Ako jeden z nástrojov na riešenie ťažko formalizovateľných problémov toho bolo povedané už pomerne veľa. A tu, na Habrém, sa ukázalo, ako použiť tieto siete na rozpoznávanie obrázkov v súvislosti s úlohou rozlúštiť captcha. Existuje však pomerne veľa typov neurónových sietí. A je klasická plne prepojená neurónová sieť (FNN) dostatočne dobrá na problém rozpoznávania (klasifikácie) obrazu?
1. Úloha
Ideme teda vyriešiť problém rozpoznávania obrázkov. Môže ísť o rozpoznávanie tvárí, predmetov, postáv atď. Navrhujem najprv zvážiť problém rozpoznávania ručne písaných číslic. Táto úloha je dobrá z niekoľkých dôvodov:
Je dosť ťažké zostaviť formalizovaný (nie inteligentný) algoritmus na rozpoznanie ručne písaného znaku, a to je jasné, stačí sa pozrieť na rovnaké číslo napísané rôznymi ľuďmi.
Úloha je celkom relevantná a súvisí s OCR (optické rozpoznávanie znakov)
Na stiahnutie a experimentovanie je k dispozícii voľne distribuovaná databáza ručne písaných symbolov
Článkov na túto tému je pomerne dosť a porovnávať rôzne prístupy je veľmi jednoduché a pohodlné.
Ako vstupné údaje sa navrhuje použiť databázu MNIST. Táto databáza obsahuje 60 000 tréningových párov (obrázok - štítok) a 10 000 testovacích párov (obrázky bez štítkov). Veľkosť obrázkov je normalizovaná a vycentrovaná. Veľkosť každej číslice nie je väčšia ako 20x20, ale sú vpísané do štvorca s veľkosťou 28x28. Príklad prvých 12 číslic z tréningovej sady MNIST je znázornený na obrázku:
Úloha je teda formulovaná takto: vytvoriť a trénovať neurónovú sieť na rozpoznávanie rukou písaných znakov, pričom ich obrázky berie ako vstup a aktivuje jeden z 10 výstupov. Aktiváciou rozumieme hodnotu 1 na výstupe. Hodnoty zostávajúcich výstupov by sa mali (v ideálnom prípade) rovnať -1. Prečo to nepoužíva stupnicu, vysvetlím neskôr.
2. "Bežné" neurónové siete.
Väčšina ľudí rozumie pod „obyčajnými“ alebo „klasickými“ neurónovými sieťami plne prepojené dopredné neurónové siete so spätným šírením chýb:

Ako už z názvu vyplýva, v takejto sieti je každý neurón prepojený s každým, signál ide len v smere od vstupnej vrstvy k výstupnej, nedochádza k rekurziám. Takúto sieť budeme nazývať skrátene PNS.
Najprv sa musíte rozhodnúť, ako odoslať údaje na vstup. Najjednoduchším a takmer nealternatívnym riešením pre PNS je vyjadrenie dvojrozmernej obrazovej matice ako jednorozmerného vektora. Tie. pre obrázok 28x28 ručne písaných číslic budeme mať 784 vstupov, čo je už dosť málo. Potom je tu niečo, pre čo mnohí konzervatívni vedci nemajú radi neurónové siete a ich metódy – výber architektúry. Ale nepáči sa im to, pretože výber architektúry je čistý šamanizmus. Doteraz neexistujú metódy, ktoré by umožnili na základe popisu problému jednoznačne určiť štruktúru a zloženie neurónovej siete. Na obranu poviem, že takáto metóda sa sotva niekedy vytvorí na problémy, ktoré sa ťažko formalizujú. Okrem toho existuje mnoho rôznych techník redukcie siete (napríklad OBD), ako aj rôzne heuristiky a orientačné pravidlá. Jedno z týchto pravidiel hovorí, že počet neurónov v skrytej vrstve musí byť aspoň o rád väčší ako počet vstupov. Ak vezmeme do úvahy, že samotný prevod z obrázku na indikátor triedy je dosť zložitý a v podstate nelineárny, jedna vrstva nestačí. Na základe vyššie uvedeného zhruba odhadujeme, že počet neurónov v skrytých vrstvách bude rádovo 15000 (10 000 v 2. vrstve a 5 000 v tretej). Zároveň pri konfigurácii s dvoma skrytými vrstvami číslo prispôsobiteľné a trénovateľné pripojenia medzi vstupmi a prvou skrytou vrstvou bude 10 miliónov + 50 miliónov medzi prvou a druhou + 50 tisíc medzi druhou a výstupom, ak predpokladáme, že máme 10 výstupov, z ktorých každý predstavuje číslo od 0 do 9. celkovo je zhruba 60 000 000 spojení. Nie nadarmo som spomínal, že sú prispôsobiteľné – to znamená, že pri tréningu bude pre každý z nich potrebné vypočítať chybový gradient.
Čo sa dá robiť, krása umelej inteligencie si vyžaduje obete. Ale ak sa nad tým zamyslíte, príde na myseľ, že keď prevedieme obrázok na lineárny reťazec bajtov, o niečo nenávratne prichádzame. A s každou vrstvou sa táto strata len zhoršuje. Je to teda – strácame topológiu obrazu, t.j. vzťah medzi jeho jednotlivými časťami. Okrem toho z úlohy rozpoznávania vyplýva schopnosť neurónovej siete byť odolná voči malým posunom, rotáciám a škálovaniu obrazu, t.j. musí z údajov vytiahnuť nejaké invarianty, ktoré nezávisia od rukopisu tej či onej osoby. Aká by teda mala byť neurónová sieť, aby bola málo výpočtovo zložitá a zároveň invariantnejšia voči rôznym deformáciám obrazu?
3. Konvolučné neurónové siete
Riešenie tohto problému našiel americký vedec francúzskeho pôvodu Jan LeCun, inšpirovaný prácou laureátov Nobelovej ceny za medicínu Torstena Nilsa Wiesela a Davida H. Hubela. Títo vedci skúmali zrakovú kôru mačky a zistili, že existujú takzvané jednoduché bunky, ktoré reagujú obzvlášť silne na priame čiary pod rôznymi uhlami, a zložité bunky, ktoré reagujú na pohyb čiar v jednom smere. Jan LeCun navrhol použiť to, čo sa nazýva konvolučné neurónové siete.
6. Výsledky
Program matlabcentral sa dodáva so súborom už natrénovanej neurónovej siete, ako aj s GUI na demonštráciu výsledkov práce. Nasledujú príklady uznania:


Odkaz obsahuje porovnávaciu tabuľku metód rozpoznávania na základe MNIST. Prvé miesto patrí konvolučným neurónovým sieťam s výsledkom 0,39% chýb rozpoznávania. Väčšina z týchto mylne rozpoznaných obrázkov nie je správne rozpoznaná každým človekom. Okrem toho boli v práci použité elastické deformácie vstupných obrázkov, ako aj predtréning bez učiteľa. Ale o týchto metódach nejako v inom článku.
Odkazy.
- Yann LeCun, J. S. Denker, S. Solla, R. E. Howard a L. D. Jackel: Optimálne poškodenie mozgu, v Touretzky, David (editori), Advances in Neural Information Processing Systems 2 (NIPS*89), Morgan Kaufman, Denver, CO, 1990
- Y. LeCun a Y. Bengio: Convolutional Networks for Images, Speech and Time-Series, v Arbib, M. A. (editori), The Handbook of Brain Theory and Neural Networks, MIT Press, 1995
- Y. LeCun, L. Bottou, G. Orr a K. Muller: Efficient BackProp, v Orr, G. a Muller K. (editori), Neural Networks: Tricks of the trade, Springer, 1998
- Ranzato Marc "Aurelio, Christopher Poultney, Sumit Chopra a Yann LeCun: Efektívne učenie sa riedkych reprezentácií s modelom založeným na energii, v J. Platt a kol. (editori), Pokroky v systémoch spracovania neurálnych informácií (NIPS 2006), MIT Press , 2006
Neurónová sieť je matematický model a jeho implementácia vo forme softvérovej alebo hardvérovo-softvérovej implementácie, ktorá je založená na modelovaní aktivity biologických neurónových sietí, čo sú siete neurónov v biologickom organizme. Vedecký záujem o túto štruktúru vznikol, pretože štúdium jej modelu umožňuje získať informácie o určitom systéme. To znamená, že takýto model môže mať praktickú implementáciu v mnohých odvetviach modernej vedy a techniky. Článok sa zaoberá otázkami súvisiacimi s témou využitia neurónových sietí na budovanie systémov identifikácie obrazu, ktoré sú široko používané v bezpečnostných systémoch. Podrobne sú študované problémy súvisiace s témou algoritmu rozpoznávania obrazu a jeho aplikácie. Stručne sú uvedené informácie o metodike trénovania neurónových sietí.
neurálne siete
učenie pomocou neurónových sietí
rozpoznávanie obrazu
paradigma lokálneho vnímania
bezpečnostné systémy
1. Yann LeCun, J.S. Denker, S. Solla, R.E. Howard a L. D. Jackel: Optimálne poškodenie mozgu, Touretzky, David (editori), Advances in Neural Information Processing Systems 2 (NIPS*89). - 2000. - 100 s.
2. Žigalov K.Yu. Metóda fotorealistickej vektorizácie údajov o polohe lasera pre ďalšie využitie v GIS. Geodézia a letecké snímkovanie. - 2007. - č. 6. - S. 285-287.
3. Ranzato Marc’Aurelio, Christopher Poultney, Sumit Chopra a Yann LeCun: Efficient Learning of Sparse Representations with a Energy-Based Model, J. Platt et al. (editori), Pokroky v systémoch spracovania neurálnych informácií (NIPS 2006). - 2010. - 400 s.
4. Žigalov K.Yu. Príprava zariadení na použitie v automatizovaných riadiacich systémoch pre výstavbu ciest // Prírodné a technické vedy. - M., 2014. - Číslo 1 (69). – S. 285–287.
5. Y. LeCun a Y. Bengio: Konvolučné siete pre obrázky, reč a časové rady, v Arbib, M. A. (editori) // The Handbook of Brain Theory and Neural Networks. - 2005. - 150 s.
6. Y. LeCun, L. Bottou, G. Orr a K. Muller: Efficient BackProp, v Orr, G. a Muller K. (editori) // Neural Networks: Tricks of the trade. - 2008. - 200 s.
K dnešnému dňu technologický a výskumný pokrok pokrýva všetky nové horizonty a rýchlo napreduje. Jedným z nich je modelovanie okolitého prírodného sveta pomocou matematických algoritmov. V tomto aspekte existujú triviálne, napríklad modelovanie morských vĺn, a mimoriadne zložité, netriviálne, viaczložkové úlohy, napríklad modelovanie fungovania ľudského mozgu. V procese štúdia tejto problematiky bol vyčlenený samostatný pojem - neurónová sieť. Neurónová sieť je matematický model a jeho implementácia vo forme softvérovej alebo hardvérovo-softvérovej implementácie, ktorá je založená na modelovaní aktivity biologických neurónových sietí, čo sú siete neurónov v biologickom organizme. Vedecký záujem o túto štruktúru vznikol, pretože štúdium jej modelu umožňuje získať informácie o určitom systéme. To znamená, že takýto model môže mať praktickú implementáciu v mnohých odvetviach modernej vedy a techniky.
Stručná história vývoja neurónových sietí
Treba poznamenať, že pôvodne pojem „neurónová sieť“ pochádza z prác amerických matematikov, neurolingvistov a neuropsychológov W. McCullocha a W. Pittsa (1943), kde ho autori prvýkrát spomínajú, definujú a robia prvý pokúsiť sa vybudovať modelovú neurónovú sieť. Už v roku 1949 D. Hebb navrhol prvý algoritmus učenia. Potom prebehla séria štúdií v oblasti neurálneho učenia a prvé funkčné prototypy sa objavili v rokoch 1990-1991. minulého storočia. Napriek tomu výpočtový výkon vtedajších zariadení nestačil na dostatočne rýchlu prevádzku neurónových sietí. Do roku 2010 sa výkon GPU grafických kariet výrazne zvýšil a objavil sa koncept programovania priamo na grafických kartách, čo výrazne (3-4 krát) zvýšilo výkon počítačov. V roku 2012 neurónové siete po prvý raz vyhrali prvenstvo v ImageNet, čo znamenalo ich ďalší rýchly rozvoj a vznik pojmu Deep Learning.
V modernom svete majú neurónové siete kolosálny rozsah, vedci považujú výskum realizovaný v oblasti štúdia behaviorálnych charakteristík a stavov neurónových sietí za mimoriadne sľubný. Zoznam oblastí, v ktorých si neurónové siete našli uplatnenie, je obrovský. Ide o rozpoznávanie a klasifikáciu vzorov, prognózovanie a riešenie problémov s aproximáciou a niektoré aspekty kompresie údajov, analýzy údajov a samozrejme aplikácie v bezpečnostných systémoch rôzneho charakteru.
Dnes sa štúdium neurónových sietí aktívne uskutočňuje vo vedeckých komunitách rôznych krajín. S takouto úvahou je prezentovaný ako špeciálny prípad množstva metód rozpoznávania vzorov, diskriminačnej analýzy a metód zhlukovania.
Treba tiež poznamenať, že za posledný rok boli finančné prostriedky pre startupy v oblasti systémov rozpoznávania obrazu alokované na viac ako predchádzajúcich 5 rokov, čo naznačuje pomerne vysoký dopyt po tomto type vývoja na konečnom trhu.
Aplikácia neurónových sietí na rozpoznávanie obrazu
Zvážte štandardné úlohy riešené neurónovými sieťami v aplikácii na obrázky:
● identifikácia objektu;
● rozpoznávanie častí predmetov (napríklad tváre, ruky, nohy atď.);
● sémantická definícia hraníc objektov (umožňuje ponechať na obrázku iba hranice objektov);
● sémantická segmentácia (umožňuje rozdeliť obrázok na rôzne samostatné objekty);
● výber normál k povrchu (umožňuje previesť dvojrozmerné obrázky na trojrozmerné obrázky);
● výber predmetov pozornosti (umožňuje určiť, čomu by človek na tomto obrázku venoval pozornosť).
Treba poznamenať, že problém rozpoznávania obrazu má jasný charakter, riešenie tohto problému je zložitý a mimoriadny proces. Pri vykonávaní rozpoznávania môže byť predmetom ľudská tvár, ručne písaná číslica, ako aj mnohé iné predmety, ktoré sa vyznačujú množstvom unikátnych znakov, čo značne komplikuje proces identifikácie.
V tejto štúdii sa budeme zaoberať algoritmom na vytváranie a učenie sa rozpoznávať ručne písané znaky neurónovej siete. Obrázok bude načítaný jedným zo vstupov neurónovej siete a jeden z výstupov sa použije na zobrazenie výsledku.
V tejto fáze je potrebné krátko sa zastaviť pri klasifikácii neurónových sietí. K dnešnému dňu existujú tri hlavné typy:
● konvolučné neurónové siete (CNN);
● rekurentné siete (hlboké učenie);
● posilňovanie učenia.
Jedným z najbežnejších príkladov budovania neurónovej siete je klasická topológia neurónovej siete. Takáto neurónová sieť môže byť reprezentovaná ako plne prepojený graf, jej charakteristickým znakom je dopredné šírenie informácie a spätné šírenie chybovej signalizácie. Táto technológia nemá rekurzívne vlastnosti. Pre názornosť je možné neurónovú sieť s klasickou topológiou znázorniť na obr. jeden.
Ryža. 1. Neurónová sieť s najjednoduchšou topológiou

Ryža. 2. Neurónová sieť so 4 vrstvami skrytých neurónov
Jednou z jednoznačne významných nevýhod tejto topológie siete je redundancia. Kvôli redundancii, keď sú dáta dodávané napríklad vo forme dvojrozmernej matice, možno na vstupe získať jednorozmerný vektor. Takže pre obrázok ručne písaného latinského listu opísaného pomocou matice 34x34 je potrebných 1156 vstupov. To naznačuje, že výpočtový výkon vynaložený na implementáciu softvérového a hardvérového riešenia tohto algoritmu bude príliš veľký.
Problém vyriešil americký vedec Jan Le Cun, ktorý rozobral prácu nositeľov Nobelovej ceny za medicínu T. Wtesela a D. Hubela. V rámci štúdie, ktorú vykonali, pôsobila vizuálna kôra mačacieho mozgu ako predmet štúdie. Analýza výsledkov ukázala, že kôra obsahuje množstvo jednoduchých buniek, ako aj množstvo zložitých buniek. Jednoduché bunky reagovali na obraz priamych čiar prijatých z vizuálnych receptorov, zatiaľ čo zložité bunky reagovali na pohyb vpred jedným smerom. V dôsledku toho bol vyvinutý princíp konštrukcie neurónových sietí, nazývaných konvolučné. Myšlienkou tohto princípu bolo, že na implementáciu fungovania neurónovej siete sa používa striedanie konvolučných vrstiev, ktoré sa zvyčajne označujú ako C - Layers, subvzorkovacie vrstvy S - Layers a plne spojené vrstvy F - Layers na výstupe neurónová sieť.
Základom budovania siete tohto druhu sú tri paradigmy – toto je paradigma lokálneho vnímania, paradigma zdieľaných váh a paradigma podvzorkovania.
Podstata paradigmy lokálneho vnímania spočíva v tom, že nie celá obrazová matica, ale jej časť, je privádzaná do každého vstupného neurónu. Zvyšné časti sú privádzané do iných vstupných neurónov. V tomto prípade môžete pozorovať mechanizmus paralelizácie, pomocou podobnej metódy môžete uložiť topológiu obrazu z vrstvy na vrstvu, spracovať ju viacrozmerne, to znamená, že v procese spracovania možno použiť určitú množinu neurónových sietí. .
Paradigma zdieľaných váh hovorí, že malá skupina váh môže byť použitá pre mnoho odkazov. Tieto sady sa tiež nazývajú "jadrá". Pre konečný výsledok spracovania obrazu môžeme povedať, že zdieľané váhy majú pozitívny vplyv na vlastnosti neurónovej siete, ktorej štúdium správania zvyšuje schopnosť nájsť invarianty v obrazoch a filtrovať zložky šumu bez ich spracovania.
Na základe vyššie uvedeného môžeme konštatovať, že pri použití postupu konvolúcie obrazu na základe jadra sa objaví výstupný obraz, ktorého prvky budú hlavnou charakteristikou stupňa zhody s filtrom, tj. vygeneruje sa mapa funkcií. Tento algoritmus je znázornený na obr. 3.

