FIVT MIPT'nin bir öğrencisi, yakın bir arkadaşım ve yakın zamanda bir meslektaşım olan Alexander Krot, büyük veri madenciliği ve makine öğrenimi (Veri madenciliği ve makine öğrenimi) için pratik araçlar hakkında bir dizi makale yayınladı.
3 makale zaten yayınlandı, umarım gelecekte daha fazlası olur:
1) Python ve Scikit-Learn ile Makine Öğrenmesine Giriş
2) Makine Öğreniminde Özellik Mühendisliği Sanatı
3) Gerçekten çok fazla veri olduğunda: Vowpal Wabbit
Yayınlanmış makaleler, otomatik veri analizi araçları ve verimli makine analizi için veri hazırlayan algoritmalarla çalışmanın pratik yönlerine odaklanır. Özellikle, Python'da (bu arada, yakın zamanda Python'daydık) özel bir kitaplık olan Scikit-Learn ile kod örnekleri vardır; bu, bilgisayarınızdaki büyük verilerin tadına varmak için bir ev bilgisayarında veya kişisel bulutta hızlı bir şekilde çalıştırılabilir. sahip olmak.
Geçenlerde nasıl diye düşündüm. Verilen araçlarla tanışmak artık bu yönde pratik deneyler yapmamıza izin verecek (bu arada Python'daki program yerleşik Linux denetleyicisinde çalıştırılabilir, ancak mobil işlemcinin gigabayt öğütme örneklerini işlemesi pek olası değildir. veri). Bu arada, Scala büyük veriyle çalışan mühendisler arasında da saygı görüyor, bu tür kodları entegre etmek daha da kolay olacak.
Geleneksel olarak, herhangi bir enstrümana ustalıkla sahip olmak, onların yardımıyla etkili bir şekilde çözülebilecek iyi bir problem bulma ihtiyacını ortadan kaldırmaz (tabii ki, bu sorunu size başka biri belirlemedikçe). Ancak ek fırsatlar için alan açılır. Benim düşünceme göre, şöyle görünebilir: bir robot (veya bir grup robot) sensörlerden bilgi toplar, bunları biriktirdiği ve kalıpları bulmak için işlendiği sunucuya gönderir; ayrıca algoritma, bulunan şablonları robotun sensörlerinin operasyonel değerleriyle karşılaştıracak ve ona ortamın en olası davranışı hakkında tahminler gönderecektir. Veya sunucuda, arazi veya belirli bir arazi türü hakkında önceden bir bilgi tabanı hazırlanır (örneğin, manzara ve tipik nesnelerin karakteristik fotoğrafları şeklinde) ve robot bunu kullanabilecektir. operasyonel bir durumda davranışı planlama bilgisi.
İlk makaleyi tohum olarak bırakacağım, gerisi Habré'deki bağlantıları takip edecek:
Numpy'yi np olarak içe aktar urllib # url'yi veri kümesi url'si ile içe aktar = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"# dosyayı indirin raw_data = urllib.urlopen (url) # CSV dosyasını bir numpy matrisi olarak yükleyin veri kümesi = np.loadtxt (raw_data, sınırlayıcı = ",") # verileri hedef niteliklerden ayırın X = veri kümesi [:, 0: 7] y = veri kümesi [:, 8]
Veri normalleştirme
Herkes, çoğu gradyan yönteminin (neredeyse tüm makine öğrenimi algoritmalarının dayandığı) veri ölçeklendirmeye karşı oldukça hassas olduğunun farkındadır. Bu nedenle, algoritmaları çalıştırmadan önce, çoğunlukla ya yapılır. normalleştirme veya sözde standardizasyon... Normalleştirme, nominal özelliklerin her birinin 0 ila 1 aralığında yer alacak şekilde değiştirilmesini içerir. Standardizasyon, verilerin bu şekilde ön işlenmesini gerektirir, bundan sonra her bir özelliğin bir 0 ve varyansı vardır. Bugün nasılsın:Sklearn içe aktarma ön işlemesinden # veri özniteliklerini normalleştir normalized_X = önişleme.normalize (X) # veri özniteliklerini standartlaştır standardized_X = önişleme.ölçek (X)
Öznitelik Seçimi
Bir sorunu çözmede genellikle en önemli şeyin işaretleri doğru seçme ve hatta oluşturma yeteneği olduğu bir sır değildir. İngiliz edebiyatında buna denir Öznitelik Seçimi ve Özellik Mühendisliği... Geleceğin Mühendisliği oldukça yaratıcı bir süreç olsa ve daha çok sezgiye ve uzmanlığa dayansa da, Özellik Seçimi için halihazırda çok sayıda hazır algoritma var. "Ağaç tabanlı" algoritmalar, özelliklerin bilgilendiriciliğinin hesaplanmasına izin verir:sklearn'den sklearn.ensemble'dan içe aktarma metriklerini içe aktarma ExtraTreesClassifier model = ExtraTreesClassifier () model.fit (X, y) # her özelliğin göreceli önemini göster yazdır (model.feature_importances_)
Diğer tüm yöntemler, şu veya bu şekilde, oluşturulan modelin en iyi kaliteyi verdiği en iyi alt kümeyi bulmak için özelliklerin alt kümelerinin verimli bir şekilde numaralandırılmasına dayanır. Bu tür kaba kuvvet algoritmalarından biri, Scikit-Learn kitaplığında da bulunan Özyinelemeli Özellik Eliminasyon algoritmasıdır:
sklearn.feature_selection'dan sklearn.linear_model'den RFE'yi içe aktar LogisticRegression modelini içe aktar = LogisticRegression () # RFE modelini oluşturun ve 3 özniteliği seçin rfe = RFE (model, 3) rfe = rfe.fit (X, y) # özelliklerin seçimini özetle yazdır (rfe.support_) yazdır (rfe.ranking_)
algoritma yapımı
Belirtildiği gibi, Scikit-Learn tüm büyük makine öğrenimi algoritmalarını uygular. Bunlardan bazılarına bir göz atalım.Lojistik regresyon
Çoğunlukla sınıflandırma problemlerini çözmek için kullanılır (ikili), ancak çok sınıflı sınıflandırmaya da izin verilir (bire-hepsi yöntemi olarak adlandırılır). Bu algoritmanın avantajı, her nesne için çıktıda sınıfa ait olma olasılığımızın olmasıdır.sklearn'den sklearn.linear_model'den içe aktarma metrikleri import LogisticRegression modeli = LogisticRegression () model.fit (X, y) print (model) # tahminlerde bulunun = y tahmini = model.predict (X)
Naif bayanlar
Aynı zamanda, ana görevi eğitim örnek verilerinin dağıtım yoğunluklarını geri yüklemek olan en ünlü makine öğrenme algoritmalarından biridir. Genellikle bu yöntem, çok sınıflı sınıflandırma problemlerinde iyi bir kalite sağlar.sklearn içe aktarma metriklerinden sklearn.naive_bayes'den içe aktar GaussianNB modeli = GaussianNB () model.fit (X, y) yazdır (model) # tahminlerde bulunun = y tahmini = model.tahmin (X) # modelin uyumunu özetle yazdır (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
