné tým, ktoré má ľudský mozog. Najbežnejšie použitie pre neurónové siete je:Klasifikácia- rozdelenie údajov podľa parametrov. Napríklad pri vchode sa dáva množina ľudí a je potrebné rozhodnúť, komu z nich požičať a komu nie. Túto prácu môže vykonávať neurónová sieť analyzujúca informácie, ako je vek, solventnosť, úverová história atď.
Predpoveď- schopnosť predvídať ďalší krok. Napríklad vzostup alebo pád akcie na základe situácie na akciovom trhu.
Uznanie- v súčasnosti najrozšírenejšie využitie neurónových sietí. Používa sa na Googli, keď hľadáte fotku, alebo vo fotoaparátoch telefónov, keď rozpozná polohu vašej tváre a nechá ju vyniknúť a oveľa viac.
Aby sme teraz pochopili, ako neurónové siete fungujú, pozrime sa na ich komponenty a ich parametre.
Čo je to neurón?

Neurón je výpočtová jednotka, ktorá prijíma informácie, vykonáva na nich jednoduché výpočty a prenáša ich ďalej. Sú rozdelené do troch hlavných typov: vstup (modrý), skrytý (červený) a výstup (zelený). Existuje aj bias neurón a kontextový neurón, o ktorých si povieme v ďalšom článku. V prípade, že neurónová sieť pozostáva z veľkého počtu neurónov, zavádza sa pojem vrstva. Podľa toho existuje vstupná vrstva, ktorá prijíma informácie, n skrytých vrstiev (zvyčajne nie viac ako 3), ktoré ich spracúvajú, a výstupná vrstva, ktorá vydáva výsledok. Každý z neurónov má 2 hlavné parametre: vstupné dáta a výstupné dáta. V prípade vstupného neurónu: vstup = výstup. Vo zvyšku sa celková informácia všetkých neurónov z predchádzajúcej vrstvy dostane do vstupného poľa, potom sa normalizuje pomocou aktivačnej funkcie (zatiaľ ju len znázorni f (x)) a dostane sa do výstupného poľa.

Dôležité mať na pamätiže neuróny operujú s číslami v rozsahu alebo [-1,1]. Ale pýtate sa, čo potom zvládnuť čísla, ktoré idú mimo tento rozsah? V tejto fáze je najjednoduchšou odpoveďou vydeliť 1 týmto číslom. Tento proces sa nazýva normalizácia a veľmi často sa používa v neurónových sieťach. Viac o tom neskôr.
Čo je synapsia?

Synapsia je spojenie medzi dvoma neurónmi. Synapsie majú 1 parameter – hmotnosť. Vďaka nemu sa vstupné informácie menia pri prenose z jedného neurónu na druhý. Povedzme, že existujú 3 neuróny, ktoré prenášajú informácie na ďalší. Potom máme 3 váhy zodpovedajúce každému z týchto neurónov. Pre neurón s väčšou váhou bude táto informácia dominantná v nasledujúcom neuróne (napríklad miešanie farieb). V skutočnosti je súbor váh neurónovej siete alebo matica váh akýmsi mozgom celého systému. Práve vďaka týmto váham sú vstupné informácie spracované a prevedené na výsledok.
Dôležité mať na pamätiže pri inicializácii neurónovej siete sa váhy prideľujú náhodne.
Ako funguje neurónová sieť?

V tomto príklade je znázornená časť neurónovej siete, kde písmená I označujú vstupné neuróny, písmeno H označuje skrytý neurón a písmeno w označuje váhy. Zo vzorca je vidieť, že vstupná informácia je súčet všetkých vstupných údajov vynásobený príslušnými váhami. Potom dáme vstup 1 a 0. Nech w1 = 0,4 a w2 = 0,7 Vstupné údaje neurónu H1 budú nasledovné: 1 * 0,4 + 0 * 0,7 = 0,4. Teraz, keď máme vstup, môžeme získať výstup zapojením vstupu do aktivačnej funkcie (viac o tom neskôr). Teraz, keď máme výstup, podáme ho ďalej. A tak opakujeme pre všetky vrstvy, kým sa nedostaneme k výstupnému neurónu. Pri prvom spustení takejto siete uvidíme, že odpoveď nie je ani zďaleka správna, pretože sieť nie je natrénovaná. Budeme ju trénovať, aby sa jej výsledky zlepšili. Predtým, ako sa však naučíme, ako na to, predstavme si niekoľko pojmov a vlastností neurónovej siete.
Aktivačná funkcia
Aktivačná funkcia je spôsob normalizácie vstupných údajov (hovorili sme o tom skôr). To znamená, že ak máte na vstupe veľké číslo, po jeho prechode cez aktivačnú funkciu získate výstup v rozsahu, ktorý potrebujete. Aktivačných funkcií je veľa, preto zvážime tie najzákladnejšie: Lineárne, Sigmoidné (Logistické) a Hyperbolické tangenty. Ich hlavným rozdielom je rozsah hodnôt.Lineárna funkcia
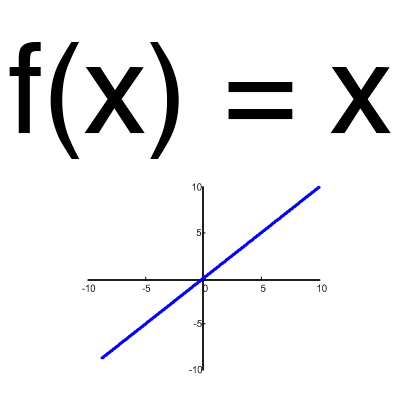
Táto funkcia sa takmer nepoužíva, okrem prípadov, keď potrebujete otestovať neurónovú sieť alebo preniesť hodnotu bez transformácií.
Sigmoid

Toto je najbežnejšia aktivačná funkcia a jej rozsah hodnôt. Práve na ňom je zobrazená väčšina príkladov na webe, niekedy sa mu hovorí aj logistická funkcia. Ak teda vo vašom prípade existujú záporné hodnoty (napríklad akcie môžu ísť nielen hore, ale aj dole), budete potrebovať funkciu, ktorá zachytáva aj záporné hodnoty.
Hyperbolická dotyčnica

Hyperbolický tangens má zmysel používať iba vtedy, keď vaše hodnoty môžu byť záporné aj kladné, pretože rozsah funkcie je [-1,1]. Túto funkciu je nevhodné používať len s kladnými hodnotami, nakoľko výrazne zhorší výsledky vašej neurónovej siete.
Tréningová súprava
Tréningová množina je sekvencia údajov, na ktorých pracuje neurónová sieť. V našom prípade exkluzívny alebo (xor) máme len 4 rôzne výsledky, to znamená, že budeme mať 4 tréningové sady: 0xor0 = 0, 0xor1 = 1, 1xor0 = 1,1xor1 = 0.Iterácia
Ide o akési počítadlo, ktoré sa zvyšuje zakaždým, keď neurónová sieť prejde jednou tréningovou sadou. Inými slovami, toto je celkový počet tréningových sád, ktoré prejde neurónová sieť.Epocha
Pri inicializácii neurónovej siete je táto hodnota nastavená na 0 a má manuálne nastavený strop. Čím väčšia je epocha, tým lepšie je natrénovaná sieť a podľa toho aj jej výsledok. Epocha sa zvyšuje zakaždým, keď prejdeme celým súborom tréningových sérií, v našom prípade 4 sérií alebo 4 iterácií.
