Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Что такое нейронные сети
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами - дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.

Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Компьютерное зрение
До того, как мы научились это применять к компьютерному зрению - в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Архитектура глубинной нейронной сети
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.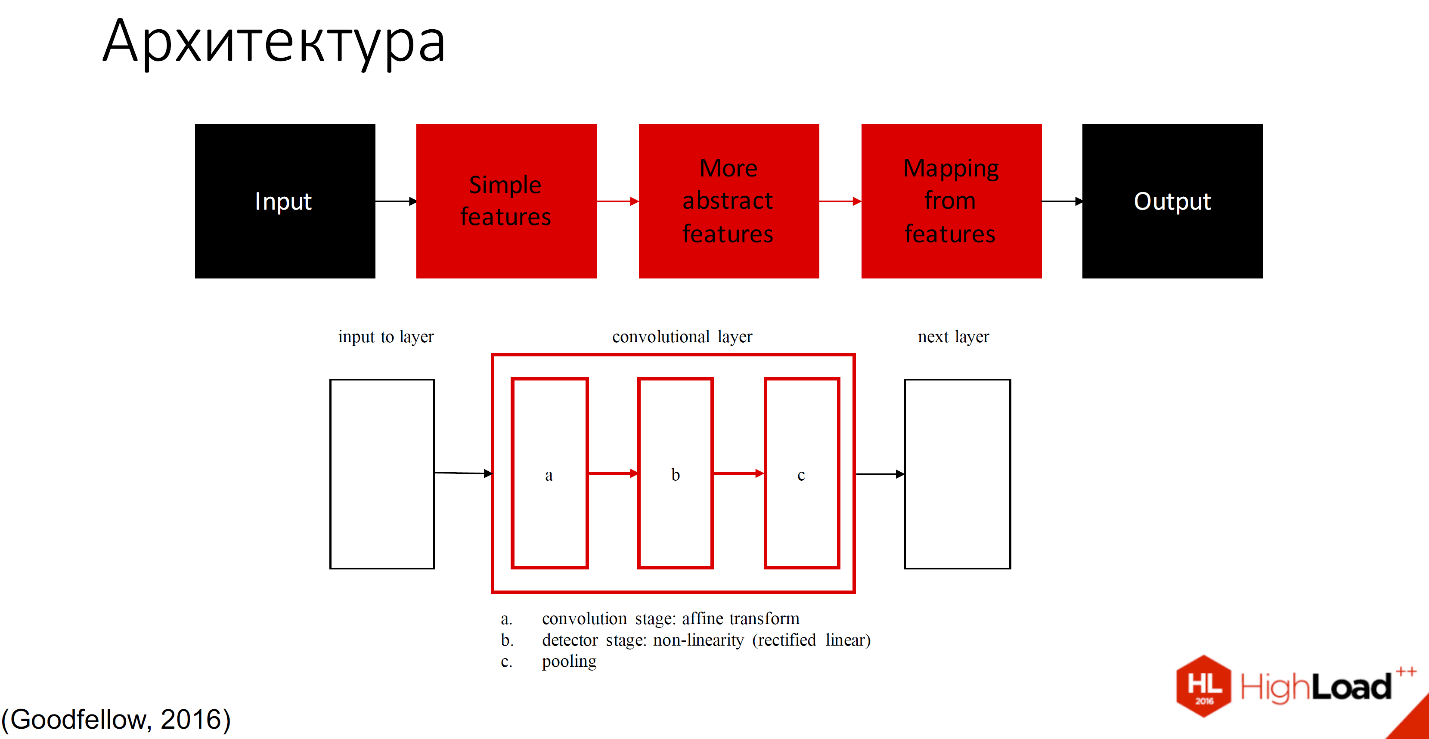
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Классические задачи сверточных нейронных сетей
Их на самом деле не так много, они относятся к трём классам. Среди них - такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ - это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания - это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ - это выделение границ, разбитых на классы.
- Выделение частей тела человека .
- И самая высокоуровневая задача - распознавание самих объектов , которое мы сейчас рассмотрим на примере распознавания лиц.
Распознавание лиц
Первое, что мы делаем - пробегаем face detector"ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Рекуррентные нейронные сети
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Обучение с подкреплением
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа - это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Нестандартные применения нейронных сетей
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали - ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах - вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
В данной статье собраны материалы - в основном русскоязычные - для базового изучения искусственных нейронных сетей.
Искусственная нейронная сеть, или ИНС - математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей - сетей нервных клеток живого организма. Наука нейронных сетей существует достаточно давно, однако именно в связи с последними достижениями научно-технического прогресса данная область начинает обретать популярность.
Книги
Начнем подборку с классического способа изучения - с помощью книг. Мы подобрали русскоязычные книги с большим количеством примеров:
- Ф. Уоссермен, Нейрокомпьютерная техника: Теория и практика. 1992 г.
В книге в общедоступной форме излагаются основы построения нейрокомпьютеров. Описана структура нейронных сетей и различные алгоритмы их настройки. Отдельные главы посвящены вопросам реализации нейронных сетей. - С. Хайкин, Нейронные сети: Полный курс. 2006 г.
Здесь рассматриваются основные парадигмы искусственных нейронных сетей. Представленный материал содержит строгое математическое обоснование всех нейросетевых парадигм, иллюстрируется примерами, описанием компьютерных экспериментов, содержит множество практических задач, а также обширную библиографию.
Д. Форсайт, Компьютерное зрение. Современный подход. 2004 г.
Компьютерное зрение – это одна из самых востребованных областей на данном этапе развития глобальных цифровых компьютерных технологий. Оно требуется на производстве, при управлении роботами, при автоматизации процессов, в медицинских и военных приложениях, при наблюдении со спутников и при работе с персональными компьютерами, в частности, поиске цифровых изображений.
Видео
Нет ничего доступнее и понятнее, чем визуальное обучение при помощи видео:
- Чтобы понять,что такое вообще машинное обучение, посмотрите вот эти две лекции от ШАДа Яндекса.
- Введение в основные принципы проектирования нейронных сетей - отлично подходит для продолжения знакомства с нейронными сетями.
- Курс лекций по теме «Компьютерное зрение» от ВМК МГУ. Компьютерное зрение - теория и технология создания искусственных систем, которые производят обнаружение и классификацию объектов в изображениях и видеозаписях. Эти лекции можно отнести к введению в эту интересную и сложную науку.
Образовательные ресурсы и полезные ссылки
- Портал искусственного интеллекта.
- Лаборатория «Я - интеллект».
- Нейронные сети в Matlab .
- Нейронные сети в Python (англ.):
- Классификация текста с помощью ;
- Простой .
- Нейронная сеть на .
Серия наших публикаций по теме
Ранее у нас публиковался уже курс #neuralnetwork@tproger по нейронным сетям. В этом списке публикации для вашего удобства расположены в порядке изучения.
Шины ISA и EISA
Шина ISA была первой стандартизированной системной шиной (ISA означает Industry Standart Architecture ) и долгие годы являлась стандартом в области РС. И даже сегодня разъемы этой шины можно встретить на некотороых системных платах.
8-разрядная шина
Родоначальником в семействе шин ISA была появившаяся в 1981 году 8-разрядная шина (8 bit ISA Bus), которую можно встретить в компьютерах ХТ-генерации. 8-разрядная шина имеет 62 линии, контакты которых можно найти на ее слотах. Они включают 8 линий данных, 20 линий адреса, 6 линий запроса прерываний. Шина функционирует на частоте 4.77 MHz. 8-разрядная шина ISA - самая медленная из всех системных шин (пропускная способность составляет всего 1.2 Mb в секунду), поэтому она уже давным давно устарела и поэтому сегодня нигде не используется, ну разве что о-о-очень редко (например, некоторые карточки FM-тюнера могут 8-разрядный ISA-интерфейс, так как там шина используется только для управления, а не для передачи собственно данных, и скорость ее работы является некритичной).
16-разрядная шина
Дальнейшим развитием ISA стала 16-разрядная шина, также иногда называемая AT-Bus, которая впервые начала использоваться в 1984 году. Если вы посмотрите на ее слоты (извините, пожалуйста, за плохое качество рисунка), то увидите, что они состоят из двух частей, из которых одна (большая) полностью копирует 8-разрядный слот. Дополнительная же часть содержит 36 контактов (дополнительные 8 линий данных, 4 линии адреса и 5 линий IRQ плюс контакт для нового сигнала SBHE). На этом основании короткие 8-разрядные платы можно устанавливать в разъемы новой шины (сделать это наоборот, конечно же, невозможно). Назначение выводов 16-разрядного слота приведено в нижеследующей таблице.
| Вывод (сторона пайки) | Сигнал | Значение | Вывод (сторона монтажа) | Сигнал | Значение |
| B1 | GND | Земля | А1 | I/O CH CK | Контроль канала ввода/вывода |
| B2 | RES DRV | Сигнал Reset | A2 | D7 | Линия данных 8 |
| B3 | +5 V | +5 V | A3 | D6 | Линия данных 7 |
| B4 | IRQ9 | Каскадирование второго контроллера прерываний | A4 | D5 | Линия данных 6 |
| B5 | -5 V | -5 V | A5 | D4 | Линия данных 5 |
| B6 | DRQ2 | Запрос DMA 2 | A6 | D3D | Линия данных 4 |
| B7 | -12 V | -12 V | A7 | D2 | Линия данных 3 |
| B8 | RES | Коммуникация с памятью без времени ожидания | A8 | D1 | Линия данных 2 |
| B9 | +12 V | +12 V | A9 | D0 | Линия данных 1 |
| B10 | GND | Земля | A10 | I/O CH RDY | Контроль готовности канала ввода/вывода |
| B11 | SMEMW | Данные записываются в память (до 1 Mb, S обозначает Small) | A11 | AEN | Address Enabled, контроль за шиной при CPU и DMA-контроллере |
| B12 | SMEMR | Данные cчитываются из памяти (до 1 Mb, S обозначает Small) | A12 | A19 | Адресная линия 20 |
| B13 | IOW | Данные записываются в I/O-порт | A13 | A18 | Адресная линия 19 |
| B14 | IOR | Данные читаются из I/O-порта | A14 | A17 | Адресная линия 18 |
| B15 | DACK3 | DMA-Acknowledge (подтверждение) 3 | A15 | A16 | Адресная линия 17 |
| B16 | DRQ3 | Запрос DMA 3 | A16 | A15 | Адресная линия 16 |
| B17 | DACK1 | DMA-Acknowledge (подтверждение) 1 | A17 | A14 | Адресная линия 15 |
| B18 | IRQ1 | Запрос прерывания 1 | A18 | A13 | Адресная линия 14 |
| B19 | REFRESH | Регенерация памяти | A19 | A12 | Адресная линия 13 |
| B20 | CLC | Системный такт 4.77 MHz | A20 | A11 | Адресная линия 12 |
| B21 | IRQ7 | Запрос прерывания 7 | A21 | A10 | Адресная линия 11 |
| B22 | IRQ6 | Запрос прерывания 6 | A22 | A9 | Адресная линия 10 |
| B23 | IRQ5 | Запрос прерывания 5 | A23 | A8 | Адресная линия 9 |
| B24 | IRQ4 | Запрос прерывания 4 | A24 | A7 | Адресная линия 8 |
| B25 | IRQ3 | Запрос прерывания 3 | A25 | A6 | Адресная линия 7 |
| B26 | DACK2 | DMA-Acknowledge (подтверждение) 2 | A26 | A5 | Адресная линия 6 |
| B27 | T/C | Terminal Count, сигнализирует конец DMA-трансформации | A27 | A4 | Адресная линия 5 |
| B28 | ALE | Address Latch Enabled, расстыковка адрес/данные | A28 | A3 | Адресная линия 4 |
| B29 | +5 V | +5 V | A29 | A2 | Адресная линия 3 |
| B30 | OSC | Такт осциллятора (14.31818 MHz) | A30 | A1 | Адресная линия 2 |
| B31 | GND | Земля | A31 | A0 | Адресная линия 1 |
| D1 | MEM CS 16 | Memory Chip Select (выбор) | C1 | SBHE | System Bus High Enabled, сигнал для 16-разрядных данных |
| D2 | I/O CS 16 | I/O-карта с 8 бит/16 бит переносом | C2 | LA23 | Адресная линия 24 |
| D3 | IRQ10 | Запрос прерывания 10 | C3 | LA22 | Адресная линия 23 |
| D4 | IRQ11 | Запрос прерывания 11 | C4 | LA21 | Адресная линия 22 |
| D5 | IRQ12 | Запрос прерывания 12 | C5 | LA20 | Адресная линия 21 |
| D6 | IRQ13 | Запрос прерывания 13 | C6 | LA19 | Адресная линия 20 |
| D7 | IRQ14 | Запрос прерывания 14 | C7 | LA18 | Адресная линия 19 |
| D8 | DACK0 | DMA-Acknowledge (подтверждение) 0 | C8 | LA17 | Адресная линия 18 |
| D9 | DRQ0 | Запрос DMA 0 | C9 | MEMR | Чтение данных из памяти |
| D10 | DACK5 | DMA-Acknowledge (подтверждение) 5 | C10 | MEMW | Запись данных в памят |
| D11 | DRQ5 | Запрос DMA 5 | C11 | SD8 | Линия данных 9 |
| D12 | DACK6 | DMA-Acknowledge (подтверждение) 6 | C12 | SD9 | Линия данных 10 |
| D13 | DRQ6 | Запрос DMA 6 | C13 | SD10 | Линия данных 11 |
| D14 | DACK7 | DMA-Acknowledge (подтверждение) 7 | C14 | SD11 | Линия данных 12 |
| D15 | DRQ7 | Запрос DMA 7 | C15 | SD12 | Линия данных 13 |
| D16 | +5 V | +5 V | C16 | SD13 | Линия данных 14 |
| D17 | MASTER | Сигнал Busmaster | C17 | SD14 | Линия данных 15 |
| D18 | GND | Земля | C18 | SD15 | Линия данных 16 |
 Реализация bus mastering не была особенно
удачной, поскольку, например, запрос на освобождение
шины (Bus hang-off) к текущему bus master обрабатывался
несколько тактов, к тому же каждый master должен
был периодически освобождать шину, чтобы дать возможность
провести обновление памяти (memory refresh), или
сам проводить обновление. Для обеспечения обратной
совместимости с 8-битными платами большинстиво новых
возможностей было реализовано путем добавления новых
линий. Так как АТ был построен на основе процессора
Intel 80286, который был существенно быстрее, чем
8088, пришлось добавить генератор состояний ожидания
(wait-state generator). Для обхода этого генератора
используется свободная линия (контакт В8) исходной
8-битной шины. При установке этой линии в 0 такты
ожидания пропускаются. Это позволило разработчикам
делать как 16-битные, так и 8-битные быстрые платы.