K-en yakın komşular
Yöntem kNN (k-En Yakın Komşular) genellikle daha karmaşık bir sınıflandırma algoritmasının parçası olarak kullanılır. Örneğin, değerlendirmesi bir nesne için bir özellik olarak kullanılabilir. Ve bazen, iyi seçilmiş özelliklerde basit bir kNN mükemmel kalite sağlar. Parametrelerin (esas olarak metriklerin) uygun şekilde ayarlanmasıyla, algoritma genellikle regresyon problemlerinde iyi kalite verir.sklearn'den sklearn.neighbors'dan metrikleri içe aktarın KNeighborsClassifier'ı içe aktarın # verilere k-en yakın komşu modelini sığdır model = KNeighborsClassifier () model.fit (X, y) print (model) # tahminlerde bulunun = y tahmini = model.predict (X) # modelin uyumunu özetle yazdır (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Karar ağaçları
Sınıflandırma ve Regresyon Ağaçları (CART) genellikle nesnelerin kategorik özelliklere sahip olduğu görevlerde kullanılır ve regresyon ve sınıflandırma görevleri için kullanılır. Ağaçlar çok sınıflı sınıflandırma için çok iyidirsklearn'den sklearn.tree'den metrikleri içe aktarın DecisionTreeClassifier'ı içe aktarın # verilere bir CART modeli sığdır model = DecisionTreeClassifier () model.fit (X, y) print (model) # tahminler bekleniyor = y tahmin ediliyor = model.predict (X) # modelin uyumunu özetle yazdır (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Destek vektör makinesi
SVM (Destek Vektör Makineleri) esas olarak sınıflandırma problemi için kullanılan en ünlü makine öğrenme algoritmalarından biridir. Lojistik regresyonun yanı sıra SVM, çok sınıflı bire karşı hepsi sınıflandırmasına izin verir.sklearn.svm'den sklearn içe aktarma metriklerinden içe aktarma SVC # bir SVM modelini veri modeline sığdır = SVC () model.fit (X, y) yazdır (model) # tahminler bekleniyor = y tahmin edilen = model.tahmin (X) # modelin uyumunu özetle yazdır (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Sınıflandırma ve regresyon algoritmalarına ek olarak, Scikit-Learn, kümeleme dahil olmak üzere çok sayıda daha karmaşık algoritmaya ve ayrıca algoritma kompozisyonları oluşturmak için uygulanan tekniklere sahiptir. torbalama ve Artırma.
Algoritma Parametrelerinin Optimizasyonu
Gerçekten etkili algoritmalar oluşturmanın en zor adımlarından biri doğru parametreleri seçmektir. Genellikle, bu deneyimle daha kolay hale gelir, ancak bir şekilde aşırıya kaçması gerekir. Neyse ki, Scikit-Learn zaten bunun için uygulanan birkaç özelliğe sahiptir.Örneğin, sırayla birkaç değer üzerinde yinelediğimiz düzenlileştirme parametresinin seçimine bakalım:
numpy'yi sklearn.linear_model'den np olarak içe aktarın Ridge'i sklearn.grid_search'ten içe aktar GridSearchCV'yi içe aktarın # test etmek için bir dizi alfa değeri hazırlayın alfalar = np.dizi () # her alfayı test ederek bir ridge regresyon modeli oluşturun ve sığdırın model = Ridge () grid = GridSearchCV (tahminleyici = model, param_grid = dict (alpha = alphas)) grid.fit (X, y) print (ızgara) # ızgara aramasının sonuçlarını özetle yazdır (grid.best_score_) yazdır (grid.best_estimator_.alpha)
Bazen, belirli bir segmentten rastgele bir parametreyi birçok kez seçmek, bu parametre için algoritmanın kalitesini ölçmek ve böylece en iyisini seçmek daha verimli olur:
numpy'yi scipy.stats'tan np olarak al # alfa parametresi için örneklemek için tek tip bir dağılım hazırlayın param_grid = ("alfa": sp_rand ()) # rastgele alfa değerlerini test ederek bir sırt regresyon modeli oluşturun ve sığdırın model = Ridge () rsearch = RandomizedSearchCV (tahminleyici = model, param_distributions = param_grid, n_iter = 100) rsearch.fit (X, y) yazdır (arama) # rastgele parametre aramasının sonuçlarını özetle yazdır (rsearch.best_score_) yazdır (rsearch.best_estimator_.alpha)
Python'un (ve Scikit-Learn kütüphanenin kendisi) R üzerinden mükemmel belgelerdir. İlerleyen kısımlarda bölümlerin her birini ayrıntılı olarak ele alacağız, özellikle böyle önemli bir şeye değineceğiz. Özellik Mühendisliği.
Bu materyalin acemi Veri Bilimcilerinin pratikte makine öğrenimi sorunlarını çözmede mümkün olan en kısa sürede başlamasına yardımcı olacağını gerçekten umuyorum.Sonuç olarak, makine öğrenimi yarışmalarına yeni katılanlara başarılar ve sabırlar diliyorum!
Hile sayfaları, daha önemli görevler için zihninizi özgür bırakacaktır. Kullanabileceğiniz ve kullanmanız gereken en iyi 27 hile sayfasını topladık.
Evet, makine öğrenimi sıçramalar ve sınırlarla gelişiyor ve koleksiyonumun modası geçeceğini düşünüyorum, ancak Haziran 2017 için bu konuyla alakalı olmaktan çok daha fazlası.
Tüm hile sayfalarını ayrı ayrı indirmek istemiyorsanız, hazır zip arşivini indirin.
Makine öğrenme
Makine öğrenimini kapsayan birçok faydalı akış şeması ve tablo var. Aşağıda en eksiksiz ve gerekli olanlar bulunmaktadır.
Sinir Ağı mimarileri
Yeni sinir ağı mimarilerinin ortaya çıkmasıyla, onları takip etmek zorlaştı. Çok sayıda kısaltma (BiLSTM, DCGAN, DCIGN, hepsini bilen var mı?) Cesaret kırıcı olabilir.
Bu yüzden bu mimarilerin çoğunu içeren bir kopya sayfası oluşturmaya karar verdim. Çoğu sinir ağları ile ilgilidir. Bu görselleştirmeyle ilgili tek bir sorun var: kullanım ilkesi gösterilmemiştir. Örneğin, varyasyonel otomatik kodlayıcılar (VAE), otomatik kodlayıcılar (AE) gibi görünebilir, ancak öğrenme süreci farklıdır.
Microsoft Azure Algoritması Akış Çizelgesi
Microsoft Azure Machine Learning Hile Sayfaları, tahmine dayalı analitik modeliniz için doğru algoritmayı seçmenize yardımcı olur. Microsoft Azure Machine Learning Studio, geniş bir regresyon, sınıflandırma, kümeleme ve anormallik algılama algoritmaları kitaplığı içerir.