Dôležité nezamieňajte si iteráciu s epochou a pochopte postupnosť ich prírastku. Prvý n
raz sa zvýši iterácia a potom epocha a nie naopak. Inými slovami, neurónovú sieť nemôžete najskôr trénovať iba na jednej zostave, potom na druhej atď. Každú sadu musíte trénovať raz za éru. Týmto spôsobom sa môžete vyhnúť chybám vo výpočtoch.
Chyba
Chyba je percento, ktoré predstavuje nesúlad medzi očakávanými a prijatými odpoveďami. Chyba sa tvorí v každej epoche a mala by klesať. Ak sa tak nestane, robíte niečo zle. Chybu je možné vypočítať rôznymi spôsobmi, ale budeme uvažovať iba o troch hlavných spôsoboch: Stredná štvorcová chyba (ďalej len MSE), Root MSE a Arctan. Neexistuje žiadne obmedzenie používania ako pri aktivačnej funkcii a vy si môžete slobodne vybrať spôsob, ktorý vám poskytne najlepšie výsledky. Stačí vziať do úvahy, že každá metóda počíta chyby rôznymi spôsobmi. V Arctane bude chyba takmer vždy väčšia, pretože funguje podľa princípu: čím väčší rozdiel, tým väčšia chyba. Root MSE bude mať najmenšiu chybu, preto sa najčastejšie používa MSE, ktorý udržuje rovnováhu vo výpočte chyby. Algoritmy, strojové učenie
Vitajte v druhej časti návodu na neurónové siete. Chcem sa ospravedlniť všetkým, ktorí čakali na druhý diel oveľa skôr. Z nejakého dôvodu som jej písanie musel odložiť. Fakt som nečakal, že prvý článok bude mať taký dopyt a že sa o túto tému bude zaujímať toľko ľudí. S prihliadnutím na vaše pripomienky sa budem snažiť poskytnúť vám čo najviac informácií a zároveň zachovať spôsob ich podania čo najzrozumiteľnejší. V tomto článku budem hovoriť o spôsoboch, ako trénovať / trénovať neurónové siete (najmä metóda backpropagation) a ak ste z nejakého dôvodu nečítali prvú časť, dôrazne odporúčam začať s ňou. V procese písania tohto článku som chcel hovoriť aj o iných typoch neurónových sietí a tréningových metódach, no keď som o nich začal písať, uvedomil som si, že by to bolo v rozpore s mojou prezentačnou metódou. Chápem, že túžite získať čo najviac informácií, ale tieto témy sú veľmi rozsiahle a vyžadujú si podrobnú analýzu a mojou hlavnou úlohou nie je napísať ďalší článok s povrchným vysvetlením, ale sprostredkovať vám každý aspekt témy zdvihol a čo najviac zjednodušil článok.vývoj. Ponáhľam sa rozrušiť tých, ktorí radi „kódujú“, pretože sa stále neuchýlim k používaniu programovacieho jazyka a všetko vysvetlím na prstoch. Dosť bolo úvodu, poďme teraz pokračovať v štúdiu neurónových sietí.
Čo je vytesňovací neurón?

Pred začatím našej hlavnej témy si musíme predstaviť koncept iného typu neurónu – vytesňovacieho neurónu. Zaujatý neurón alebo zaujatý neurón je tretí typ neurónu používaný vo väčšine neurónových sietí. Zvláštnosťou tohto typu neurónov je, že jeho vstup a výstup sú vždy rovné 1 a nikdy nemajú vstupné synapsie. Vytesňovacie neuróny môžu byť buď prítomné v neurónovej sieti jeden po druhom na vrstve, alebo môžu úplne chýbať, 50/50 nemôže byť (váhy a neuróny, ktoré nemožno umiestniť, sú na diagrame znázornené červenou farbou). Spojenia pre vytesňovacie neuróny sú rovnaké ako pre bežné neuróny – so všetkými neurónmi ďalšej úrovne, okrem toho, že medzi dvoma zaujatými neurónmi nemôžu existovať žiadne synapsie. Preto môžu byť umiestnené na vstupnej vrstve a všetkých skrytých vrstvách, ale nie na výstupnej vrstve, pretože jednoducho nemajú s čím vytvoriť spojenie.
Na čo je zaujatý neurón?

Vytesňovací neurón je potrebný na to, aby bolo možné získať výstupný výsledok posunutím grafu aktivačnej funkcie doprava alebo doľava. Ak to znie mätúco, pozrime sa na jednoduchý príklad, kde je jeden vstupný neurón a jeden výstupný neurón. Potom je možné stanoviť, že výstup O2 sa bude rovnať vstupu H1 vynásobenému jeho hmotnosťou a prejde cez aktivačnú funkciu (vzorec na fotografii vľavo). V našom konkrétnom prípade použijeme sigmatu.
Zo školského kurzu matematiky vieme, že ak vezmeme funkciu y = ax + b a zmeníme jej hodnoty „a“, zmení sa sklon funkcie (farby čiar na grafe vľavo) a ak zmeníme "b", tak funkciu posunieme doprava alebo doľava (farby čiar na grafe vpravo). Takže „a“ je váha H1 a „b“ je váha zaujatého neurónu B1. Toto je hrubý príklad, ale takto to funguje (ak sa pozriete na aktivačnú funkciu vpravo na obrázku, všimnete si veľmi silnú podobnosť medzi vzorcami). To znamená, že keď počas tréningu upravujeme váhy skrytých a výstupných neurónov, meníme sklon aktivačnej funkcie. Úprava váhy zaujatých neurónov nám však môže poskytnúť príležitosť posunúť aktivačnú funkciu pozdĺž osi X a zachytiť nové oblasti. Inými slovami, ak sa nachádza bod zodpovedný za vaše riešenie, ako je znázornené na grafe vľavo, potom vaša neurónová sieť nikdy nebude schopná vyriešiť problém bez použitia zaujatých neurónov. Preto len zriedka nájdete neurónové siete bez zaujatých neurónov.
Skreslené neuróny pomáhajú aj v prípade, keď všetky vstupné neuróny dostanú ako vstup 0 a bez ohľadu na to, akú majú váhu, prenesú všetko do ďalšej vrstvy 0, ale nie v prípade prítomnosti zaujatého neurónu. Prítomnosť alebo neprítomnosť zaujatých neurónov je hyperparameter (viac o tom neskôr). Stručne povedané, musíte sa sami rozhodnúť, či potrebujete použiť zaujaté neuróny alebo nie, spustením neurónovej siete s a bez miešania neurónov a porovnávaním výsledkov.
DÔLEŽITÉ uvedomte si, že niekedy na diagramoch neoznačujú skreslené neuróny, ale jednoducho berú do úvahy ich váhy pri výpočte vstupnej hodnoty, napríklad:
Vstup = H1 * w1 + H2 * w2 + b3
b3 = odchýlka * w3
Keďže jeho výstup je vždy 1, môžeme si jednoducho predstaviť, že máme ďalšiu synapsiu s váhou a túto váhu pripočítame k súčtu bez toho, aby sme spomenuli samotný neurón.
Ako prinútiť Národné zhromaždenie dávať správne odpovede?
Odpoveď je jednoduchá – musíte ju trénovať. Akokoľvek jednoduchá je odpoveď, jej implementácia z hľadiska jednoduchosti ponecháva veľa požiadaviek. Existuje niekoľko metód výučby neurónových sietí a ja vyberiem 3, podľa môjho názoru, najzaujímavejšie:- Metóda spätného šírenia
- Odolné šírenie (Rprop)
- Genetický algoritmus
Čo je to gradientný zostup?