Реализация bus mastering не была особенно
удачной, поскольку, например, запрос на освобождение
шины (Bus hang-off) к текущему bus master обрабатывался
несколько тактов, к тому же каждый master должен
был периодически освобождать шину, чтобы дать возможность
провести обновление памяти (memory refresh), или
сам проводить обновление. Для обеспечения обратной
совместимости с 8-битными платами большинстиво новых
возможностей было реализовано путем добавления новых
линий. Так как АТ был построен на основе процессора
Intel 80286, который был существенно быстрее, чем
8088, пришлось добавить генератор состояний ожидания
(wait-state generator). Для обхода этого генератора
используется свободная линия (контакт В8) исходной
8-битной шины. При установке этой линии в 0 такты
ожидания пропускаются. Это позволило разработчикам
делать как 16-битные, так и 8-битные быстрые платы.
Новый слот содержал 4 новых адресных линии (LA20-LA23) и копии трех младших адресных линий (LA17-LA19). Необходимость в таком дублировании возникла из-за того, что адресные линии ХТ были линиями с задержкой (latched lines), и эти задержки приводили к снижению быстродействия периферийных устройств. Использование дублирующего набора адресных линий позволяло 16-битной карте в начале цикла определить, что к ней обращаются, и послать сигнал о том, что она может осуществлять 16-битный обмен. На самом деле это ключевой момент в обеспечении обратной совместимости. Если процессор пытается осуществить 16-битный доступ к плате, он сможет это сделать только в том случае, если получит от нее соответствующий отклик IO16. В противном случае чипсет инициирует вместо одного 16-битного цикла два 8-битных. И все бы было хорошо, но адресных линий без задержки всего 7, поэтому платы, использующие диапазон адресов меньший, чем 128 Kb, не могли определить, находится ли переданный адрес в их диапазоне адресов, и, соответственно, послать отклик IO16. Таким образом, многие платы, в том числе платы EMS, не могли использовать 16-битный обмен.
Передача байта данных по шине ISA происходит следующим образом: сначала на адресной шине выставляется адрес ячейки RAM или порта устройства ввода/вывода, куда следует передать байт, затем на линии данных выставляется байт данных. Призводится задержка тактами ожидания и подается сигнал на передачу байта (строб записи), причем неизвестно, успели записаться данные или нет. Поэтому тактова частота шины выбрана 8.33 MHz, чтобы даже самые медленные устройства гарантированно могли произвести по шине обмен даными (командами). Пропускная способность при этом составила 5.3 Mb/s.
 Несмотря на отсутствие официального стандарта
и технических "изюминок", шина ISA превосходила
потребности среднего пользователя 1984 года, а популярность
IBM AT на рынке массовых компьютеров привела к тому,
что производители плат расширения и клонов AT приняли
ISA за стандарт. Такая популярность шины привела
к тому, что слоты ISA до сих пор присутствуют на
многих современных системных плат, и карты для шины
ISA все еще производятся (именно поэтому мы и представили
так детально распайку 16-разрядной шины ISA).
Несмотря на отсутствие официального стандарта
и технических "изюминок", шина ISA превосходила
потребности среднего пользователя 1984 года, а популярность
IBM AT на рынке массовых компьютеров привела к тому,
что производители плат расширения и клонов AT приняли
ISA за стандарт. Такая популярность шины привела
к тому, что слоты ISA до сих пор присутствуют на
многих современных системных плат, и карты для шины
ISA все еще производятся (именно поэтому мы и представили
так детально распайку 16-разрядной шины ISA).
Правда, в последних спецификациях компьютерного оборудования начали отказваться от старой шины (все-таки более 15 лет в области компьютерной индустрии - это громадный срок). Но все дело в том, что у пользователей за это время накопилось мнжество разнообразных плат с ISA-интерфесом, и вряд ли они пожелают лекго с ними расстаться. Тем более что такие низкоскоростные устройства как, например, модемы или медленные сетевые платы не не требуют высокой пропускной способности шины, и применение более современных интерфейсов не дает для них каких-либо особых преимуществ. И никто не запрещает производителям материнских плат ставить на свои изделия один-два больших черных слота, тем более что при наметившейся тенденции платы с поддержкой ISA могут пользоваться повышенным спросом у владельцев старых карт. Так что ISA, по-видимому, еще не ушла и не так скоро уйдет со своих насиженных позиций, как это может показаться на первый взгляд.
Шина EISA
Необходимость повышения производительности наряду с обеспечением совместимости привела к дальнейшему развитию шины ISA. Поэтому в сентябре 1988 года Compaq, Epson, Hewllett-Packard, NEC, Wyse, Zenith, Olivetti, AST Research и Tandy представили 32-разрядное расширение шины с полной обратной совместимостью, которое получило название EISA (Extended ISA ). Основные характеристики нового интерфейса были следующими:
- Слот EISA полностью совместим со слотом ISA. Как и в случае 16-разрядного расширения, новые возможности обеспечивались путем добавления новых линий. Поскольку дальше удлинять разъем ISA было некуда, разработчики нашли оригинальное решение: новые контакты были размещены между контактами шины ISA и не были доведены до края разъема. Специальная система выступов на разъеме и щелей в cоответствующих местах на EISA-картах позволяла им (картам) глубже заходить в разъем и подсоединяться к новым контактам. На "первом этаже" (верхнем) этой двухэтажной конструкции находятся контакты уже известной ISA, в то время как на "втором этаже" (нижнем) находятся новые выводы EISA. По этой причине в слоты EISA могут вставляться и ISA-карточки (последние не будут полностью входить в разъем, так как они не имеют прорези)
- EISA является 32-разрядной шиной, что в сочетании с 8.33 MHz"ами дает пропускную способность в 33 Mb/s
- 32-разрядная адресация памяти позволяла адресовать до 4 Gb памяти (как и в расширении ISA, новые адресные линии были без задержки)
- Автонастройка плат расширения, а также возможность их конфигурации не с помощью DIP-переключателей, а программно
- Поддержка возможности задания уровня двухуровневого (edge-triggered ) прерывания, что позволяло нескольким устройствам использовать одно прерывание, как и в случае многоуровневого (level-triggered ) прерывания
- Поддержка multiply bus master
- Шина EISA предоставляет большие преимущества при использовании кэш-памяти
Как видно из изложенного описания, для потребностей того времени этого было вполне достаточно.
Важной особенностью шины являлась возможность для любого bus master обращаться к любому устройству памяти или периферийному устройству, даже если они имели разные разряды шины. Говоря о полной обратной совместимости с ISA, следует отметить, что ISA-карты, естественно, не поддерживали разделение прерываний, даже будучи вставленными в EISA-коннектор. Что касается поддержки multiply bus master, то она представляла собой улучшенную и дополненную версию таковой для ISA. Также присутствовали четыре уровня приоритета:
- Cхемы обновления памяти
- Процессор
- Адаптеры шины
Имелся также арбитр шины EISA - так называемый перефирийный контроллер (ISP, Integrated System Peripheral ), который следил за порядком. Кроме этого, наличествовало еще одно устройство - Intel"s Bus Master Interface Chip (BMIC), которое следило за тем, чтобы master не засиживался на шине. Через определенное количество тактов master снимался с шины и генерировалось немаскируемое прерывание.
Я не буду приводить назначение выводов EISA-слота, так как шина EISA не получила такого большого распространения, как ISA, и уже давно вымерла. Найти ее можно разве что только в достаточно древних компьютерах.
Шина ISA (I ndustrial S tandart A rhitecture) является фактически стандартной шиной для персональных компьютеров типа IBM PC/AT и совместимых с ними. Шина EISA , с которой ряд фирм выпускал персональные компьютеры, уступила шине PCI и в настоящее время используется редко.
Основные отличия шины ISA персонального компьютера IBM PC/AT от своей предшественницы - шины компьютера IBM PC/XT заключаются в следующем:
шина AT компьютеров позволяет использовать на внешних платах как 16-разрядные устройства ввода/вывода, так и 16-разрядную память;
цикл доступа к 16-разрядной памяти на внешней плате может быть выполнен без вставки тактов ожидания;
объем непосредственно адресуемой памяти на внешних платах может достигать 16 Мб;
внешняя плата может становиться хозяином (задатчиком) на шине и самостоятельно осуществлять доступ ко всем ресурсам как на шине, так и на материнской плате.
При описании шины целесообразно представить компьютер как состоящий из материнской платы (motherboard) и внешних плат, которые взаимодействуют между собой и ресурсами материнской платы через шину. Все пассивные устройства (не могущие стать задачиками) на шине можно разделить на две группы - память и устройства ввода/вывода (порты). Циклы доступа для каждой из групп отличаются друг от друга как по временным характеристикам, так и по вырабатываемым на шине сигналам.
Чисто условно, для удобства понимания функционирования шины ISA , будем считать, что на материнской плате компьютера существуют следующие устройства, способные быть владельцами (задатчиками) шины: центральный процессор (ЦП), контроллер прямого доступа в память (ПДП), контроллер регенерации памяти (КРП). Кроме этого, задатчиком на шине может быть и внешняя плата. При выполнении цикла доступа на шине задатчиком может быть только одно из устройств. Рассмотрим подробнее функции этих устройств на шине ISA .
Центральный процессор (ЦП) - является основным задатчиком на шине. По умолчанию именно ЦП будет считаться задатчиком на шине. Контроллер ПДП, а также контроллер регенерации памяти запрещают работу ЦП на время своей работы.
Контроллер ПДП - это устройство связано с сигналами запроса на режим ПДП и сигналами подтверждения режима ПДП. Активный сигнал запроса на ПДП будет разрешать последующий захват шины контроллером ПДП для передачи данных из памяти в порты вывода или из портов ввода в память.
Контроллер регенерации памяти - становится владельцем шины и генерирует сигналы адреса и чтения памяти для регенерации информации в микросхемах динамической памяти как на материнской памяти, так и внешних платах.
Внешняя плата - взаимодействует с остальными устройствами через разъем на шине ISA. Может становиться задатчиком на шине для доступа к памяти или устройствам ввода/вывода.
Кроме этого, на материнской плате компьютера имеется ряд устройств, которые не могут быть задатчиками на шине, но тем не менее взаимодействуют с ней. Это следующие устройства:
Часы реального времени (Таймер-счетчик) - это устройство состоит из часов реального времени для поддержки даты и времени и таймера, как правило на базе микросхемы Intel 8254A. Один из таймеров-счетчиков этой микросхемы вырабатывает импульсы с периодом 15 микросекунд для запуска контроллера регенерации памяти на регенерацию.
Кросс материнской платы - часть материнской платы, которая соединяет разъемы шины ISA для подключения внешних плат с другими ресурсами на материнской плате.
Память на материнской плате - часть или все микросхемы памяти прямого доступа (ОЗУ), используемые для хранения информации ЦП. На внешних платах также могут быть размещены микросхемы дополнительной памяти.
Контроллер прерываний - это устройство связано с линиями запросов прерываний на шине. Прерывания требуют дальнейшего обслуживания ЦП.
Устройства ввода/вывода - часть или все устройства ввода/вывода (такие как параллельные или последовательные порты) могут размещаться как на материнской плате, так и на внешних платах.
Перестановщик байтов данных - это устройство позволяет обмениваться данными между собой 16-разрядными и 8-разрядными устройствами.
Архитектура персонального компьютера IBM PC/AT с точки зрения использования шины ISA показана на рисунке.
Внешние платы, устанавливаемые в разъемы шины, могут быть 8- и/или 16-разрядными. 8-разрядная плата имеет только один интерфейсный разъем и может оперировать только с 8-разрядными данными. 8-разрядный слот также не может быть задатчиком на шине. 16-разрядная плата обязательно имеет два интерфейсных разъема - один основной, такой же как в 8-разрядных платах, и один дополнительный. Такая плата может оперировать как с 8-, так и с 16-разрядными данными и, кроме этого, она может быть задатчиком на шине. Общее число устанавливаемых в разъемы шины плат ограничивается как нагрузочной способностью шины, так и конструктивным исполнением материнской платы. Как правило, допускается устанавливать не более 8 (пять 16-разрядных и три 8-разрядных) внешних плат на шину. Такое ограничение вызвано также и относительно небольшим количеством свободных линий запросов на ПДП и запросов на прерывания, имеющихся на шине.