Ryža. 3. Algoritmus na generovanie mapy objektov
Paradigma podvzorkovania je taká, že vstupný obraz sa redukuje zmenšením priestorového rozmeru jeho matematického ekvivalentu – n-rozmernej matice. Potreba podvzorkovania je vyjadrená invariantnosťou k mierke pôvodného obrázku. Pri aplikácii techniky striedania vrstiev je možné generovať nové mapy prvkov z existujúcich, to znamená, že praktická implementácia tejto metódy spočíva v tom, že schopnosť degenerovať viacrozmernú maticu na vektorovú hodnotu a potom úplne na skalárnu hodnotu.
Implementácia tréningu neurónových sietí
Existujúce siete sú z hľadiska učenia rozdelené do 3 tried architektúr:
● učenie pod dohľadom (percepton);
● učenie bez dozoru (adaptívne rezonančné siete);
● zmiešané učenie (siete radiálnych základných funkcií).
Jedným z najdôležitejších kritérií na hodnotenie výkonu neurónovej siete v prípade rozpoznávania obrazu je kvalita rozpoznávania obrazu. Je potrebné poznamenať, že na kvantifikáciu kvality rozpoznávania obrazu pomocou fungovania neurónovej siete sa najčastejšie používa algoritmus root-mean-square error:
![]() (1)
(1)
V tejto závislosti je Ep p-tou chybou rozpoznávania pre pár neurónov,
Dp je očakávaný výstup neurónovej siete (väčšinou by sa sieť mala snažiť o 100% rozpoznanie, ale to sa v praxi zatiaľ nedeje) a konštrukcia O(Ip,W)2 je druhá mocnina výstupu siete, ktorá závisí od p-tého vstupu a nastavených váhových koeficientov W. Táto konštrukcia zahŕňa konvolučné jadrá aj váhové koeficienty všetkých vrstiev. Výpočet chyby spočíva vo výpočte aritmetického priemeru pre všetky páry neurónov.
Ako výsledok analýzy bola odvodená zákonitosť, že nominálnu hodnotu hmotnosti, keď je hodnota chyby minimálnu, možno vypočítať na základe závislosti (2):
![]() (2)
(2)
Z tejto závislosti môžeme povedať, že úlohou výpočtu optimálnej váhy je aritmetický rozdiel derivácie chybovej funkcie prvého rádu podľa hmotnosti, delený deriváciou chybovej funkcie druhého rádu.
Uvedené závislosti umožňujú triviálny výpočet chyby, ktorá je vo výstupnej vrstve. Výpočet chýb v skrytých vrstvách neurónov je možné realizovať pomocou metódy spätného šírenia chýb. Hlavnou myšlienkou metódy je šírenie informácií vo forme chybového signálu z výstupných neurónov na vstupné, to znamená v smere opačnom k šíreniu signálov cez neurónovú sieť.
Treba tiež poznamenať, že trénovanie siete sa vykonáva na špeciálne pripravených databázach obrázkov zaradených do veľkého počtu tried a trvá pomerne dlho.
K dnešnému dňu je najväčšou databázou ImageNet (www.image_net.org) . Má bezplatný prístup pre akademické inštitúcie.
Záver
V dôsledku vyššie uvedeného je potrebné poznamenať, že neurónové siete a algoritmy implementované na princípe ich fungovania môžu byť použité v systémoch rozpoznávania kariet odtlačkov prstov pre orgány vnútorných záležitostí. Často je to softvérová zložka softvérového a hardvérového komplexu zameraná na rozpoznanie takého jedinečného komplexného obrazu ako vzor, ktorý je identifikačným údajom, ktorý úplne nerieši úlohy, ktoré mu boli pridelené. Program implementovaný na základe algoritmov založených na neurónovej sieti bude oveľa efektívnejší.
Keď to zhrnieme, môžeme zhrnúť nasledovné:
● neurónové siete je možné využiť v problematike rozpoznávania obrazu aj textu;
● táto teória umožňuje hovoriť o vytvorení novej perspektívnej triedy modelov, a to modelov založených na inteligentnom modelovaní;
● neurónové siete sú schopné učenia, čo naznačuje možnosť optimalizácie procesu z fungovania. Táto možnosť je mimoriadne dôležitou možnosťou pre praktickú implementáciu algoritmu;
● Vyhodnotenie algoritmu rozpoznávania vzorov pomocou výskumu neurónovej siete môže mať kvantitatívnu hodnotu, resp. existujú mechanizmy na úpravu parametrov na požadovanú hodnotu pomocou výpočtu požadovaných váhových koeficientov.
Ďalšie štúdium neurónových sietí sa k dnešnému dňu javí ako perspektívna oblasť výskumu, ktorá sa úspešne uplatní v ešte viacerých odvetviach vedy a techniky, ako aj ľudských aktivít. Hlavný dôraz vo vývoji moderných rozpoznávacích systémov sa v súčasnosti presúva do oblasti sémantickej segmentácie 3D obrazov v geodézii, medicíne, prototypovaní a iných oblastiach ľudskej činnosti - ide o pomerne zložité algoritmy a je to spôsobené:
● s nedostatkom dostatočného počtu databáz referenčných obrázkov;
● nedostatok dostatočného počtu bezplatných odborníkov na úvodné zaškolenie systému;
● Obrázky sa neukladajú v pixeloch, čo si vyžaduje dodatočné zdroje od počítača aj od vývojárov.
Treba tiež poznamenať, že dnes existuje veľké množstvo štandardných architektúr na budovanie neurónových sietí, čo značne zjednodušuje úlohu budovania neurónovej siete od začiatku a redukuje ju na výber sieťovej štruktúry vhodnej pre konkrétnu úlohu.
V súčasnosti je na trhu pomerne veľké množstvo inovatívnych spoločností, ktoré sa zaoberajú rozpoznávaním obrazu pomocou technológií učenia neurónových sietí. S istotou je známe, že pomocou databázy 10 000 obrázkov dosiahli presnosť rozpoznávania obrázkov okolo 95 %. Všetky úspechy sa však týkajú statických obrázkov, s videosekvenciou je momentálne všetko oveľa komplikovanejšie.
Bibliografický odkaz
Markova S.V., Zhigalov K.Yu. APLIKÁCIA NEURÁLNEJ SIETE NA VYTVORENIE SYSTÉMU ROZPOZNÁVANIA OBRAZU // Fundamental Research. - 2017. - č.8-1. - S. 60-64;URL: http://fundamental-research.ru/ru/article/view?id=41621 (dátum prístupu: 24.03.2020). Dávame do pozornosti časopisy vydávané vydavateľstvom "Academy of Natural History"
Je urobený prehľad metód neurónových sietí používaných pri rozpoznávaní obrazu. Metódy neurónových sietí sú metódy založené na použití rôznych typov neurónových sietí (NN). Hlavné oblasti použitia rôznych NN na rozpoznávanie vzorov a obrázkov:
- aplikácia na extrahovanie kľúčových charakteristík alebo vlastností daných obrázkov,
- klasifikácia samotných obrázkov alebo charakteristík z nich už extrahovaných (v prvom prípade k extrakcii kľúčových charakteristík dochádza implicitne v rámci siete),
- riešenie optimalizačných problémov.
Architektúra umelých neurónových sietí má určité podobnosti s prirodzenými neurónovými sieťami. NN navrhnuté na riešenie rôznych problémov sa môžu výrazne líšiť vo fungujúcich algoritmoch, ale ich hlavné vlastnosti sú nasledovné.
NN sa skladá z prvkov nazývaných formálne neuróny, ktoré sú samy o sebe veľmi jednoduché a sú spojené s inými neurónmi. Každý neurón premieňa súbor signálov prichádzajúcich na jeho vstup na výstupný signál. Práve spojenia medzi neurónmi, zakódované váhami, zohrávajú kľúčovú úlohu. Jednou z výhod NN (ako aj nevýhodou pri ich implementácii na sekvenčnú architektúru) je, že všetky prvky môžu fungovať paralelne, čím sa výrazne zvyšuje efektivita riešenia problému, najmä pri spracovaní obrazu. Okrem toho, že neurónové siete umožňujú efektívne riešiť mnohé problémy, poskytujú výkonné flexibilné a univerzálne mechanizmy učenia, čo je ich hlavná výhoda oproti iným metódam (pravdepodobnostné metódy, lineárne separátory, rozhodovacie stromy atď.). Učenie eliminuje potrebu výberu kľúčových vlastností, ich významu a vzťahov medzi vlastnosťami. Napriek tomu výber počiatočnej reprezentácie vstupných dát (vektor v n-rozmernom priestore, frekvenčné charakteristiky, vlnky a pod.) výrazne ovplyvňuje kvalitu riešenia a je samostatnou otázkou. NN majú dobrú schopnosť generalizácie (lepšiu ako rozhodovacie stromy), t.j. môže úspešne rozšíriť skúsenosti získané na záverečnej tréningovej súprave na celú sadu obrázkov.
Opíšme si aplikáciu neurónových sietí na rozpoznávanie obrazu a všimnime si možnosti ich využitia na rozpoznanie osoby z obrazu tváre.
1. Viacvrstvové neurónové siete
Architektúra viacvrstvovej neurónovej siete (MNN) pozostáva zo sekvenčne spojených vrstiev, kde neurón každej vrstvy je svojimi vstupmi prepojený so všetkými neurónmi predchádzajúcej vrstvy a výstupmi ďalšej vrstvy. NN s dvoma rozhodovacími vrstvami môže aproximovať akúkoľvek viacrozmernú funkciu s akoukoľvek presnosťou. Neurónová sieť s jednou rozhodovacou vrstvou je schopná vytvárať lineárne deliace plochy, čo značne zužuje okruh úloh, ktoré riešia, najmä takáto sieť nedokáže vyriešiť problém typu „exkluzívny alebo“. NN s nelineárnou aktivačnou funkciou a dvoma rozhodovacími vrstvami umožňuje vytvárať ľubovoľné konvexné oblasti v priestore riešenia a s tromi rozhodovacími vrstvami - oblasti akejkoľvek zložitosti, vrátane nekonvexných. Zároveň MNS nestráca svoju zovšeobecňujúcu schopnosť. MNN sa trénuje pomocou algoritmu spätného šírenia chýb, čo je metóda gradientového zostupu v priestore váh, aby sa minimalizovala celková chyba siete. V tomto prípade sa chyby (presnejšie hodnoty korekcie hmotnosti) šíria opačným smerom od vstupov k výstupom, cez váhy spájajúce neuróny.
Najjednoduchšou aplikáciou jednovrstvovej NN (nazývanej autoasociatívna pamäť) je trénovať sieť na rekonštrukciu obrázkov kanálov. Privedením testovacieho obrazu na vstup a výpočtom kvality rekonštruovaného obrazu je možné odhadnúť, ako dobre sieť rozpoznala vstupný obraz. Pozitívne vlastnosti tejto metódy spočívajú v tom, že sieť dokáže obnoviť skreslený a zašumený obraz, ale nie je vhodná na vážnejšie účely.
Ryža. 1. Viacvrstvová neurónová sieť na klasifikáciu obrazu. Neurón s najvyššou aktivitou (tu prvý) označuje príslušnosť k rozpoznanej triede.
MNN sa používa aj na priamu klasifikáciu obrázkov – vstupom je buď samotný obrázok v nejakej forme, alebo súbor predtým extrahovaných kľúčových charakteristík obrázku, na výstupe neurón s maximálnou aktivitou indikuje príslušnosť k rozpoznanej triede (obr. 1). Ak je táto aktivita pod určitou hranicou, potom sa má za to, že predložený obrázok nepatrí do žiadnej zo známych tried. Proces učenia stanovuje súlad vstupných obrázkov s príslušnosťou k určitej triede. Toto sa nazýva učenie pod dohľadom. Pri použití na rozpoznávanie tvárí je tento prístup vhodný pre úlohy riadenia prístupu pre malú skupinu ľudí. Tento prístup poskytuje priame porovnanie samotných obrázkov sieťou, ale s nárastom počtu tried exponenciálne narastá čas školenia a prevádzky siete. Preto pri úlohách, ako je vyhľadávanie podobnej osoby vo veľkej databáze, je potrebné extrahovať kompaktný súbor kľúčových funkcií, z ktorých sa bude hľadať.
Klasifikačný prístup využívajúci frekvenčné charakteristiky celého obrazu je opísaný v . Použil sa jednovrstvový NS založený na viachodnotových neurónoch. 100% rozpoznanie bolo zaznamenané v databáze MIT, ale rozpoznanie bolo vykonané medzi obrázkami, s ktorými bola sieť trénovaná.
Použitie MNS na klasifikáciu obrazov tváre na základe charakteristík, ako sú vzdialenosti medzi určitými špecifickými časťami tváre (nos, ústa, oči) je popísané v . V tomto prípade boli tieto vzdialenosti aplikované na vstup NS. Používali sa aj hybridné metódy - v prvej sa na vstup neurónovej siete privádzali výsledky spracovania skrytým Markovovým modelom a pri druhej sa na vstup neurónovej siete privádzal výsledok práce neurónovej siete. Markov model. V druhom prípade neboli pozorované žiadne výhody, čo naznačuje, že výsledok klasifikácie NA je dostatočný.
B ukazuje použitie NN na klasifikáciu obrazu, keď sieťový vstup prijíma výsledky rozkladu obrazu metódou hlavných komponentov.
V klasickom MNS sú medzivrstvové neurónové spojenia plne prepojené a obraz je reprezentovaný ako jednorozmerný vektor, hoci je dvojrozmerný. Architektúra konvolučnej neurónovej siete má za cieľ tieto nedostatky prekonať. Využíval lokálne receptorové polia (poskytujúce lokálnu dvojrozmernú konektivitu neurónov), všeobecné váhy (poskytujúce detekciu niektorých znakov kdekoľvek na obrázku) a hierarchickú organizáciu s priestorovým podvzorkovaním (priestorové podvzorkovanie). Konvolučný NN (CNN) poskytuje čiastočnú odolnosť voči zmenám mierky, posunom, rotáciám, deformáciám. Architektúra SNS pozostáva z mnohých vrstiev, z ktorých každá má niekoľko rovín a neuróny ďalšej vrstvy sú spojené len s malým počtom neurónov predchádzajúcej vrstvy z okolia lokálnej oblasti (ako v ľudskom vizuálnom kôra). Váhy v každom bode tej istej roviny sú rovnaké (konvolučné vrstvy). Po konvolučnej vrstve nasleduje vrstva, ktorá zmenšuje svoj rozmer lokálnym spriemerovaním. Potom opäť konvolučná vrstva a tak ďalej. Tým sa dosiahne hierarchická organizácia. Neskoršie vrstvy extrahujú všeobecnejšie prvky, ktoré sú menej závislé od skreslenia obrazu. CNN je trénovaná štandardnou metódou spätného šírenia. Porovnanie MHC a SNA ukázalo významné výhody posledne menovaného z hľadiska rýchlosti a spoľahlivosti klasifikácie. Užitočnou vlastnosťou CNN je, že charakteristiky generované na výstupoch z vyšších vrstiev hierarchie možno použiť na klasifikáciu metódou najbližšieho suseda (napríklad výpočtom euklidovskej vzdialenosti) a CNN dokáže takéto charakteristiky úspešne extrahovať. pre obrázky, ktoré nie sú v tréningovej sade. SNS sa vyznačuje rýchlym učením sa a rýchlosťou práce. Testovanie CNN na databáze ORL, ktorá obsahuje obrázky tvárí s malými zmenami osvetlenia, mierky, priestorových rotácií, polohy a rôznych emócií, ukázalo približne 98% presnosť rozpoznávania a pre známe tváre boli prezentované varianty ich obrázkov, ktoré boli nie v tréningovej súprave. Tento výsledok robí túto architektúru sľubnou pre ďalší vývoj v oblasti rozpoznávania obrazu priestorových objektov.
MNS sa používajú aj na detekciu objektov určitého typu. Okrem toho, že každý trénovaný MNS dokáže do určitej miery určiť príslušnosť obrázkov k „svojim“ triedam, môže byť špeciálne trénovaný na spoľahlivé zistenie určitých tried. V tomto prípade budú výstupnými triedami triedy, ktoré patria a nepatria do daného typu obrázka. Na detekciu obrazu tváre na vstupnom obrázku bol použitý detektor neurónovej siete. Obraz bol naskenovaný oknom 20x20 pixelov, ktoré bolo privedené na vstup siete, ktorá rozhoduje o tom, či daná oblasť patrí do triedy tvárí. Školenie sa uskutočnilo s použitím pozitívnych príkladov (rôzne obrázky tvárí) aj negatívnych príkladov (obrázky, ktoré nie sú tvárami). Na zlepšenie spoľahlivosti detekcie bol použitý tím NN vyškolený s rôznymi počiatočnými váhami, v dôsledku čoho sa NN dopúšťali chýb rôznymi spôsobmi a konečné rozhodnutie padlo hlasovaním celého tímu.
Ryža. 2. Hlavné komponenty (vlastné tváre) a rozklad obrazu na hlavné komponenty.
NN sa tiež používa na extrakciu kľúčových charakteristík obrazu, ktoré sa potom používajú na následnú klasifikáciu. V , je znázornený spôsob implementácie metódy analýzy hlavných komponentov neurónovej siete. Podstatou metódy analýzy hlavných komponentov je získanie maximálne dekorovaných koeficientov, ktoré charakterizujú vstupné vzory. Tieto koeficienty sa nazývajú hlavné komponenty a používajú sa na štatistickú kompresiu obrazu, pri ktorej sa na reprezentáciu celého obrazu používa malý počet koeficientov. NN s jednou skrytou vrstvou obsahujúcou N neurónov (ktorá je oveľa menšia ako rozmer obrazu), trénovaná metódou spätného šírenia chýb na obnovenie vstupného obrazu na výstupe, generuje koeficienty prvých N hlavných komponentov na výstupe skryté neuróny, ktoré slúžia na porovnanie. Zvyčajne sa používa 10 až 200 hlavných komponentov. S rastúcim počtom komponentov sa jeho reprezentatívnosť výrazne znižuje a nemá zmysel používať komponenty s veľkými číslami. Pri použití nelineárnych aktivačných funkcií neurónových prvkov je možný nelineárny rozklad na hlavné zložky. Nelinearita vám umožňuje presnejšie odrážať variácie vo vstupných údajoch. Aplikovaním analýzy hlavných komponentov na dekompozíciu obrazov tvárí získame hlavné komponenty, nazývané vlastné tváre (holony v práci), ktoré majú tiež užitočnú vlastnosť - sú to komponenty, ktoré odrážajú najmä také základné charakteristiky tváre, ako je pohlavie, rasa, emócie. . Po obnove majú komponenty vzhľad podobný tvári, pričom prvý odráža najvšeobecnejší tvar tváre, druhý predstavuje rôzne menšie rozdiely medzi tvárami (obr. 2). Táto metóda je dobre použiteľná na vyhľadávanie podobných obrázkov tvárí vo veľkých databázach. Ukazuje sa aj možnosť ďalšieho zmenšovania rozmeru hlavných komponentov pomocou NS. Vyhodnotením kvality rekonštrukcie vstupného obrazu sa dá veľmi presne určiť, či patrí do triedy tvárí.
AlexNet je konvolučná neurónová sieť, ktorá mala veľký vplyv na vývoj strojového učenia, najmä na algoritmy počítačového videnia. Sieť vyhrala v roku 2012 ImageNet LSVRC-2012 Image Recognition Contest s veľkým náskokom (s chybovosťou 15,3 % oproti 26,2 % za druhé miesto).
Architektúra AlexNet je podobná sieti LeNet, ktorú vytvoril Yann LeCum. AlexNet má však viac filtrov na jednotlivé vrstvy a vnorených konvolučných vrstiev. Sieť zahŕňa konvolúcie, maximálne združovanie, výpadky, rozširovanie dát, aktivačné funkcie ReLU a stochastický gradientový zostup.
Vlastnosti
- Ako aktivačná funkcia sa Relu používa namiesto arkus tangens na pridanie nelinearity do modelu. Vďaka tomu sa pri rovnakej presnosti metódy rýchlosť zvýši 6-krát.
- Použitie výpadku namiesto regularizácie rieši problém nadmerného vybavenia. Tréningový čas sa však zdvojnásobí s mierou výpadku 0,5.
- Prekrývajúce sa spojenia sa vykonávajú na zmenšenie veľkosti siete. Vďaka tomu sa chybovosť prvej a piatej úrovne znižuje na 0,4 % a 0,3 %.
Dataset ImageNet
ImageNet je súbor 15 miliónov označených obrázkov s vysokým rozlíšením rozdelených do 22 000 kategórií. Obrázky sa zhromažďujú online a ručne sa označujú pomocou crowdsourcingu Amazon Mechanical Turk. Od roku 2010 sa každoročne organizuje ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) ako súčasť Pascal Visual Object Challenge. Výzva využíva časť súboru údajov ImageNet s 1 000 obrázkami v každej z 1 000 kategórií. Celkovo existuje 1,2 milióna tréningových obrázkov, 50 000 overovacích obrázkov a 150 000 testovacích obrázkov. ImageNet pozostáva z obrázkov s rôznym rozlíšením. Preto sú pre konkurenciu zmenšené na pevné rozlíšenie 256 × 256. Ak bol obrázok pôvodne obdĺžnikový, potom je orezaný na štvorec v strede obrázka.
Architektúra
Obrázok 1Architektúra siete je znázornená na obrázku 1. AlexNet obsahuje osem vážených vrstiev. Prvých päť z nich je konvolučných a zvyšné tri sú plne prepojené. Výstup prechádza cez stratovú funkciu softmax, ktorá generuje distribúciu 1000 triednych štítkov. Sieť maximalizuje multilineárnu logistickú regresiu, čo je ekvivalentné maximalizácii priemeru za všetky prípady trénovania logaritmu pravdepodobnosti správneho označenia rozdelenia očakávaní. Jadrá druhej, štvrtej a piatej konvolučnej vrstvy sú spojené iba s tými mapami jadra v predchádzajúcej vrstve, ktoré sú na rovnakom GPU. Jadrá tretej konvolučnej vrstvy sú spojené so všetkými mapami jadier druhej vrstvy. Neuróny v plne prepojených vrstvách sú spojené so všetkými neurónmi v predchádzajúcej vrstve.
AlexNet teda obsahuje 5 konvolučných vrstiev a 3 plne prepojené vrstvy. Relu sa nanáša po každej konvolučnej a úplne spojenej vrstve. Dropout sa aplikuje pred prvou a druhou úplne spojenou vrstvou. Sieť obsahuje 62,3 milióna parametrov a minie 1,1 miliardy výpočtov pri prechode dopredu. Konvolučné vrstvy, ktoré predstavujú 6 % všetkých parametrov, vykonávajú 95 % výpočtov.
Vzdelávanie
AlexNet prechádza 90 epochami. Tréning trvá 6 dní súčasne na dvoch GPU Nvidia Geforce GTX 580, čo je dôvod, prečo je sieť rozdelená na dve časti. Použije sa stochastický gradientový zostup s rýchlosťou učenia 0,01, hybnosťou 0,9 a poklesom hmotnosti 0,0005. Rýchlosť učenia sa po saturácii presnosti vydelí 10 a počas tréningu sa zníži o faktor 3. Schéma aktualizácie hmotnosti w vyzerá ako:

kde i- iteračné číslo, v je premenná hybnosti a epsilon- rýchlosť učenia. Počas celej tréningovej fázy bola rýchlosť učenia zvolená rovnako pre všetky vrstvy a manuálne korigovaná. Ďalšou heuristikou bolo vydeliť rýchlosť učenia 10, keď počet chýb validácie prestal klesať.
Príklady použitia a implementácie
Výsledky ukazujú, že veľká, hlboká konvolučná neurónová sieť je schopná dosiahnuť rekordné výsledky na veľmi zložitých súboroch údajov iba s použitím učenia pod dohľadom. Rok po zverejnení AlexNet začali všetci účastníci súťaže ImageNet využívať konvolučné neurónové siete na riešenie klasifikačného problému. AlexNet bola prvou implementáciou konvolučných neurónových sietí a otvorila novú éru výskumu. Teraz je jednoduchšie implementovať AlexNet pomocou knižníc hlbokého učenia: PyTorch, TensorFlow, Keras.
Výsledok
Sieť dosahuje ďalšiu úroveň chýb prvej a piatej úrovne: 37,5 % a 17,0 %. Najlepší výkon dosiahnutý počas súťaže ILSVRC-2010 bol 47,1 % a 28,2 % pri použití prístupu, ktorý spriemeruje predpovede zo šiestich riedko kódovaných modelov trénovaných na rôznych vektoroch znakov. Odvtedy sa dosiahli výsledky 45,7 % a 25,7 % pomocou prístupu, ktorý spriemeruje predpovede dvoch klasifikátorov vyškolených na Fisherových vektoroch. Výsledky ILSVRC-2010 sú uvedené v tabuľke 1.

 Vľavo: Osem testovacích obrázkov ILSVRC-2010 a päť štítkov, ktoré model považuje za najpravdepodobnejšie. Správne označenie je napísané pod každým obrázkom a pravdepodobnosť je zobrazená ako červený pruh, ak je v prvej päťke. Vpravo: päť testovacích obrázkov ILSVRC-2010 v prvom stĺpci. Zvyšné stĺpce zobrazujú šesť tréningových obrázkov.
Vľavo: Osem testovacích obrázkov ILSVRC-2010 a päť štítkov, ktoré model považuje za najpravdepodobnejšie. Správne označenie je napísané pod každým obrázkom a pravdepodobnosť je zobrazená ako červený pruh, ak je v prvej päťke. Vpravo: päť testovacích obrázkov ILSVRC-2010 v prvom stĺpci. Zvyšné stĺpce zobrazujú šesť tréningových obrázkov. Úvod
Predmetom tohto výskumu je vývoj systému rozpoznávania obrazu založeného na aparáte umelých neurónových sietí. Úloha rozpoznávania obrazu je veľmi dôležitá, keďže možnosť automatického rozpoznávania obrazu počítačom prináša veľa nových príležitostí v rozvoji vedy a techniky, ako je vývoj systémov na vyhľadávanie tvárí a iných objektov na fotografiách, kontrola kvality vyrábané produkty bez ľudského zásahu, automatické riadenie dopravy a mnohé iné.
Čo sa týka umelých neurónových sietí, v posledných rokoch sa táto sekcia strojového učenia čoraz viac rozvíjala vďaka výraznému zvýšeniu výpočtového výkonu existujúcich počítačov a rozšírenému využívaniu grafických kariet pre výpočtovú techniku, čo umožňuje trénovať neurónové siete oveľa väčších rozmerov. hĺbku a zložitú štruktúru ako predtým, ktoré zase vykazujú výrazne lepšie výsledky v porovnaní s inými algoritmami pre mnohé problémy, najmä problém rozpoznávania obrazu. Tento smer vo vývoji neurónových sietí sa nazýva hlboké učenie (“deep learning”) a je jedným z najúspešnejších a najrýchlejšie sa rozvíjajúcich v súčasnosti. Napríklad podľa výsledkov každoročnej súťaže ImageNet-2014 v rozpoznávaní obrázkov veľká väčšina úspešných algoritmov využívala hlboké konvolučné siete.
Keďže problém rozpoznávania obrázkov je veľmi rozsiahly a vo väčšine prípadov si vyžaduje samostatný prístup pre rôzne typy obrázkov, je takmer nemožné uvažovať o probléme rozpoznávania obrázkov ako o celku v rámci jednej štúdie, preto bolo rozhodnuté napr. napríklad samostatne zvážiť takú podúlohu rozpoznávania obrazu, ako je rozpoznávanie dopravných značiek.
Hlavným cieľom tejto štúdie teda bolo vyvinúť systém rozpoznávania obrazu založený na umelých neurónových sieťach pre obrazy dopravných značiek. Na dosiahnutie tohto cieľa boli sformulované tieto úlohy:
Vykonanie analytického prehľadu literatúry na tému umelých neurónových sietí a ich aplikácie na problém rozpoznávania obrazu
Vývoj algoritmu na rozpoznávanie dopravných značiek pomocou aparátu umelých neurónových sietí
Vývoj prototypu systému rozpoznávania obrazu založeného na vyvinutom algoritme. Výsledkom tejto úlohy by mal byť softvérový balík, ktorý umožní používateľovi nahrať obrázok a získať predpoveď triedy tohto obrázka
Vykonávanie experimentálnych štúdií. Je potrebné vykonať výskum a vyhodnotiť presnosť výsledného algoritmu
V priebehu štúdie boli všetky úlohy splnené. Konkrétne výsledky pre každý z nich budú popísané v hlavnej časti práce.
1. Prehľad literatúry
.1 Strojové učenie
Neurónové siete, o ktorých sa podrobne hovorí v tomto článku, sú jednou z odrôd algoritmov strojového učenia alebo strojového učenia. Strojové učenie je jednou z podoblastí umelej inteligencie. Hlavnou vlastnosťou algoritmov strojového učenia je ich schopnosť učiť sa v procese. Napríklad algoritmus na zostavenie rozhodovacieho stromu, ktorý nemá žiadne predchádzajúce informácie o tom, čo sú to dáta a aké vzory v nich existujú, ale iba nejakú vstupnú množinu objektov a hodnoty niektorých funkcií pre každý z nich, spolu s označenie triedy, v procese budovania samotného stromu odhaľuje skryté vzorce, to znamená, že sa učí a po naučení je schopný predpovedať triedu už pre nové objekty, ktoré predtým nevidel.
Existujú dva hlavné typy strojového učenia: učenie pod dohľadom a učenie bez dozoru. Riadené učenie predpokladá, že algoritmus okrem samotných počiatočných údajov dostane o nich aj niektoré ďalšie informácie, ktoré môže neskôr použiť na učenie. Najpopulárnejšie problémy pre kontrolované učenie sú klasifikačné a regresné problémy. Klasifikačný problém možno formulovať napríklad takto: ak máme určitú množinu objektov, z ktorých každý patrí do jednej z niekoľkých tried, je potrebné určiť, do ktorej z týchto tried nový objekt patrí. Úloha rozpoznávania dopravných značiek, o ktorej sme uvažovali v tejto práci, je typickým typom klasifikačného problému: existuje niekoľko typov dopravných značiek - tried a úlohou algoritmu je značku „rozpoznať“, to znamená priraďte ho jednej z existujúcich tried.
Učenie bez dozoru sa líši od učenia pod dohľadom v tom, že algoritmu sa neposkytujú žiadne ďalšie informácie okrem samotného počiatočného súboru údajov. Najpopulárnejším príkladom problému učenia bez dozoru je problém zhlukovania. Podstata problému zhlukovania je nasledovná: vstupom do algoritmu je určitý počet objektov patriacich do rôznych tried (ale ktorá trieda patrí ku ktorému objektu nie je známa, počet tried samotných môže byť tiež neznámy) a cieľ algoritmu je rozdeliť túto množinu objektov na podmnožiny "podobných" objektov, to znamená, že patria do rovnakej triedy.
Medzi všetkými algoritmami strojového učenia existuje niekoľko hlavných rodín. Pokiaľ ide o problém klasifikácie, medzi najobľúbenejšie takéto rodiny patria napríklad:
· Klasifikátory založené na pravidlách - hlavnou myšlienkou takýchto klasifikátorov je hľadanie pravidiel na klasifikáciu objektov do konkrétnej triedy vo forme „AK - POTOM“. Na vyhľadávanie takýchto pravidiel sa zvyčajne používajú niektoré štatistické metriky a bežná je aj konštrukcia pravidiel na základe rozhodovacieho stromu.
· Logistická regresia – hlavnou myšlienkou je nájsť lineárnu rovinu, ktorá najpresnejšie rozdelí priestor na dva polpriestory tak, aby predmety rôznych tried patrili do rôznych polpriestorov. V tomto prípade sa hľadá rovnica cieľovej roviny ako lineárna kombinácia vstupných parametrov. Na trénovanie takéhoto klasifikátora možno použiť napríklad metódu gradientového zostupu.
Bayesovský klasifikátor – ako už názov napovedá, klasifikátor vychádza z Bayesovej vety, ktorá je zapísaná v tvare
strojové učenie neurónovej siete
Myšlienkou klasifikátora je v tomto prípade nájsť triedu s maximálnou zadnou pravdepodobnosťou za predpokladu, že všetky parametre majú rovnaké hodnoty, aké majú pre klasifikovaný prípad. Vo všeobecnom prípade táto úloha zahŕňa predchádzajúce znalosti o veľmi veľkom počte podmienených pravdepodobností, a teda veľkú veľkosť trénovacej vzorky a vysokú výpočtovú zložitosť, preto sa v praxi najčastejšie používa typ bayesovského klasifikátora nazývaný naivný Bayesov klasifikátor. použitý, v ktorom sa predpokladá, že všetky parametre sú na sebe nezávislé.vzájomne, respektíve vzorec nadobúda oveľa jednoduchšiu podobu a vyžaduje len malý počet podmienených pravdepodobností na jeho použitie.