Toto je spôsob, ako nájsť lokálne minimum alebo maximum funkcie pohybom pozdĺž gradientu. Keď pochopíte podstatu gradientného zostupu, nemali by ste mať žiadne otázky pri používaní metódy backpropagation. Po prvé, poďme zistiť, čo je gradient a kde sa nachádza v našej neurónovej sieti. Zostavme si graf, kde na osi x budú hodnoty hmotnosti neurónu (w) a na osi y bude chyba zodpovedajúca tejto váhe (e).
Pri pohľade na tento graf pochopíme, že graf funkcie f (w) je závislosť chyby od zvolenej hmotnosti. Na tomto grafe nás zaujíma globálne minimum - bod (w2, e2) alebo inak povedané miesto, kde sa graf najviac približuje k osi x. Tento bod bude znamenať, že výberom hmotnosti w2 dostaneme najmenšiu chybu - e2 a v dôsledku toho najlepší možný výsledok. Tento bod nám pomôže nájsť metóda gradientového zostupu (spád je na grafe znázornený žltou farbou). Podľa toho bude mať každá váha v neurónovej sieti svoj vlastný graf a gradient a každá musí nájsť globálne minimum.
Aký je teda tento gradient? Gradient je vektor, ktorý definuje strmosť svahu a označuje jeho smer vzhľadom na ktorýkoľvek z bodov na povrchu alebo grafe. Ak chcete nájsť gradient, musíte zobrať deriváciu grafu v danom bode (ako je znázornené na grafe). Pohybom v smere tohto spádu plynule skĺzneme do nížiny. Teraz si predstavte, že chyba je lyžiar a funkčný graf je hora. Ak je teda chyba 100 %, potom je lyžiar na samom vrchole hory a ak je chyba 0 %, potom v nížine. Ako všetci lyžiari, aj ploštica má tendenciu čo najrýchlejšie klesať a znižovať svoju hodnotu. Nakoniec by sme mali dostať nasledujúci výsledok:

Predstavte si, že lyžiara vyhodí helikoptéra do hory. Ako vysoká alebo nízka závisí od prípadu (podobne ako v neurónovej sieti sa počas inicializácie náhodne priraďujú váhy). Povedzme, že chyba je 90% a toto je náš východiskový bod. Teraz musí lyžiar ísť dole pomocou stúpania. Cestou dole si v každom bode vypočítame gradient, ktorý nám ukáže smer klesania a pri zmene sklonu ho upravíme. Ak je svah rovný, tak po n-tom počte takýchto akcií sa dostaneme do nížiny. No vo väčšine prípadov bude svah (graf funkcií) zvlnený a náš lyžiar bude čeliť veľmi vážnemu problému - lokálnemu minimu. Myslím, že každý vie, čo je lokálne a globálne minimum funkcie, tu je príklad na osvieženie pamäte. Dostať sa do miestneho minima je spojené so skutočnosťou, že náš lyžiar zostane navždy v tejto nížine a nikdy sa nešmýka z hory, a preto nikdy nebudeme môcť dostať správnu odpoveď. Tomu sa však môžeme vyhnúť tak, že nášho lyžiara vybavíme jetpackom s názvom momentum. Tu je rýchla ukážka tohto momentu:

Ako ste už určite uhádli, tento batoh poskytne lyžiarovi potrebné zrýchlenie na zdolanie kopca, ktorý nás drží na miestnom minime, no má to jedno ALE. Predstavme si, že nastavíme určitú hodnotu parametra momentu a môžeme ľahko prekonať všetky lokálne minimá a dostať sa na globálne minimum. Keďže nemôžeme jednoducho vypnúť jetpack, môžeme prekĺznuť za globálne minimum, ak sú vedľa neho ešte nížiny. V konečnom prípade to nie je až také dôležité, keďže skôr či neskôr sa predsa len vrátime ku globálnemu minimu, no treba si uvedomiť, že čím väčší moment, tým väčší švih, s ktorým bude lyžiar jazdiť po nížinách. Spolu s momentom metóda spätného šírenia využíva aj taký parameter, akým je rýchlosť učenia. Ako si asi mnohí budú myslieť, čím vyššia rýchlosť učenia, tým rýchlejšie budeme trénovať neurónovú sieť. nie Rýchlosť učenia, rovnako ako moment, je hyperparameter - hodnota, ktorá sa vyberá pomocou pokusov a omylov. Rýchlosť učenia môže priamo súvisieť s rýchlosťou lyžiara a pokojne sa dá povedať, že ďalej pôjdete tichšie. Sú tu však aj určité aspekty, keďže ak lyžiarovi nedáme rýchlosť vôbec, tak nepôjde vôbec nikam a ak dáme nízku rýchlosť, tak sa čas jazdy môže natiahnuť na veľmi, veľmi dlho. doba. Čo sa potom stane, ak dáme príliš veľkú rýchlosť?

Ako vidíte, nič dobré. Lyžiar sa začne šmýkať po nesprávnej ceste a možno aj opačným smerom, čo nás, ako ste pochopili, len vzďaľuje od nájdenia správnej odpovede. Preto je potrebné vo všetkých týchto parametroch nájsť zlatú strednú cestu, aby sa predišlo nekonvergencii NN (viac o tom neskôr).
Čo je metóda spätného šírenia (MPA)?
Takže sme sa dostali do bodu, kedy môžeme diskutovať o tom, ako zabezpečiť, aby sa vaša neurónová sieť vedela správne učiť a prijímať správne rozhodnutia. MOP je na tomto GIF vykreslený veľmi dobre:
Teraz sa pozrime bližšie na každú fázu. Ak si pamätáte, že v predchádzajúcom článku sme sa zaoberali výstupom Národného zhromaždenia. Iným spôsobom sa to nazýva dopredný priechod, to znamená, že postupne prenášame informácie zo vstupných neurónov na výstupné neuróny. Potom vypočítame chybu a na základe nej urobíme postback, ktorý spočíva v postupnej zmene váh neurónovej siete, počnúc váhami výstupného neurónu. Váhy sa budú meniť v smere, ktorý nám dáva najlepší výsledok. Vo svojich výpočtoch použijem metódu nájdenia delty, pretože je to najjednoduchší a najzrozumiteľnejší spôsob. Stochastickú metódu použijem aj na aktualizáciu váh (o tom neskôr).
Teraz pokračujme tam, kde sme skončili s výpočtami v predchádzajúcom článku.
Tieto úlohy z predchádzajúceho článku

Údaje: I1 = 1, I2 = 0, w1 = 0,45, w2 = 0,78, w3 = -0,12, w4 = 0,13, w5 = 1,5, w6 = -2,3.
Vstup H1 = 1 * 0,45 + 0 * -0,12 = 0,45
Výstup H1 = sigmoid (0,45) = 0,61
Vstup H2 = 1 * 0,78 + 0 * 0,13 = 0,78
Výstup H2 = sigmoid (0,78) = 0,69
O1vstup = 0,61 * 1,5 + 0,69 * -2,3 = -0,672
Výstup O1 = sigmoid (-0,672) = 0,33
O1ideal = 1 (0xor1 = 1)
Chyba = ((1-0,33) ^ 2) /1 = 0,45
Výsledok je 0,33, chyba je 45 %.
Keďže sme už vypočítali výsledok NN a jeho chybu, môžeme hneď pristúpiť k MPA. Ako som už spomenul, algoritmus vždy začína výstupným neurónom. V takom prípade vypočítame jej hodnotu? (delta) podľa vzorca 1.