Центральный процессор по умолчанию является основным владельцем шины, контроллер ПДП и контроллер регенерации памяти могут стать задатчиками на шине, только предварительно запретив работу ЦП. Процесс запрещения работы ЦП состоит в выработке сигнала запроса на ПДП и приема сигнала подтверждения ПДП.
Центральный процессор может быть источником как 16-разрядных операций, так и 32-разрядных. Когда ЦП является 16-разрядным ресурсом, он может выполнять операции как с 16-, так и с 8-разрядными ресурсами на шине. При выполнении ЦП команды, оперирующей с 16-разрядными данными, если ресурс доступа 8- разрядный, то специальными аппаратными средствами на материнской плате в этом случае выполняются два цикла доступа. Если же ЦП является 32-разрядным, то аппаратно на материнской плате компьютера один 32-разрядный цикл работы ЦП с внешним ресурсом должен быть преобразован в два индивидуальных 16-разрядных цикла доступа.
Особенности для внешних плат. Если ЦП является задатчиком на шине, то внешние платы могут функционировать только в режиме памяти или устройства ввода/вывода.
Сигналы для поддержки ПДП заводятся с разъема непосредственно на контроллер ПДП, выполненный, как правило, на микросхеме Intel 8237A. Когда режим ПДП запрашивается каким-либо устройством (хотя бы один из сигналов DRQ становится активным), контроллер ПДП осуществляет захват шины у ЦП. Выдача затем соответствующего сигнала -DACK означает, что контроллер ПДП начал передачу данных. Циклы ПДП не будут выполняться на шине, если сигнал -MASTER будет разрешен с какой-либо внешней платы.
Если запрос на ПДП требуется устройству ввода/вывода, то следует учесть, что каналы 0...3 ПДП поддерживают передачу только 8-разрядных данных; все данные должны передаваться только по линиям SD<7...0> . Перестановка байтов в этом случае выполняется аппаратно на материнской плате в соответствии с сигналами SA0 и -SBHE . Такая перестановка может потребоваться, например, при передаче данных из старшего байта 16-разрядной памяти в 8-разрядный порт. Каналы ПДП 5...7 поддерживают передачу только 16-разрядных данных; все данные должны передаваться как 16-разрядные по линиям SD<15...0> . Память, участвующая в работе в режиме ПДП по этим каналам, должна быть только 16-разрядной. Перестановщик байтов на материнской плате не будет корректировать несоответствие размеров данных.
ПРИМЕЧАНИЕ: 8-разрядная память со своей стороны может передавать данные в режиме ПДП только 8-разрядным устройствам ввода/вывода; использование 8-разрядной памяти с 16-разрядными устройствами ввода/вывода не допускается.
ВНИМАНИЕ! Контроллер регенерации памяти не может захватить шину до тех пор, пока контроллер ПДП ей владеет. Это означает, что любой цикл ПДП не должен превышать 15 мкс. В противном случае может произойти потеря информации в микросхемах динамической памяти.
ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ
Сигналы запроса и подтверждения режима ПДП заведены на все внешние платы и эти сигналы вырабатываются обычными ТТЛ выходами, поэтому все внешние платы должны использовать и анализировать различные каналы ПДП. В противном случае возможен конфликт внешних слотов между собой или с устройствами на материнской плате.
Внешние слоты могут быть или памятью прямого доступа или устройством ввода/вывода, когда они взаимодействуют с контроллером ПДП.
Внешние платы могут функционировать в 5 различных режимах: задатчика шины, памяти и устройств ввода/вывода прямого доступа, памяти и устройств ввода/вывода, регенерации памяти или сброса. Платы могут поддерживать любую комбинацию из первых четырех режимов; сигналу сброса должны подчиниться все платы одновременно.
Только 16-разрядные платы с двумя интерфейсными разъемами могут становиться задатчиками на шине . Для захвата шины внешняя плата должна разрешить сигнал -DRQ и, получив сигнал -DACK от контроллера ПДП, разрешить сигнал -MASTER . На этом процедура захвата шины заканчивается.
Внешняя плата, захватив шину, может выполнять любые циклы доступа, так же как центральный процессор. Единственное ограничение - невозможность выполнять циклы ПДП, так как все интерфейсные сигналы, управляющие работой контроллера ПДП, заведены на материнскую плату и не могут быть использованы контроллером ПДП, находящимся на внешней плате. Когда внешняя плата является задатчиком на шине, контроллер ПДП запрещает сигнал AEN и это позволяет устройствам ввода/вывода нормально дешифрировать адрес и быть доступными для внешней платы. При запрещенном сигнале AEN циклы передачи ПДП невозможны (подробнее в разделе описания сигнала AEN , в гл. 3). Кроме этого, циклы ПДП не могут быть выполнены на шине также и потому, что у контроллера ПДП канал, через который был осуществлен захват шины, занят, а другие каналы контроллера ПДП не могут быть использованы до освобождения ранее занятого, т.е. до освобождения шины захватившей ее внешней платой.
ПРИМЕЧАНИЕ: Программное обеспечение, поддерживающее работу внешней платы в качестве задатчика шины, должно обеспечивать использование каналов ПДП только в режиме каскадирования. В противном случае внешняя плата не сможет осуществить захват шины.
ПРИМЕЧАНИЕ: Внешняя плата начинает любой цикл доступа как 16-разрядная, однако если сигнал -MEM CS16 или -I/O CS16 не будет разрешен, цикл будет завершен как 8-разрядный. При этом перестановщик байтов на материнской плате будет определять, по каким линиям данных (SD<15...8> или SD<8...0> ) передается байт информации, исходя из анализа сигналов -SBHE и SA0 .
ВНИМАНИЕ! Захватившая шину внешняя плата обязана не реже, чем через 15 мкс, вырабатывать сигнал -REFRESH для запроса контроллеру регенерации на регенерацию памяти. Контроллер регенерации при выполнении цикла регенерации памяти вырабатывает сигналы адреса, команд и анализирует сигнал I/O CH RDY , но внешняя плата, выработавшая сигнал -REFRESH , по завершении цикла регенерации снимает этот сигнал и продолжает оставаться задатчиком на шине. При необходимости выполнить несколько циклов регенерации сигнал -REFRESH может быть удержан внешней платой на все время требуемого количества циклов регенерации.
Контроллер регенерации памяти не может захватить шину сам до тех пор, пока контроллер ПДП (а именно через него внешняя плата становится задатчиком на шине) не освободит ее на время регенерации по сигналу -REFRESH.
Внешняя плата может работать в режиме ПДП только в том случае, если контроллер ПДП является задатчиком на шине. В режиме прямого доступа к памяти данные всегда передаются между устройством ввода/вывода и памятью на внешней плате. В режиме прямого доступа к устройству ввода/вывода данные передаются между памятью и устройством ввода/вывода на внешней плате. Внешняя плата, отвечающая на шине как 8- или 16-разрядное устройство, должна соответственно использовать 8- или 16- разрядные каналы контроллера ПДП. В табл. 2.2 показано состояние сигналов на шине для режима ПДП.
ВНИМАНИЕ! Следует специально обратить внимание на некоторые особенности при выполнении циклов передачи данных между 8-разрядными устройствами ввода/вывода и 16-разрядной памятью на внешней плате. Во-первых, внешняя плата должна анализировать сигналы -SBHE и SA0 для правильного определения передаваемых данных.
Во-вторых, при записи в УВВ из памяти на внешней плате перестановщик байтов на материнской плате будет определять, по какой половине шины данных (SD<15...8> или SD<7...0> ) следует направить байт; внешняя плата после анализа -SBHE и SA0 должна определить, по какой половине шины данных ей направить байт данных. В-третьих, при чтении УВВ в память на внешней плате перестановшик байтов направляет в память байт данных также либо по старшей половине шины данных SD<15...8> , либо по младшей половине SD<7...0> . Внешняя плата по сигналам -SBHE и SA0 должна определять, когда следует переводить в третье состояние свои выходы по младшей половине шины данных SD<7...0> во избежание столкновений на шине.
Внешняя плата может как 16-разрядная память обмениваться в режиме ПДП как с 8-ми разрядными устройствами ввода/вывода, так и с 16-разрядными. Но, если внешняя плата является 8-разрядной памятью, то в режиме ПДП она может обмениваться данными только с 8-разрядными устройствами ввода/вывода. Другая особенность относится к тому случаю, когда контроллер ПДП выполняет запись данных в 8- разрядное устройство вывода на внешней плате из 16-разрядной памяти. Если такая внешняя плата установлена в 16-разрядный слот и может работать в 16-разрядном режиме, она должна для такого случая поддерживать старшую половину шины данных SD<15...8> в третьем состоянии во избежание столкновения сигналов на шине.
ВНИМАНИЕ! Когда контроллер ПДП является задатчиком на шине, он игнорирует сигнал -0WS, поэтому если внешняя плата используется как 16-разрядная память и обмен с ней выполняется контроллером ПДП, применение быстрых микросхем памяти в такой плате лишено смысла.
Обычный доступ к внешней плате как к памяти или устройству ввода/вывода . Внешняя плата становится обычным ресурсом памяти или ввода/вывода, если задатчиком на шине является центральный процессор или другая внешняя плата.
ВНИМАНИЕ! Существуют особенности такого использования внешней платы, если она устанавливается в слот, а участвует в обмене данными как 8-разрядная память или УВВ в течении всего цикла доступа. При чтении данных в такую внешнюю плату перестановщик байтов будет переставлять данные между шинами SD<15...8> или SD<7...0> для правильного приема данных внешней платой. Внешняя плата при этом должна поддерживать свои выходы SD<15...8> в третьем состоянии, так как иначе неизбежно столкновение сигналов на шине данных.
ВНИМАНИЕ! Когда некоторые внешние платы становятся задатчиками на шине, они могут игнорировать сигнал I/O CH RDY или -0WS и выполнять цикл доступа как цикл обращения к 8- или 16-разрядной памяти. Но любые внешние платы обязаны возвращать задатчику на шине ISA эти сигналы при необходимости, так как если центральный процессор является задатчиком на шине, то он использует эти сигналы для определения продолжительности цикла доступа.
Все внешние платы оказываются в режиме сброса при разрешенном сигнале RESET DRV ; иначе этот режим невозможен. Все выходы с тремя состояниями на плате должны быть в третьем состоянии и все выходы с открытым коллектором должны быть в состоянии логической единицы на время не менее 500 нс после разрешения сигнала RESET DRV . Все внешние платы должны завершить свою инициализацию за время не более 1 мс после разрешения сигнала RESET DRV и быть готовыми к выполнению циклов доступа на шине. Любые операции на шине возможны только после запрещения сигнала RESET DRV .
Контроллер регенерации памяти выполняет циклы чтения памяти по специальным адресам на материнской плате и внешних платах для регенерации информации в микросхемах динамической памяти. Каждые 15 мкс контроллер пытается овладеть шиной для запуска цикла регенерации. Если в этот момент задатчиком на шине является центральный процессор, то он освобождает шину для контроллера регенерации. Если в этот момент шина захвачена внешней платой, то контроллер регенерации выполнит цикл регенерации только при выработке внешней платой сигнала -REFRESH . Если в этот момент задатчиком на шине являлся контроллер ПДП, то до освобождения им шины цикл регенерации не может быть выполнен.
Когда выполняется цикл регенерации, контроллер регенерации вырабатывает сигналы адреса SA<7...0> с одним из 256 возможных адресов регенерации. Другие адресные линии неопределены и могут находиться в третьем состоянии. Этот цикл может выполняться с задержкой по сигналу I/O CH RDY с разрешенными сигналами -SMEMR и -MEMR .
ВНИМАНИЕ! Циклы регенерации должны выполняться каждые 15 мкс для перебора всех 256 адресов за 4 мс. Если это условие не выполняется, данные, хранящиеся в динамической памяти, могут быть утеряны.
В данной главе рассматриваются характеристики шины, не зависящие от типа устройства, захватившего шину.
Максимальное адресное пространство при обращении к памяти, поддерживаемое шиной ISA , 16 Мб (24 линии адреса), но не все слоты поддерживают полностью это адресное пространство. Когда задатчик на шине осуществляет доступ к памяти на материнской плате или к памяти, установленной в слот, он должен разрешать сигналы -MEMR или -MEMW ; аппаратно на материнской плате дополнительно разрешаются сигналы -SMEMR и -SMEMW , если требуемый адрес находится в пределах первого мегабайта адресного пространства. К 8-разрядным слотам подведены только линии -SMEMR и -SMEMR , SD<7...0> и SA<19...0> ; поэтому внешние платы, установленные в 8-разрядные слоты, могут быть либо только 8-разрядными устройствами ввода/вывода, либо 8-ми разрядной памятью в первом мегабайте адресного пространства. Внешние платы, устанавливаемые в 8/16-разрядные слоты, принимают все командные сигналы, адреса и данные; они могут быть как 8-, так и 16-разрядными и адресное пространство памяти на них может быть любым в пределах 16 Мб. Цикл доступа к таким внешним платам завершается как 16-разрядный, если плата разрешает сигнал -I/O CS16 или -MEM CS16 .