Hoci tento predpoklad je zvyčajne ďaleko od reality, klasifikátor Naive Bayes často funguje dobre.
Rozhodovacie stromy - v zjednodušenej forme tento algoritmus spočíva v zostavení stromu, v ktorom každý uzol zodpovedá nejakému testu, ktorý sa vykonáva na parametroch objektu a listy sú finálne triedy. Existuje mnoho druhov rozhodovacích stromov a algoritmov na ich konštrukciu. Napríklad jeden z najpopulárnejších algoritmov je C4.5.
· Neurónové siete - model reprezentovaný ako množina prvkov (neurónov) a spojení medzi nimi, ktoré môžu byť vo všeobecnom prípade smerované alebo nie a majú určitú váhu. Počas činnosti neurónovej siete časť jej neurónov, nazývaná vstupy, prijíma signál (vstupné dáta), ktorý sa nejakým spôsobom šíri a transformuje a na výstupe siete (výstupné neuróny) je vidieť výsledok tzv. siete, napríklad pravdepodobnosti jednotlivých tried. Neurónovým sieťam sa v tejto práci budeme venovať podrobnejšie v ďalšej časti.
Podporné vektorové stroje - koncepcia algoritmu je rovnaká ako v prípade logistickej regresie, pri hľadaní oddeľujúcej roviny (alebo viacerých rovín), avšak spôsob hľadania tejto roviny je v tomto prípade odlišný - rovina hľadá sa taká, aby vzdialenosť od nej k najbližším bodom - predstaviteľom oboch tried bola čo najväčšia, na čo sa zvyčajne používajú kvadratické optimalizačné metódy.
· Lenivé klasifikátory (Lazy learningers) – špeciálny druh klasifikačných algoritmov, ktoré namiesto toho, aby vopred zostavili model a následne na jeho základe rozhodovali o zaradení objektu do konkrétnej triedy, sú založené na myšlienke, že podobné objekty najčastejšie mať jednu a tú istú triedu. Keď takýto algoritmus prijme objekt na klasifikáciu ako vstup, vyhľadá podobné objekty medzi predtým prezeranými objektmi a pomocou informácií o ich triedach vytvorí vlastnú predpoveď týkajúcu sa triedy cieľového objektu.
Je vidieť, že klasifikačné algoritmy môžu mať veľmi odlišné myšlienky a vo svojom základe a samozrejme vykazujú rôznu účinnosť pre rôzne typy úloh. Takže pri problémoch s malým počtom vstupných prvkov môžu byť systémy založené na pravidlách užitočné, ak je pre vstupné objekty možné rýchlo a pohodlne vypočítať nejakú metriku podobnosti - lenivé klasifikátory, ale ak hovoríme o problémoch s veľmi veľkým Množstvo parametrov, ktoré sa navyše ťažko identifikujú alebo interpretujú, ako je rozpoznávanie obrazu alebo reči, sa neurónové siete stávajú najvhodnejšou klasifikačnou metódou.
1.2 Neurónové siete
Umelé neurónové siete sú jedným zo všeobecne známych a používaných modelov strojového učenia. Myšlienka umelých neurónových sietí je založená na napodobňovaní nervového systému zvierat a ľudí.
Zjednodušený model nervového systému zvierat je prezentovaný ako systém buniek, z ktorých každá má telo a vetvy dvoch typov: dendrity a axóny. V určitom momente bunka prijíma signály od iných buniek cez dendrity a ak sú tieto signály dostatočne silné, dochádza k excitácii a toto budenie prenáša cez axóny na ďalšie bunky, s ktorými je spojená. Signál (excitácia) sa teda šíri po celom nervovom systéme. Model neurónovej siete je štruktúrovaný podobným spôsobom. Neurónová sieť pozostáva z neurónov a riadených spojení medzi nimi, pričom každé spojenie má určitú váhu. Niektoré z neurónov sú zároveň vstupné – prijímajú dáta z vonkajšieho prostredia. Potom v každom kroku neurón prijme signál zo všetkých vstupných neurónov, vypočíta vážený súčet signálov, aplikuje naň nejakú funkciu a výsledok odovzdá každému zo svojich výstupov. Sieť má tiež určitý počet výstupných neurónov, ktoré tvoria výsledok siete. Takže pre problém klasifikácie môžu výstupné hodnoty týchto neurónov znamenať predpovedané pravdepodobnosti každej z tried pre vstupný objekt. Trénovanie neurónovej siete teda spočíva vo výbere takých váh pre spojenia medzi neurónmi, aby sa výstupné hodnoty pre všetky vstupné dáta čo najviac približovali skutočným.
Existuje niekoľko hlavných typov architektúr neurónových sietí:
Feed-forward network – znamená, že neuróny a spojenia medzi nimi tvoria acyklický graf, kde sa signály šíria len jedným smerom. Práve tieto siete sú najpopulárnejšie a najštudovanejšie a ich školenie predstavuje najmenšie ťažkosti.
Rekurentné neurónové siete (rekurentné neurónové siete) - v takýchto sieťach, na rozdiel od sietí priameho šírenia, môžu byť signály prenášané oboma smermi a môžu doraziť na ten istý neurón niekoľkokrát v procese spracovania jednej vstupnej hodnoty. Konkrétnym typom rekurentných neurónových sietí je napríklad Boltzmannov stroj. Hlavným problémom pri práci s takýmito sieťami je ich školenie, pretože vytvorenie efektívneho algoritmu na to je vo všeobecnosti náročná úloha a stále nemá univerzálne riešenie.
· Samoorganizujúce sa Kohonenove mapy - neurónová sieť určená predovšetkým na zhlukovanie a vizualizáciu dát.
V histórii vývoja neurónových sietí existujú 3 hlavné obdobia rastu. Prvý výskum v oblasti umelých neurónových sietí sa datuje do 40. rokov 20. storočia. V roku 1954 J. McCulloch a W. Pitts publikovali prácu „The logic calculus of ideas related to nervove activity“, ktorá načrtla základné princípy konštrukcie umelých neurónových sietí. V roku 1949 vyšla kniha D. Hebba „Organizácia správania“, kde sa autor zamýšľal nad teoretickými základmi trénovania neurónových sietí a po prvýkrát sformuloval koncept trénovania neurónových sietí ako nastavenie váh medzi neurónmi. V roku 1954 W. Clark urobil prvý pokus implementovať analógovú sieť Hebb pomocou počítača. V roku 1958 F. Rosenblatt navrhol model perceptrónu, čo bola v podstate neurónová sieť s jednou skrytou vrstvou. Hlavný pohľad na Rosenblattov perceptrón je znázornený na obrázku 1.

Obrázok 1. Rosenblatt Perceptron
Tento model bol natrénovaný pomocou metódy korekcie chýb, ktorá spočívala v tom, že váhy zostávajú nezmenené, pokiaľ je výstupná hodnota perceptrónu správna, v prípade chyby sa váha spoja zmení o 1 naopak. smer k chybe. Tento algoritmus, ako dokázal Rosenblatt, vždy konverguje. Pomocou takéhoto modelu bolo možné vytvoriť počítač, ktorý rozpoznáva niektoré písmená latinskej abecedy, čo malo v tom čase nepochybne veľký úspech.
Záujem o neurónové siete však výrazne klesol po vydaní knihy „Perceptróny“ od M. Minského a S. Paperta v roku 1969, kde popísali výrazné obmedzenia, ktoré perceptrónový model má, najmä nemožnosť reprezentovať exkluzívny, resp. funkcie, a poukázal aj na príliš vysoké požiadavky na požadovaný výpočtový výkon počítačov pre trénovanie neurónových sietí. Keďže títo vedci mali vo vedeckej komunite veľmi vysokú autoritu, neurónové siete boli nejaký čas uznávané ako neperspektívna technológia. Situácia sa zmenila až po vytvorení algoritmu backpropagation v roku 1974.
Algoritmus spätného šírenia navrhli v roku 1974 súčasne a nezávisle dvaja vedci, P. Verbos a A. Galushkin. Tento algoritmus je založený na metóde gradientového zostupu. Hlavnou myšlienkou algoritmu je šíriť chybové informácie zo sieťových výstupov na jej vstupy, teda v opačnom smere ako je štandardný prístup. V tomto prípade sa váhy odkazov upravia na základe informácie o chybe, ktorá sa k nim dostala. Hlavnou požiadavkou tohto algoritmu je, že aktivačná funkcia neurónov musí byť diferencovateľná, pretože metóda gradientového zostupu, čo nie je prekvapujúce, sa vypočítava na základe gradientu.
Algoritmus backpropagation uľahčuje trénovanie siete, ktorá má niekoľko skrytých vrstiev, čo vám umožňuje obísť obmedzenia perceptrónu, ktoré predtým blokovali rozvoj tohto odvetvia. Z matematického hľadiska je tento algoritmus zredukovaný na sekvenčné násobenie matíc - čo je pomerne dobre preštudovaný a optimalizovaný problém. Okrem toho je tento algoritmus dobre paralelizovaný, čo môže výrazne urýchliť čas tréningu siete. To všetko spolu viedlo k novému rozkvetu neurónových sietí a množstvu aktívneho výskumu v tomto smere.
Algoritmus spätného šírenia má zároveň množstvo problémov. Použitie gradientového zostupu teda zahŕňa riziko konvergencie k lokálnemu minimu. Ďalším dôležitým problémom je dlhý čas učenia algoritmu v prítomnosti veľkého počtu vrstiev, pretože chyba v procese spätného šírenia má tendenciu klesať viac a viac, keď sa blíži začiatok siete, respektíve trénovanie počiatočných vrstiev. siete bude extrémne pomalý. Ďalšou nevýhodou neurónových sietí vo všeobecnosti je náročnosť interpretácie výsledkov ich práce. Model trénovanej neurónovej siete je akousi čiernou skrinkou, ktorej vstupom je objekt a výstupom predpoveď, avšak zvyčajne je dosť problematické určiť, ktoré vlastnosti vstupného objektu boli brané do úvahy a ktoré z neurónov. je zodpovedný za čo. Vďaka tomu sú neurónové siete oveľa menej atraktívne v porovnaní napríklad s rozhodovacími stromami, v ktorých samotný trénovaný model predstavuje určitú kvintesenciu vedomostí o predmetnej oblasti a pre výskumníka je ľahké pochopiť, prečo bol tento objekt priradený konkrétnemu trieda.
Tieto nevýhody v kombinácii so skutočnosťou, že aj keď neurónové siete fungovali dobre, tieto výsledky boli porovnateľné s výsledkami iných klasifikátorov, ako sú napríklad stále populárnejšie podporné vektorové stroje, zatiaľ čo výsledky druhých sa dali oveľa ľahšie interpretovať a trénovanie si vyžadovalo menej času, viedlo k ďalšiemu poklesu rozvoja neurónových sietí.
Tento úpadok sa skončil až v roku 2000 21. storočia, keď sa objavil a začal šíriť koncept hlbokého učenia alebo hlbokého učenia. Oživenie neurónových sietí uľahčil vznik nových architektúr, ako sú konvolučné siete, obmedzené bolzmanove stroje, stohované autoenkódery atď., ktoré umožnili dosiahnuť výrazne lepšie výsledky v takých oblastiach strojového učenia, ako je rozpoznávanie obrazu a reči. Podstatným faktorom pre ich vývoj bol aj vznik a rozšírenie výkonných grafických kariet a ich využitie pre výpočtové úlohy. Grafické karty, ktoré sa líšia výrazne väčším počtom jadier v porovnaní s procesorom, aj keď s menším výkonom, sú ideálne na trénovanie neurónových sietí. To v kombinácii s nedávno výrazne zvýšeným výkonom počítačov vo všeobecnosti a rozšírením výpočtových klastrov umožnilo trénovať podstatne zložitejšie a hlbšie architektúry neurónových sietí ako doteraz.
1.3
hlbokýučenie
Jedným z najdôležitejších problémov, ktorým musí človek čeliť pri používaní algoritmov strojového učenia, je problém výberu správnych funkcií, na základe ktorých sa školenie vykonáva. Tento problém sa stáva obzvlášť závažným pri zvažovaní úloh, ako je rozpoznávanie obrazu, rozpoznávanie reči, spracovanie prirodzeného jazyka a podobne, teda také, pri ktorých neexistuje zrejmý súbor funkcií, ktoré možno použiť na učenie. Zvyčajne výber súboru funkcií na školenie vykonáva samotný výskumník prostredníctvom nejakej analytickej práce a práve vybraný súbor funkcií do značnej miery určuje úspešnosť algoritmu. Takže pre problém s rozpoznávaním obrazu môže ako takéto znaky slúžiť prevládajúca farba v obraze, stupeň jej zmeny, prítomnosť jasných hraníc v obraze alebo niečo iné. Otázkou rozpoznávania obrazu a výberom správnych funkcií sa budeme podrobnejšie zaoberať v príslušnej kapitole.
Tento prístup má však značné nevýhody. Po prvé, tento prístup zahŕňa značné množstvo práce na identifikáciu prvkov a túto prácu vykonáva výskumník manuálne a môže byť časovo náročná. Po druhé, identifikácia znakov, na základe ktorých je možné získať kvalitatívny algoritmus, sa v tomto prípade stáva prevažne náhodnou, navyše je nepravdepodobné, že by znaky, ktoré môžu mať dôležitý vplyv na vnútornú štruktúru obrazu, brať do úvahy, ale keď to nie je pre ľudí zrejmé. Myšlienka automatickej detekcie funkcií, ktoré možno neskôr použiť na fungovanie algoritmov strojového učenia, teda vyzerá obzvlášť atraktívne. A to je práve príležitosť, ktorú poskytuje využitie prístupu hlbokého učenia.
Z pohľadu teórie strojového učenia je hlboké učenie podmnožinou takzvaného reprezentačného učenia. Hlavnou koncepciou učenia sa reprezentácií je práve automatické vyhľadávanie vlastností, na základe ktorých bude v budúcnosti fungovať nejaký algoritmus, napríklad klasifikácia.
Na druhej strane, ďalším dôležitým problémom, s ktorým sa človek musí stretnúť pri používaní strojového učenia, je prítomnosť variačných faktorov, ktoré môžu mať významný vplyv na vzhľad pôvodných údajov, ale nesúvisia s ich samotnou podstatou, ktorou výskumník je. snažím sa analyzovať.. Takže v probléme rozpoznávania obrazu môžu byť takými faktormi uhol, pod ktorým je objekt na obrázku otočený smerom k pozorovateľovi, denná doba, osvetlenie atď. Takže podľa uhla pohľadu a počasia môže mať červené auto na fotke iný odtieň a tvar. Preto sa pri takýchto úlohách, ako je identifikácia objektu zobrazeného na fotografii, zdá rozumné brať do úvahy nie špecifické skutočnosti nízkej úrovne, ako je farba konkrétneho pixelu, ale charakteristiky vyššej úrovne abstrakcie, ako napr. prítomnosť kolies. Je však zrejmé, že určiť, či má kolesá na základe pôvodného obrázku, nie je triviálna úloha a jej priame riešenie môže byť veľmi náročné. Prítomnosť kolies je navyše len jedným z obrovského množstva možných znakov a určenie všetkých z nich a zostavenie algoritmov na kontrolu ich prítomnosti na obrázku nevyzerá veľmi realisticky. Práve tu môžu výskumníci naplno využiť prístup hlbokého učenia. Hlboké učenie je založené na poskytovaní počiatočného objektu vo forme hierarchickej štruktúry vlastností, takže každá ďalšia úroveň vlastností je postavená na základe prvkov predchádzajúcej úrovne. Takže, ak hovoríme o obrázkoch, počiatočné pixely obrázka budú pôsobiť ako najnižšia úroveň, segmenty, ktoré možno medzi týmito pixelmi rozlíšiť, budú ďalšou úrovňou, potom rohy a iné geometrické tvary, do ktorých sa segmenty pridajú. . Na ďalšej úrovni ich postáv sa tvoria predmety už rozpoznateľné pre ľudí, napríklad kolesá, a nakoniec posledná úroveň hierarchie je zodpovedná za konkrétne objekty na obrázku, napríklad auto.
Na implementáciu prístupu hlbokého učenia v modernej vede sa používajú viacvrstvové neurónové siete rôznych architektúr. Neurónové siete sú ideálne na riešenie problému identifikácie z údajov a budovanie hierarchického súboru funkcií, pretože v skutočnosti je neurónová sieť súborom neurónov, z ktorých každý je aktivovaný iba vtedy, ak vstupné údaje spĺňajú určité kritériá - tj. , predstavuje určitú vlastnosť, pričom pravidlá aktivácie neurónov - to je to, čo túto vlastnosť určuje - sa učia automaticky. Zároveň neurónové siete vo svojej najbežnejšej forme samy o sebe predstavujú hierarchickú štruktúru, kde každá ďalšia vrstva neurónov využíva ako svoj vstup výstupy neurónov predchádzajúcej vrstvy – alebo inými slovami vlastnosti vyššej vrstvy. úroveň sú tvorené na základe vlastností nižšej úrovne.
Rozšírenie tohto prístupu a v súvislosti s tým aj ďalší rozkvet neurónových sietí bolo spôsobené tromi vzájomne súvisiacimi dôvodmi:
Vznik nových architektúr neurónových sietí, zameraných na riešenie určitých problémov (konvolučné siete, Boltzmannove stroje atď.)
Vývoj a dostupnosť výpočtov s gpu a paralelných výpočtov vo všeobecnosti
Vznik a distribúcia prístupu vrstveného trénovania neurónových sietí, v ktorom je každá vrstva trénovaná samostatne pomocou štandardného algoritmu spätného šírenia (zvyčajne na neoznačených dátach, to znamená, že je trénovaný autokóder), čo umožňuje Na tejto úrovni je možné identifikovať významné vlastnosti a potom sa všetky vrstvy spoja do jednej siete a sieť sa ďalej trénuje pomocou označených údajov na vyriešenie konkrétneho problému (jemné doladenie). Tento prístup má dve významné výhody. Po prvé, toto výrazne zvyšuje efektivitu sieťového trénovania, pretože v každom okamihu nie je trénovaná hlboká štruktúra, ale sieť s jednou skrytou vrstvou - v dôsledku toho problémy s klesajúcimi chybovými hodnotami ako hĺbka siete. sa zvyšuje a zodpovedajúce zníženie miery učenia zmizne. A po druhé, tento prístup k sieťovému trénovaniu vám umožňuje pri trénovaní používať neoznačené dáta, ktorých je zvyčajne oveľa viac ako označovaných – vďaka čomu je trénovanie siete pre výskumníkov jednoduchšie a dostupnejšie. Označené údaje v tomto prístupe sú potrebné až na samom konci na doladenie siete na vyriešenie konkrétneho klasifikačného problému a zároveň, keďže všeobecná štruktúra funkcií, ktoré popisujú údaje, už bola vytvorená v procese predchádzajúceho školenia, na doladenie siete je potrebných oveľa menej údajov ako na počiatočné školenie. Okrem zníženia potrebného množstva označených údajov vám použitie tohto prístupu umožňuje trénovať sieť raz pomocou veľkého množstva neoznačených údajov a potom použiť výslednú štruktúru funkcií na riešenie rôznych problémov s klasifikáciou, prekonfigurovanie siete pomocou rôznych súborov údajov. - v oveľa kratšom čase, ako by bolo potrebné v prípade úplného sieťového školenia zakaždým.
Pozrime sa bližšie na hlavné architektúry neurónových sietí bežne používané v kontexte hlbokého učenia.
· Viacvrstvový perceptrón – je konvenčná plne prepojená neurónová sieť s veľkým počtom vrstiev. Otázka, koľko vrstiev sa považuje za dostatočne veľké, nemá jednoznačnú odpoveď, ale zvyčajne sa siete s 5-7 vrstvami už považujú za „hlboké“. Táto architektúra neurónových sietí, aj keď nemá zásadné rozdiely od sietí, ktoré boli predtým používané pred rozšírením konceptu hlbokého učenia, môže byť veľmi efektívna, ak sa úspešne vyrieši problém jej trénovania, čo bol hlavný problém práce s takýmito sieťami. V súčasnosti je tento problém vyriešený použitím grafických kariet na trénovanie siete, čo umožňuje rýchlejšie trénovanie a tým aj viac iterácií trénovania, alebo už spomínané vrstvené trénovanie siete. Takže v roku 2012 Ciresan a kolegovia publikovali článok „Hlboké veľké viacvrstvové perceptróny na rozpoznávanie číslic“, v ktorom vychádzali z predpokladu, že viacvrstvový perceptrón s veľkým počtom vrstiev v prípade dostatočnej doby tréningu (ktorá sa dosiahne v primeranom čase pomocou paralelných výpočtov na gpu ) a dostatok údajov na trénovanie (ktoré sa dosiahne aplikáciou rôznych náhodných transformácií na pôvodný súbor údajov) môže ukázať výkon, ktorý nie je horší ako iné, zložitejšie modely. Ich model, ktorým je neurónová sieť s 5 skrytými vrstvami, pri klasifikácii čísel z dátového súboru MNIST vykázal chybovosť 0,35, čo je lepšie ako predtým publikované výsledky zložitejších modelov. Taktiež spojením viacerých takto natrénovaných sietí do jedného modelu dokázali znížiť chybovosť na 0,31 %. Viacvrstvový perceptrón je teda napriek svojej zjavnej jednoduchosti celkom úspešným predstaviteľom algoritmov hlbokého učenia.
· Stacked autoencoder (stack autoencoder) - tento model úzko súvisí s viacvrstvovým perceptrónom a vo všeobecnosti s úlohou trénovania hlbokých neurónových sietí. Tréning hlbokých sietí vrstva po vrstve je implementovaný pomocou zásobníkového autokódera. Tento model sa však používa nielen na účely výcviku iných modelov, ale často má sám o sebe veľkú praktickú hodnotu. Aby sme opísali podstatu stohovaného autokódera, uvažujme najprv o koncepte konvenčného autokódera. Autoenkóder je algoritmus učenia bez dozoru, v ktorom sú očakávané výstupné hodnoty neurónovej siete jej vlastné vstupné hodnoty. Schematicky je model autokódera znázornený na obrázku 2:

Obrázok 2. Klasický autokóder
Je zrejmé, že úloha trénovania takéhoto modelu má triviálne riešenie, ak sa počet neurónov v skrytej vrstve rovná počtu vstupných neurónov - potom skrytá vrstva jednoducho potrebuje preložiť svoje vstupné hodnoty na výstup. Preto sa pri trénovaní autoenkóderov zavádzajú ďalšie obmedzenia, napríklad počet neurónov v skrytej vrstve je nastavený tak, aby bol výrazne menší ako vo vstupnej vrstve, alebo sa používajú špeciálne regularizačné techniky na zabezpečenie vysokej miery riedkosti skrytej vrstvy. neuróny. Jedným z najbežnejších použití automatických kódovačov v ich najčistejšej forme je úloha získať komprimovanú reprezentáciu pôvodných údajov. Takže napríklad autokóder s 30 neurónmi v skrytej vrstve, trénovaný na dátovom súbore MNIST, vám umožňuje obnoviť pôvodné obrázky číslic na výstupnej vrstve prakticky bez zmien, čo znamená, že v skutočnosti každý z pôvodných obrázkov môže byť presne opísaný iba 30 číslami. V tejto aplikácii sa autoenkódery často považujú za alternatívu k analýze hlavných komponentov. Skladaný autokóder je v podstate kombináciou niekoľkých konvenčných autokódovačov, ktoré sa učia vrstvu po vrstve. V tomto prípade výstupné hodnoty trénovaných neurónov skrytej vrstvy prvého z autokódovačov fungujú ako vstupné hodnoty pre druhý z nich atď.
Konvolučné siete sú v poslednej dobe jedným z najpopulárnejších modelov hlbokého učenia, ktorý sa používa predovšetkým na rozpoznávanie obrázkov. Koncept konvolučných sietí je postavený na troch hlavných myšlienkach:
o Lokálna citlivosť (lokálne receptívne polia) – ak hovoríme o úlohe rozpoznávania obrazu, znamená to, že rozpoznávanie toho či onoho prvku v obraze by malo byť primárne ovplyvnené jeho bezprostredným okolím, pričom pixely umiestnené v inej časti obrazu , s najväčšou pravdepodobnosťou s týmto prvkom nijako nesúvisia a neobsahujú informácie, ktoré by pomohli k jeho správnej identifikácii
o Zdieľané váhy – prítomnosť zdieľaných váh v modeli v skutočnosti stelesňuje predpoklad, že rovnaký objekt možno nájsť v ktorejkoľvek časti obrázka, zatiaľ čo rovnaký vzor (sada váh) sa používa na jeho hľadanie vo všetkých častiach obrázka. obrázok
o Subsampling (podvzorkovanie) – koncept, ktorý umožňuje urobiť model odolnejším voči menším odchýlkam od požadovaného vzoru – vrátane tých, ktoré sú spojené s malými deformáciami, zmenami osvetlenia atď. Myšlienka podvzorkovania spočíva v tom, že pri porovnávaní so vzorom sa neberie do úvahy presná hodnota pre daný pixel alebo oblasť pixelov, ale jeho agregácia v určitom susedstve, napríklad priemer, resp. maximálna hodnota.
Z matematického hľadiska je základom konvolučných neurónových sietí operácia konvolúcie matice, ktorá spočíva v násobení matice po prvku, ktorá predstavuje malú oblasť pôvodného obrazu (napríklad 7 * 7 pixelov) s maticou rovnakej veľkosti, nazývanou konvolučné jadro, a potom sčítaním výsledných hodnôt . V tomto prípade je zosúlaďovacie jadro v skutočnosti určitá šablóna a číslo získané ako výsledok súčtu charakterizuje stupeň podobnosti danej oblasti obrázka s touto šablónou. Preto každá vrstva konvolučnej siete pozostáva z určitého počtu vzorov a úlohou trénovania siete je vybrať správne hodnoty v týchto vzoroch tak, aby odrážali najvýznamnejšie charakteristiky pôvodných obrázkov. V tomto prípade sa každá šablóna postupne porovnáva so všetkými časťami obrázka - tu sa prejavuje myšlienka oddelenia váh. Vrstvy tohto typu v konvolučnej sieti sa nazývajú konvolučné vrstvy. Okrem konvolučných vrstiev majú konvolučné siete vrstvy podvzorkovania, ktoré nahrádzajú malé oblasti obrazu jediným číslom, čím sa súčasne znižuje veľkosť vzorky pre ďalšiu vrstvu, na ktorej má pracovať, a sieť je odolnejšia voči malým zmenám v údajoch. V posledných vrstvách konvolučnej siete sa zvyčajne používa jedna alebo viac plne prepojených vrstiev, vyškolených na vykonávanie priamej klasifikácie objektov. V posledných rokoch sa používanie konvolučných sietí stalo de facto štandardom v klasifikácii obrázkov a umožňuje dosiahnuť najlepšie výsledky v tejto oblasti.
· Restricted Boltzmann Machines – ďalší typ modelu hlbokého učenia, na rozdiel od konvolučných sietí, ktorý sa používa predovšetkým na rozpoznávanie reči. Boltzmannov stroj v klasickom zmysle je neorientovaný graf, ktorého okraje odrážajú závislosti medzi uzlami (neurónmi). Niektoré z neurónov sú viditeľné a niektoré sú skryté. Boltzmannov stroj je z pohľadu neurónových sietí v podstate rekurentná neurónová sieť, z pohľadu štatistiky je to náhodné Markovovo pole. Dôležitými konceptmi pre Boltzmannove stroje sú koncepty sieťovej energie a rovnovážneho stavu. Energia siete závisí od toho, koľko silne prepojených neurónov je súčasne v aktivovanom stave, pričom úlohou trénovania takejto siete je konvergovať do rovnovážneho stavu, pri ktorom je jej energia minimálna. Hlavnou nevýhodou takýchto sietí sú veľké problémy s ich trénovaním vo všeobecnosti. Na vyriešenie tohto problému J. Hinton a kolegovia navrhli model Restricted Boltzmann Machines, ktorý obmedzuje štruktúru siete a predstavuje ju ako bipartitný graf, v jednej časti ktorého sú iba viditeľné neuróny a v druhej iba skryté, respektíve spojenia sú prítomné iba medzi viditeľnými a skrytými neurónmi. Toto obmedzenie umožnilo vyvinúť efektívne algoritmy pre trénovacie siete tohto typu, vďaka čomu sa dosiahol výrazný pokrok v riešení problémov s rozpoznávaním reči, kde tento model takmer nahradil predtým populárny model skrytých Markovových sietí.
Teraz, keď sme zvážili základné koncepty a princípy hlbokého učenia, stručne zvážime základné princípy a vývoj rozvoja rozpoznávania obrazu a aké miesto v ňom hlboké učenie zaujíma.
1.4 Rozpoznanie obrazu
Existuje mnoho formulácií pre problém rozpoznávania obrazu a je dosť ťažké ho jednoznačne definovať. Napríklad rozpoznávanie obrázkov možno považovať za úlohu vyhľadávania a identifikácie niektorých logických objektov v pôvodnom obrázku.
Rozpoznanie obrazu je pre počítačový algoritmus zvyčajne náročná úloha. Je to dané predovšetkým vysokou variabilitou obrazov jednotlivých predmetov. Úloha nájsť auto na obrázku je teda jednoduchá pre ľudský mozog, ktorý je schopný automaticky identifikovať prítomnosť dôležitých prvkov pre auto (kolesá, konkrétny tvar) v objekte a v prípade potreby „dostať“ obraz v predstavách, predstavujúci chýbajúce detaily, a pre počítač mimoriadne náročný, keďže existuje veľké množstvo druhov áut rôznych značiek a modelov, ktoré majú veľa rôznych tvarov, navyše konečný tvar objekt na snímke veľmi závisí od bodu snímania, uhla, pod ktorým je snímaný, a ďalších parametrov. Dôležitú úlohu zohráva aj osvetlenie, ktoré ovplyvňuje farebnosť výsledného obrazu a môže tiež zneviditeľniť či skresliť jednotlivé detaily.
Hlavné ťažkosti pri rozpoznávaní obrazu sú teda spôsobené:
Rôzne predmety v triede
Variabilita tvaru, veľkosti, orientácie, polohy v obraze
Variabilita osvetlenia
Na boj proti týmto ťažkostiam boli v priebehu histórie rozpoznávania obrazov navrhnuté rôzne metódy av súčasnosti sa v tejto oblasti už dosiahol významný pokrok.
Prvé štúdie v oblasti rozpoznávania obrazu publikoval v roku 1963 L. Roberts v článku „Machine Perception Of Three-Dimensional Solids“, kde sa autor pokúsil abstrahovať od možných zmien tvaru objektu a sústredil sa na rozpoznávanie obrazu jednoduchých geometrických tvarov v rôznych svetelných podmienkach a pri zákrutách. Počítačový program, ktorý vyvinul, dokázal na obrázku identifikovať geometrické objekty niektorých jednoduchých tvarov a vytvoriť ich trojrozmerný model v počítači.
V roku 1987 S. Ulman a D. Huttenlocher publikovali článok „Object Recongnition Using Alignment“, kde sa tiež pokúsili rozpoznať objekty relatívne jednoduchých tvarov, pričom proces rozpoznávania bol organizovaný v dvoch fázach: po prvé, hľadanie oblasti. na obrázku, kde sa nachádza cieľový objekt, a určenie jeho možných rozmerov a orientácie („zarovnanie“) pomocou malého súboru charakteristických znakov a potom porovnanie potenciálneho obrazu objektu pixel po pixeli s očakávaným.
Porovnávanie obrázkov pixel po pixeli má však mnoho podstatných nevýhod, ako je jeho zložitosť, potreba šablóny pre každý z objektov možných tried a skutočnosť, že v prípade porovnávania pixel po pixeli je možno prehľadávať konkrétny objekt a nie celú triedu objektov. V niektorých situáciách je to použiteľné, ale vo väčšine prípadov stále musíte hľadať nie jeden konkrétny objekt, ale veľa objektov určitej triedy.
Jedným z dôležitých smerov v ďalšom vývoji rozpoznávania obrazu bolo rozpoznávanie obrazu založené na identifikácii obrysu. V mnohých prípadoch sú to práve kontúry, ktoré obsahujú väčšinu informácií o obrázku a zároveň to, že sa obrázok považuje za súbor kontúr, môže ho výrazne zjednodušiť. Na vyriešenie problému hľadania kontúr na obrázku je klasickým a najznámejším prístupom Canny Edge Detector, ktorého práca je založená na hľadaní lokálneho maxima gradientu.
Ďalším dôležitým smerom v oblasti analýzy obrazu je aplikácia matematických metód, ako je frekvenčná filtrácia a spektrálna analýza. Tieto metódy sa používajú napríklad na kompresiu obrázkov (kompresia JPEG) alebo zlepšenie ich kvality (Gaussov filter). Keďže však tieto metódy priamo nesúvisia s rozpoznávaním obrazu, nebudeme ich tu podrobnejšie rozoberať.
Ďalším problémom, ktorý sa často uvažuje v súvislosti s problémom rozpoznávania obrazu, je problém segmentácie. Hlavným účelom segmentácie je výber jednotlivých objektov v obraze, pričom každý z nich je potom možné samostatne študovať a klasifikovať. Úloha segmentácie je značne zjednodušená, ak je pôvodný obrázok binárny – to znamená, že pozostáva z pixelov iba dvoch farieb. V tomto prípade sa problém segmentácie často rieši pomocou metód matematickej morfológie. Podstatou metód matematickej morfológie je reprezentovať obraz ako súbor binárnych hodnôt a aplikovať na tento súbor logické operácie, z ktorých hlavné sú prenos, rast (logické sčítanie) a erózia (logické násobenie). Pomocou týchto operácií a ich derivátov, ako je zatváranie a otváranie, je možné napríklad eliminovať šum v obraze alebo zvýrazniť okraje. Ak sa takéto metódy použijú v segmentačnom probléme, potom sa ich najdôležitejšou úlohou stáva práve eliminácia šumu a vytváranie viac-menej homogénnych oblastí na obrázku, ktoré sa potom dajú ľahko nájsť pomocou algoritmov podobných hľadaniu spojených komponentov v grafe. - to budú požadované segmenty Obrázky.
Čo sa týka segmentácie RGB obrázkov, jedným z dôležitých zdrojov informácií o segmentoch obrázku môže byť jeho textúra. Na určenie textúry obrazu sa často používa filter Gabor, ktorý bol vytvorený v snahe reprodukovať vlastnosti vnímania textúr ľudským zrakom. Tento filter je založený na frekvenčnej transformačnej funkcii obrazu.
Ďalšou dôležitou skupinou algoritmov používaných na rozpoznávanie obrazu sú algoritmy založené na vyhľadávaní lokálnych prvkov. Lokálne prvky sú niektoré dobre definované oblasti obrázka, ktoré vám umožňujú korelovať obrázok s modelom (objekt, ktorý hľadáte) a určiť, či sa daný obrázok zhoduje s modelom, a ak áno, určiť parametre modelu (napr. , uhol sklonu, aplikovaná kompresia atď.) . Pre kvalitatívne plnenie svojich funkcií musia byť lokálne singularity odolné voči afinným transformáciám, posunom atď. Klasickým príkladom miestnych prvkov sú rohy, ktoré sú často prítomné na hraniciach rôznych objektov. Najpopulárnejším algoritmom na hľadanie rohov je Harrisov detektor.
V poslednej dobe sú čoraz populárnejšie metódy rozpoznávania obrazu založené na neurónových sieťach a hlbokom učení. Hlavný rozkvet týchto metód nastal po objavení sa na konci 20. storočia konvolučných sietí (LeCun, ), ktoré vykazujú výrazne lepšie výsledky v rozpoznávaní obrazu v porovnaní s inými metódami. Väčšina popredných (nielen) algoritmov v každoročnej súťaži v rozpoznávaní obrázkov ImageNet-2014 teda využívala konvolučné siete v tej či onej forme.
1.5 Rozpoznávanie dopravných značiek
Vo všeobecnosti je rozpoznávanie dopravných značiek jednou z mnohých úloh rozpoznávania obrázkov alebo v niektorých prípadoch aj videozáznamov. Táto úloha má veľký praktický význam, pretože rozpoznávanie dopravných značiek sa používa napríklad v programoch automatizácie riadenia automobilov. Úloha rozpoznávania dopravných značiek má mnoho variácií – napríklad identifikovať prítomnosť dopravných značiek na fotografii, zvýrazniť oblasť na obrázku, ktorá je dopravnou značkou, určiť, ktorá konkrétna značka je zobrazená na fotografii, ktorá je zjavne obrázkom dopravná značka atď. S rozpoznávaním dopravných značiek sú zvyčajne spojené tri globálne úlohy - ich identifikácia medzi okolitou krajinou, priame rozpoznávanie alebo klasifikácia a takzvané sledovanie - to znamená schopnosť algoritmu "nasledovať", tj. udržujte vo videosekvencii zaostrenú dopravnú značku. Každá z týchto čiastkových úloh je sama o sebe samostatným predmetom výskumu a zvyčajne má svoj okruh výskumníkov a tradičné prístupy. V tejto práci sa pozornosť sústredila na problém klasifikácie dopravnej značky zobrazenej na fotografii, preto sa ňou budeme zaoberať podrobnejšie.
Táto úloha je klasifikačnou úlohou pre triedy s nevyváženou frekvenciou. To znamená, že pravdepodobnosť, že obrázok patrí do rôznych tried, je iná, pretože niektoré triedy sú bežnejšie ako iné - napríklad na ruských cestách je značka rýchlostného limitu „40“ oveľa bežnejšia ako značka „Neprejazdnosť“. . Okrem toho dopravné značky tvoria niekoľko skupín tried tak, že triedy v rámci jednej skupiny sú si navzájom veľmi podobné – napríklad všetky značky obmedzujúce rýchlosť vyzerajú veľmi podobne a líšia sa len číslami vo vnútri, čo, samozrejme, výrazne komplikuje klasifikačná úloha. Na druhej strane, dopravné značky majú jasný geometrický tvar a malú množinu možných farieb, čo by mohlo výrazne zjednodušiť postup klasifikácie - nebyť toho, že skutočné fotografie dopravných značiek je možné nasnímať z rôznych uhlov a za rôznych svetelných podmienok . Úloha klasifikácie dopravných značiek, hoci ju možno považovať za typickú úlohu rozpoznávania obrazu, si vyžaduje špeciálny prístup na dosiahnutie najlepšieho výsledku.
Výskum na túto tému bol do istého času dosť chaotický a nesúvisiaci, keďže každý výskumník si stanovoval svoje vlastné úlohy a používal vlastný súbor údajov, takže dostupné výsledky nebolo možné porovnávať a zovšeobecňovať. V roku 2005 teda Bahlmann a kolegovia ako súčasť komplexného systému rozpoznávania dopravných značiek, ktorý podporuje všetky 3 vyššie uvedené čiastkové úlohy rozpoznávania dopravných značiek, implementovali algoritmus rozpoznávania značiek, ktorý pracuje s presnosťou 94 % pre dopravné značky patriace 23 rôznym triedy. Školenie sa uskutočnilo na 40 000 snímkach, pričom počet snímok zodpovedajúcich každej triede sa pohyboval od 30 do 600. Algoritmus AdaBoost a vlnky Haar boli použité na detekciu dopravných značiek v tomto systéme a bol použitý prístup založený na algoritme Expectation Maximization. slúži na klasifikáciu nájdených znakov. Systém rozpoznávania dopravných značiek s rýchlostnými obmedzeniami vyvinutý spoločnosťou Moutarde v roku 2007 mal presnosť až 90 % a bol natrénovaný na súbore 281 obrázkov. V tomto systéme sa na detekciu dopravných značiek v obrázkoch použili kruhové a štvorcové detektory (pre európske a americké značky), v ktorých sa potom každá číslica extrahovala a klasifikovala pomocou neurónovej siete. V roku 2010 Ruta a kolegovia vyvinuli systém na detekciu a klasifikáciu 48 rôznych typov dopravných značiek s presnosťou klasifikácie 85,3 %. Ich prístup bol založený na hľadaní kruhov a mnohostenov v obraze a zvýraznení malého počtu špeciálnych oblastí v nich, ktoré umožňujú rozlíšiť tento znak od všetkých ostatných. Zároveň bola aplikovaná špeciálna transformácia farieb obrazu, ktorú autori nazvali Color Distance Transform, ktorá umožňuje znížiť počet farieb prítomných v obraze a tým zvýšiť možnosti porovnávania obrázkov a znížiť veľkosť spracovávaných údajov. Broggie a Collen v roku 2007 navrhli trojstupňový algoritmus na detekciu a klasifikáciu dopravných značiek, pozostávajúci z farebnej segmentácie, detekcie tvaru a neurónovej siete, ale v ich publikácii chýbajú kvantitatívne ukazovatele výsledkov ich algoritmu. Gao a kol., v roku 2006 navrhli systém rozpoznávania dopravných značiek založený na analýze farby a tvaru zamýšľanej značky a preukázali presnosť rozpoznávania 95 % medzi 98 prípadmi dopravných značiek.
Situácia s roztrieštenosťou výskumu v oblasti rozpoznávania dopravných značiek sa zmenila v roku 2011, keď sa na konferencii IJCNN (International Joint Conference on Neural Networks) uskutočnila súťaž v rozpoznávaní dopravných značiek. Pre túto súťaž bol vyvinutý súbor údajov German Traffic Sign Recognition Benchmark (GTSRB), ktorý obsahuje viac ako 50 000 obrázkov dopravných značiek umiestnených na nemeckých cestách a patriacich do 43 rôznych tried. Na základe tohto súboru údajov sa uskutočnila súťaž, ktorá pozostávala z dvoch etáp. Výsledkom druhej etapy bol článok „Človek vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition“, ktorý poskytuje prehľad výsledkov súťaže a popis prístupov, ktoré používajú najúspešnejšie tímy. Aj v nadväznosti na túto udalosť bolo publikovaných množstvo článkov samotných autorov algoritmov - účastníkov súťaže a tento súbor údajov sa následne stal základným meradlom pre algoritmy súvisiace s rozpoznávaním dopravných značiek, podobne ako dobre- známy MNIST pre rozpoznávanie ručne písaných číslic.
Medzi najúspešnejšie algoritmy v tejto súťaži patrí komisia konvolučných sietí (tím IDSIA), viacúrovňová konvolučná sieť (Multi-Scale CNN, tím Sermanet) a náhodný les (Random Forests, tím CAOR). Pozrime sa bližšie na každý z týchto algoritmov.
Výbor pre neurónové siete navrhnutý tímom IDSIA z talianskeho Inštitútu pre výskum umelej inteligencie Dalle Molle, ktorý vedie D. Ciresan, dosiahol presnosť klasifikácie znakov 99,46 %, čo je viac ako ľudská presnosť (99,22 %), ktorá bola hodnotená. v rámci tej istej súťaže. Tento algoritmus bol následne podrobnejšie popísaný v článku „Multi-stĺpcová hlboká neurónová sieť pre klasifikáciu dopravných značiek“ . Hlavnou myšlienkou tohto prístupu je, že na pôvodné dáta boli aplikované 4 rôzne normalizačné metódy: úprava obrazu, ekvalizácia histogramu, ekvalizácia adaptívneho histogramu a normalizácia kontrastu. Potom sa pre každý súbor údajov získaný ako výsledok normalizácie a pôvodný súbor údajov vytvorilo a natrénovalo 5 konvolučných sietí s náhodne inicializovanými počiatočnými hodnotami váh, každá z 8 vrstiev, pričom na sieť boli aplikované rôzne náhodné transformácie. vstupné hodnoty počas tréningu, čo umožnilo zvýšiť veľkosť a variabilitu tréningovej vzorky. Výsledná predikcia siete bola vytvorená spriemerovaním predikcie každej z konvolučných sietí. Na trénovanie týchto sietí bola použitá implementácia využívajúca gpu computing.
Algoritmus využívajúci viacúrovňovú konvolučnú sieť navrhol tím pozostávajúci z P. Sermaneta a Y. LeCuna z New York University. Tento algoritmus bol podrobne popísaný v článku „Rozpoznávanie dopravných značiek pomocou konvolučných sietí Milti-Scale“ . V tomto algoritme boli všetky pôvodné obrázky zmenšené na veľkosť 32 x 32 pixelov a konvertované do odtieňov šedej, po čom sa na ne použila normalizácia kontrastu. Veľkosť pôvodnej trénovacej množiny sa tiež zväčšila 5-násobne použitím malých náhodných transformácií na pôvodné obrázky. Výsledná sieť sa skladala z dvoch etáp (etáp), ako je znázornené na obrázku 3, pričom konečná klasifikácia využívala výstupné hodnoty nielen z druhej, ale aj z prvej. Táto sieť vykazovala presnosť 98,31 %.