 Keďže výstupný neurón nemá odchádzajúce synapsie, použijeme prvý vzorec (? Výstup), preto pre skryté neuróny už vezmeme druhý vzorec (? Hidden). Všetko je tu celkom jednoduché: vypočítame rozdiel medzi požadovaným a získaným výsledkom a vynásobíme deriváciou aktivačnej funkcie zo vstupnej hodnoty daného neurónu. Pred začatím výpočtov vás chcem upozorniť na deriváciu. Po prvé, ako už bolo pravdepodobne jasné, s MOPmi by sa mali používať iba tie aktivačné funkcie, ktoré možno rozlíšiť. Po druhé, aby sa nerobili zbytočné výpočty, odvodený vzorec možno nahradiť priateľskejším a jednoduchším vzorcom formulára:
Keďže výstupný neurón nemá odchádzajúce synapsie, použijeme prvý vzorec (? Výstup), preto pre skryté neuróny už vezmeme druhý vzorec (? Hidden). Všetko je tu celkom jednoduché: vypočítame rozdiel medzi požadovaným a získaným výsledkom a vynásobíme deriváciou aktivačnej funkcie zo vstupnej hodnoty daného neurónu. Pred začatím výpočtov vás chcem upozorniť na deriváciu. Po prvé, ako už bolo pravdepodobne jasné, s MOPmi by sa mali používať iba tie aktivačné funkcie, ktoré možno rozlíšiť. Po druhé, aby sa nerobili zbytočné výpočty, odvodený vzorec možno nahradiť priateľskejším a jednoduchším vzorcom formulára: 
Naše výpočty pre bod O1 teda budú vyzerať takto.
Riešenie
Výstup O1 = 0,33
O1 ideálne = 1
Chyba = 0,45
O1 = (1 - 0,33) * ((1 - 0,33) * 0,33) = 0,148
Tým sú výpočty pre neurón O1 ukončené. Pamätajte, že po výpočte delty neurónu musíme okamžite aktualizovať váhy všetkých odchádzajúcich synapsií tohto neurónu. Keďže v prípade O1 chýbajú, prejdeme na neuróny na latentnej úrovni a urobíme to isté, až na to, že teraz máme druhý vzorec na výpočet delty a jeho podstatou je vynásobiť deriváciu aktivačnej funkcie zo vstupu. hodnotu súčtom súčinov všetkých odchádzajúcich váh a delta neurónu, s ktorým je táto synapsia spojená. Prečo sú však vzorce odlišné? Ide o to, že celý zmysel MOR je v propagácii chyby výstupných neurónov na všetky váhy neurónovej siete. Chybu je možné vypočítať iba na výstupnej úrovni, ako sme to už urobili, vypočítali sme aj deltu, v ktorej už táto chyba existuje. Preto teraz namiesto chyby použijeme deltu, ktorá sa bude prenášať z neurónu na neurón. V takom prípade nájdime deltu pre H1:
Riešenie
H1 výstup = 0,61
w5 = 1,5
a01 = 0,148
H1 = ((1 - 0,61) * 0,61) * (1,5 * 0,148) = 0,053
Teraz musíme nájsť gradient pre každú odchádzajúce synapsiu. Tu zvyčajne vložia 3-poschodový zlomok s kopou derivátov a iné matematické peklo, ale práve v tom je krása použitia metódy delta počítania, pretože v konečnom dôsledku bude váš vzorec na nájdenie gradientu vyzerať takto:
Tu je bod A bod na začiatku synapsie a bod B je na konci synapsie. Gradient w5 teda môžeme vypočítať takto:
Riešenie
H1 výstup = 0,61
a01 = 0,148
GRADw5 = 0,61 * 0,148 = 0,09
Teraz máme všetky potrebné údaje na aktualizáciu hmotnosti w5 a urobíme to vďaka funkcii MOP, ktorá vypočíta množstvo, o ktoré je potrebné tú či onú váhu zmeniť, a vyzerá to takto:
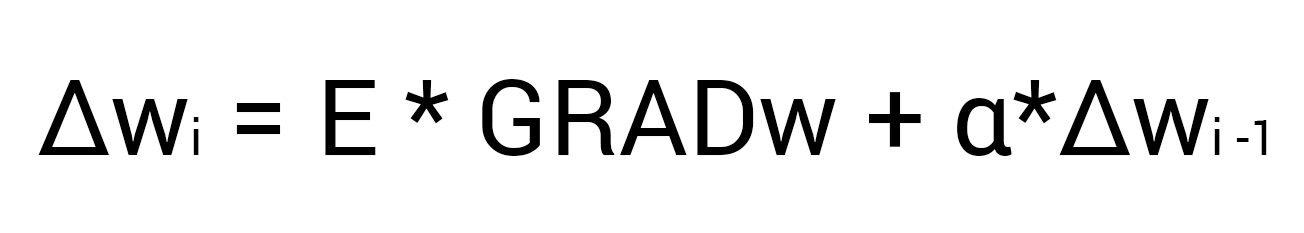
Dôrazne vám odporúčam, aby ste neignorovali druhú časť výrazu a použili moment, pretože vám to umožní vyhnúť sa problémom s lokálnym minimom.
Tu vidíme 2 konštanty, o ktorých sme už hovorili, keď sme uvažovali o algoritme zostupu gradientu: E (epsilon) - rýchlosť učenia,? (alfa) - moment. Preložením vzorca do slov dostaneme: zmena váhy synapsie sa rovná koeficientu rýchlosti učenia vynásobenému gradientom tejto váhy, pripočítame moment vynásobený predchádzajúcou zmenou tejto váhy (pri 1. iterácii sa rovná 0). V tomto prípade vypočítajme zmenu hmotnosti w5 a aktualizujeme jej hodnotu pridaním?W5 k nej.
Riešenie
E = 0,7
? = 0.3
w5 = 1,5
GRADw5 = 0,09
A w5 (i-1) = 0
W5 = 0,7 * 0,09 + 0 * 0,3 = 0,063
w5 = w5 + w5 = 1,563
Po aplikovaní algoritmu sa teda naša váha zvýšila o 0,063. Teraz navrhujem, aby ste urobili to isté pre H2.
Riešenie
Výstup H2 = 0,69
w6 = -2,3
a01 = 0,148
E = 0,7
? = 0.3
A w6 (i-1) = 0
H2 = ((1 - 0,69) * 0,69) * (-2,3 * 0,148) = -0,07
GRADw6 = 0,69 * 0,148 = 0,1
W6 = 0,7 * 0,1 + 0 * 0,3 = 0,07
W6 = w6 + W6 = -2,2
A samozrejme, nezabudnite na I1 a I2, pretože majú tiež synapsie hmotnosti, ktoré tiež musíme aktualizovať. Pamätajte však, že nepotrebujeme nájsť delty pre vstupné neuróny, pretože nemajú vstupné synapsie.
Riešenie
w1 = 0,45, w1 (i-1) = 0
w2 = 0,78, w2 (i-1) = 0
w3 = -0,12, w3 (i-1) = 0
w4 = 0,13, w4 (i-1) = 0
5 H1 = 0,053
5 H2 = -0,07
E = 0,7
? = 0.3
GRADw1 = 1 * 0,053 = 0,053
GRADw2 = 1 * -0,07 = -0,07
GRADw3 = 0 * 0,053 = 0
GRADw4 = 0 * -0,07 = 0
W1 = 0,7 * 0,053 + 0 * 0,3 = 0,04
w2 = 0,7 * -0,07 + 0 * 0,3 = -0,05
► w3 = 0,7 * 0 + 0 * 0,3 = 0
A w4 = 0,7 * 0 + 0 * 0,3 = 0
W1 = w1 + < W1 = 0,5
w2 = w2 + < w2 = 0,73
w3 = w3 + < w3 = -0,12
w4 = w4 + < w4 = 0,13
Teraz sa presvedčíme, že sme všetko urobili správne a opäť vypočítajme výstup neurónovej siete len s aktualizovanými váhami.