ПРИМЕЧАНИЕ: Память на материнской плате или внешней плате считается 16- разрядным ресурсом только в том случае, если разрешается сигнал -MEM CS16 . Этот сигнал вырабатывается из сигналов адреса LA<23...17> ; поэтому 16-разрядная память может быть выбрана только блоками по 128 Кб; внутри такого блока память не может быть частично 8-разрядной, а частично 16-разрядной, так как невозможно по обращению к меньшему блоку однозначно выработать сигнал -MEM CS16 . Разрядность внутри такого блока должна быть одинаковой при обращении по любому адресу внутри 128 Кб.
ВНИМАНИЕ! Микросхемы динамической памяти требуют циклов регенерации через каждые 15 мкс. Если циклы регенерации выполняются реже, чем через 15 мкс, то данные в памяти могут быть потеряны.
ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ
Динамическая память на материнской плате может иметь два вида своей организации - 16- или 32-разрядная. Но разрядность памяти на материнской плате принимается во внимание только центральным процессором, для внешних плат динамическая память на материнской плате всегда только 16-разрядная. ПЗУ на материнской плате, содержащее BIOS (Base Input/Output System - Базовая Система Ввода/Вывода), также всегда 16-разрядное.
Максимально адресное пространство для устройств ввода/вывода, поддерживаемое шиной ISA составляет 64 Кб (16 адресных линий). Все слоты поддерживают 16 адресных линий. Первые 256 адресов зарезервированы для устройств, расположенных, как правило, на материнской плате - регистры контроллера ПДП, контроллера прерываний, часов реального времени, таймера-счетчика и других устройств, требующихся для AT совместимости различных компьютеров.
ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ
Несмотря на то, что для выбора адреса УВВ доступны все 16 сигналов адреса, традиционно для адресов УВВ в компьютерах серии IBM PC/XT/AT использовались только первые 10 разрядов адреса. Это означает, что адреса из следующих килобайтных блоков будут декодироваться также как адреса в первом килобайте адресов УВВ. Поэтому для вновь разрабатываемых внешних плат следует использовать "окна" в существующем сейчас распределении адресов стандартных УВВ для компьютеров IBM PC/AT. Для увеличения количества используемых адресов УВВ (при необходимости) можно использовать адресное пространство выбранного окна со сдвигом на 1 Кб или кратное ему значение. Очевидно, что внешняя плата в этом случае должна декодировать более чем 10 линий адреса.
Линии запроса на прерывания непосредственно заведены на контроллеры прерываний типа Intel 8259A. Контроллер прерываний будет реагировать на запрос по такой линии в случае, если сигнал на ней перейдет из низкого уровня в высокий. Шина ISA не имеет линий, подтверждающих прием запроса на прерывание, поэтому запрашивающее прерывание устройство должно само определять по реакции ЦП подтверждение приема своего запроса.
ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ
Линии запроса на прерывания заведены на все слоты и обрабатываются контроллером прерывания по нарастающему фронту сигнала. До установки новой внешней платы, если она использует в своей работе контроллер прерываний, следует определить, есть ли свободная линия запроса на прерывание и именно ее использовать для новой внешней платы. При не соблюдении этого условия возможно возникновение конфликтных ситуаций на шине.
Центральный процессор или внешняя плата могут выполнить как 8- так и 16-разрядные циклы доступа, причем все циклы всегда начинаются как 16-разрядные, а завершаются как 8- или 16-разрядные. Цикл доступа будет завершен как 8-разрядный, если устройство, к которому осуществляется доступ, запретит сигнал -I/O CS16 или -MEM CS16 .

Перестановщик байтов всегда находится на материнской плате. Его задача - точно согласовать размер данных, которыми обмениваются устройства. На рис. 3.1 показано место перестановщика байтов при пересылке данных между задатчиком и ресурсом, к которому осуществляется доступ. В табл. 3.1 суммируется вся информация по перестановке байтов во время циклов доступа. Перестановка байтов осуществляется с шины SD<15...0> (HIGH BYTE - старший байт) на SD<7...0> (LOW BYTE - младший байт) или наоборот. В таблице перенос байта с шины SD<15...0> на SD<7...0> обозначается как H > L, наоборот - L < H. LL означает, что байт по младшей половине шины данных не переставляется, HH - что байт по старшей половине шины не переставляется. HH/LL - и старший и младший байт передаются каждый по своей половине шины данных и не переставляются.
Таблица 3.1.
|
Задатчик на шине |
Ресурс, к которому осуществляется доступ |
Завершение цикла |
|||||
|
Размер данных |
Размер данных |
Размер данных |
Маршрут чтение запись |
||||
На рис. 3.2 показано место перестановщика байтов для циклов пересылки данных в режиме ПДП. В табл. 3.2 суммируется вся информация по перестановке байтов во время циклов ПДП. Перестановка байтов осуществляется с шины SD<15...0> (HIGH BYTE) на SD<7...0> (LOW BYTE) или наоборот. В таблице перенос байта с шины SD<15...0> на SD<7...0> обозначается как H > L, наоборот - L < H. LL означает, что байт по младшей половине шины данных не переставляется, HH - что байт по старшей половине шины не переставляется. HH/LL - и старший и младший байт передаются каждый по своей половине шины данных и не переставляются.

Таблица 3.2.
|
Устройство ввода/вывода |
Контроллер ПДП |
Завершение цикла |
||||||||||||||||||||||
|
Размер данных |
Размер данных |
-MEM CS16 |
Размер данных |
чтение запись |
||||||||||||||||||||
|
Запрещено |
||||||||||||||||||||||||
|
В этой главе описываются все сигналы на шине ISA. Для лучшего понимания функционирования шины целесообразно разбить все сигналы на 7 групп: АДРЕСА, ДАННЫЕ, СИНХРОСИГНАЛЫ, КОМАНДНЫЕ СИГНАЛЫ, СИГНАЛЫ РЕЖИМА ПДП, ЦЕНТРАЛЬНЫЕ СИГНАЛЫ УПРАВЛЕНИЯ, СИГНАЛЫ ПРЕРЫВАНИЯ, ПИТАНИЕ. Информация о направленности сигналов (вход, выход или двунаправленный) приводится относительно задатчика на шине. Группа сигналов адреса включает в себя адреса, вырабатываемые текущим задатчиком на шине. На шине ISA есть два вида сигналов адреса, SA<19...0> и LA<23...17> . SA<19...0> Адресные сигналы этого типа поступают на шину с регистров адреса, в которых адрес "защелкивается". Сигналы SA<19...0> позволяют осуществлять доступ к памяти только в младшем мегабайте адресного пространства. При доступе к устройству ввода/вывода только сигналы SA<15...0> SA<19...16> не определено. Во время выполнения циклов регенерации адреса только сигналы SA<7...0> имеют действительное значение, а состояние сигналов SA<19...8> неопределено и эти выводы должны быть в третьем состоянии для всех устройств на шине. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Внешняя плата, ставшая задатчиком на шине, должна разрешать сигнал -REFRESH для регенерации памяти, при этом внешняя плата должна перевести свои выходные формирователи сигналов адреса в третье состояние. LA<23...17> Сигналы этого типа поступают на шину без "защелкивания" в регистрах. Когда центральный процессор является задатчиком на шине, то значения сигналов на линиях LA<23...17> истинны во время выработки сигнала BALE и они могут иметь произвольное значение в конце цикла доступа. Если задатчиком на шине является контроллер ПДП, сигналы LA<23...17> истинны до начала сигнала -MEMR или -MEMW и сохраняются до конца цикла. При выполнении циклов доступа к памяти сигналы LA<23...17> всегда истинны, а при доступе к устройствам ввода/вывода эти сигналы имеют уровень логического "0". При выполнении циклов регенерации состояние линий LA<23...17> неопределено и все ресурсы на шине должны поддерживать свои выходы по этим линиям в третьем состоянии. РЕКОМЕНДАЦИИ: Для "защелкивания" сигналов LA следует использовать только регистры с потенциальным входом. Это вызвано тем, что в этом случае новый истинный адрес появится на выходе регистра по началу сигнала BALE (а не по его заднему фронту) и, кроме этого, во время циклов доступа к памяти каким-либо другим задатчиком, а не ЦП, сигнал BALE поддерживается в состоянии логической "1" и регистр с потенциальным входом станет просто повторителем сигналов LA (что и требуется в таком случае). ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является задатчиком на шине, то сигналы LA<23...17> должны быть истинны до начала сигнала -MEMR или -MEMW и сохраняться таковыми до завершения цикла. -REFRESH (следует помнить, что внешняя плата может это сделать, только будучи задатчиком на шине), то вырабатывать сигналы адреса будет контроллер регенерации, поэтому внешней плате следует перевести свои адресные выходы в третье состояние. Сигнал -SBHE (System Bus High Enable - Разрешение старшего байта на системной шине) разрешается центральным процессором для указания всем ресурсам на магистрали о том, что по линиям SD<15...8> пересылается байт данных. Сигналы -SBHE и SA0 используются для определения того, какой байт и по какой половине шины данных пересылается (в соответствии с табл. 3.1). Сигнал -SBHE не вырабатывается контроллером регенерации при захвате им шины, так как никаких перестановок байтов нет и нет реального чтения данных. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата становится задатчиком на шине, то она должна вырабатывать сигнал -SBHE так же как центральный процессор. Если внешняя плата, являющаяся задатчиком на шине, вырабатывает сигнал -REFRESH , то ее выход сигнала -SBHE должен быть переведен в третье состояние. BALE Сигнал BALE (Bus Address Latch Enable - Разрешение на "защелкивание" адреса на шине) является стробом для записи адреса по линиям LA<23...17> и сообщает ресурсам на шине, что адрес является истинным и его можно "защелкнуть" в регистре. Этот сигнал также информирует ресурсы на шине о том, что сигналы SA<19...0> и -SBHE истинны. При захвате шины контроллером ПДП сигнал BALE всегда равен логической "1" (вырабатывается на материнской плате), так как сигналы LA<23...17> и SA<19...0> истинны до выработки командных сигналов. Если контроллер регенерации становится задатчиком на шине, то на линии BALE также поддерживается уровень логической единицы, поскольку сигналы адреса SA<19...0> истинны до начала командных сигналов. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ При захвате шины внешней платой сигнал BALE поддерживается материнской платой в состоянии логической "1" на все время захвата шины. Адресные сигналы LA<23...17> и SA<19...0> должны быть при этом истинны в течении времени разрешения платой командных сигналов. Если центральный процессор является задатчиком на шине и выполняет цикл доступа к ресурсу на внешней плате, то сигналы LA<23...17> истинны только в течении короткого времени, поэтому сигнал BALE должен быть использован для "защелкивания" адреса в регистре. При захвате шины любым устройством, кроме ЦП, на линии BALE поддерживается уровень логической "1". AEN Сигнал AEN (Address Enable - Разрешение адреса) разрешается тогда, когда контроллер ПДП становится задатчиком на шине и сообщает всем ресурсам на шине о том, что на шине выполняются циклы ПДП. Разрешенный сигнал AEN также информирует все устройства ввода/вывода о том, что контроллер ПДП установил адрес памяти и УВВ следует запретить на время сигнала AEN декодирование адреса. Этот сигнал запрещается, если задатчиком на шине является центральный процессор или контроллер регенерации. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата, выполняя процедуру захвата шины, вырабатывает сигнал -MASTER, сигнал AEN запрещается контроллером ПДП для того, чтобы позволить внешней плате доступ к устройствам ввода/вывода. SD<7...0> и SD<15...8> Линии SD<7...0> и SD<15...8> , как правило, еще называют шиной данных, причем по линии SD15 передается старший значащий бит, а по линии SD0 - младший значащий бит. Линии SD<7...0> - младшая половина шины данных, SD<15...0> - старшая половина шины данных. Все 8-ми разрядные ресурсы могут обмениваться данными только по младшей половине шины данных. Поддержка обмена данными между 16-ти разрядным задатчиком на шине и 8-ми разрядным ресурсом осуществляется перестановщиком байтов на материнской плате (табл. 3.1 и рис. 3.1 иллюстрирует его работу). ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если сигнал - REFRESH разрешен, то внешние платы должны перевести свои выходы по шине данных в третье состояние, так как нет пересылок данных во время циклов регенерации памяти. Сигналы этой группы управляют как продолжительностью, так и типами циклов доступа, выполняемых на шине. Группа состоит из шести командных сигналов, двух сигналов готовности и трех сигналов, которые определяют размеры и тип цикла. Командные сигналы определяют вид устройства (память или УВВ) и направление пересылки (запись или чтение). Сигналы готовности управляют продолжительностью цикла доступа, укорачивая его или, наоборот, удлиняя. -MEMR и -SMEMR Сигнал -MEMR (Memory Read - Чтение памяти) разрешается задатчиком на шине для чтения данных из памяти по адресу, определяемому сигналами по линиям LA<23...17> и SA<19...0> . Сигнал -SMEMR (System Memory Read - Системное чтение памяти) функционально идентичен -MEMR, за исключением того, что сигнал -SMEMR разрешается при чтении памяти, находящейся в пределах первого мегабайта адресного пространства. Сигнал -SMEMR -MEMR -MEMR на 10 или менее наносекунд. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ -MEMR , так как сигнал -SMEMR может разрешаться только материнской платой при чтении из памяти в первом мегабайте адресного пространства. Если внешняя плата разрешает сигнал -REFRESH -MEMR в третье состояние, так после разрешения сигнала -REFRESH контроллер регенерации будет разрешать этот сигнал. -MEMW и -SMEMW Сигнал -MEMW (Memory Write - Запись в память) разрешается задатчиком на шине для записи данных в память по адресу, определяемому сигналами по линиям LA<23...17> и SA<19...0> . Сигнал -SMEMW (System Memory Write - Системная запись в память) функционально идентичен -MEMW, за исключением того, что сигнал -SMEMW разрешается при записи в память, находящейся в пределах первого мегабайта адресного пространства. Сигнал -SMEMW вырабатывается на материнской плате из сигнала -MEMW и, поэтому, задерживается относительно сигнала -MEMR на 10 нс или менее. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата становится задатчиком на шине, то она может разрешать только сигнал -MEMW , так как сигнал -SMEMW может разрешаться только материнской платой при записи в память в первом мегабайте адресного пространства. Если внешняя плата разрешает сигнал -REFRESH , то она должна перевести свой выход по сигналу -MEMW в третье состояние. -I/OR Сигнал -I/OR (I/O Read - Чтение устройства ввода/вывода) разрешается задатчиком на шине для чтения данных из устройства ввода/вывода по адресу, определяемому сигналами SA<15...0> . ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата разрешает сигнал -REFRESH , то она должна перевести свой выход по сигналу -I/OR в третье состояние. -I/OW Сигнал -I/OW (I/O Write - Запись в устройства ввода/вывода) разрешается задатчиком на шине для записи данных в устройство ввода/вывода по адресу, определяемому сигналами SA<15...0> . ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата разрешает сигнал -REFRESH , то она должна перевести свой выход по сигналу -IOW в третье состояние. -MEM CS16 Сигнал -MEM CS16 (Memory Cycle Select - Выбор цикла для памяти) разрешается 16-разрядной памятью для сообщения задатчику шины о том, что память, к которой он обращается, имеет 16-разрядную организацию и ему следует выполнить 16-разрядный цикл доступа. Если этот сигнал запрещен, то только 8-разрядный цикл доступа может быть выполнен на шине. Память, к которой выполняется цикл доступа, должна выработать этот сигнал из адресных сигналов LA<23...17> . -MEM CS16 РЕКОМЕНДАЦИИ: Декодировав сигналы LA на внешней плате 16-разрядной памяти, следует разрешить сигнал -MEM CS16 , если установленный на шине адрес является адресом этой внешней платы. Так как этот сигнал фиксируется на материнской плате, как правило, по заднему фронту сигнала BALE , то схема дешифрации сигналов LA и последующего формирования -MEM CS16 должна иметь минимально возможную задержку (для компьютеров с тактовой частотой ЦП 20 МГц не более 20 нс). ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является 16-разрядной памятью, то она должна информировать об этом задатчика на шине, разрешив сигнал -MEM CS16 . SA<15...0> и какое-либо устройство ввода/вывода случайно при декодировании этого адреса разрешит сигнал -I/O CS16 , то внешняя плата должна игнорировать его в течении цикла доступа к памяти. -I/O CS16 Сигнал -I/O CS16 (I/O Cycle Select - Выбор цикла для УВВ) разрешается 16- разрядным УВВ для сообщения задатчику шины о том, что УВВ, к которому он обращается, имеет 16-разрядную организацию и ему следует выполнить 16-разрядный цикл доступа. Если этот сигнал запрещен, то только 8-разрядный цикл доступа к УВВ может быть выполнен на шине. УВВ, к которому выполняется цикл доступа, должна выработать этот сигнал из адресных сигналов SA<15...0> . ПРИМЕЧАНИЕ: Контроллер ПДП и контроллер регенерации игнорируют сигнал -I/O CS16 при выполнении циклов ПДП и регенерации памяти. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является 16-разрядным УВВ, то она должна информировать об этом задатчика на шине, разрешив сигнал -I/O CS16. Если внешняя плата, являясь задатчиком на шине, выработает сигналы адреса LA<23...17> и какое-либо устройство памяти случайно при декодировании этого адреса разрешит сигнал -MEM CS16 , то внешняя плата должна игнорировать его в течении цикла доступа к УВВ. I/O CH RDY Сигнал I/O CH RDY (I/O Channel Ready - Готовность канала ввода/вывода) является асинхронным сигналом, вырабатываемый тем устройством, к которому осуществляется доступ на шине. Если этот сигнал запрещен, то цикл доступа удлиняется, так как в него будут добавлены такты ожидания на время запрещения. Когда задатчиком на шине является центральный процессор или внешняя плата, то каждый такт ожидания по длительности - половина периода частоты SYSCLK (для тактовой частоты SYSCLK =8 МГц длительность такта ожидания - 62.5 нс). Если задатчиком на шине является контроллер ПДП, то каждый такт ожидания - один период SYSCLK (для SYSCLK =8 МГц - 125 нс). При обращении к памяти на внешней плате ЦП всегда автоматически вставляет один такт ожидания (если сигнал -0WS запрещен), поэтому, если внешней плате достаточно времени цикла с одним тактом ожидания, то запрещать сигнал I/O CH RDY не требуется. ПРИМЕЧАНИЕ: При выполнении циклов ПДП устройства ввода/вывода не должны вырабатывать этот сигнал, так как УВВ разрешает сигнал DRQ только после того, как истинные данные могут быть приняты или посланы УВВ и необходимости в дополнительном управлении длительностью цикла по сигналу I/O CH RDY нет. Только устройства памяти во время циклов ПДП могут разрешать этот сигнал. ВНИМАНИЕ: Сигнал I/O CH RDY не может быть запрещен на время больше чем 15 мкс, так как при нарушении этого требования возможна потеря данных в микросхемах динамической памяти. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является задатчиком на шине, то она должна принимать и анализировать сигнал I/O CH RDY при выполнении ей циклов доступа к другим ресурсам. При работе внешней платы в других режимах она должна разрешать этот сигнал в том случае, когда она готова завершить цикл. I/O CH RDY и выполняют все циклы доступа как обычные циклы доступа к 8- или 16-разрядной памяти. Поэтому, устанавливая в компьютер внешнюю плату, которая требует удлинения цикла доступа по сигналу I/O CH RDY , следует обязательно убедиться в отсутствии в компьютере такой некорректно разработанной внешней платы. -0WS Сигнал -0WS (0 Wait States - 0 тактов ожидания) является единственным на всей шине сигналом, который требует при приеме его задатчиком на шине синхронизации с частотой SYSCLK . Он разрешается ресурсом, к которому осуществляется доступ центральным процессором или внешней платой, и информирует задатчика на шине о том, что цикл доступа должен быть завершен без вставки такта ожидания. ПРИМЕЧАНИЕ: Несмотря на то, что этот сигнал присоединен к слоту для 8- разрядных плат, он не может быть использован 8-разрядным ресурсом. Он может быть использован только при доступе к 16-разрядной памяти, установленной в слот, когда центральный процессор или внешняя плата являются задатчиком на шине. Этот сигнал игнорируется при доступе к УВВ или когда контроллер ПДП или контроллер регенерации являются задатчиком на шине. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является задатчиком на шине, то она должна принимать сигнал -0WS от ресурсов, к которым она осуществляет доступ и выполнять циклы доступа с такими ресурсами без дополнительных тактов ожидания. Когда внешняя плата является 16-разрядной памятью, то она должна разрешать сигнал -0WS , если быстродействие этой памяти позволяет выполнять циклы доступа к ней без вставки дополнительного такта ожидания. ВНИМАНИЕ! К сожалению, некоторые внешние платы, став задатчиком на шине, игнорируют сигнал -0WS и выполняют все циклы доступа как обычные циклы доступа к 8- или 16-разрядной памяти. -REFRESH Сигнал -REFRESH (Refresh - регенерация) разрешается контроллером регенерации для информирования всех устройств на шине о том, что выполняются циклы регенерации памяти. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если внешняя плата является задатчиком на шине, то она должна разрешать сигнал -REFRESH для запроса на регенерацию памяти. При этом цикл регенерации будет выполнен даже несмотря на то, что контроллер регенерации не является задатчиком на шине. Группа центральных сигналов управления состоит из сигналов различных частот, сигналов управления и ошибок. Сигнал -MASTER (Master - Ведущий) должен вырабатываться только той внешней платой, которая желает стать задатчиком на шине. ВНИМАНИЕ! Если сигнал -MASTER разрешен на время более 15 мкс, то внешняя плата должна запросить цикл регенерации памяти, разрешив сигнал -REFRESH . ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Сигнал -MASTER разрешается внешней платой, становящейся задатчиком на шине, только после приема ей соответствующего сигнала -DACK от контроллера ПДП. После того, как сигнал -MASTER будет разрешен, внешняя плата должна ждать минимум один период частоты SYSCLK , прежде чем начать выработку сигналов адреса и данных и минимум два периода SYSCLK до выработки командных сигналов. -I/O CH CK Сигнал -I/O CH CK (I/O Channel Check - Проверка Канала Ввода/вывода) может быть разрешен любым ресурсом на шине как сообщение о фатальной ошибке, которая не может быть исправлена. Типичный пример такой ошибки - ошибка четности при доступе к памяти. Сигнал - I/O CH CK должен быть разрешен на время не менее 15 нс. Если в момент выработки этого сигнала задатчиком на шине являлся контроллер ПДП или контроллер регенерации, то сигнал -I/O CH CK будет записан в регистр на материнской плате, а обработан только после того, как центральный процессор станет задатчиком на шине. Этот сигнал, как правило, соединен со входом немаскированного прерывания ЦП и его выработка приводит к прекращению нормальной работы компьютера. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Если сигнал -I/O CH CK разрешается в тот момент, когда задатчиком на шине является внешняя плата, то он записывается в регистр на материнской плате и будет обработан только после захвата шины центральным процессором. RESET DRV Сигнал RESET DRV (Reset Driver - Сброс Устройства) вырабатывается центральным процессором для начальной установки всех ресурсов доступа на шине после включения питания или падения его напряжения. Минимальное время разрешения этого сигнала - 1 мс. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Внешние платы на все время выработки этого сигнала должны перевести свои выходы в третье состояние. SYSCLK Сигнал SYSCLK (System Clock - системная частота) в данной книге принимается равной 8 МГц, хотя, как правило, эта частота такая же, как и тактовая частота центрального процессора на материнской плате, но с 50% (по длительности) уровнем логической "1". Все циклы шины пропорциональны SYSCLK , но все сигналы на шине, за исключением -0WS , не синхронизированы с SYSCLK . ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Когда внешняя плата является задатчиком на шине, она может использовать SYSCLK для задания длины цикла, но кроме как для выработки -0WS любой сигнал для синхронизации может быть использован. OSC Сигнал OSC вырабатывается материнской платой всегда фиксированной частотой 14.3818 МГц с 45-55% (по длительности) уровнем логической "1". Сигнал OSC не синхронизирован ни с SYSCLK ни с каким-либо другим сигналом на шине и поэтому не может быть использован для применений, требующих синхронизации с другими сигналами. Исторически этот сигнал появился для поддержки первых контроллеров цветных мониторов для персональных компьютеров серии IBM PC. Этот сигнал удобен для использования внешними платами, поскольку он одинаков для всех моделей компьютеров, совместимых с IBM PC/AT. Группа сигналов прерывания используется для запроса на прерывание центрального процессора. ПРИМЕЧАНИЕ: Обычно сигналы запроса на прерывания присоединены к контроллеру прерываний типа Intel 8259A. Несмотря на то, что доступ к контроллерам прерываний (как к УВВ) имеет любой задатчик на шине, для совместимости программного обеспечения только центральный процессор может обслуживать контроллер прерываний. IRQ<15,14,12,11,10> IRQ<9,7...3> Прерывание может быть запрошено ресурсами как на материнской плате, так и на внешних платах разрешением соответствующего сигнала IRQ . Сигнал должен оставаться разрешенным до подтверждения прерывания центральным процессором, которое, как правило, заключается в доступе ЦП к ресурсу, запросившему прерывание. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Запрос на прерывание записывается в триггер в контроллере прерываний по нарастающему фронту сигнала запроса на прерывание и должен вырабатываться микросхемами с обычными ТТЛ выходами. Поэтому, выбирая линию запроса на прерывание для своей внешней платы, следует убедиться, что эта линия не занята какой-либо другой внешней платой. Эти сигналы поддерживают циклы пересылки данных при прямом доступе в память. ПРИМЕЧАНИЕ: Каналы ПДП <3...0> поддерживают только пересылки 8-разрядных данных. Каналы ПДП <7...5> поддерживают пересылки только 16-разрядных данных. DRQ<7...5,0> DRQ<3,2,1> Сигналы DRQ (DMA Request - запрос на ПДП) разрешаются ресурсами на материнской плате или внешними платами для запроса на обслуживание контроллером ПДП или для захвата шины. Сигнал DRQ должен быть разрешен до тех пор, пока контроллер ПДП не разрешит соответствующий сигнал -DACK . ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Сигналы DRQ вырабатываются с выходов обычных ТТЛ микросхем, поэтому при установке внешней платы в слот шины ISA следует правильно выбрать канал ПДП, который не должен быть занят другими внешними платами. -DACK<7...5,0> -DACK<3,2,1> Сигналы -DACK (DMA Acknowledge - подтверждение ПДП) разрешаются контроллером ПДП как подтверждение сигналов запросов DRQ<7...5,3...0> . Разрешение соответствующего сигнала -DACK означает, что либо циклы ПДП будут начаты, либо внешняя плата захватила шину. T/C Сигнал T/C (Terminal Count - Окончание счета) разрешается контроллером ПДП тогда, когда по какому-либо из каналов ПДП будет окончен счет числа пересылок данных, то есть все пересылки данных выполнены. Для питания внешних плат на шине ISA используются 5 напряжений питания постоянного тока: +5 В, -5 В, +12 В, -12 В, 0 В (корпус - Ground). Все линии питания заведены на 8-разрядный разъем, кроме одной линии по +5 В и одной линии корпуса на дополнительном разъеме. Максимально допустимые токи потребления для внешней платы по каждому напряжению питания приведены в табл. 4.1. Таблица 4.1. Максимальные токи потребления внешней платой