SAS Algoritması Akış Şeması
SAS algoritmalarına sahip hile sayfaları, belirli bir sorunu çözmek için doğru algoritmayı hızlı bir şekilde bulmanızı sağlar. Burada sunulan algoritmalar, çeşitli veri bilimcileri, geliştiricileri ve makine öğrenimi uzmanlarından alınan geri bildirim ve tavsiyelerin bir derlemesinin sonucudur.

Algoritmaların toplanması
Regresyon, düzenlileştirme, kümeleme, karar ağacı, Bayesian ve diğer algoritmalar için algoritmalar sunar. Hepsi nasıl çalıştıklarına göre gruplandırılmıştır.

Ayrıca liste infografik formatındadır:

Tahmin algoritması: "için / karşı"
Bu hile sayfaları, tahmine dayalı analizde kullanılan en iyi algoritmaları topladı. Tahmin, bir çıktı değişkeninin değerinin bir dizi girdi değişkeninden belirlendiği bir süreçtir.

piton
Şaşırtıcı olmayan bir şekilde Python, geniş bir topluluğa ve birçok çevrimiçi kaynağa sahiptir. Bu bölüm için çalıştığım en iyi hile sayfalarını seçtim.
Bu, Python ve R kodlarıyla en sık kullanılan 10 makine öğrenimi algoritmasının bir koleksiyonudur.Alıntı sayfası, yararlı makine öğrenimi algoritmalarını kullanmanıza yardımcı olmak için mükemmel bir referanstır.

Python'un bugün yükselişte olduğu inkar edilemez. Hile sayfaları, fonksiyonlar ve örnek olarak Python dilini kullanan nesne yönelimli programlama tanımı dahil olmak üzere ihtiyacınız olan her şeyi içeriyordu.

Bu hile sayfası, herhangi bir Python öğreticisinin giriş bölümüne harika bir ektir:

Dizi
NumPy, Python'un verileri hızlı bir şekilde işlemesini sağlayan bir kitaplıktır. İlk çalışmada, tüm işlevleri ve yöntemleri hatırlamakta sorun yaşayabilirsiniz, bu nedenle burada kütüphanenin çalışmasını büyük ölçüde kolaylaştırabilecek en faydalı kopya sayfaları toplanmıştır. Alma / verme, dizi oluşturma, kopyalama, sıralama, öğeleri taşıma ve çok daha fazlasını kapsar.

Ve burada teorik kısım ek olarak sunulmaktadır:

Bazı verilerin şematik bir gösterimi bu hile sayfasında bulunabilir:

Diyagramlarla ihtiyacınız olan tüm bilgiler:

Üst düzey Pandalar kitaplığı, veri analizi için tasarlanmıştır. İlgili çerçeveler, paneller, nesneler, paket işlevselliği ve diğer gerekli bilgiler, uygun şekilde organize edilmiş bir hile listesinde toplanır:

Pandalar kitaplığı hakkındaki bilgilerin şematik bir gösterimi:

Ve bu hile sayfası, örnekler ve tablolarla ayrıntılı bir özet içeriyordu:

Önceki Pandas kütüphanesini matplotlib paketi ile tamamlarsak, alınan verilere grafik çizmek mümkün olacaktır. Matplotlib'in sorumlu olduğu şey Python'da grafik çizmek içindir. Bu genellikle acemi Python programcıları tarafından kullanılan ilk işleme ile ilgili pakettir ve sunulan hile sayfaları bu kitaplığın işlevselliğinde hızlı bir şekilde gezinmenize yardımcı olacaktır.

İkinci kopya sayfasında, grafiklerin görsel sunumuna ilişkin daha fazla örnek bulacaksınız:

Makine öğrenimi algoritmalarının Scikit-Learn Python kitaplığı, öğrenmesi en kolay olanı değildir, ancak hile sayfaları ile çalışma prensibi mümkün olduğunca netleşir.

Şematik sunum:

Teori, örnekler ve ek materyallerle:

TensorFlow
Makine öğrenimi için başka bir kütüphane, ancak kendi işlevselliği ve algılanmasının zorlukları var. Aşağıda, TensorFlow'u öğrenmek için yararlı bir hile sayfası bulunmaktadır.
Her veri analisti kendisine hangi programlama dilini seçeceğini sorar. — R veya Python - yaz? Bu soruya en iyi cevabı bulmak için çoğu durumda en popüler arama motoru Google kullanılmaktadır. Doğru cevapları bulamayan potansiyel adaylar asla makine öğrenimi teknolojileri veya analitik konusunda uzman olamazlar. Bu makale, makine öğrenimi teknolojilerinin geliştirilmesinde kullanımları için R ve Python dillerinin özelliklerini açıklamaya çalışmaktadır.
Makine öğrenimi ve veri bilimi, çözümlerin ve uygulamaların geliştirilmesinde çeşitli karmaşık sorunları ve zorlukları çözen günümüzün ileri teknolojisinin gelişen ve büyüyen bölümleridir. Bu bağlamda, küresel ölçekte analistler ve veri analistleri, güçlerini ve yeteneklerini yapay zeka, IoT ve büyük veri gibi teknolojilerde uygulamak için en geniş fırsatları açıyorlar. Uzmanlar ve teknisyenler, yeni karmaşık sorunları çözmek için büyük miktarda veriyi işlemek için güçlü bir araca ihtiyaç duyar ve verileri analiz etme, tanıma ve toplama görevlerini otomatikleştirmek için çeşitli makine öğrenimi araçları ve kitaplıkları geliştirilmiştir.
Makine öğrenmesi kitaplıklarının geliştirilmesinde R ve Python gibi programlama dilleri ön plandadır. Birçok uzman ve analist, doğru dili seçmek için zaman ayırır. Makine öğrenimi amaçları için tercih edilen programlama dili nedir?
R ve Python Nasıl Benzerdir?
- Her iki dil — R ve Python — açık kaynak programlama dilleridir. Programlama topluluğunun çok sayıda üyesi, dokümantasyonun geliştirilmesine ve bu dillerin geliştirilmesine katkıda bulunmuştur.
- Diller veri analizi, analitik ve makine öğrenimi projeleri için kullanılabilir.
- Her ikisi de veri bilimi projelerini tamamlamak için gelişmiş araçlara sahiptir.
- R ve Python'da çalışmayı tercih eden veri analistlerinin maaşı hemen hemen aynı.
- Python ve R'nin güncel sürümleri — x.x
R ve Python - rakipler arasındaki rekabet
Tarihi gezi:
- 1991 yılında Guido Van Rossum, C, Modula-3 ve ABC dillerinin geliştirilmesinden ilham alarak yeni bir programlama dili önerdi - Python.
- 1995 yılında Ross Ihaka ve Robert Gentleman, S programlama diline benzetilerek geliştirilen R dilini yarattı.
Hedefler:
- Python geliştirmenin amacı, yazılım ürünleri oluşturmak, geliştirme sürecini basitleştirmek ve kodu okunabilir kılmaktır.
- R dili ise esas olarak kullanıcı dostu veri analizi ve karmaşık istatistiksel problemlerin çözümü için geliştirilmiştir. Esas olarak istatistiksel yönelimli bir dildir.
Öğrenme Kolaylığı:
- Kodun okunabilirliği Python'u öğrenmeyi kolaylaştırır. Önceden programlama deneyimi olmadan öğrenilebilen yeni başlayanlar için uygun bir dildir.
- R dili zordur, ancak bu dili programlamada ne kadar uzun süre kullanırsanız, öğrenmesi o kadar kolay olur ve karmaşık istatistiksel formülleri çözmedeki performansı o kadar yüksek olur. Deneyimli programcılar için R bir seçenektir gitmek.
Topluluklar:
- Python, üyeleri geleceğe yönelik uygulamalar için dili geliştirmeye kendini adamış çeşitli toplulukların desteğine sahiptir. Programcılar ve geliştiriciler, StackOverflow üyeleri gibi Python topluluğunun aktif üyeleridir.
- R dili ayrıca posta listeleri, kullanıcı katkı belgeleri ve daha fazlası aracılığıyla çok çeşitli toplulukların üyeleri tarafından desteklenir.Çoğu istatistikçi, araştırmacı ve veri analisti dilin geliştirilmesinde aktif olarak yer alır.
Esneklik:
- Python üretkenlik odaklı bir dildir, bu nedenle çeşitli uygulamalar geliştirmek için yeterince esnektir. Python, büyük ölçekli uygulamaların geliştirilmesi için çeşitli modüller ve kütüphaneler içerir.
- R dili ayrıca karmaşık formüller geliştirmede, istatistiksel testler gerçekleştirmede, veri görselleştirmede ve daha pek çok konuda esnektir.Kullanıma hazır çeşitli paketler içerir.
Başvuru:
- Python, uygulama geliştirmede liderdir. Web sitesi geliştirme ve oyun geliştirme, veri bilimini desteklemek için kullanılır.
- R dili esas olarak istatistik ve görselleştirmeye odaklanan veri analizi projelerinin geliştirilmesinde kullanılır.
Hem R hem de Python'un avantajları ve dezavantajları vardır. Çoğu durumda, bunlar belirli merkezli dillerdir, çünkü R istatistik ve görselleştirmeye odaklanırken Python herhangi bir uygulama geliştirme kolaylığına odaklanır.
Buna dayanarak, R, temel olarak bilimsel kurumlarda araştırma, istatistiksel analizler ve veri görselleştirme için kullanılabilir. Öte yandan Python, programları geliştirme, veri işleme vb. sürecini basitleştirmek için kullanılır. R, veri analizi alanında çalışan istatistikçiler için çok faydalı olabilirken Python, veri için ürünler oluşturan programcılar ve geliştiriciler için daha uygundur. analistler...
pitonçeşitli nedenlerle uygulamak için harika bir programlama dilidir. Başta, piton net bir sözdizimine sahiptir. İkincisi, içinde piton metni işlemek çok kolaydır. piton tüm dünyada çok sayıda insan ve kuruluş tarafından kullanılmaktadır, bu nedenle gelişmektedir ve iyi belgelenmiştir. Dil çapraz platformdur ve kullanımı tamamen ücretsizdir.
Yürütülebilir sözde kod
Sezgisel sözdizimi piton genellikle yürütülebilir sözde kod olarak adlandırılır. Kurulum piton varsayılan olarak, artık kullanıcı tarafından uygulanması gerekmeyen listeler, tanımlama grupları, sözlükler, kümeler, diziler vb. gibi üst düzey veri türlerini zaten içerir. Bu üst düzey veri türleri, soyut kavramların uygulanmasını kolaylaştırır. piton aşina olduğunuz herhangi bir tarzda programlamanıza izin verir: nesne yönelimli, prosedürel, işlevsel vb.
V piton Metni işlemesi ve değiştirmesi kolaydır, bu da onu sayısal olmayan verileri işlemek için ideal hale getirir. Kullanılacak çok sayıda kütüphane var piton Web sayfalarına erişmek için ve sezgisel metin işleme, veri çıkarmayı kolaylaştırır HTML-kod.
piton popüler
Programlama dili piton popülerdir ve mevcut birçok kod örneği, öğrenmeyi yeterince basit ve hızlı hale getirir. İkincisi, popülerlik, farklı uygulamalar için birçok modülün mevcut olduğu anlamına gelir.
piton bilim ve finans çevrelerinde popüler bir programlama dilidir. Bilimsel hesaplama için bir dizi kütüphane, örneğin bilim ve Dizi vektörler ve matrisler üzerinde işlem yapmanızı sağlar. Ayrıca kodu daha da okunabilir hale getirir ve lineer cebir ifadelerine benzeyen kodlar yazmanıza olanak tanır. Ayrıca araştırma kütüphaneleri bilim ve Dizi düşük seviyeli diller kullanılarak derlenmiş ( İLE BİRLİKTE ve Fortran), bu da bu araçları kullanırken hesaplamaları çok daha hızlı hale getirir.
Bilimsel Araçlar piton adlı bir grafik araçla birlikte harika çalışın matplotlib. matplotlib 2D ve 3D grafikler çizebilir ve bilim camiasında yaygın olarak kullanılan çoğu çizim türüyle çalışabilir.
piton ayrıca geliştirilmekte olan programın öğelerini görüntülemenize ve kontrol etmenize olanak tanıyan etkileşimli bir kabuğa sahiptir.
Yeni modül piton, aranan pilab, fırsatları birleştirmeye çalışır Dizi, bilim, ve matplotlib tek bir ortamda ve kurulumda. bugün paket pilab hala geliştirme aşamasında, ancak harika bir geleceği var.
Avantajlar ve dezavantajlar piton
İnsanlar farklı programlama dilleri kullanır. Ancak birçokları için bir programlama dili sadece bazı problemleri çözmek için bir araçtır. piton Verileri anlamak için daha fazla, bilgisayara nasıl sunulması gerektiğini düşünmek için daha az zaman harcamanıza izin veren üst düzey bir dildir.
Tek gerçek kusur pitonörneğin kodu olduğu kadar hızlı yürütmemesidir. Java veya C... Bunun nedeni, piton- yorumlanmış dil. Ancak, derlenmiş olarak adlandırmak mümkündür. C-programlar piton... Bu, çeşitli programlama dillerinin en iyisini kullanmanıza ve programınızı adım adım geliştirmenize olanak tanır. Kullanma fikrini denediyseniz piton ve bitmiş sistemde uygulamak istediğiniz şeyin tam olarak bu olduğuna karar verdiyseniz, bu geçişi prototipten çalışma programına uygulamak kolay olacaktır. Program modüler bir temelde oluşturulmuşsa, önce ihtiyacınız olanın içinde yazılan kodda çalıştığından emin olabilirsiniz. piton ve ardından kod yürütme hızını artırmak için kritik bölümleri dilde yeniden yazın. C... Kütüphane C++ Boost yapmayı kolaylaştırır. Gibi diğer araçlar Cython ve PyPy normal programa kıyasla programın performansını artırmanıza izin verir piton.
Programın kendisi tarafından uygulanan fikir "kötü" ise, kodu yazmak için minimum değerli zaman harcayarak bunu anlamak daha iyidir. Fikir işe yararsa, program kodunun kısmen kritik bölümlerini yeniden yazarak performansı her zaman artırabilirsiniz.
Son yıllarda, ileri derecelere sahip olanlar da dahil olmak üzere çok sayıda geliştirici, dilin ve bireysel paketlerinin performansını iyileştirmek için çalıştı. Bu nedenle, kodu üzerine yazdığınız bir gerçek değildir. C zaten var olandan daha hızlı çalışacak piton.
Python'un hangi sürümünü kullanmalıyım?
Bunun çeşitli versiyonları şu anda aynı anda yaygın olarak kullanılmaktadır, yani 2.x ve 3.x. Üçüncü sürüm hala aktif geliştirme aşamasındadır, çeşitli kütüphanelerin çoğunun ikinci sürüm üzerinde çalışması garantilidir, bu yüzden size tavsiye ettiğim ikinci sürümü, yani 2.7.8'i kullanıyorum. Bu programlama dilinin 3. sürümünde doğrudan önemli bir değişiklik yoktur, bu nedenle gelecekte minimum değişiklikle kodunuz gerekirse üçüncü sürümle kullanılmak üzere taşınabilir.
Yüklemek için resmi web sitesine gidin: www.python.org/downloads/
işletim sisteminizi seçin ve yükleyiciyi indirin. Kurulum konusuna detaylı değinmeyeceğim, arama motorları bu konuda size kolaylıkla yardımcı olacaktır.
ben varım Mac os işletim sistemi kendime bir sürüm yükledim piton, sistemde kurulu olandan farklı ve paket yöneticisi aracılığıyla paketler anakonda(bu arada, kurulum seçenekleri de var pencereler ve Linux).
Altında pencereler, onlar söylüyor, piton tef ile konur ama kendim denemedim yalan söylemeyeceğim.
Dizi
![]()
Dizi bilimsel hesaplama için ana pakettir piton. Dizi programlama dilinin bir uzantısıdır piton büyük çok boyutlu diziler ve matrisler için desteğin yanı sıra bu dizilerle çalışmak için geniş bir üst düzey matematik işlevleri kitaplığı ekleme. selefi Dizi, naylon poşet sayısal Başlangıçta Jim Haganin tarafından bir dizi başka geliştiricinin girdileriyle oluşturuldu. 2005 yılında Travis Olyphant, Dizi rakip bir paketin özelliklerini etkinleştirerek Numarray v sayısal kapsamlı değişiklikler yaparken.
Terminalde kurulum için Linux gerçekleştiriyoruz:
sudo apt-get güncellemesi sudo apt-get kurulumu python-numpy
sudo apt - güncelleme al sudo apt - python'u yükle - numpy |
1'den 12'ye kadar 12 sayıdan tek boyutlu bir vektör oluşturan ve onu üç boyutlu bir matrise dönüştüren NumPy kullanan basit bir kod:
numpy import'dan * a = arange (12) a = a.reshape (3,2,2) yazdır a
numpy içe aktarmadan * a = aralık (12) bir = bir. yeniden şekillendir (3, 2, 2) yazdır |
Bilgisayarımdaki sonuç şöyle görünüyor:

Genel olarak konuşursak, Terminalde, kod piton Bir şeyi hesap makinesindeki kadar hızlı hesaplamak dışında çok sık yapmıyorum. çalışmayı seviyorum IDE PyCharm... Yukarıdaki kodu çalıştırdığınızda arayüzü böyle görünüyor.

bilim
![]() bilim Bilimsel hesaplama için açık kaynaklı bir açık kaynak kitaplığıdır. İş için bilimönceden yüklenmiş olması gerekir Dizi, çok boyutlu dizilerle rahat ve hızlı işlemler sağlar. Kütüphane bilim dizilerle çalışır Dizi, ve örneğin sayısal entegrasyon ve optimizasyon için birçok uygun ve verimli hesaplama prosedürü sağlar. Dizi ve bilim kullanımı kolay, ancak çeşitli bilimsel ve teknik hesaplamaları yapacak kadar güçlü.
bilim Bilimsel hesaplama için açık kaynaklı bir açık kaynak kitaplığıdır. İş için bilimönceden yüklenmiş olması gerekir Dizi, çok boyutlu dizilerle rahat ve hızlı işlemler sağlar. Kütüphane bilim dizilerle çalışır Dizi, ve örneğin sayısal entegrasyon ve optimizasyon için birçok uygun ve verimli hesaplama prosedürü sağlar. Dizi ve bilim kullanımı kolay, ancak çeşitli bilimsel ve teknik hesaplamaları yapacak kadar güçlü.
Kitaplığı yüklemek için bilim v Linux, terminalde çalıştırıyoruz:
sudo apt-get güncellemesi sudo apt-get kurulumu python-scipy
sudo apt - güncelleme al sudo apt - python'u yükle - scipy |
Bir fonksiyonun ekstremumunu bulmak için bir kod örneği vereceğim. Sonuç, paket kullanılarak zaten görüntüleniyor matplotlib Aşağıda tartışılmıştır.
numpy'yi scipy'den np olarak içe aktar, özel içe aktar, matplotlib.pyplot'u plt olarak içe aktar f = lambda x: -special.jv (3, x) sol = optimize.minimize (f, 1.0) x = np.linspace (0, 10, 5000) plt.plot (x, özel.jv (3, x), "-", sol.x, -sol.fun, "o") plt.show ()
numpy'yi np olarak içe aktar scipy'den özel içe aktarma, optimize etme f = lambda x: - özel. jv (3, x) sol = optimize. simge durumuna küçült (f, 1.0) x = np. doğrusal boşluk (0, 10, 5000) plt. arsa (x, özel.jv (3, x), "-", sol. x, - sol. eğlenceli, "o") plt. göstermek () |
Sonuç, işaretli bir ekstremumu olan bir grafiktir:

Eğlenmek için aynı şeyi dilde uygulamaya çalışın C ve sonucu elde etmek için gereken kod satırı sayısını karşılaştırın. Kaç satır aldın? Yüz? Beş yüz? İki bin?
pandalar
![]() pandalar bir paket mi piton"göreli" veya "etiketli" verilerle basit ve sezgisel bir şekilde çalışmayı kolaylaştıran hızlı, esnek ve anlamlı veri yapıları sağlamak üzere tasarlanmıştır. pandalar tutmak için ana üst düzey yapı taşı olmayı hedeflemektedir. piton gerçek dünyadan elde edilen verilerin pratik analizi. Ayrıca, bu paket en güçlü ve esnek olduğunu iddia ediyor açık kaynak herhangi bir programlama dilinde mevcut olan bir veri analizi / işleme aracı.
pandalar bir paket mi piton"göreli" veya "etiketli" verilerle basit ve sezgisel bir şekilde çalışmayı kolaylaştıran hızlı, esnek ve anlamlı veri yapıları sağlamak üzere tasarlanmıştır. pandalar tutmak için ana üst düzey yapı taşı olmayı hedeflemektedir. piton gerçek dünyadan elde edilen verilerin pratik analizi. Ayrıca, bu paket en güçlü ve esnek olduğunu iddia ediyor açık kaynak herhangi bir programlama dilinde mevcut olan bir veri analizi / işleme aracı.
pandalar farklı veri türleri ile iyi çalışır:
- Tablolar gibi farklı sütun türlerine sahip tablo verileri SQL veya Excel.
- Zaman serilerinin sıralı ve sırasız verileri (sabit bir sıklıkta olması gerekmez).
- Etiketli satırlar ve sütunlarla keyfi matris verileri (homojen veya heterojen).
- Başka herhangi bir gözlemsel veri kümesi veya istatistiksel veri biçimi. Veriler, veri yapısına yerleştirilecek bir etiket gerçekten gerektirmez. pandalar.
Paket yüklemek için pandalar Terminalde gerçekleştiriyoruz Linux:
sudo apt-get güncellemesi sudo apt-get install python-pandas
sudo apt - güncelleme al sudo apt - python'u yükle - pandalar |
Tek boyutlu diziyi veri yapısına dönüştüren basit kod pandalar:
pandaları pd olarak içe aktar numpy'yi np değerleri olarak içe aktar = np.array () ser = pd.Series (değerler) print ser
pandaları pd olarak içe aktar numpy'yi np olarak içe aktar değerler = np. dizi ([2.0, 1.0, 5.0, 0.97, 3.0, 10.0, 0.0599, 8.0]) ser = pd. Seriler (değerler) baskı sunucusu |
Sonuç:

matplotlib
![]()
matplotlib programlama dili için bir grafik kütüphanesidir piton ve hesaplamalı matematiğe uzantıları Dizi... Kitaplık, araçları kullanan uygulamalara grafikleri gömmek için nesne yönelimli bir API sağlar GUI gibi genel amaçlı WxPython, Qt, veya GTK +... bir de prosedür var pilab-arayüze benzeyen MATLAB. bilim kullanır matplotlib.
Kitaplığı yüklemek için matpoltlib v Linux aşağıdaki komutları çalıştırın:
sudo apt-get güncellemesi sudo apt-get kurulumu python-matplotlib
sudo apt - güncelleme al sudo apt - python'u yükle - matplotlib |
Kitaplığı kullanarak örnek kod matplotlib histogramlar oluşturmak için:
numpy'yi np olarak içe aktar matplotlib.mlab'ı mlab olarak içe aktar matplotlib.pyplot'u plt olarak içe aktar # örnek veri mu = 100 # dağılım ortalaması sigma = 15 # dağılımın standart sapması x = mu + sigma * np.random.randn (10000) num_bins = 50 # verilerin histogramı n, bins, patch = plt.hist (x, num_bins, normed = 1, facecolor = "green", alpha = 0.5) # "en uygun" satırı ekleyin y = mlab.normpdf (bins , mu, sigma) plt.plot (bins, y, "r--") plt.xlabel ("Akıllılar") plt.ylabel ("Olasılık") plt.title (r "IQ Histogramı: $ \ mu = 100 $, $ \ sigma = 15 $ ") # ylabel plt.subplots_adjust (sol = 0.15) plt.show () 'nin kırpılmasını önlemek için boşlukları ayarlayın
numpy'yi np olarak içe aktar matplotlib'i içe aktarın. mlab olarak mlab matplotlib'i içe aktarın. plt olarak pyplot # örnek veri mu = 100 # ortalama dağılım sigma = 15 # dağılımın standart sapması x = mu + sigma * np. rastgele. randn (10000) num_bins = 50 # verilerin histogramı n, kutular, yamalar = plt. geçmiş (x, num_bins, normlu = 1, yüz rengi = "yeşil", alfa = 0,5) # "en uygun" satırı ekleyin y = mlab. normpdf (bins, mu, sigma) plt. arsa (binler, y, "r--") plt. xlabel ("Akıllı") plt. ylabel ("Olasılık") plt. başlık (r "IQ histogramı: $ \ mu = 100 $, $ \ sigma = 15 $") # ylabel'in kırpılmasını önlemek için boşlukları ayarlayın plt. subplots_adjust (sol = 0.15) plt. göstermek () |
Bunun sonucu:
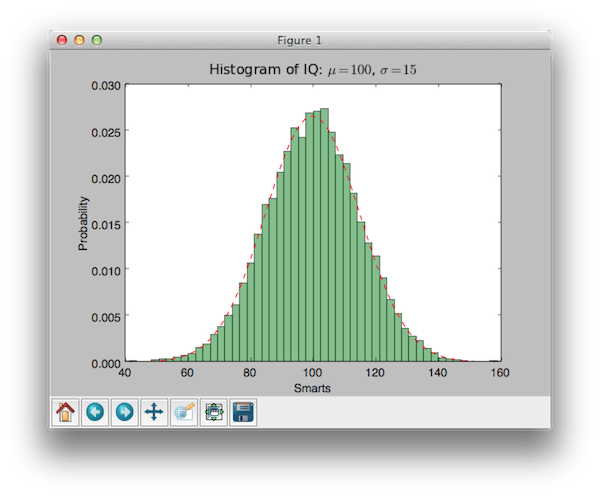
Bana göre, çok güzel!
orijinal olarak programlama dili için geliştirilmiş, çeşitli programlama dillerinde etkileşimli hesaplama için bir komut kabuğudur. Python. sunumun olanaklarını genişletmenize, kabuğa sözdizimi, otomatik tamamlama ve kapsamlı bir komut geçmişi eklemenize olanak tanır. şu anda aşağıdaki özellikleri sağlar:
- Güçlü etkileşimli kabuklar (terminal tipi ve tabanlı Qt).
- Kod, metin, matematik ifadeleri, satır içi grafikler ve diğer sunum yeteneklerini destekleyen tarayıcı tabanlı düzenleyici.
- Etkileşimli veri görselleştirmeyi ve GUI araçlarının kullanımını destekler.
- Kendi projelerinizde çalışmak için esnek, yerleşik tercümanlar.
- Kullanımı kolay, yüksek performanslı paralel bilgi işlem araçları.
IPython web sitesi:
IPython'u Linux'a kurmak için terminalde aşağıdaki komutları çalıştırın:
sudo apt-get güncellemesi sudo pip kurulumu ipython
Pakette bulunan belirli bir veri seti için doğrusal regresyon oluşturan bir kod örneği vereceğim. scikit-öğren:
matplotlib.pyplot'u plt olarak içe aktar numpy'yi sklearn'den içe aktar veri kümelerinden np olarak içe aktar, linear_model # Diyabet veri kümesini yükle diabetes = datasets.load_diabetes () # Yalnızca bir özellik kullanın diabetes_X = diabetes.data [:, np.newaxis] diabetes_X_temp = diabetes_X [: ,:, 2] # Verileri eğitim / test setlerine ayırın diyabet_X_train = diyabet_X_temp [: - 20] diyabet_X_test = diyabet_X_temp [-20:] # Hedefleri eğitim / test setlerine ayırın diyabet_y_train = diyabet.target [: - 20] diyabet_y_test = diyabet.target [-20:] # Lineer regresyon nesnesi oluştur regr = lineer_model.LinearRegression () # Regr.fit (diabetes_X_train, diabetes_y_train) eğitim setlerini kullanarak modeli eğitin # Katsayılar yazdır ("Katsayılar: \ n", regr .coef_) # Ortalama kare hatası çıktısı ("Kalan kareler toplamı:% .2f"% np.ortalama ((regr.predict (diabetes_X_test) - diabetes_y_test) ** 2)) # Açıklamalı varyans puanı: 1 mükemmel tahmin çıktısıdır ("Varyans skoru:% .2f"% kayıt skoru (diabetes_X_test, diabetes_y_test)) # Grafik çıktısı uts plt.scatter (diabetes_X_test, diabetes_y_test, color = "black") plt.plot (diabetes_X_test, regr.predict (diabetes_X_test), color = "blue", linewidth = 3) plt.xticks (()) plt.yticks (( )) plt.göster ()
matplotlib'i içe aktarın. plt olarak pyplot numpy'yi np olarak içe aktar sklearn içe aktarma veri kümelerinden, linear_model # Diyabet veri setini yükleyin diyabet = veri kümeleri. load_diabetes () # Yalnızca bir özellik kullanın diyabet_X = diyabet. veri [:, np. yeni eksen] |
Merhaba habr!
numpy'yi np olarak içe aktar urllib # url'yi veri kümesi url'si ile içe aktar = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # indir file raw_data = urllib.urlopen (url) # CSV dosyasını numpy matrix veri kümesi olarak yükle = np.loadtxt (raw_data, sınırlayıcı = ",") # verileri hedef niteliklerden ayırın X = veri kümesi [:, 0: 7] y = veri kümesi [:, 8]
Ayrıca, tüm örneklerde bu veri seti ile yani nesne-nitelik matrisi ile çalışacağız. x ve hedef değişkenin değerleri y.
Veri normalleştirme
Herkes, çoğu gradyan yönteminin (neredeyse tüm makine öğrenimi algoritmalarının dayandığı) veri ölçeklendirmeye karşı oldukça hassas olduğunun farkındadır. Bu nedenle, algoritmaları çalıştırmadan önce, çoğunlukla ya yapılır. normalleştirme veya sözde standardizasyon... Normalleştirme, nominal özelliklerin her birinin 0 ila 1 aralığında yer alacak şekilde değiştirilmesini içerir. Standardizasyon, verilerin bu şekilde ön işlenmesini gerektirir, bundan sonra her bir özelliğin bir 0 ve varyansı vardır. Bugün nasılsın:Sklearn içe aktarma önişlemesinden # veri özniteliklerini normalize edin normalize_X = önişleme.normalize (X) # veri özniteliklerini standartlaştırın standardize_X = önişleme.ölçek (X)
Öznitelik Seçimi
Bir sorunu çözmede genellikle en önemli şeyin işaretleri doğru seçme ve hatta oluşturma yeteneği olduğu bir sır değildir. İngiliz edebiyatında buna denir Öznitelik Seçimi ve Özellik Mühendisliği... Geleceğin Mühendisliği oldukça yaratıcı bir süreç olsa ve daha çok sezgiye ve uzmanlığa dayansa da, Özellik Seçimi için halihazırda çok sayıda hazır algoritma var. "Ağaç tabanlı" algoritmalar, özelliklerin bilgilendiriciliğinin hesaplanmasına izin verir:sklearn'den sklearn.ensemble'dan içe aktarma metriklerini içe aktarma ExtraTreesClassifier model = ExtraTreesClassifier () model.fit (X, y) # her özniteliğin göreceli önemini göster print (model.feature_importances_)