Riešenie
I1 = 1
I2 = 0
w1 = 0,5
w2 = 0,73
w3 = -0,12
w4 = 0,13
w5 = 1,563
w6 = -2,2
Vstup H1 = 1 * 0,5 + 0 * -0,12 = 0,5
Výstup H1 = sigmoid (0,5) = 0,62
Vstup H2 = 1 * 0,73 + 0 * 0,124 = 0,73
Výstup H2 = sigmoid (0,73) = 0,675
O1vstup = 0,62 * 1,563 + 0,675 * -2,2 = -0,51
Výstup O1 = sigmoid (-0,51) = 0,37
O1ideal = 1 (0xor1 = 1)
Chyba = ((1-0,37) ^ 2) /1 = 0,39
Výsledok je 0,37, chyba je 39 %.
Ako môžeme vidieť po jednej iterácii MPA, podarilo sa nám znížiť chybu o 0,04 (6 %). Teraz to musíte opakovať znova a znova, kým vaša chyba nebude dostatočne malá.
Čo ešte potrebujete vedieť o procese učenia?
Neurónová sieť sa môže učiť s učiteľom alebo bez neho (učenie pod dohľadom, bez dozoru).Učenie pod dohľadom- Toto je typ tréningu, ktorý je súčasťou problémov, ako je regresia a klasifikácia (použili sme ho v príklade vyššie). Inými slovami, tu vystupujete ako učiteľ a NS ako študent. Poskytnete vstupné údaje a požadovaný výsledok, to znamená, že študent pri pohľade na vstupné údaje pochopí, že sa musí snažiť o výsledok, ktorý ste mu poskytli.
Učenie bez učiteľa- tento typ tréningu nie je taký bežný. Nie je tu žiadny učiteľ, takže sieť nedosahuje požadovaný výsledok alebo je ich počet veľmi malý. V zásade je tento typ tréningu vlastný neurónovým sieťam, ktorých úlohou je zoskupovať údaje podľa určitých parametrov. Povedzme, že odošlete Habrému 10 000 článkov a po analýze všetkých týchto článkov ich bude môcť Národné zhromaždenie kategorizovať napríklad podľa často sa vyskytujúcich slov. Články, v ktorých sa spomínajú programovacie jazyky, programovanie a kde sú slová ako Photoshop, dizajn.
Existuje aj taká zaujímavá metóda ako posilňovacie učenie(posilňovacie učenie). Táto metóda by si zaslúžila samostatný článok, no pokúsim sa stručne popísať jej podstatu. Táto metóda je použiteľná, keď ju môžeme na základe výsledkov získaných od Národného zhromaždenia posúdiť. Chceme napríklad naučiť Národné zhromaždenie hrať PAC-MAN, potom vždy, keď Národné zhromaždenie získa veľa bodov, budeme ho povzbudzovať. Inými slovami, dávame NS právo nájsť akýkoľvek spôsob dosiahnutia cieľa, pokiaľ to prinesie dobrý výsledok. Sieť tak začne chápať, čo ňou chce dosiahnuť a pokúsi sa nájsť najlepší spôsob, ako tento cieľ dosiahnuť bez neustáleho poskytovania údajov zo strany „učiteľa“.
Školenie možno vykonávať aj pomocou troch metód: stochastická metóda, dávková metóda a minidávková metóda. Existuje toľko článkov a štúdií o tom, ktorá metóda je najlepšia, a nikto nemôže prísť so všeobecnou odpoveďou. Som zástancom stochastickej metódy, ale nepopieram, že každá metóda má svoje pre a proti.
Stručne o každej metóde:
Stochastické(niekedy sa tomu hovorí aj online) metóda funguje podľa nasledujúceho princípu - nájdené? w, okamžite aktualizujte zodpovedajúcu hmotnosť.
Dávková metóda funguje to inak. Zosumarizujeme?W všetkých váh v aktuálnej iterácii a až potom aktualizujeme všetky váhy pomocou tohto súčtu. Jednou z najdôležitejších výhod tohto prístupu je výrazná úspora výpočtového času, pričom presnosť môže byť v tomto prípade vážne ovplyvnená.
Mini dávková metóda je zlatou strednou cestou a snaží sa spojiť výhody oboch metód. Princíp je nasledovný: váhy voľne rozdeľujeme medzi skupiny a meníme ich váhy o súčet?W všetkých váh v tej či onej skupine.
Čo sú hyperparametre?
Hyperparametre sú hodnoty, ktoré je potrebné vyberať ručne a často pokusom a omylom. Medzi tieto hodnoty patria:- Okamih a rýchlosť učenia
- Počet skrytých vrstiev
- Počet neurónov v každej vrstve
- Prítomnosť alebo neprítomnosť posunovacích neurónov
Čo je to konvergencia?

Konvergencia indikuje, či je architektúra neurónovej siete správna a či boli hyperparametre zvolené správne v súlade s úlohou. Povedzme, že náš program vypíše chybu NS pri každej iterácii protokolu. Ak sa chyba s každou iteráciou znižuje, potom sme na správnej ceste a naša neurónová sieť sa zbližuje. Ak chyba skáče hore a dole alebo zamrzne na určitej úrovni, potom NN nekonverguje. V 99% prípadov sa to rieši zmenou hyperparametrov. Zvyšné 1% bude znamenať, že máte chybu v architektúre neurónovej siete. Stáva sa tiež, že konvergenciu ovplyvňuje preškolenie neurónovej siete.
Čo je to rekvalifikácia?
Overfitting, ako už názov napovedá, je stav neurónovej siete, keď je presýtená dátami. Tento problém nastáva, ak trénovanie siete na rovnakých údajoch trvá príliš dlho. Inými slovami, sieť sa z údajov nezačne učiť, ale zapamätať si ich a „napchať“. Preto, keď už odošlete nové údaje na vstup tejto neurónovej siete, v prijatých údajoch sa môže objaviť šum, ktorý ovplyvní presnosť výsledku. Napríklad, ak ukážeme NA rôzne fotografie jabĺk (iba červené) a povieme, že toto je jablko. Potom, keď NS uvidí žlté alebo zelené jablko, nebude môcť určiť, že ide o jablko, pretože si zapamätala, že všetky jablká musia byť červené. Naopak, keď NS uvidí niečo červené a tvar jablka, napríklad broskyne, povie, že je to jablko. Toto je hluk. Na grafe bude šum vyzerať takto.
Je vidieť, že graf funkcie značne kolíše z bodu do bodu, ktoré sú výstupom (výsledkom) našej neurónovej siete. V ideálnom prípade by mal byť tento graf menej zvlnený a menej rovný. Aby ste sa vyhli preťaženiu, nemali by ste NN trénovať dlhodobo na rovnakých alebo veľmi podobných dátach. Príčinou nadmerného vybavenia môže byť aj veľké množstvo parametrov, ktoré dodávate na vstup neurónovej siete alebo príliš zložitá architektúra. Ak teda po tréningovej fáze zaznamenáte chyby (šum) vo výstupe, mali by ste použiť jednu z metód regularizácie, ale vo väčšine prípadov to nebude potrebné.