ВНИМАНИЕ! Данные, приведенные в табл. 4.1, не означают, что каждая из установленных в слоты внешних плат может потреблять такие токи. Таблица информирует только о том, какие токи разрешается пропускать через разъем (разъемы) внешней платы. Общие допустимые токи потребления для всех внешних плат как правило, ограничиваются источником питания компьютера. Поэтому, до установки новой внешней платы в слот шины следует определить наличие соответствующего резерва по токам потребления для этой платы у источника питания компьютера. Циклы шины ISA всегда асинхронны по отношению к SYSCLK . Различные сигналы разрешаются и запрещаются в любое время; внутри допустимых интервалов сигналы отклика могут также быть выработаны в любое время. Исключением является только сигнал -0WS , который должен быть синхронизирован с SYSCLK . На шине существуют 4 индивидуальных типа циклов: Доступ к Ресурсу , ПДП , Регенерация , Захват Шины . Цикл Доступа к Ресурсу выполняется, если центральный процессор или внешняя плата в качестве задатчиков обмениваются данными с различными ресурсами на шине. Цикл ПДП выполняется, если контроллер ПДП является задатчиком на шине и выполняет циклы передачи данных между памятью и УВВ. Цикл Регенерации выполняется только контроллером регенерации для регенерации микросхем динамической памяти. Цикл Захвата Шины выполняется внешней платой для того, чтобы стать задатчиком на шине. Структурно циклы отличаются по типу задатчика на шине и видами ресурсов доступа на ней. Внутри типа цикла существуют различные виды его, обусловленные различной продолжительностью каждого вида. Существуют три типа цикла Доступа к Ресурсу : цикл с 0 тактов ожидания - этот цикл наиболее короткий из всех возможных; нормальный цикл - при выполнении такого цикла ресурс доступа не запрещает сигнал готовности I/O CH RDY - далее цикл такого вида будет называться просто нормальным; удлиненный цикл - при выполнении такого цикла ресурс доступа запрещает сигнал готовности I/O CH RDY на время, необходимое ресурсу для приема или передачи данных - далее цикл такого вида будет называться удлиненным. В циклах ПДП и Регенерация тоже существуют два вида: нормальный и удлиненный, исходя из таких же, описанных выше условий.Ниже все типы циклов будут подробно описаны и, кроме этого, в гл. 6 приведены временные диаграммы всех типов циклов. Центральный процессор начинает цикл Доступа к Ресурсу выработкой сигнала BALE , сообщающего всем ресурсам об истинности адреса на линиях SA<19...0> , а также для фиксации ресурсами адреса по линиям LA<23...17> . Ресурсы должны сообщать ЦП разрешением сигнала -MEM CS16 или -I/O CS16 о том, что цикл должен быть 16- разрядным; иначе цикл будет завершен как 8-разрядный. ЦП также вырабатывает команды -MEMR , -MEMW , -IORC и -IOWC определяющие тип ресурса (память или УВВ), а также направление передачи данных. Если доступ к памяти в первом мегабайте адресного пространства, то также будет разрешаться сигнал -SMEMR или -SMEMW . Ресурс доступа, которому необходимо изменить время цикла, должен отвечать сигналом -0WS или I/O CH RDY для информирования ЦП о продолжительности цикла доступа. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Внешняя плата, захватившая шину, также начинает цикл доступа с выработки адресных сигналов, но, в отличии от ЦП, не подтверждает адрес сигналом BALE . На линии этого сигнала поддерживается материнской платой на все время захвата шины внешней платой уровень логической "1". Поэтому внешняя плата должна выработать истинные сигналы как по линиям SA<19...0> так и по линиям LA<23...17> до начала разрешения командных сигналов, сохраняя адрес до конца цикла. Внешняя плата также должна иметь возможность анализа сигналов -MEM CS16 и -I/O CS16 и в соответствии с этими сигналами завершать цикл как 16- или 8-разрядный. Цикл доступа с 0 тактов ожидания - наиболее короткий цикл из всех возможных на шине. Этот цикл может быть выполнен только при доступе ЦП или внешней платы (когда она задатчик на шине) к 16-разрядной памяти. В начале цикла задатчик должен установить адрес на линиях LA<23...17> для выбора блока памяти в 128 Кб. Если затем не будет разрешен сигнал -MEM CS16 , то цикл будет завершен как 8-разрядный (нормальный или удлиненный) и цикл с 0 тактов ожидания не будет выполнен. Если ресурсом будет разрешен сигнал -MEM CS16 , то затем он должен разрешить сигнал -0WS в соответствующее время после выдачи командного сигнала -MEMR или -MEMW для завершения цикла с 0 тактов ожидания. При запрещении сигнала -0WS цикл завершается как нормальный или удлиненный. ПРИМЕЧАНИЯ: Если сигнал -0WS разрешается ресурсом доступа, то задатчик не требует разрешения сигнала I/O CH RDY - он игнорируется. Только сигнал -0WS является на шине ISA синхронным по отношению к SYSCLK сигналом. ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Внешняя плата, захватившая шину, выполняет цикл доступа с 0 тактов ожидания точно также как центральный процессор. Нормальный цикл может быть выполнен ЦП или внешней платой (если она владеет шиной) при доступе к 8- или 16-разрядному УВВ или к памяти. После выдачи на шину сигналов адреса задатчик разрешает командные сигналы -MEMR , -MEMW , -I/OR или -I/OW . В ответ ресурс должен разрешить сигнал I/O CH RDY в соответствующее время, так как иначе цикл будет завершен как удлиненный. Разрешение I/O CH RDY заставляет задатчика завершить цикл за фиксированный период времени (этот период кратен периоду SYSCLK , но не синхронизирован с ним). Длительность нормального цикла определяется временем разрешения сигналов -MEMR , -MEMW , -I/OR или -I/OW которое, в свою очередь, зависит от размера данных и адреса ресурса доступа. Удлиненный цикл может быть выполнен ЦП или внешней платой (если она владеет шиной) при доступе к 8- или 16-разрядному УВВ или к памяти. Задатчик на шине выполняет удлиненный цикл в том случае, если ресурс, к которому осуществляется доступ, не разрешает в соответствующее время после разрешения командного сигнала сигнал I/O CH RDY . Задатчик продолжает разрешать командный сигнал до тех пор, пока ресурс не разрешит сигнал I/O CH RDY . Период времени удлиненного цикла также кратен SYSCLK Контроллер регенерации пытается захватить шину по истечении 15 мкс с последнего цикла регенерации двумя способами: если шиной владеет центральный процессор, то он по завершении выполнения текущей команды передает шину контроллеру регенерации; если шиной владеет контроллер ПДП, то шина будет передана контроллеру регенерации только по завершении циклов пересылки данных контроллером ПДП. Назначение следующих сигналов во время цикла регенерации имеют оригинальную интерпретацию: -REFRESH - разрешение этого сигнала сообщает о начале цикла регенерации; Адрес - контроллер регенерации вырабатывает только сигналы по линиям адреса SA<7...0>, остальные сигналы адреса не определены; -MEMR - сигнал -MEMR разрешается контроллером регенерации, при этом сигнал -SMEMR будет разрешен материнской платой; SD<15...0> - линии данных игнорируются контроллером регенерации и все ресурсы на шине обязаны перевести свои выходы по линиям данных в третье состояние; Эти сигналы игнорируются контроллером регенерации: -MEM CS16 -I/O CS16 ОСОБЕННОСТИ ДЛЯ ВНЕШНИХ ПЛАТ Когда внешняя плата является задатчиком на шине, она должна самостоятельно разрешать сигнал -REFRESH для запуска цикла регенерации памяти. Нормальный цикл регенерации контроллер регенерации начинает с разрешения сигнала -MEMR , в ответ ресурс должен разрешить сигнал I/O CH RDY в соответствующее время, так как иначе цикл будет завершен как удлиненный. Длину цикла фактически определяет только продолжительность сигнала -MEMR . Удлиненный цикл контроллер регенерации выполняет в том случае, если хотя бы один ресурс доступа не разрешает сигнал I/O CH RDY в соответствующее время после разрешения сигнала -MEMR . Контроллер регенерации продолжает разрешать сигнал -MEMR до того, как сигнал I/O CH RDY будет разрешен всеми ресурсами на шине. Период времени удлиненного цикла также кратен SYSCLK , но не синхронизирован с ним. Цикл ПДП подобен циклу доступа, который выполняет другой владелец шины. Циклы ПДП запускаются после разрешения сигнала -DACK контроллером ПДП. Размер передаваемых данных зависит от используемого канала ПДП: каналы с 0 по 3 определены для 8-разрядных пересылок данных, а каналы с 5 по 7 для 16-разрядных пересылок данных. Сигналы -MEM CS16 и -I/O CS1 6 игнорируются самим контроллером ПДП, но эти сигналы использует перестановщик байтов на материнской плате. Циклы ПДП выполняются только между памятью и устройствами ввода/вывода. Сигналы адреса, вырабатываемые контроллером ПДП, содержат только адрес памяти и не содержат адрес УВВ. Процесс пересылки данных в цикле ПДП выполняется так: источник данных выставляет данные на шине, а приемник данных должен быть готов их принять в это же самое время. Команды записи и чтения также разрешаются одновременно для правильного выбора направления пересылки. При этом сигнал чтения обязательно разрешается раньше, чем сигнал записи во избежание столкновения между буферами данных в двух ресурсах. УВВ, запрашивающее режим ПДП на шине, разрешает сигнал DRQ соответствующего канала. Если задатчиком на шине является центральный процессор, то он освобождает шину контроллеру ПДП, который, в свою очередь, извещает УВВ разрешением сигнала -DACK о том, что начинается цикл ПДП. Так как контроллер ПДП вырабатывает только адрес памяти, УВВ должно использовать сигналы -I/OR , -I/OW и -DACK для приема или передачи данных в режиме ПДП. Цикл ПДП начинается с разрешения сигнала -DACK соответствующего канала, а также сигнала AEN . Разрешением сигнала AEN контроллер ПДП извещает все ресурсы на шине о том, что адреса и командные сигналы вырабатываются контроллером ПДП, а не центральным процессором, контроллером регенерации или внешней платой. После разрешения командных сигналов контроллер ПДП анализирует сигнал I/O CH RDY для определения длительности цикла. Если цикл удлиняется, то период удлинения кратен удвоенному периоду SYSCLK , хотя и не синхронизирован с SYSCLK . ПРИМЕЧАНИЕ: Данные, которые записываются в память или УВВ, должны быть истинны до разрешения команды записи и оставаться истинными до запрещения команды записи. Нормальный цикл выполняется контроллером ПДП для 8- или 16-разрядных пересылок данных. Контроллер ПДП разрешает сигналы -MEMR , -MEMW , -I/OR и -I/OW , а память, с которой выполняется обмен, должна разрешить сигнал I/O CH RDY в соответствующее время, иначе цикл будет завершен как удлиненный. Разрешение сигнала I/O CH RDY заставляет контроллер завершить цикл за фиксированный период времени; этот период кратен периоду SYSCLK , но не синхронизирован с ним. Продолжительность разрешения сигналов -MEMR , -MEMW , -I/OR и -I/OW определяет продолжительность всего цикла, причем эта продолжительность зависит от размера данных для различных адресных пространств. Удлиненный цикл ПДП выполняется контроллером ПДП также как и нормальный цикл, за исключением того, что при удлиненном цикле сигнал I/O CH RDY не разрешается в соответствующее время после того, как командный сигнал будет разрешен. Контроллер ПДП продолжает разрешать командные сигналы до тех пор, пока УВВ не разрешит сигнал I/O CH RDY . Период времени, на который удлиняется цикл, в этом случае кратен удвоенному периоду SYSCLK , хотя и не синхронен с SYSCLK . ПРИМЕЧАНИЕ: Сигналы адреса LA<23...0> во время обычного цикла доступа должны записываться в регистр ресурсами доступа для запоминания адреса в течении всего цикла. В отличие от обычных циклов, при выполнении циклов ПДП эти адресные сигналы истинны в течении всего цикла ПДП. ВНИМАНИЕ! Каналы ПДП, которые используются внешними платами для захвата шины, должны быть запрограммированы в каскадном режиме. Любая внешняя плата, установленная в слот, может стать задатчиком на шине ISA. Захват шины внешняя плата должна начать с разрешения сигнала DRQ канала ПДП, предварительно запрограммированного в каскадный режим. Канал ПДП, запрограммированный в каскадном режиме, считает, что все циклы ПДП были выполнены внешним ресурсом - в данном случае внешней платой. Контроллер ПДП отвечает внешней плате разрешением сигнала -DACK ; внешняя плата в ответ на -DACK разрешает сигнал -MASTER . После разрешения сигнала -MASTER внешняя плата должна ждать некоторое время, после чего может начинать свои циклы доступа. | ||||||||||||||||||||||||
ISA Bus (Industry Standard Architecture) - шина расширения, применявшаяся с первых моделей PC и ставшая промышленным стандартом, В компьютере XT использовалась шина с разрядностью данных 8 бит и адреса - 20 бит. В компьютерах AT ее расширили до 16 бит данных и 24 бит адреса. Конструктивно, как показано на рис. 6.1, шина выполнена в виде двух щелевых разъемов с шагом выводов 2,54 мм (0,1 дюйма). В подмножестве ISA-8 используется только 62-контакт¬ный слот (ряды А, В), в ISА-16 применяется дополнительный 36-контактный слот (ряды С, D). Шина РС/104, разработанная для встраиваемых контроллеров на базе PC, отличается от обычной ISA только конструктивно. В шине EISA - дорогом 32-разрядном расширении ISA - используется «двухэтажный» слот, позволяющий устанавливать и обычные карты ISA.