Diğer tüm yöntemler, şu veya bu şekilde, oluşturulan modelin en iyi kaliteyi verdiği en iyi alt kümeyi bulmak için özelliklerin alt kümelerinin verimli bir şekilde numaralandırılmasına dayanır. Bu tür kaba kuvvet algoritmalarından biri, Scikit-Learn kitaplığında da bulunan Özyinelemeli Özellik Eliminasyon algoritmasıdır:
sklearn.feature_selection'dan sklearn.linear_model'den RFE'yi içe aktar LogisticRegression modelini içe aktar = LogisticRegression () # RFE modelini oluştur ve 3 özniteliği seç rfe = RFE (model, 3) rfe = rfe.fit (X, y) # seçimini özetle öznitelikler yazdır (rfe.support_) yazdır (rfe.ranking_)
algoritma yapımı
Belirtildiği gibi, Scikit-Learn tüm büyük makine öğrenimi algoritmalarını uygular. Bunlardan bazılarına bir göz atalım.Lojistik regresyon
Çoğunlukla sınıflandırma problemlerini çözmek için kullanılır (ikili), ancak çok sınıflı sınıflandırmaya da izin verilir (bire-hepsi yöntemi olarak adlandırılır). Bu algoritmanın avantajı, her nesne için çıktıda sınıfa ait olma olasılığımızın olmasıdır.sklearn'den sklearn.linear_model'den metrikleri içe aktar LogisticRegression modeli = LogisticRegression () model.fit (X, y) yazdır (model) # tahminleri yap = y tahmini = model.tahmin (X) # modelin uygunluğunu özetle yazdır ( metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Naif bayanlar
Aynı zamanda, ana görevi eğitim örnek verilerinin dağıtım yoğunluklarını geri yüklemek olan en ünlü makine öğrenme algoritmalarından biridir. Genellikle bu yöntem, çok sınıflı sınıflandırma problemlerinde iyi bir kalite sağlar.sklearn içe aktarma metriklerinden sklearn.naive_bayes'den içe aktar GaussianNB modeli = GaussianNB () model.fit (X, y) yazdır (model) # tahminleri yap = y tahmin et = model.tahmin (X) # modelin uygunluğunu özetle yazdır ( metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
K-en yakın komşular
Yöntem kNN (k-En Yakın Komşular) genellikle daha karmaşık bir sınıflandırma algoritmasının parçası olarak kullanılır. Örneğin, değerlendirmesi bir nesne için bir özellik olarak kullanılabilir. Ve bazen, iyi seçilmiş özelliklerde basit bir kNN mükemmel kalite sağlar. Parametrelerin (esas olarak metriklerin) uygun şekilde ayarlanmasıyla, algoritma genellikle regresyon problemlerinde iyi kalite verir.sklearn içe aktarma metriklerinden sklearn.neighbors'tan içe aktar KNeighborsClassifier # k-en yakın komşu modelini veri modeline sığdır = KNeighborsClassifier () model.fit (X, y) print (model) # tahminleri yap = y tahmin edilen = model.predict ( X) # modelin uygunluğunu özetleme (metrics.classification_report (beklenen, tahmin edilen)) print (metrics.confusion_matrix (beklenen, tahmin edilen))
Karar ağaçları
Sınıflandırma ve Regresyon Ağaçları (CART) genellikle nesnelerin kategorik özelliklere sahip olduğu görevlerde kullanılır ve regresyon ve sınıflandırma görevleri için kullanılır. Ağaçlar çok sınıflı sınıflandırma için çok iyidirsklearn'den sklearn.tree'den içe aktarma metriklerini içe aktar DecisionTreeClassifier # bir CART modelini veri modeline sığdır = DecisionTreeClassifier () model.fit (X, y) yazdır (model) # tahminleri yap = y tahmin edilen = model.tahmin (X) # modelin uygunluğunu özetleyin yazdırma (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Destek vektör makinesi
SVM (Destek Vektör Makineleri) esas olarak sınıflandırma problemi için kullanılan en ünlü makine öğrenme algoritmalarından biridir. Lojistik regresyonun yanı sıra SVM, çok sınıflı bire karşı hepsi sınıflandırmasına izin verir.sklearn.svm'den sklearn içe aktarma metriklerinden içe SVC'yi içe aktar # bir SVM modelini veri modeline sığdır = SVC () model.fit (X, y) yazdır (model) # tahminlerde bulun = y tahmin edilen = model.tahmin (X) # modelin uygunluğunu özetleyin yazdırma (metrics.classification_report (beklenen, tahmin edilen)) yazdır (metrics.confusion_matrix (beklenen, tahmin edilen))
Sınıflandırma ve regresyon algoritmalarına ek olarak, Scikit-Learn, kümeleme dahil olmak üzere çok sayıda daha karmaşık algoritmaya ve ayrıca algoritma kompozisyonları oluşturmak için uygulanan tekniklere sahiptir. torbalama ve Artırma.
Algoritma Parametrelerinin Optimizasyonu
Gerçekten etkili algoritmalar oluşturmanın en zor adımlarından biri doğru parametreleri seçmektir. Genellikle, bu deneyimle daha kolay hale gelir, ancak bir şekilde aşırıya kaçması gerekir. Neyse ki, Scikit-Learn zaten bunun için uygulanan birkaç özelliğe sahiptir.Örneğin, sırayla birkaç değer üzerinde yinelediğimiz düzenlileştirme parametresinin seçimine bakalım:
numpy'yi sklearn.linear_model'den np olarak içe aktar sklearn.grid_search'ten Ridge'i içe aktar GridSearchCV'den içe aktar # alfaları test etmek için bir dizi alfa değeri hazırla = np.array () # her alfa modelini test ederek bir sırt regresyon modeli oluştur ve sığdır = Sırt ( ) grid = GridSearchCV (tahminleyici = model, param_grid = dict (alpha = alphas)) grid.fit (X, y) print (grid) # grid aramasının sonuçlarını özetler print (grid.best_score_) print (grid.best_estimator_. alfa)
Bazen, belirli bir segmentten rastgele bir parametreyi birçok kez seçmek, bu parametre için algoritmanın kalitesini ölçmek ve böylece en iyisini seçmek daha verimli olur:
numpy'yi scipy.stats'tan np olarak içe aktar sklearn.linear_model'den uniform'u sp_rand olarak al bir ridge regresyon modeli, rasgele alfa değerlerinin test edilmesi model = Ridge () rsearch = RandomizedSearchCV (tahminleyici = model, param_distributions = param_grid, n_iter = 100) rsearch.fit (X, y) print (arama) # sonuçlarını özetler rastgele parametre arama yazdırma (rsearch.best_score_) yazdırma (rsearch.best_estimator_.alpha)
Python'un (ve Scikit-Learn kütüphanenin kendisi) R üzerinden mükemmel belgelerdir. İlerleyen kısımlarda bölümlerin her birini ayrıntılı olarak ele alacağız, özellikle böyle önemli bir şeye değineceğiz. Özellik Mühendisliği.
Bu materyalin acemi Veri Bilimcilerinin pratikte makine öğrenimi sorunlarını çözmede mümkün olan en kısa sürede başlamasına yardımcı olacağını gerçekten umuyorum.Sonuç olarak, makine öğrenimi yarışmalarına yeni katılanlara başarılar ve sabırlar diliyorum!








Valle d'Aosta. İtalya. Sol menüyü aç Valle d'Aosta Vine Kahramanları
Dünyadaki elektrik prizi türleri ve voltajları
Dünyanın farklı ülkelerindeki voltaj standartları, frekansları ve çıkış türleri nelerdir?
Kuzey ve Güney Kore arasındaki askerden arındırılmış bölge nasıl değişti?
Windows'ta Otomatik Güncelleştirmeleri Devre Dışı Bırakın