Záver
Dúfam, že tento článok dokázal objasniť kľúčové body takej náročnej témy, akou sú neurónové siete. Verím však, že bez ohľadu na to, koľko článkov prečítate, zvládnuť tak zložitú tému je nemožné bez praxe. Preto, ak ste len na začiatku cesty a chcete študovať toto sľubné a rozvíjajúce sa odvetvie, potom vám odporúčam začať cvičiť napísaním vlastnej neurónovej siete a až potom sa uchýliť k používaniu rôznych rámcov a knižníc. Taktiež, ak vás zaujal môj spôsob prezentácie informácií a chcete, aby som písal články na iné témy týkajúce sa Machine Learning, potom zahlasujte v ankete nižšie za tému, ktorá vás zaujíma. Uvidíme sa v ďalších článkoch :)Neurálne siete
Schéma jednoduchej neurónovej siete. Zeleno označené vstup prvky v žltej farbe - deň voľna element
Umelé neurónové siete(ANN) - matematické modely, ako aj ich softvérové alebo hardvérové implementácie, postavené na princípe organizácie a fungovania biologických neurónových sietí - sietí nervových buniek živého organizmu. Tento koncept vznikol pri štúdiu procesov prebiehajúcich v mozgu počas myslenia a pri pokuse o modelovanie týchto procesov. Prvým takýmto modelom mozgu bol perceptrón. Následne sa tieto modely začali využívať na praktické účely, zvyčajne pri predpovedaní problémov.
Neurónové siete nie sú naprogramované v bežnom zmysle slova sú vyškolení... Učenie je jednou z hlavných výhod neurónových sietí oproti tradičným algoritmom. Technicky tréning spočíva v hľadaní koeficientov spojení medzi neurónmi. Počas tréningu je neurónová sieť schopná identifikovať zložité závislosti medzi vstupnými dátami a výstupmi, ako aj vykonávať zovšeobecňovanie. To znamená, že v prípade úspešného tréningu bude sieť schopná vrátiť správny výsledok na základe údajov, ktoré v tréningovej sade chýbali.
Chronológia
Známe aplikácie
Zhlukovanie
Klastrovanie sa chápe ako rozdelenie množiny vstupných signálov do tried, pričom nie je vopred známy ani počet, ani charakteristika tried. Po zaškolení je takáto sieť schopná určiť, do ktorej triedy vstupný signál patrí. Sieť môže signalizovať aj to, že vstupný signál nepatrí do žiadnej z vybraných tried – to je znakom nových údajov, ktoré v trénovacej vzorke absentujú. Teda podobná sieť dokáže identifikovať nové, predtým neznáme triedy signálov... Korešpondencia medzi triedami pridelenými sieťou a triedami existujúcimi v doméne je stanovená osobou. Klastrovanie je realizované napríklad Kohonenovymi neurónovými sieťami.
Experimentálny výber charakteristík siete
Po výbere všeobecnej štruktúry musíte experimentálne vybrať parametre siete. Pre siete ako perceptrón to bude počet vrstiev, počet blokov v skrytých vrstvách (pre siete Word), prítomnosť alebo absencia bypassových spojení, prenosové funkcie neurónov. Pri výbere počtu vrstiev a neurónov v nich by sa malo vychádzať zo skutočnosti schopnosť siete zovšeobecňovať je tým vyššia, čím väčší je celkový počet spojení medzi neurónmi... Na druhej strane je počet odkazov zhora ohraničený počtom záznamov v trénovacích údajoch.
Experimentálny výber tréningových parametrov
Po výbere konkrétnej topológie je potrebné zvoliť parametre pre trénovanie neurónovej siete. Táto fáza je obzvlášť dôležitá pre siete učenia pod dohľadom. Správna voľba parametrov závisí nielen od toho, ako rýchlo budú odpovede siete konvergovať k správnym odpovediam. Napríklad výber nízkej rýchlosti učenia predĺži čas konvergencie, no niekedy sa vyhne paralýze siete. Zvýšenie momentu učenia môže viesť k zvýšeniu aj zníženiu času konvergencie v závislosti od tvaru chybovej plochy. Na základe takéhoto rozporuplného vplyvu parametrov môžeme konštatovať, že ich hodnoty by sa mali vyberať experimentálne, pričom by sa mali riadiť kritériom dokončenia tréningu (napríklad minimalizácia chyby alebo obmedzenie času tréningu).
Skutočné školenie siete
Počas tréningu sieť skenuje tréningovú vzorku v určitom poradí. Poradie skenovania môže byť sekvenčné, náhodné atď. Niektoré siete bez dozoru, napríklad siete Hopfield, skenujú vzorku iba raz. Iné, ako napríklad siete Kohonen a siete pod dohľadom, skenujú vzorku viackrát, pričom jeden úplný prechod cez vzorku tzv. éra učenia... Pri výučbe s učiteľom je súbor počiatočných údajov rozdelený na dve časti - samotná tréningová vzorka a testovacie údaje; princíp oddelenia môže byť ľubovoľný. Tréningové dáta sa privádzajú do siete na trénovanie a validačné dáta sa používajú na výpočet chyby siete (validačné dáta sa nikdy nepoužívajú na trénovanie siete). Ak sa teda chyba na testovacích údajoch zníži, sieť sa zovšeobecní. Ak sa chyba v trénovacích údajoch naďalej znižuje a chyba v testovacích údajoch sa zvyšuje, potom sieť prestala zovšeobecňovať a jednoducho si „pamätá“ trénovacie údaje. Tento jav sa nazýva preťaženie siete alebo preťaženie siete. V takýchto prípadoch sa tréning zvyčajne zastaví. Počas procesu učenia sa môžu objaviť ďalšie problémy, ako napríklad paralýza alebo zasiahnutie siete na lokálne minimum chybového povrchu. Nie je možné vopred predvídať prejav konkrétneho problému, ako aj poskytnúť jednoznačné odporúčania na ich riešenie.
Kontrola primeranosti školenia
Aj v prípade na prvý pohľad úspešného učenia sa sieť nie vždy naučí presne to, čo od nej tvorca chcel. Je známy prípad, keď bola sieť trénovaná na rozpoznávanie obrázkov tankov z fotografií, no neskôr sa ukázalo, že všetky tanky boli odfotené na rovnakom pozadí. V dôsledku toho sa sieť „naučila“ rozpoznávať tento typ terénu, namiesto toho, aby sa „naučila“ rozpoznávať tanky. Sieť teda „chápe“ nie to, čo sa od nej vyžaduje, ale to, čo je najjednoduchšie zovšeobecniť.
Klasifikácia podľa typu vstupných informácií
- Analógové neurónové siete (používajú informácie vo forme reálnych čísel);
- Binárne neurónové siete (pracujú s informáciami prezentovanými v binárnej forme).
Klasifikácia podľa povahy učenia
- Riadené učenie – výstupný priestor riešení neurónových sietí je známy;
- Učenie bez dozoru – neurónová sieť tvorí výstupný priestor riešení len na základe vstupu. Takéto siete sa nazývajú samoorganizujúce sa;
- Reinforcement Learning je systém na prideľovanie pokút a odmien z okolia.
Klasifikácia podľa povahy ladenia synapsií
Klasifikácia doby prenosu signálu
V mnohých neurónových sieťach môže aktivačná funkcia závisieť nielen od váhových koeficientov spojení w ij, ale aj na čase prenosu impulzu (signálu) komunikačnými kanálmi τ ij... Preto vo všeobecnosti aktivačná (vysielacia) komunikačná funkcia c ij z prvku u i k prvku u j vyzerá ako:. Potom synchrónna sieť ij každá väzba sa rovná buď nule alebo pevnej konštante τ. Asynchrónne je sieť, pre ktorú je čas prenosu τ ij pre každé prepojenie medzi prvkami u i a u j svoj vlastný, ale aj stály.