Для шины ISA выпущено (и продолжает выпускаться) огромное количество разнообразных карт расширения. Ряд фирм выпускает карты-прототипы (Prototype Card), представляющие собой печатные платы полного или уменьшенного формата с крепежной скобой. На платах установлены обязательные интерфейсные цепи - буфер данных, дешифратор адреса и некоторые другие. Остальная часть платы свободна, и здесь разработчик может разместить макетный вариант своего устройства. Эти платы удобны для проверки нового изделия, а также для монтажа единичных экземпляров устройства, когда разработка и изготовление печатной платы нерентабельно.
Рис. 26 Слот ISA
В каждый момент времени шиной может управлять только одно устройство-задатчик, обращающееся к ресурсам (портам или ячейкам памяти) устройств-исполнителей. Шина ISA обеспечивает возможность обращения к 8- или 16-битным регистрам устройств, отображенным на пространства ввода-вывода и памяти. Диапазон адресов памяти для устройств ограничен областью верхней памяти UM А (АОООО-FFFFFh). Для шины ISA-16 настройками CMOS Setup может быть разрешено пространство между 15-м и 16-м мегабайтом памяти (при этом компьютер не сможет использовать более 15 Мбайт ОЗУ). Для шины ISA диапазон адресов ввода-вывода сверху ограничен количеством задействованных для дешифрации бит адреса, нижняя областью адресов О-FFh недоступна (зарезервирована под устройства системной платы). В PC была принята 10-битная адресация ввода-вывода, при которой линии адреса А устройствами игнорировались. Таким образом, диапазон адресов устройств шины ISА ограничивается областью lOOh-3FFh. Впоследствии стали применять 12-битную адресацию (диапазон lOOh-FFFh). При этом приходится учитывать возможность присутствия на шине старых 10-битных адаптеров, которые «отзовутся» на адрес с подходящими ему битами А во всей допустимой области 12-битного адреса четыре раза (у каждого 10-битного адреса будет еще по три 12-битных псевдонима). Полный 16-битный адрес используется только в шинах EISA и PCI.
Шина ISA-8 может предоставить до 6 линий запросов прерываний, ISА-16 - 11. Часть из них могут «отобрать» устройства системной платы или шина PCI.
Шина ISA-8 позволяет использовать до трех 8-битных каналов DMA. На 16-бит¬ной шине доступны еще три 16-битных и один 8-битный канал.
Все перечисленные ресурсы шины должны быть бесконфликтно распределены. Бесконфликтность подразумевает выполнение перечисленных ниже условий.
- Каждое устройство-исполнитель должно управлять шиной
данных только при чтении по его адресам или по используемому им каналу DMA. Области адресов, по которым выполняется чтение регистров различных устройств, не должны пересекаться. Поскольку при записи шиной данных управляет лишь текущий задатчик, возможность конфликтов, приводящих к искажениям данных, исключена. «Подсматривать» операции записи, адресованные не данному устройству, не возбраняется.
- Назначенную линию IRQx или DRQx устройство должно
держать на низком уровне в пассивном состоянии и переводить в высокий уровень для активации запроса. Неиспользуемыми линиями запросов устройство управлять не имеет права, они должны электрически отсоединяться или подключаться к буферу, находящемуся в третьем состоянии. Одной линией запроса может пользоваться только одно устройство. Такая нелепость (с точки зрения схемотехники ТТЛ) была допущена в первых PC и из требований совместимости тиражируется до сих пор.
Задача распределения ресурсов для старых адаптеров решалась с помощью джамперов, затем появились программно конфигурируемые устройства, которые вытесняются автоматически конфигурируемыми платами PnP.
Назначение контактов слотов шин ISA и EISA приведено в таблице
Таблица 11. Основной разъем шин ISA-8, ISA-16 и EISA
| Ряд В | № | Ряд А |
| GND | IOCHK# | |
| Reset | SD7 | |
| 5 В | SD6 | |
| IRQ2/9" | SD5 | |
| -5 В | SD4 | |
| DRQ2 | SD3 | |
| -12В | SD2 | |
| OWS# 2 | SD1 | |
| +12В | SDO | |
| GND | IOCHDRY | |
| SMEMW# | AEN | |
| SMEMR# | SA19 | |
| IOWR# | SA18 | |
| IORD# | SA17 | |
| DACK3# | SA16 | |
| DRQ3 | SA15 | |
| DACK1# | SA14 | |
| DRQ1 | SA13 | |
| REFRESH» | SA12 | |
| BCLK | SA11 | |
| IRO7 | SA10 | |
| IRQ6 | SA9 | |
| IRQ5 | SA8 | |
| IRQ4 | SA7 | |
| IRQ3 | SA6 | |
| DACK2# | SA5 | |
| C | SA4 | |
| BALE | SA3 | |
| +5 В | SA2 | |
| Osc | SA1 | |
| GND | SA0 |
1 В4: XT=IRQ2, AT=IRQ9.
2 В8: XT-Card Selected.
Таблица 12. Дополнительный разъем шин ISA-16 и ЕISA
| Ряд O | № | Ряд C |
| MEMCS16# | SBHE# | |
| IOCS16# | LA23 | |
| IRQ10 | LA22 | |
| IRQ 11 | LA21 | |
| IRQ12 | LA20 | |
| IRQ 15 | LA19 | |
| IRQ14 | LA18 | |
| DACKO# | LA17 | |
| DRQO | MEMR# | |
| DACK5# | MEMW# | |
| DRQ5 | SD8 | |
| DACK6# | SD9 | |
| DRQ6 | SD10 | |
| DACK7# | SD11 | |
| DRQ7 | SD12 | |
| +5B | SD13 | |
| MASTER* | SD14 | |
| GND | SD15 |
Сигналы шины ISA естественны для периферийных микросхем фирмы Intel (в стиле семейства 8080). Набор сигналов ISA-8 предельно прост. Программное обращение к ячейкам памяти и пространства ввода-вывода обеспечивают следующие сигналы:
- SD - шина данных. Иное название сигналов - Data или D.
- SA (Addr, A) - шина адреса.
- AEN - разрешение адресации портов (запрещает ложную
дешифрацию адреса в цикле DMA).
- IOW# (IOWC#, IOWR#) - запись в порт.
- IOR# (IORC#, IORD#) - чтение порта.
- SMEMW* (SMEMWR#, SMWTC#) - запись в системную
память (в диапазоне адресов 0-FFFFFh).
- SMEMR* (SMEMRD#, SMRDC#) - чтение системной
памяти (в диапазоне адресов 0-FFFFFh).
Ниже перечислены сигналы, относящиеся к сигналам запросов прерывания и каналам прямого доступа к памяти.
- IRQ2/9, IRQ - запросы прерываний. Положительный
перепад сигнала вызывает запрос аппаратного прерывания. Для идентификации источника высокий уровень должен сохраняться до подтверждения прерывания процессором, что затрудняет разделение (совместное использование) прерываний. Линия IRQ2/9 в шинах XT вызывает аппаратное прерывание с номером 2, а в AT - с номером 9.
- DRQ - запросы 8-битных каналов DMA
(положительным перепадом).
- DACK# - подтверждение запросов 8-битных каналов
- ТС - признак завершения счетчика циклов DMA.
Шина имеет и несколько служебных сигналов синхронизации, сброса и регенерации памяти, установленной на адаптерах.
- IOCHRDY (CHRDY, I/OCHRDY) - готовность устройства,
низкий уровень удлиняет текущий цикл (не более 15 икс).
- BALE (ALE) - разрешение защелки адреса. После его
спада в каждом цикле процессора линии SA гарантированно содержат действительный адрес.
- REFRESH* (REF#) - цикл регенерации памяти (в XT
называется DACKO#).
Сигнал появляется каждые 15 мкс, при этом шина адреса указывает на очередную регенерируемую строку памяти.
- ЮСНК# - контроль канала, низкий уровень вызывает NMI
CPU (разрешение и индикация в системных портах 061h, 062h).
- RESET (RESDRV, RESETDRV) - сигнал аппаратного
сброса (активный уровень - высокий).
- BCLK (CLK) - синхронизация шины с частотой около 8
МГц. ПУ могут не использовать этот сигнал, работая только по управляющим сигналам записи и чтения.
- OSC - несинхронизированная с шиной частота 14,431818
МГц (использовалась старыми дисплейными адаптерами).
Кроме логических сигналов шина имеет контакты для разводки питания +5, -5, +12 и-12 В.
Дополнительный разъем, расширяющий шину до 16-битной, содержит линии данных, адреса, запросов прерываний и каналов прямого доступа.
- SD - шина данных.
- SBHE# - признак наличия данных на линиях SD.
- LA - нефиксированные сигналы адреса, требующие
защелкивания по спаду сигнала BALE. Такой способ подачи адреса позволяет сократить задержку. Кроме того, схемы дешифратора адреса памяти плат расширения начинают декодирование несколько раньше спада BALE.
- IRQ, IRQ - дополнительные запросы
прерываний.
- DRQ - запросы 16-битных каналов DMA
(положительным перепадом).
- DACK# - подтверждение запросов 16-битных каналов
- DRQO и DACKO* - запрос и подтверждение 8-битного
канала DMA, освободившегося от регенерации памяти.
Перечисленные ниже сигналы связаны с переключением разрядности данных.
- МEMCS16#(М16#) - адресуемое устройство поддерживает
16-битные обращения к памяти.
- IOCS16* (I/OCS16*, Ю16#) - адресуемое устройство
поддерживает 16-битные обращения к портам.
К новым управляющим сигналам относятся следующие.
- MEMW# (MWTC#) - запись в память в любой области до
- MEMR# (MRDC#) - чтение памяти в любой области до 16
- OWS# (SRDY#, NOWS#, ENDXFR) - укорочение текущего
цикла по инициативе адресованного устройства.
- MASTER* (MASTER 16#) - запрос от устройства,
использующего 16-битный канал DMA на управление шиной. При получении подтверждения DACK Bus-Master может захватить шину.
Для передачи данных от исполнителя к задатчику предназначены циклы чтения ячейки памяти или порта ввода-вывода, для передачи данных от задатчика к исполнителю - циклы записи ячейки памяти или порта ввода-вывода. В каждом цикле текущий (на время данного цикла) задатчик формирует адрес обращения и управляющие сигналы, а в циклах записи еще и данные на шине. Адресуемое устройство-исполнитель в соответствии с полученными управляющими сигналами принимает (в цикле записи) или формирует (в цикле чтения) данные. Также оно может, при необходимости, управлять длительностью цикла и разрядностью передачи. Обобщенные временные диаграммы циклов чтения или записи памяти или ввода-вывода приведены на рис. 6.2. Здесь условный сигнал CMD* изображает один из следующих сигналов:
- SMEMR#, MEMR# - в цикле чтения памяти;
- SMEMW#, MEMW# - в цикле записи памяти;
- IOR# - в цикле чтения порта ввода-вывода;
- IOW# - в цикле записи порта ввода-вывода.
В каждом из рассматриваемых циклов активными (с низким уровнем) могут быть только сигналы лишь из одной строки данного списка, и во время всего цикла сигнал AEN имеет низкий уровень. Цикл прямого доступа к памяти, в котором это правило не соблюдается, рассмотрен ниже, и в таком цикле сигнал AEN будет иметь высокий уровень. Сигналы SMEMR* и SMEMW* вырабатываются из сигналов MEMR# и MEMW# соответственно, когда адрес принадлежит диапазону О-FFFFFh. Поэтому сигналы SMEMR* и SMEMW* задержаны относительно MEMR# и MEMW* на 5-10 не.