Obrázok 3. Viacúrovňová neurónová sieť
Tretí úspešný náhodný lesný algoritmus bol vyvinutý tímom CAOR v MINES ParisTech. Podrobný popis ich algoritmu bol publikovaný v článku “Rozpoznávanie dopravných značiek v reálnom čase pomocou priestorovo vážených stromov HOG” . Tento algoritmus je založený na vytvorení lesa 500 náhodných rozhodovacích stromov, z ktorých každý je trénovaný na náhodne vybranej podmnožine trénovacej množiny, pričom konečná výstupná hodnota klasifikátora je tá, ktorá získala najviac hlasov. Tento klasifikátor na rozdiel od predchádzajúcich nepoužíval pôvodné obrázky vo forme množiny pixelov, ale HOG reprezentácie obrázkov (orientované gradientové histogramy), ktoré spolu s nimi poskytli organizátori súťaže. Konečným výsledkom algoritmu bolo 96,14 % správne klasifikovaných obrázkov, čo ukazuje, že pre úlohu rozpoznávania dopravných značiek možno celkom úspešne použiť aj metódy nesúvisiace s neurónovými sieťami a hlbokým učením, hoci ich výkonnosť stále zaostáva za výsledkami konvolučné siete..
1.6 Analýza existujúcich knižníc
Pre implementáciu algoritmov pre prácu s neurónovými sieťami vo vyvíjanom systéme bolo rozhodnuté využiť niektorú z existujúcich knižníc. Preto bola vykonaná analýza existujúcich softvérových riešení pre implementáciu algoritmov hlbokého učenia a na základe výsledkov tejto analýzy bol urobený výber. Analýza existujúcich riešení pozostávala z dvoch fáz: teoretickej a praktickej.
Počas teoretickej fázy sa uvažovalo o knižniciach ako Deeplearning4j, Theano, Pylearn2, Torch a Caffe. Zvážme každú z nich podrobnejšie.
Deeplearning4j (www.deeplearning4j.org) je knižnica s otvoreným zdrojovým kódom na implementáciu neurónových sietí a algoritmov hlbokého učenia napísaných v jazyku Java. Dá sa použiť z jazykov Java, Scala a Closure, podporovaná je integrácia s Hadoop, Apache Spark, Akka a AWS. Knižnicu vyvíja a spravuje spoločnosť Skymind, ktorá pre túto knižnicu poskytuje aj komerčnú podporu. Vo vnútri tejto knižnice je použitá knižnica pre rýchlu prácu s n-rozmernými poľami ND4J vyvinutá tou istou spoločnosťou. Deeplearning4j podporuje mnoho typov sietí, vrátane viacvrstvových perceptrónov, konvolučných sietí, obmedzených Bolzmannových strojov, stohovaných odšumovacích automatických kódovačov, hlbokých automatických kódovačov, rekurzívnych automatických kódovačov, sietí s hlbokým presvedčením, rekurentných sietí a niektorých ďalších. Dôležitou vlastnosťou tejto knižnice je jej schopnosť pracovať v klastri. Knižnica tiež podporuje trénovanie siete GPU.
· Theano (www.github.com/Theano/Theano) je open source knižnica Python, ktorá vám umožňuje efektívne vytvárať, vyhodnocovať a optimalizovať matematické výrazy pomocou viacrozmerných polí. Na reprezentáciu multidimenzionálnych polí a prevádzku na nich sa používa knižnica NumPy. Táto knižnica je určená predovšetkým na vedecký výskum a vytvorila ju skupina vedcov z univerzity v Montreale. Možnosti Theana sú veľmi široké a práca s neurónovými sieťami je len jednou z jeho malých častí. Práve táto knižnica je zároveň najpopulárnejšia a najčastejšie sa spomína pri práci s hlbokým učením.
Pylearn2 (www.github.com/lisa-lab/pylearn2) je open source python knižnica postavená na Theano, ale poskytuje užívateľsky prívetivejšie a jednoduchšie rozhranie pre výskumníkov, poskytuje hotovú sadu algoritmov a umožňuje jednoduchá konfigurácia sietí vo formáte YAML súborov. Vyvinutý skupinou vedcov z laboratória LISA Montrealskej univerzity.
· Torch (www.torch.ch) – knižnica na počítanie a implementáciu algoritmov strojového učenia implementovaná v jazyku C, ale umožňujúca výskumníkom s ňou pracovať pomocou oveľa pohodlnejšieho skriptovacieho jazyka Lua. Táto knižnica poskytuje vlastnú efektívnu implementáciu operácií s maticami, viacrozmernými poliami, podporuje výpočty GPU. Umožňuje vám implementovať plne prepojené a konvolučné siete. Má otvorený zdrojový kód.
· Caffe (www.caffe.berkeleyvision.org) je knižnica zameraná na efektívnu implementáciu algoritmov hlbokého učenia, vyvinutá predovšetkým Berkley Vision and Learning Center, ale ako všetky predchádzajúce je open source. Knižnica je implementovaná v C, ale poskytuje aj pohodlné rozhranie pre Python a Matlab. Podporuje plne prepojené a konvolučné siete, umožňuje popísať siete vo formáte ako súbor vrstiev vo formáte .prototxt, podporuje GPU computing. K výhodám knižnice patrí aj prítomnosť veľkého množstva predtrénovaných modelov a príkladov, čo v kombinácii s ďalšími charakteristikami robí knižnicu najjednoduchším začiatkom práce spomedzi vyššie uvedených.
Na základe súboru kritérií boli na ďalšie posúdenie vybrané 3 knižnice: Deeplearning4j, Theano a Caffe. Tieto 3 knižnice boli nainštalované a testované v praxi.
Spomedzi týchto knižníc sa ako najproblematickejšia inštalácia ukázala Deeplearning4j, navyše sa našli chyby v ukážkach dodávaných s knižnicou, čo vyvolalo určité otázky týkajúce sa spoľahlivosti knižnice a mimoriadne sťažilo jej ďalšie štúdium. Okrem toho, berúc do úvahy nižší výkon jazyka Java v porovnaní s jazykom C, na ktorom je implementovaný Caffe, bolo rozhodnuté odmietnuť ďalšie úvahy o tejto knižnici.
Knižnica Theano sa tiež pomerne ťažko inštaluje a konfiguruje, ale pre túto knižnicu existuje veľké množstvo kvalitnej a dobre štruktúrovanej dokumentácie a príkladov pracovného kódu, takže nakoniec bola knižnica schopná fungovať vrátane použitia grafickej karty. Ako sa však ukázalo, implementácia čo i len elementárnej neurónovej siete v tejto knižnici si vyžaduje napísanie veľkého množstva vlastného kódu, a preto sú aj veľké ťažkosti s popisom a úpravou štruktúry siete. Preto, napriek potenciálne oveľa širším možnostiam tejto knižnice v porovnaní s Caffe, pre túto štúdiu bolo rozhodnuté zamerať sa na druhú, ako najvhodnejšiu pre dané úlohy.
1.7 Knižnicakaviareň
Knižnica Caffe poskytuje pomerne jednoduché a pre výskumníkov priateľské rozhranie, ktoré uľahčuje konfiguráciu a trénovanie neurónových sietí. Pre prácu s knižnicou je potrebné vytvoriť popis siete vo formáte prototxt (súbor s definíciou vyrovnávacej pamäte protokolu – jazyk na popis údajov vytvorený spoločnosťou Google), ktorý je do istej miery podobný formátu JSON, je dobre štruktúrovaný a pre človeka zrozumiteľný. Popis siete je v podstate popisom každej z jej vrstiev. Ako vstup môže knižnica pracovať s databázou (leveldb alebo lmdb), údajmi v pamäti, súbormi HDF5 a obrázkami. Na vývojové a testovacie účely je možné použiť aj špeciálny typ údajov nazývaný DummyData.
Knižnica podporuje vytváranie vrstiev nasledujúcich typov: InnerProduct (plne prepojená vrstva), Splitting (konvertuje dáta na prenos do viacerých výstupných vrstiev naraz), Flattening (konvertuje dáta z viacrozmernej matice na vektorovú), Reshape (umožňuje vám na zmenu dátovej dimenzie), zreťazenie (konvertuje dáta z viacerých vstupných vrstiev do jednej výstupnej vrstvy), Slicing a niekoľko ďalších. Pre konvolučné siete sú podporované aj špeciálne typy vrstiev – Convolution (konvolučná vrstva), Pooling (subvzorkovacia vrstva) a Local Response Normalization (vrstva pre lokálnu normalizáciu dát). Okrem toho je podporovaných niekoľko typov stratových funkcií pre tréning siete (Softmax, Euclidean, Hinge, Sigmoid Cross-Entropy, Infogain a Accuracy) a funkcie aktivácie neurónov (Rectified-Linear, Sigmoid, Hyperbolic Tangent, Absolute Value, Power a BNLL) - ktoré sú tiež nakonfigurované ako samostatné sieťové vrstvy.
Sieť je teda opísaná deklaratívne v celkom jednoduchej forme. Príklady sieťových konfigurácií použitých v tejto štúdii si môžete pozrieť v prílohe 1. Aby knižnica fungovala pomocou štandardných skriptov, musíte vytvoriť súbor solver.prototxt, ktorý popisuje konfiguráciu sieťového trénovania – počet iterácií na trénovanie, rýchlosť učenia, výpočtová platforma - CPU alebo GPU atď.
Tréning modelu je možné implementovať pomocou vstavaných skriptov (po ich dokončení pre aktuálnu úlohu) alebo manuálne napísaním kódu pomocou poskytnutého api v pythone alebo Matlabe. Zároveň existujú skripty, ktoré umožňujú nielen trénovať sieť, ale napríklad aj vytvárať databázu na základe poskytnutého zoznamu obrázkov – v tomto prípade budú obrázky zmenšené na pevnú veľkosť a normalizované pred pridaný do databázy. Tréningové skripty zapuzdrujú aj niektoré pomocné akcie – napríklad vyhodnotia aktuálnu presnosť modelu po určitom počte iterácií a uložia aktuálny stav natrénovaného modelu do súboru snapshot. Použitie súborov snímok vám umožňuje pokračovať v trénovaní modelu v budúcnosti namiesto toho, aby ste v prípade potreby začínali odznova, a tiež po určitom počte iterácií zmeniť konfiguráciu modelu - napríklad pridať novú vrstvu - a pri Zároveň si váhy predtým trénovaných vrstiev zachovajú svoje hodnoty, čo vám umožňuje implementovať skôr popísaný mechanizmus vrstveného učenia.
Vo všeobecnosti sa knižnica ukázala ako celkom vhodná na použitie a umožnila implementovať všetky požadované modely, ako aj získať hodnoty presnosti klasifikácie pre tieto modely.
2. Vývoj prototypu systému rozpoznávania obrazu
.1 Algoritmus klasifikácie obrázkov
Počas štúdia teoretického materiálu na danú tému a praktických experimentov sa vytvoril nasledujúci súbor myšlienok, ktoré by mali byť zahrnuté do konečného algoritmu:
· Využitie hlbokých konvolučných neurónových sietí. Konvolučné siete neustále vykazujú najlepšie výsledky v rozpoznávaní obrazu vrátane dopravných značiek, takže ich použitie vo vyvinutom algoritme vyzerá logicky
· Použitie viacvrstvových perceptrónov. Napriek všeobecne vyššej efektivite konvolučných sietí existujú typy obrazov, pri ktorých viacvrstvový perceptrón vykazuje lepšie výsledky, preto bolo rozhodnuté použiť aj tento algoritmus.
· Spojenie výsledkov niekoľkých modelov pomocou dodatočného klasifikátora. Keďže bolo rozhodnuté použiť aspoň dva typy neurónových sietí, je potrebný spôsob, ako vytvoriť nejaký všeobecný výsledok klasifikácie na základe výsledkov každej z nich. Na tento účel sa plánuje použiť ďalší klasifikátor, ktorý nesúvisí s neurónovými sieťami, ktorých vstupné hodnoty sú výsledkom klasifikácie každej zo sietí a výstupom je konečná predpovedaná trieda obrazu.
· Aplikujte dodatočné transformácie na vstupné dáta. Na zvýšenie vhodnosti vstupných obrázkov na rozpoznávanie a tým aj zlepšenie výkonu klasifikátora je potrebné na vstupné dáta použiť niekoľko typov transformácií a výsledky každého z nich spracovať samostatná sieť vyškolená na rozpoznávanie obrázkov. s týmto typom transformácie.
Na základe všetkých vyššie uvedených myšlienok sa vytvoril nasledujúci koncept klasifikátora obrázkov. Klasifikátor je súbor 6 nezávislých neurónových sietí: 2 viacvrstvové perceptróny a 4 konvolučné siete. Siete rovnakého typu sa od seba zároveň líšia typom transformácie aplikovaným na vstupné dáta. Vstupné údaje sú škálované tak, aby každá sieť mala vždy rovnakú veľkosť ako vstup a tieto veľkosti sa môžu v jednotlivých sieťach líšiť. Na agregáciu výsledkov všetkých sietí sa používa dodatočný klasický klasifikátor, pre ktorý boli použité 2 možnosti: algoritmus J48, založený na rozhodovacom strome, a algoritmus kStar, ktorý je „lenivým“ klasifikátorom. Transformácie použité v klasifikátore:
· Binarizácia - obrázok je nahradený novým, pozostávajúcim iba z čiernobielych pixelov. Na vykonanie binarizácie sa používa metóda adaptívneho prahovania. Podstatou metódy je, že pre každý pixel obrázku sa vypočíta priemerná hodnota niektorého z jeho susedstva pixelov (predpokladá sa, že obrázok obsahuje iba odtiene šedej, preto boli pôvodné obrázky predtým podľa toho prevedené), a potom sa na základe vypočítanej priemernej hodnoty určí, či sa má pixel považovať za čierny alebo biely.
· Ekvalizácia histogramu - podstatou metódy je aplikovať určitú funkciu na histogram obrazu tak, aby sa hodnoty na výslednom diagrame rozložili čo najrovnomernejšie. V tomto prípade sa objektívna funkcia vypočíta na základe funkcie rozloženia intenzity farby v pôvodnom obrázku. Príklad aplikovania podobnej funkcie na histogram snímky je na obrázku 4. Túto metódu je možné aplikovať na čiernobiele aj farebné snímky – samostatne pre každú farebnú zložku. V tejto štúdii boli použité obe možnosti.