Klasifikácia podľa povahy väzieb
Dopredné siete
Všetky spojenia sú nasmerované striktne od vstupných neurónov k výstupným neurónom. Príkladmi takýchto sietí sú Rosenblattov perceptrón, viacvrstvový perceptrón, siete Word.
Rekurentné neurónové siete
Signál z výstupných neurónov alebo neurónov skrytej vrstvy sa čiastočne prenáša späť na vstupy neurónov vstupnej vrstvy (spätná väzba). Rekurentná sieť Hopfieldova sieť „filtruje“ vstupné dáta, vracia sa do ustáleného stavu a tým umožňuje riešiť problémy s kompresiou dát a budovaním asociatívnej pamäte. Obojsmerné siete sú špeciálnym prípadom rekurentných sietí. V takýchto sieťach existujú spojenia medzi vrstvami tak v smere od vstupnej vrstvy k výstupnej vrstve, ako aj v opačnom smere. Klasickým príkladom je Koskova neurónová sieť.
Radiálne bázové funkcie
Umelé neurónové siete využívajúce siete na radiálnej báze ako aktivačné funkcie (takéto siete sa označujú skratkou RBF siete). Celkový pohľad na funkciu radiálnej bázy:
 , napríklad,
, napríklad, ![]()
kde X je vektor vstupných signálov neurónov, σ je šírka okna funkcie, φ ( r) je klesajúca funkcia (najčastejšie sa rovná nule mimo určitého segmentu).
Radiálna základná sieť sa vyznačuje tromi vlastnosťami:
1. Jediná skrytá vrstva
2. Len neuróny skrytej vrstvy majú nelineárnu aktivačnú funkciu
3. Synaptické váhy spojení vstupnej a skrytej vrstvy sú rovné jednej
O tréningovom postupe - pozri literatúru
Samoorganizujúce sa karty
Takéto siete predstavujú konkurenčnú neurónovú sieť s nekontrolovaným učením, ktorá vykonáva úlohu vizualizácie a klastrovania. Je to metóda premietania viacrozmerného priestoru do priestoru s nižšou dimenziou (najčastejšie dvojrozmerného), používa sa aj na riešenie problémov modelovania, predpovedania a pod. Je to jedna z verzií Kohonenovych neurónových sietí. Samoorganizujúce sa Kohonenove mapy sa primárne používajú na vizualizáciu a počiatočnú („prieskumnú“) analýzu údajov.
Signál do Kohonenovy siete ide do všetkých neurónov naraz, váhy zodpovedajúcich synapsií sú interpretované ako súradnice polohy uzla a výstupný signál je tvorený podľa princípu „víťaz berie všetko“ – teda neurón. najbližšie (v zmysle váh synapsií) k vstupnému signálu má nenulový objekt výstupného signálu. V procese trénovania sa váhy synapsií upravujú tak, že mriežkové uzly sú „umiestnené“ v miestach lokálnej kondenzácie dát, teda popisujú zhlukovú štruktúru dátového cloudu, na druhej strane spojenia medzi neurónmi zodpovedajú susedským vzťahom medzi zodpovedajúcimi zhlukmi v priestore znakov.
Takéto mapy je vhodné považovať za dvojrozmerné siete uzlov umiestnených vo viacrozmernom priestore. Samoorganizujúca sa mapa je spočiatku mriežkou uzlov, prepojených odkazmi. Kohonen zvažoval dve možnosti pripojenia uzlov - v obdĺžnikovej a šesťhrannej mriežke - rozdiel je v tom, že v obdĺžnikovej mriežke je každý uzol pripojený k 4 susedným uzlom a v šesťhrannej mriežke k 6 najbližším uzlom. Pri dvoch takýchto mriežkach sa proces konštrukcie Kohonenovy siete líši len v mieste, kam sa presunú susedia najbližšie k danému uzlu.
Počiatočné vnorenie siete do dátového priestoru je ľubovoľné. Autorský balík SOM_PAK ponúka možnosti náhodného počiatočného usporiadania uzlov v priestore a možnosť usporiadania uzlov v rovine. Potom sa uzly začnú pohybovať v priestore podľa nasledujúceho algoritmu:
- Dátový bod je vybraný náhodne X .
- Najbližšie k X uzol karty (BMU - Best Matching Unit).
- Tento uzol sa posunie o daný krok smerom k x. Nepohybuje sa však sám, ale nesie so sebou určitý počet najbližších uzlov z určitého susedstva na mape. Zo všetkých pohybujúcich sa uzlov je centrálny uzol - ten, ktorý je najbližšie k dátovému bodu - premiestnený najsilnejšie a ostatné zažívajú menšie posuny, čím ďalej sú od BMU. Pri ladení mapy existujú dve fázy – fáza objednávania a fáza jemného dolaďovania. V prvej fáze sa vyberú veľké hodnoty okolia a pohyb uzlov má kolektívny charakter - v dôsledku toho sa mapa „narovná“ a zhruba odráža štruktúru údajov; v štádiu jemného ladenia je polomer okolia 1–2 a upravujú sa jednotlivé polohy uzlov. Okrem toho hodnota posunu v priebehu času rovnomerne klesá, to znamená, že je veľká na začiatku každej z tréningových etáp a blízka nule na konci.
- Algoritmus opakuje určitý počet epoch (je zrejmé, že počet krokov sa môže značne líšiť v závislosti od úlohy).
Známe typy sietí
- Hammingova sieť;
- neocognitron;
- Chaotická neurónová sieť;
- Counter Spread Network;
- Sieť s radiálnymi základnými funkciami (RBF-network);
- Generalizovaná regresná sieť;
- Pravdepodobnostná sieť;
- siamská neurónová sieť;
- Adaptívne rezonančné siete.
Rozdiely od strojov s von Neumannovou architektúrou
Dlhé obdobie evolúcie dalo ľudskému mozgu mnohé vlastnosti, ktoré v strojoch s von Neumannovou architektúrou chýbajú:
- Hromadný súbeh;
- Distribuovaná prezentácia informácií a výpočtov;
- Schopnosť učiť sa a zovšeobecňovať;
- Prispôsobivosť;
- Vlastnosť spracovania kontextových informácií;
- Tolerancia voči chybám;
- Nízka spotreba energie.
Neurónové siete - univerzálne aproximátory
Neurónové siete sú univerzálne aproximačné zariadenia a dokážu simulovať akýkoľvek spojitý automat s akoukoľvek presnosťou. Je dokázaná zovšeobecnená aproximačná veta: pomocou lineárnych operácií a kaskádového zapojenia je možné získať zariadenie z ľubovoľného nelineárneho prvku, ktoré vypočíta ľubovoľnú spojitú funkciu s akoukoľvek vopred určenou presnosťou. To znamená, že nelineárna charakteristika neurónu môže byť ľubovoľná: od sigmoidálnej po ľubovoľný vlnový paket alebo vlnku, sínus alebo polynóm. Zložitosť konkrétnej siete môže závisieť od výberu nelineárnej funkcie, ale pri akejkoľvek nelineárnosti zostáva sieť univerzálnym aproximátorom a pri správnej voľbe štruktúry môže aproximovať fungovanie akéhokoľvek spojitého automatu tak presne, ako si želáte.