Рис. 27. Временные диаграммы циклов чтения или записи на шине ISA
В начале каждого цикла контроллер шины устанавливает адрес обращения: на линиях SA и SBHE# действительный адрес сохраняется на время всего текущего цикла; на линиях 1_А адрес действителен только в начале цикла, так что требуется его «защелкивание». Каждое устройство имеет дешифратор адреса - комбинационную схему, срабатывающую только тогда, когда на шине присутствует адрес, относящийся к данному устройству. В фазе адресации устройства еще «не знают», к какому из пространств (памяти или ввода-вывода) относится выставленный адрес. Но дешифраторы адресов уже срабатывают, и, когда в следующей фазе шина управления сообщает тип операции, адресуемое устройство уже оказывается готовым к ее исполнению. Если устройство использует линии LA (они нужны лишь для обращений к памяти выше границы FFFFFh), то они на дешифратор адреса должны проходить через регистр-защелку, «прозрачный» во время действия сигнала BALE и фиксирующий состояние выходов по его спаду. Это позволяет дешифратору, всегда вносящему некоторую задержку, начинать работу раньше, чем поступит управляющий сигнал чтения или записи. При обращении к портам ввода-вывода сигналы 1_А не используются.
Если устройство имеет более одного регистра (ячейки), то для выбора конкретного регистра (ячейки) ему требуется несколько линий адреса. Как правило, старшие биты шины адреса поступают на вход дешифраторов адреса, формирующих сигналы выборки устройств, а младшие биты - на адресные входы самих устройств. Тогда каждое устройство в пространстве будет занимать наиболее компактную область смежных адресов размером в 2П байт, где п - номер младшей линии адреса, поступающей на дешифратор. Из них реально необходимы 2Ш адресов, где m - номер самой старшей линии адреса, участвующей в выборе регистра устройства. В идеале должно быть n=m+l: при большем значении п отведенное (по дешифратору) пространство адресов не будет использовано полностью и регистры устройства будут повторяться в отведенной области 2n"m"1 раз, то есть у них появятся адреса-псевдонимы (alias). Адреса-псевдонимы будут отличаться от истинного адреса (минимального из всех псевдонимов) на Kx2m+1, где К - целое число. Меньшее значение п недопустимо, поскольку тогда не все регистры устройства будут доступны задатчику. В принципе можно использовать дешифратор адреса, срабатывающий только на какой-то части адресов из области 2П (не кратной степени двойки), если устройству требуется «неудобное» количество регистров. Однако на практике «фигурное выпиливание» областей из пространства адресов обычно не делают, так что часть адресов может пропадать бесполезно.
Разрядность данных в каждом цикле обращения определяется потребностями текущего задатчика и возможностями исполнителя. В IBM PC/XT и системная шина, и шина ISA были 8-разрядными, так что вопросов согласования разрядности не возникало. В IBM PC/AT286 (и 386-SX) системная шина уже 16-разрядная, и в современных ПК с 32- и 64-разрядными системными шинами контроллер шины ISA является ее 16-разрядным задатчиком. На системной плате имеется «косой буфер», он же перестановщик байтов, который при необходимости транслирует данные с младшего байта шины на старшую или обратно. Логика управления этим буфером использует сигналы SBHE#, SAO, IOCS16* и MEMCS16*. Поддержка 16-разрядных передач сообщается адресуемым исполнителем сигналами IOCS16* и MEMCS16* при срабатывании его дешифратора адреса. Сигнал IOCS16# влияет только на разрядность обращений к портам, MEMCS16* - к памяти. Все операции обмена (транзакции) начинаются задатчиком единообразно, поскольку он еще не «знает» возможностей исполнителя. Развитие событий зависит от намерений задатчика и полученных сигналов разрешения 16-битных передач. В чисто 16-разрядных машинах начальный адрес однозначно соответствует передаваемому байту или младшему байту передаваемого слова1. В машинах с 32-разрядными процессорами начальный адрес, выставляемый на шине в начале транзакции, зависит от разрядности данных, запланированной задатчиком, и может зависеть от положения адресуемых данных относительно границы двойного слова (32 битного). 16-разрядные передачи выполняются за 1 цикл только при условии передачи по четному адресу (АСНО) и при ответе исполнителя сигналом IOCS16* или MEMCS16*, в иных случаях они разбиваются на два цикла. 32-разрядные передачи будут разбиваться на 2 (16+16), 3 (8+16+8) или 4 (8+8+8+8) цикла, в зависимости от возможностей исполнителя и четности адреса. Порядок, в котором передаются байты (во времени), неоднозначен (возможен как инкремент, так и декремент адреса), но в адресном пространстве они раскладываются по своим местам однозначно.
В табл. 6.4 приводятся состояния сигналов шины ISA для различных вариантов записи в порты ввода-вывода, проверенные экспериментальным путем. Вывод 16-разрядных данных выполнялся командой OUT DX,AX (в DX - адрес порта, в АХ - данные; AL содержит младший байт, АН - старший), вывод 8-разрядных - командой OUT DX,AL. Несколько неожиданные (для автора) варианты 3 и 6 с декрементом адреса, возможно, будут иметь место не на всех системных платах, но их следует иметь в виду при проектировании устройств, претендующих на глобальную совместимость. Правда на практике 16-битных передач по нечетным адресам обычно избегают (даже чисто подсознательно), и побочные эффекты от такого порядка маловероятны.
Таблица 13. Состояние сигналов при 8- и 16-битных обращениях к устройству ISA
| Сигнал (шина) | 1 цикл | 2 цикл |
| 1. Вывод 16-разрядных данных в 16-битное устройство по четному адресу | ||
| SBHE# | L | |
| SA | DX(AO=0) | |
| D | АН | |
| D | AL | |
| IOCS16# | L | |
| 2. Вывод 16-разрядных данных в 16-битное устройство по нечетному адресу ххх1,ххх5, xxx9,xxxD | ||
| SBHE# | L | H |
| SA | DX(AO=1) | DX+1 (A0=0) |
| D | AL | |
| D | AL | AH |
| IOCS16# | L | L |
| 3. Вывод 16-разрядных данных в 16-битное устройство по нечетному адресу хххЗ,ххх7, xxxB.xxxF | ||
| SBHE# | H | L |
| SA | (A0=0) | DX (A0= 1 |
| D | AL | |
| D | AH | |
| IOCS16* | L | L |
| 4. Вывод 16-разрядных данных в 8-битное устройство по четному адресу | ||
| SBHE# | L | L |
| SA | DX(AO=0) | DX+1(AO=1) |
| D | AH | AH |
| D | AL | AH |
| IOCS16* | H | H |
| 5. Вывод 16-разрядных данных в 8-битное устройство по нечетному адресу ххх1,ххх5, xxx9,xxxD | ||
| SBHE# | L | H |
| SA[ 1:0] | DX (A0= 1) | DX+1 (A0=0) |
| D | AL | |
| D | AL | AH |
| IOCS16# | H | H |
| 6. Вывод 16-разрядных данных в 8-битное устройство по нечетному адресу хххЗ,ххх7, xxxB,xxxF | ||
| SBHE# | H | L |
| SA[ 1:0] | DX+1(AO=0) | DX(AO=1) |
| D | AL | |
| D | AH | AL |
| IOCS16# | H | H |
| 7. Вывод 8-разрядных данных в 16-битное устройство по четному адресу | ||
| SBHE# | H | |
| SA | DX(AO=0) | |
| D | ||
| D | AL | |
| IOCS16* | L | |
| 8. Вывод 8-разрядных данных в 16-битное устройство по нечетному адресу | ||
| SBHE# | L | |
| SA | DX(AO=1) | |
| D | AL | |
| D | 0(AL?) | |
| IOCS16* | L |
Момент помещения действительных данных на линии SD определяется управляющими сигналами чтения/записи, так что исполнителю не требуется синхронизация с тактовым сигналом шины. В циклах чтения адресованный исполнитель должен выдать данные на шину по началу (спаду) соответствующего сигнала чтения (IOR#, MEMR#, SMEMR#) и удерживать их до конца действия сигнала (пока не произойдет подъем сигнала). В циклах записи задатчик выставляет действительные данные несколько позже начала (спада) сигнала записи (IOW#, MEMW#, SMEMW#). Устройство-исполнитель должно фиксировать для себя эти данные в конце цикла по подъему сигнала записи. От устройства-исполнителя не предусматривается никаких подтверждений исполнения циклов; длительность цикла устанавливает задатчик, но исполнитель может потребовать удлинения или укорочения циклов. С помощью сигнала IOCHRDY исполнитель может удлинить цикл на произвольное число тактов, при этом задатчик будет вводить дополнительные такты ожидания (wait states). Обычно контроллер шины следит за длительностью цикла и по достижении критического времени принудительно его завершает (по тайм-ауту, возможно, и не сообщая об этом событии). Слишком длинные циклы тормозят работу компьютера, а превышение длительности 15 мкс может привести к сбою регенерации и потере данных в ОЗУ. С помощью сигнала OWS# исполнитель предлагает задатчику укоротить цикл, исключив такты ожидания. Реакция задатчика на одновременное использование сигналов IOCHRDY и OWS# непредсказуема, этой ситуации следует избегать.
Номинальная длительность цикла определяется чипсетом и может программироваться в BIOS Setup заданием числа тактов ожидания (wait states). При этом циклы обращения к памяти, как правило, короче циклов обращения к портам ввода-вывода. Для управления длительностью цикла используются также сигналы управления разрядностью передачи: если устройство поддерживает 16-битные передачи, предполагается, что оно может работать с меньшим количеством тактов ожидания. Этим объясняется, что в BIOS Setup длительности циклов ISA задаются раздельно как для памяти и ввода-вывода, так и для 8- и 16-битных операций. Кроме длительности цикла, устройства могут быть критичны к времени восстановления (recovery time) - длительности пассивного состояния управляющих сигналов чтения-записи между циклами. Этот параметр также может программироваться в BIOS Setup и тоже раздельно для 8- и 16-разрядных операций.
Карты расширения для подключения к шине данных, как правило, используют буферные микросхемы, раздельные для линий SD и SD. Здесь широко применяются микросхемы 74ALS245 (1533АП6) - 8-разрядные двунаправленные приемопередатчики. Буфер должен открываться сигналом ОЕ# (Output Enable - разрешение выхода), когда на шине адреса присутствует адрес, относящийся к диапазону адресов подключаемого устройства. «Дежурным» является направление передачи «от шины - к устройству»; переключение в обратную сторону производится по сигналу IOR#, если устройство представляет порты ввода-вывода, или MEMRD*, если устройство приписано к пространству памяти. Таким образом, буферы имеют право передавать данные на шину (управлять шиной данных) только во время действия сигнала чтения, относящегося к зоне адресов данного устройства. Карта расширения может являться комбинацией 8- и 16-битных устройств; например, некогда популярные мультикарты содержали 16-битный адаптер AT A и набор 8-битных контроллеров портов COM, LPT, GAME и контроллера НГМД. В таких картах логика управления буферами и сигналами IOCS16* и MSC16* управляется сигналами от дешифратора адреса. Если устройство по данному адресу является 8-разрядным (не формирует сигналы IOCS16* или MSC16*), то оно имеет право разрешать чтение только через буфер линий SD, а буфер старших линий SD (если он имеется на карте) должен быть переведен в третье состояние. Если устройство по данному адресу является 16-разрядным, то оно формирует сигнал IOCS16* или MSC16*, а разрешением буферов управляют сигналы SBHE* и SAO. В этом случае буфер линий SD разрешается только при SAO=0, а буфер линий SD разрешается только при SBHE#=L. Некорректное разрешение буферов может приводить к их конфликту с перестановщиком байтов системной платы и искажениям данных.
Восьмиразрядные устройства (например, микросхемы 8255, 8250, 8253 и т. п.) следует подключать только к линиям SD и при обращении к ним не формировать сигналы IOCS16* или MSC16*. Никакие «косые» буферы (перестановщики байтов) на интерфейсных картах не нужны.
В одном из источников описывается эффект перестановки байтов при обращении к порту ввода-вывода: «Если прочитать слово из порта по четному адресу, значение одно, а если по нечетному - старшие 8 бит предыдущего значения становятся младшими, а старшие нового = FFh». Первые подозрения падают на ошибку в логике управления буферами. На самом деле все объясняется гораздо проще. Пусть имеется устройство с двухбайтным регистром, младший байт которого имеет адрес RO (четный), старший - RO+1, а по адресу R+2 устройство (и никакие другие) не откликается. Пусть в данный момент в нем записано число AA55h, тогда чтением порта по команде IN AX, R0 получим в регистрах процессора AL=55h, AH=AAh. Теперь если попытаться его «прочитать по нечетному адресу», то есть командой IN АХ, R0+1, то получим AL=AAh (содержимое RO+1, к которому мы на самом деле и адресовались!), a AH=FFh (результат чтения «пустоты»). Так что это не «эффект перестановки», а просто незнание общего правила «интеловской» адресации: адресом слова (двойного, учетверенного...) является адрес его младшего байта. Если в нашем устройстве применяется неполная дешифрация адреса (линия SA1 не используется ни для дешифрации адреса, ни для выбора регистра), то мы увидим полную перестановку байт - в AH=55h, результат чтения RO по адресу-псевдониму RO+2. Логика работы контроллера шины вместе со всеми буферами делает обращение к любой ячейке памяти или порту инвариантным к способу программной адресации - что закажешь, то и получишь, но требуется учитывать особенности периферийных устройств, у которых в адресации портов нередко встречаются псевдонимы. Адреса-псевдонимы встречаются и в пространстве памяти (например, копии образов BIOS под границей 1-го и 16-го мегабайтами памяти в «классических» PC/AT).








: не боится воды и экономии Стоит ли покупать samsung a7")

Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows
Резервное копирование и восстановление драйверов Windows
Как на «Билайне» перейти на другой тариф: все способы