Obrázok 4, výsledky aplikácie zarovnania grafu na obrázok
Vylepšenie kontrastu – spočíva v tom, že pre každý pixel obrazu existuje lokálne minimum a maximum v niektorom jeho okolí a následne je tento pixel nahradený lokálnym maximom, ak je jeho počiatočná hodnota bližšia k maximu, resp. inak miestne minimum. Vzťahuje sa na čiernobiele obrázky.
Schematicky je všeobecná schéma výsledného klasifikátora znázornená na obrázku 5:

Obrázok 5, konečná schéma klasifikátora
Na implementáciu časti modelu zodpovednej za transformáciu vstupných dát a neurónových sietí sa používa jazyk Python a knižnica Caffe. Poďme si podrobnejšie popísať štruktúru každej zo sietí.
Oba viacvrstvové perceptróny obsahujú 4 skryté vrstvy a vo všeobecnosti je ich konfigurácia opísaná takto:
vstupná vrstva
Vrstva 1, 1500 neurónov
Vrstva 2 500 neurónov
Vrstva 3 300 neurónov
Vrstva 4, 150 neurónov
výstupná vrstva
Príklad konfiguračného súboru Caffe popisujúceho túto sieť je uvedený v prílohe 1. Čo sa týka konvolučných sietí, ako základ pre ich architektúru bola vzatá známa sieť LeNet, vyvinutá na klasifikáciu obrázkov z dátového súboru ImageNet. Aby však zodpovedali uvažovaným obrázkom, ktoré majú výrazne menšiu veľkosť, bola sieť upravená. Krátky popis vyzerá takto:
Schéma tejto siete je znázornená na obrázku 6.

Obrázok 6, schéma konvolučnej siete
Každá z neurónových sietí vedúcich k modelu je trénovaná samostatne. Po natrénovaní neurónových sietí dostane špeciálny Python skript pre každú zo sietí pre každý z obrázkov trénovacej množiny výsledok klasifikácie vo forme zoznamu pravdepodobností pre každú z tried, vyberie dve najpravdepodobnejšie triedy a zapíše získané hodnoty spolu so skutočnou hodnotou triedy obrázkov do súboru. Výsledný súbor sa potom odovzdá ako trénovacia množina klasifikátoru (J48 a kStar) implementovanému v knižnici Weka. V súlade s tým sa pomocou tejto knižnice vykoná ďalšia klasifikácia.
2.2 Architektúra systému
Teraz, po zvážení algoritmu rozpoznávania dopravných značiek pomocou neurónových sietí a dodatočného klasifikátora, prejdime priamo k popisu vyvinutého systému pomocou tohto algoritmu.
Vyvinutý systém je aplikácia s webovým rozhraním, ktorá umožňuje používateľovi nahrať obrázok dopravnej značky a získať výsledok klasifikácie tejto značky pomocou opísaného algoritmu. Táto aplikácia sa skladá zo 4 modulov: webová aplikácia, modul neurónových sietí, klasifikačný modul a administrátorské rozhranie. Schéma interakcie modulov je znázornená na obrázku 7.

Obrázok 7, schéma klasifikačného systému
Čísla v diagrame označujú postupnosť akcií, keď používateľ pracuje so systémom. Používateľ odovzdá obrázok. Požiadavku používateľa spracuje webový server a stiahnutý obrázok prenesie do modulu neurónovej siete, kde sa na obrázku vykonajú všetky potrebné transformácie (zmenšenie, zmena farebnej schémy atď.), po ktorých každá z neurónových sietí generuje vlastnú predpoveď. Riadiaca logika tohto modulu potom vyberie dve najpravdepodobnejšie predpovede pre každú sieť a vráti tieto údaje na webový server. Webový server odovzdá prijaté predikčné údaje siete do klasifikačného modulu, kde sa spracuje a vytvorí sa konečná odpoveď o predpovedanej triede obrázka, ktorá sa vráti na webový server a odtiaľ používateľovi. V tomto prípade sa interakcia medzi používateľom a web serverom a web serverom a modulmi neurónových sietí a klasifikácia uskutočňuje prostredníctvom požiadaviek REST pomocou protokolu HTTP. Obrázok sa prenáša v dátovom formáte viacdielneho formulára a údaje o výsledkoch práce klasifikátorov sú vo formáte JSON. Vďaka tejto prevádzkovej logike sú jednotlivé moduly dostatočne izolované od seba, čo umožňuje ich nezávislý vývoj vrátane použitia rôznych programovacích jazykov a v prípade potreby je možné jednoducho zmeniť prevádzkovú logiku každého modulu samostatne bez ovplyvnenia prevádzkovej logiky ostatných modulov. .
Jazyky HTML a Java Script boli použité na implementáciu používateľského rozhrania v tomto systéme, jazyk Java bol použitý na implementáciu webového servera a klasifikačného modulu a jazyk Python bol použitý na implementáciu modulu neurónových sietí. Vzhľad používateľského rozhrania systému je znázornený na obrázku 8.

Obrázok 8. Používateľské rozhranie systému
Použitie tohto systému predpokladá, že neurónová sieť a klasifikačné moduly už obsahujú natrénované modely. Zároveň je poskytnuté administrátorské rozhranie pre trénovacie modely, čo je v podstate sada python skriptov na trénovanie neurónových sietí a konzolová utilita Java na trénovanie finálneho klasifikátora. Tieto nástroje nie sú určené na časté používanie alebo používanie neprofesionálnymi používateľmi, takže pokročilejšie rozhranie pre nich nie je potrebné.
Vo všeobecnosti vyvinutá aplikácia úspešne plní všetky úlohy, ktoré sú jej pridelené, vrátane toho, že používateľovi umožňuje pohodlne získať predikciu triedy pre obrázok, ktorý si vybral. Preto zostáva otvorená iba otázka praktických výsledkov práce klasifikátora použitého v tomto algoritme a budeme sa ňou zaoberať v kapitole 3.
3. Výsledky experimentálnych štúdií
.1 Počiatočné údaje
Ako vstupné údaje v tejto štúdii bol použitý predtým uvedený súbor údajov GTSRB (German Traffic Signs Recognition Benchmark). Tento súbor údajov pozostáva z 51840 obrázkov patriacich do 43 tried. Počet obrázkov patriacich do rôznych tried je zároveň odlišný. Rozdelenie počtu obrázkov podľa tried je znázornené na obrázku 9.

Obrázok 9. Rozdelenie počtu obrázkov podľa tried
Líšia sa aj veľkosti vstupných obrázkov. Najmenší obrázok má šírku 15 pixelov a najväčší má šírku 250 pixelov. Všeobecné rozdelenie veľkostí obrázkov je znázornené na obrázku 10.

Obrázok 10. Rozdelenie veľkostí obrázkov
Zdrojové obrázky sú prezentované vo formáte ppm, teda ako súbor, kde každý pixel zodpovedá trom číslam - hodnotám intenzity červenej, zelenej a modrej zložky.
3.2 Predspracovanie údajov
Pred začatím prác boli podľa toho pripravené prvotné dáta - prevedené z PPM formy do formátu JPEG, s ktorým môže knižnica Caffe pracovať, náhodne rozdelené do tréningových a testovacích sád v pomere 80:20% a tiež škálované. Klasifikačný algoritmus používa obrázky dvoch veľkostí - 45 * 45 (na trénovanie viacvrstvového perspronu na binarizovaných dátach) a 60 * 60 (na trénovanie iných sietí), takže inštancie týchto dvoch veľkostí boli vytvorené pre každý obrázok tréningovej a testovacej sady. . Na každý z obrázkov sa aplikovali aj vyššie uvedené transformácie (binarizácia, normalizácia histogramu, vylepšenie kontrastu) a už získané obrázky sa uložili do databázy LMDB (Lightning Memory-Mapped Database), čo je rýchly a efektívny kľúč – hodnota. úložisko“. Tento spôsob ukladania dát poskytuje najrýchlejšiu a najpohodlnejšiu prácu knižnice Caffe. Obrázky boli konvertované pomocou Python Imaging Library (PIL) a scikit-image. Príklady obrázkov získaných po každej z transformácií sú na obrázku 11. Obrázky uložené v databáze boli neskôr použité na priame trénovanie neurónových sietí.
Obrázok 11. Výsledky aplikovania transformácií na obrázok
Čo sa týka trénovania neurónových sietí, každá zo sietí sa trénovala samostatne a vyhodnocovali sa výsledky jej práce a následne sa zostavoval a trénoval finálny klasifikátor. Ešte predtým však bola vybudovaná a natrénovaná najjednoduchšia sieť, ktorou je perceptrón s jednou skrytou vrstvou. Úvaha o tejto sieti mala dva ciele – preštudovať si prácu s knižnicou Caffe na jednoduchom príklade a vytvoriť meradlo pre vecnejšie hodnotenie výsledkov práce iných sietí v porovnaní s ňou. Preto v ďalšej časti zvážte každý zo sieťových modelov a výsledky jeho práce podrobnejšie.
3.3 Výsledky jednotlivých modelov
Modely implementované v priebehu tejto štúdie zahŕňajú:
Neurónová sieť s jednou skrytou vrstvou
· Viacvrstvová neurónová sieť postavená na základe počiatočných údajov
Viacvrstvová neurónová sieť postavená na báze binarizovaných dát
Konvolučná sieť postavená na základe pôvodných údajov
· Konvolučná sieť postavená na základe údajov RGB po zarovnaní grafu
Konvolučná sieť postavená na báze odtieňov šedej - dáta po zarovnaní grafu
Konvolučná sieť postavená na základe údajov v odtieňoch šedej po zvýšení kontrastu
· Kombinovaný model pozostávajúci z kombinácie dvoch viacvrstvových neurónových sietí a 4 konvolučných.
Zvážme každú z nich podrobnejšie.
Existuje neurálny s jednou skrytou vrstvou, aj keď sa nevzťahuje na modely hlbokého učenia, napriek tomu sa ukazuje ako veľmi užitočný na implementáciu, po prvé, ako školiaci materiál pre prácu s knižnicou, a po druhé, ako nejaký základný algoritmus. pre porovnanie s prácou iných modelov . Medzi nesporné výhody tohto modelu patrí ľahká konštrukcia a vysoká rýchlosť učenia.
Tento model bol vytvorený pre pôvodné farebné obrázky s veľkosťou 45 x 45 pixelov, pričom skrytá vrstva obsahovala 500 neurónov. Tréning siete trval približne 30 minút a výsledná presnosť predikcie bola 59,7 %.
Druhým zostaveným modelom je viacvrstvová plne prepojená neurónová sieť. Tento model bol vytvorený pre binarizované a farebné verzie obrázkov menšieho formátu a obsahoval 4 skryté vrstvy. Konfigurácia siete je opísaná nasledovne:
vstupná vrstva
Vrstva 1, 1500 neurónov
Vrstva 2 500 neurónov
Vrstva 3 300 neurónov
Vrstva 4, 150 neurónov
výstupná vrstva
Schematicky je model tejto siete znázornený na obrázku 12.