Príklady aplikácií
Predpovedanie finančných časových radov
Vstupné údaje - skladová cena za r. Úlohou je určiť zajtrajší kurz. Prebieha nasledujúca premena - kurz na dnes, včera, na predvčerom, na predvčerom je zoradený. Ďalší riadok sa posunie podľa dátumu o jeden deň atď. Na výslednej množine sa natrénuje sieť s 3 vstupmi a jedným výstupom - teda výstup: sadzba za dátum, vstupy: sadzba za dátum mínus 1 deň, mínus 2 dni, mínus 3 dni. Pre trénovanú sieť odošleme kurz na dnes, včera, predvčerom a dostaneme odpoveď na zajtra. Je ľahké vidieť, že v tomto prípade sieť jednoducho zobrazí závislosť jedného parametra od troch predchádzajúcich. Ak je žiaduce vziať do úvahy nejaký iný parameter (napríklad všeobecný index pre odvetvie), potom ho treba pridať ako vstup (a zahrnúť do príkladov), sieť preškoliť a získať nové výsledky. Pre čo najpresnejší tréning sa oplatí použiť metódu ORO, pretože je najpredvídateľnejšia a jednoduchšie na implementáciu.
Psychodiagnostika
Štúdiu otázky možnosti rozvoja psychologickej intuície v expertných systémoch neurónových sietí sa venuje séria prác M. G. Dorrera a kol. Získané výsledky poskytujú prístup k odhaleniu mechanizmu intuície neurónových sietí, ktorý sa prejavuje pri riešení psychodiagnostických úloh. Vytvorené neštandardné pre výpočtovú techniku intuitívne prístup k psychodiagnostike, ktorý spočíva vo vylúčení konštrukcie opísaná realita... Umožňuje skrátiť a zjednodušiť prácu na psychodiagnostických technikách.
Chemoinformatika
Neurónové siete sú široko používané v chemickom a biochemickom výskume. V súčasnosti sú neurónové siete jednou z najrozšírenejších metód chemoinformatiky na hľadanie kvantitatívnych vzťahov medzi štruktúrou a vlastnosťami, vďaka čomu sa aktívne využívajú ako na predpovedanie fyzikálno-chemických vlastností, tak aj biologickej aktivity chemických látok. zlúčenín a na smerový dizajn chemických zlúčenín a materiálov s vopred určenými vlastnosťami, a to aj pri vývoji nových liekov.
Poznámky (upraviť)
- McCulloch W.S., Pitts W., Logický počet myšlienok súvisiacich s nervovou činnosťou // V zbierke: "Automata" ed. C. E. Shannon a J. McCarthy. - M .: Zahraničné vydavateľstvo. lit., 1956.-- s.363-384. (Preklad anglického článku z roku 1943)
- Rozpoznávanie vzoru a adaptívne ovládanie. BERNARD VDROW
- Widrow B., Stearns S., Adaptívne spracovanie signálu. - M .: Rádio a komunikácia, 1989 .-- 440 s.
- Werbos P.J., Beyond regression: Nové nástroje na predikciu a analýzu v behaviorálnych vedách. Ph.D. diplomová práca, Harvardská univerzita, Cambridge, MA, 1974.
- Galuškin A.I. Syntéza viacvrstvových systémov rozpoznávania vzorov. - M.: "Energia", 1974.
- Rumelhart D.E., Hinton G.E., Williams R.J., Učenie sa interných vyhlásení šírením chýb. In: Parallel Distributed Processing, roč. 1, str. 318-362. Cambridge, MA, MIT Press. 1986.
- Bartsev S.I., Okhonin V.A. Adaptívne siete na spracovanie informácií. Krasnojarsk: Fyzikálny ústav, Sibírska pobočka Akadémie vied ZSSR, 1986. Predtlač N 59B. - 20 p.
- BaseGroup Labs – praktická aplikácia neurónových sietí v problémoch klasifikácie
- Tento typ kódovania sa niekedy označuje ako kód „1 z N“.
- Otvorené systémy - úvod do neurónových sietí
- Mirkes E.M., Logicky transparentné neurónové siete a produkcia explicitných znalostí z údajov, V knihe: Neuroinformatika / A. N. Gorban, V. L. Dunin-Barkovskij, A. N. Kirdin a ďalšie - Novosibirsk: Veda. Siberian Enterprise RAS, 1998 .-- 296 s ISBN 5020314102
- Zmienka o tomto príbehu v časopise Popular Mechanics
- http://www.intuit.ru/department/expert/neuro/10/ INTUIT.ru – Opakujúce sa siete ako asociatívne úložné zariadenia]
- Kohonen, T. (1989/1997/2001), Samoorganizujúce sa mapy, Berlín - New York: Springer-Verlag. Prvé vydanie 1989, druhé vydanie 1997, tretie rozšírené vydanie 2001, ISBN 0-387-51387-6, ISBN 3-540-67921-9
- A. Yu Zinoviev Vizualizácia viacrozmerných údajov. - Krasnojarsk: Ed. Krasnojarská štátna technická univerzita, 2000 .-- 180 s.
- Gorban A. N., Všeobecná aproximačná teoréma a výpočtové schopnosti neurónových sietí, Siberian Journal of Computational Mathematics, 1998. Zväzok 1, č. 1. S. 12-24.
- Gorban A.N., Rossijev D.A., Dorrer M.G., MultiNeuron – simulátor neurónových sietí pre medicínske, fyziologické a psychologické aplikácie, Wcnn'95, Washington, DC: Svetový kongres o neurónových sieťach Výročné stretnutie Medzinárodnej spoločnosti pre neurónové siete v roku 1995: Renaissance Hotel, Washington, DC, USA, 17. – 21. júla, 1995.
- Dorrer M.G., Psychologická intuícia umelých neurónových sietí, Diss. ... 1998. Ďalšie kópie online:,
- Baskin I.I., Palyulin V.A., Zefirov N.S., Aplikácia umelých neurónových sietí v chemickom a biochemickom výskume, Vestn. Moskva Un-Ta. Ser. 2. Chémia. 1999, zväzok 40. č. 5.
- Galberstam N.M., Baskin I.I., Palyulin V.A., Zefirov N.S. Neurónové siete ako metóda hľadania štruktúry závislostí - vlastnosť organických zlúčenín // Pokroky v chémii... - 2003. - T. 72. - Č. 7. - S. 706-727.
- Baskin I.I., Palyulin V.A., Zefirov N.S. Viacvrstvové perceptróny pri štúdiu vzťahov medzi štruktúrou a vlastnosťami organických zlúčenín // Russian Chemical Journal (Časopis Ruskej chemickej spoločnosti pomenovaný po D.I. Mendelejevovi)... - 2006. - T. 50. - S. 86-96.
Odkazy
- Umelá neurónová sieť pre PHP 5.x - Seriózny projekt vývoja neurónových sietí v programovacom jazyku PHP 5.X
- Fórum o neurónových sieťach a genetických algoritmoch
- Mirkes E.M., Neuroinformatika: Učebnica. manuál pre študentov s programami pre laboratórnu prácu.
- Krok za krokom príklady implementácie najznámejších typov neurónových sietí v MATLAB, Neural Network Toolbox
- Výber materiálov o neurónových sieťach a prediktívnej analýze
- protivníkova aplikácia neurónových sietí pri predpovedaní cien akcií








Pomer strán 1440 x 900
Rozlíšenia obrazovky monitora
Kedy potrebujem aktualizovať firmvér
Ako premeniť smartfón s Androidom na bezpečnostnú kameru
Ako vyzerá čínska klávesnica (história a fotografie)