Obrázok 12. Schéma viacvrstvového perceptrónu
Výsledná presnosť výsledného modelu je 66,1 % pre binarizované obrázky a 81,5 % pre farebné. Avšak – čo ospravedlňuje zostavenie modelu pre binarizované obrázky napriek jeho nižšej presnosti – existovalo množstvo obrázkov, pre ktoré bol práve binarizovaný model schopný určiť správnu triedu. Farebný obrazový model si navyše vyžiadal výrazne dlhší čas na zaškolenie – približne 5 hodín v porovnaní s 1,5 hodinou pri binarizovanej verzii.
Ostatné zostavené modely sú nejakým spôsobom založené na konvolučných sieťach, keďže práve takéto siete preukázali najväčšiu efektivitu v úlohách typu rozpoznávania obrazu. Známa sieť LeNet, vyvinutá na klasifikáciu obrázkov z dátového súboru ImageNet, bola vzatá ako základ pre architektúru neurónovej siete. Aby však zodpovedali uvažovaným obrázkom, ktoré majú výrazne menšiu veľkosť, bola sieť upravená. Stručný popis architektúry siete:
3 konvolučné vrstvy s veľkosťou jadra 9, 3 a 3
3 vrstvy podvzorkovania
3 plne prepojené vrstvy s veľkosťou 100, 100 a 43 neurónov
Táto sieť bola samostatne trénovaná na väčších originálnych snímkach, snímkach po vyrovnaní histogramu (zachovaná farba), snímkach po vyrovnaní histogramu zredukovaných na čiernobiele a nakoniec čiernobielych snímkach so zvýšeným kontrastom. Výsledky vzdelávania sú uvedené v tabuľke 1:
Tabuľka 1. Výsledky tréningu konvolučnej siete
Vidno, že najlepšie výsledky vykázala sieť postavená na báze čiernobielych obrázkov po vyrovnaní histogramu. Dá sa to vysvetliť tým, že v procese vyrovnávania diagramu sa kvalita obrazu, napríklad rozdiely medzi obrazom a pozadím a celkový stupeň jasu, zlepšili a zároveň sa zlepšili ďalšie informácie obsiahnuté v farebnosť a nenesenie výraznej sémantickej záťaže - človek je schopný ľahko rozoznať tie isté samotné znaky čiernobielo - ale zašumený obraz a sťažujúce klasifikáciu - bola eliminovaná. Trénujte každú sieť na trénovacej množine pomocou metódy backpropagation (množina je rovnaká pre všetky siete, ale na obrázky sú aplikované rôzne transformácie) 2. Pre každú inštanciu trénovacej množiny získajte z každej siete dve najpravdepodobnejšie triedy v zostupnom poradí pravdepodobnosti, uložte výslednú množinu (celkovo 12 hodnôt) a skutočný štítok triedy Použite výslednú množinu údajov – 12 atribútov a označenie triedy – ako trénovaciu množinu pre konečný klasifikátor Vyhodnoťte presnosť výsledného modelu: pre každú inštanciu testovacieho súboru získajte dve najpravdepodobnejšie triedy v zostupnom poradí pravdepodobnosti z každej siete a konečnú predpoveď triedy založenú na tomto súbore údajov Na základe výsledkov krokov z tejto schémy bola vypočítaná konečná presnosť kombinovaného algoritmu: 93 % pri použití algoritmu J48 a 94,8 % pri použití KStar. Algoritmus založený na rozhodovacom strome zároveň vykazuje o niečo horšie výsledky, má však dve dôležité výhody: po prvé, strom získaný ako výsledok činnosti algoritmu jasne demonštruje klasifikačnú logiku a umožňuje vám lepšie pochopiť skutočnú štruktúru údajov. (napríklad, ktorá zo sietí dáva najpresnejšie predpovede pre určitý typ znakov, a preto jej predikcia jednoznačne určuje výsledok), a po druhé, po zostavení modelu vám tento algoritmus umožňuje veľmi rýchlo klasifikovať nové entity, pretože klasifikácia vyžaduje iba jeden prechod cez strom zhora nadol. Pokiaľ ide o algoritmus KStar, model sa v priebehu svojej činnosti v skutočnosti nevytvára a klasifikácia je založená na hľadaní najpodobnejších inštancií v rámci trénovacej množiny. Preto tento algoritmus, hoci klasifikuje entity, neposkytuje pre ne žiadne ďalšie informácie, a čo je najdôležitejšie, klasifikácia každej inštancie môže vyžadovať značné množstvo času, čo môže byť neprijateľné pre úlohy, pri ktorých potrebujete získať výsledok veľmi rýchlo, napríklad pri rozpoznávaní dopravných značiek pri automatickej jazde. Tabuľka 2 predstavuje všeobecné porovnanie výsledkov všetkých uvažovaných algoritmov. Tabuľka 2. Porovnanie výsledkov algoritmov Obrázok 13 ukazuje graf sieťového tréningu na príklade konvolučnej siete pre údaje v odtieňoch šedej s vyrovnaním histogramu (počet iterácií na osi x, presnosť na osi y). Obrázok 13. Graf tréningu konvolučnej siete Aby sme zhrnuli výsledky štúdie, užitočné je aj preštudovať si výsledky klasifikácie a identifikovať, ktoré znaky sa klasifikovali najľahšie a ktoré, naopak, ťažko rozpoznať. Na tento účel zvážte výstupné hodnoty algoritmu J48 a výslednú kontingenčnú tabuľku (pozri prílohu 3). Je vidieť, že pre niektoré značky je presnosť klasifikácie 100% alebo veľmi blízko k nim - napríklad sú to značky „Stoj“ (trieda 14), „Daj prednosť v jazde“ (trieda 13), „Hlavná cesta“ ( trieda 12), „Ukončite všetky obmedzenia“ (trieda 32), „Prejazd odmietnutý“ (trieda 15) (Obrázok 12). Väčšina týchto značiek má charakteristický tvar („Hlavná cesta“) alebo špeciálne grafické prvky, ktoré nemajú obdobu na iných značkách („Koniec všetkých obmedzení“). Obrázok 12. Príklady ľahko rozpoznateľných dopravných značiek Iné značky sa často navzájom miešajú, napríklad ako obchádzka vľavo a obchádzka vpravo alebo rôzne značky obmedzujúce rýchlosť (obrázok 13). Obrázok 13. Príklady bežne zamieňaných znakov Je zarážajúce, že neurónové siete často miešajú znaky, ktoré sú navzájom symetrické - to platí najmä pre konvolučné siete, ktoré hľadajú lokálne znaky v obraze a neanalyzujú obraz ako celok - na klasifikáciu takýchto obrazov sú vhodnejšie viacvrstvové perceptróny . V súhrne môžeme povedať, že pomocou konvolučných neurónových sietí a kombinovaného algoritmu postaveného na ich základe sa nám podarilo dosiahnuť dobré výsledky v klasifikácii dopravných značiek - presnosť výsledného klasifikátora je takmer 95%, čo nám umožňuje na získanie praktických výsledkov má navyše navrhovaný prístup využívajúci dodatočný klasifikátor na kombinovanie výsledkov neurónových sietí veľký priestor na ďalšie zlepšenie. Záver
V tomto príspevku je podrobne študovaný problém rozpoznávania obrazu pomocou aparátu umelých neurónových sietí. Zvažovali sa najrelevantnejšie prístupy k rozpoznávaniu obrazu, vrátane tých, ktoré využívajú hlboké neurónové siete, a na príklade problému rozpoznávania dopravných značiek pomocou hlbokých sietí bol vyvinutý vlastný algoritmus na rozpoznávanie obrazu. Podľa výsledkov práce možno povedať, že všetky úlohy stanovené na začiatku práce boli splnené: Uskutočnil sa analytický prehľad literatúry na tému využitia umelých neurónových sietí na rozpoznávanie obrazu. Na základe výsledkov tohto prehľadu sa zistilo, že najefektívnejšie a najrozšírenejšie sú v poslednej dobe prístupy k rozpoznávaniu obrazu založené na použití hlbokých konvolučných sietí. Algoritmus na rozpoznávanie obrazu bol vyvinutý na príklade problému rozpoznávania dopravných značiek pomocou súboru neurónových sietí pozostávajúci z dvoch viacvrstvových perceptrónov a 4 hlbokých konvolučných sietí a pomocou dvoch typov dodatočného klasifikátora - J48 a KStar - na kombináciu výsledkov. jednotlivých sietí a tvoria konečnú predpoveď Bol vyvinutý prototyp systému na rozpoznávanie obrázkov na príklade dopravných značiek na základe algoritmu z bodu 3, ktorý používateľovi poskytuje webové rozhranie na nahrávanie obrázka a pomocou vopred pripravených modelov tento obrázok klasifikuje a zobrazuje výsledok klasifikácie. používateľovi Algoritmus vyvinutý v kapitole 3 bol trénovaný pomocou súboru údajov GTSRB, pričom výsledky každej zo sietí v ňom zahrnutých a konečná presnosť algoritmu pre dva typy dodatočného klasifikátora boli hodnotené samostatne. Najvyššiu presnosť rozpoznávania rovnajúcu sa 94,8 % dosahuje podľa výsledkov experimentov súbor neurónových sietí a klasifikátor KStar a spomedzi jednotlivých sietí najlepšie výsledky - presnosť 89,1 % vykázala konvolučná sieť, ktorá využíva predbežnú konverziu obrazu do odtieňov sivej a vykonáva ekvalizáciu histogramu obrazu. Vo všeobecnosti táto štúdia potvrdila, že v súčasnosti sú hlboké umelé neurónové siete, najmä konvolučné siete, najefektívnejším a najsľubnejším prístupom na klasifikáciu obrázkov, čo potvrdzujú aj výsledky mnohých štúdií a súťaží v rozpoznávaní obrázkov. Zoznam použitej literatúry
1. Al-Azawi M. A. N. Automatické rozpoznávanie dopravných značiek na základe neurónovej siete // Medzinárodný žurnál digitálnych informácií a bezdrôtových komunikácií (IJDIWC). - 2011. - zväzok 1. - č. 4. - S. 753-766. 2. Baldi P. Autoencoders, Unsupervised Learning, and Deep Architectures //ICML Unsupervised and Transfer Learning. - 2012. - T. 27. - S. 37-50. Bahlmann C. a kol. Systém na detekciu, sledovanie a rozpoznávanie dopravných značiek pomocou informácií o farbe, tvare a pohybe // Intelligent Vehicles Symposium, 2005. Proceedings. IEEE. - IEEE, 2005. - S. 255-260. Bastien F. a kol. Theano: nové funkcie a vylepšenia rýchlosti //predtlač arXiv arXiv:1211.5590. - 2012. Bengio Y., Goodfellow I., Courville A. hlboké učenie. - MIT Press, kniha sa pripravuje Bergstra J. a kol. Theano: matematický kompilátor CPU a GPU v Pythone //Proc. 9. Python vo vede Conf. - 2010. - S. 1-7. Broggi A. a kol. Rozpoznávanie dopravných značiek v reálnom čase // Sympózium inteligentných vozidiel, 2007 IEEE. - IEEE, 2007. - S. 981-986. Canny J. Výpočtový prístup k detekcii hrán //Analýza vzorov a strojová inteligencia, IEEE transakcie zapnuté. - 1986. - č. 6. - S. 679-698. Ciresan D., Meier U., Schmidhuber J. Viacstĺpcové hlboké neurónové siete pre klasifikáciu obrazu //Počítačové videnie a rozpoznávanie vzorov (CVPR), 2012 Konferencia IEEE. - IEEE, 2012. - S. 3642-3649. Ciresan D. a kol. Výbor neurónových sietí pre klasifikáciu dopravných značiek // Neurónové siete (IJCNN), Medzinárodná spoločná konferencia v roku 2011. - IEEE, 2011. - S. 1918-1921. 11. Ciresan D. C. a kol. Hlboké veľké viacvrstvové perceptróny na rozpoznávanie číslic //Neurónové siete: Obchodné triky. - Springer Berlin Heidelberg, 2012. - S. 581-598. Daugman J. G. Kompletné diskrétne 2-D Gabor transformácie pomocou neurónových sietí na analýzu a kompresiu obrazu //Akustika, spracovanie reči a signálu, IEEE transakcie zapnuté. - 1988. - T. 36. - Č. 7. - S. 1169-1179. Gao X. W. a kol. Rozpoznávanie dopravných značiek na základe ich farebných a tvarových prvkov extrahovaných pomocou modelov ľudského videnia //Journal of Visual Communication and Image Representation. - 2006. - T. 17. - Č. 4. - S. 675-685. Goodfellow I. J. a kol. Pylearn2: výskumná knižnica strojového učenia //predtlač arXiv arXiv:1308.4214. - 2013. Han J., Kamber M., Pei J. Data mining: Koncepty a techniky. - Morgan Kaufmann, 2006. Harris C., Stephens M. Kombinovaný rohový a okrajový detektor //Alvey vision conference. - 1988. - T. 15. - S. 50. Houben S. a kol. Detekcia dopravných značiek v reálnych obrazoch: Nemecká referenčná hodnota detekcie dopravných značiek //Neurónové siete (IJCNN), Medzinárodná spoločná konferencia v roku 2013. - IEEE, 2013. - S. 1-8. Huang F. J., LeCun Y. Učenie vo veľkom meradle so svm a konvolučnou sieťou na rozpoznávanie generických objektov // Konferencia počítačovej spoločnosti IEEE o počítačovom videní a rozpoznávaní vzorov v roku 2006. - 2006. Huttenlocher D. P., Ullman S. Rozpoznávanie objektov pomocou zarovnania //Proc. ICCV. - 1987. - T. 87. - S. 102-111. Jia, Yangqing. "Caffe: Open source konvolučná architektúra pre rýchle vkladanie funkcií." h ttp://caffe. Berkeleyvision. org (2013). Krizhevsky A., Sutskever I., Hinton G. E. Klasifikácia Imagenet s hlbokými konvolučnými neurónovými sieťami //Pokroky v systémoch spracovania neurónových informácií. - 2012. - S. 1097-1105. Lafuente-Arroyo S. a kol. Klasifikácia dopravných značiek invariantná k rotácii pomocou podporných vektorových strojov //Proceedings of Advabced Concepts for Intelligent Vision Systems, Brusel, Belgicko. - 2004. LeCun Y., Bengio Y. Konvolučné siete pre obrázky, reč a časové rady //Príručka teórie mozgu a neurónových sietí. - 1995. - T. 3361. - S. 310. LeCun Y. a kol. Učebné algoritmy pre klasifikáciu: Porovnanie rozpoznávania ručne písaných číslic //Neurónové siete: perspektíva štatistickej mechaniky. - 1995. - T. 261. - S. 276. Masci J. a kol. Skladané konvolučné automatické kódovače na extrakciu hierarchických prvkov //Umelé neurónové siete a strojové učenie-ICANN 2011. - Springer Berlin Heidelberg, 2011. - S. 52-59. Matan O. a kol. Ručne písané rozpoznávanie znakov pomocou architektúr neurónových sietí //Proceedings of the 4th USPS Advanced technology Conference. - 1990. - S. 1003-1011. McCulloch W. S., Pitts W. Logický kalkul myšlienok imanentných v nervovej činnosti // Bulletin matematickej biofyziky. - 1943. - T. 5. - Č. 4. - S. 115-133. Minsky M., Seymour P. Perceptrons. - 1969. Mitchell T. Generatívne a diskriminačné klasifikátory: naivná Bayes a logistická regresia, 2005 //Rukopis dostupný na #"897281.files/image021.gif">

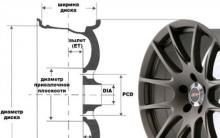
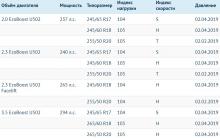
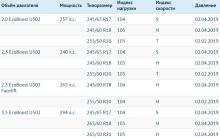







Rozmýšľame, ako obnoviť Skype na prenosnom počítači
Fixies masters plná verzia Fixies hra plná verzia stiahnutá do vášho počítača
Inštalácia alebo aktualizácia, oprava chýb Net framework 3
Virtuálne meny a virtuálne burzy vo svete
Zlaté čísla Ako predať krásne telefónne číslo