A tak ďalej.. V prvom rade, samozrejme, hovoríme o zdrojoch internetu a World Wide Web. URI poskytuje jednoduchý a rozšíriteľný spôsob identifikácie zdrojov. Rozšíriteľnosť URI znamená, že v rámci URI už existuje niekoľko identifikačných schém a v budúcnosti budú vytvorené ďalšie.
Ďalšie podrobnosti nájdete v časti"Štruktúra URI" nižšie.
Najznámejšími príkladmi URI sú URN. URL je URI, ktoré okrem identifikácie zdroja poskytuje aj informácie o umiestnení tohto zdroja. A URN je URI, ktoré identifikuje zdroj v špecifickom mennom priestore (a teda v špecifickom kontexte). Napríklad URN urn:ISBN:0-395-36341-1 je URI, ktoré ukazuje na zdroj (knihu) 0-395-36341-1 v mennom priestore ISBN, ale na rozdiel od URL URN neukazuje na umiestnenie tohto zdroja. V poslednom čase sa však objavila tendencia iba povedať URI o akomkoľvek reťazci identifikátora bez ďalšieho upresňovania. Snáď sa teda pojmy URL a URN čoskoro stanú minulosťou.
Príbeh
Nová verzia URI bola definovaná v roku 1998 v RFC 2396, v rovnakom čase slovo Univerzálny názov bol zmenený na Uniforma. V decembri 1999 RFC 2732 zaviedol menšie zmeny v špecifikácii URI, aby sa zabezpečila kompatibilita s augustom 2002. RFC 3305 oznámilo ukončenie podpory termínu URL a prioritu URI. Aktuálna štruktúra a syntax URI sa riadi RFC 3986, vydaným v januári 2005. Mnohé z najnovších technológií sémantického webu (napríklad RDF) sú založené na štandarde URI. Vedúcu úlohu vo vývoji URI má teraz World Wide Web Consortium.
Nedostatky
URL bola zásadnou inováciou na internete, takže princípy URI boli zdokumentované ako úplne kompatibilné s URL. Odtiaľ pochádza veľká nevýhoda URI, ktorá pochádza z adresy URL. V URI, rovnako ako v URL, je možné použiť iba obmedzený súbor latinských znakov a interpunkčných znamienok (dokonca menej ako v cyrilike, hieroglyfoch alebo, povedzme, špecifických francúzskych znakoch, potom budeme musieť URI zakódovať do rovnakým spôsobom ako vo Wikipédii sú adresy URL kódované znakmi Unicode... Napríklad reťazec ako:
http://en.wikipedia.org/wiki/Microcredit
zakódované v URL ako:
http://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D0%BA%D1%80%D0%B5%D0%B4%D0 %B8%D1%82
Keďže písmená všetkých abecied podliehajú takejto transformácii, s výnimkou latinskej abecedy používanej v angličtine, URI so slovami v iných jazykoch (aj európskych) strácajú schopnosť byť vnímané ľuďmi. A to je v hrubom rozpore s princípom internacionalizmu, ktorý hlásajú všetky popredné organizácie internetu vrátane W3C a IRI (angl. Medzinárodný identifikátor zdroja ) sú medzinárodné identifikátory zdrojov, v ktorých možno bez problémov používať znaky Unicode a ktoré by neporušovali práva iných jazykov. Aj keď je ťažké vopred povedať, či identifikátory niekedy budú môcť . Cieľom tohto formátu je vytvoriť identifikátory, ktoré sú úplne nezávislé od kontextu, t. j. nezávislé od protokolu, domény, cesty, aplikácie a platformy. absolútne nezávislý.
Tvorca URI, Tim Berners-Lee, tiež povedal, že systém názvov domén, ktorý je základom adresy URL, je zlé rozhodnutie, ktoré vnucuje zdrojom hierarchickú architektúru, ktorá nie je vhodná pre hypertextový web.
Štruktúra URI
Analýza štruktúry URI
Pre takzvané „analyzovanie“ URI (angl. parsovanie), čiže na rozklad URI na jednotlivé časti a ich následnú identifikáciu je najvhodnejšie použiť systém regulárnych výrazov, ktorý je dnes dostupný takmer vo všetkých moderných programovacích jazykoch. Na analýzu URI sa odporúča nasledujúci vzor:
^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))? 12 3 4 5 6 7 8 9
Tento vzor zahŕňa 9 skupín označených vyššie číslami (viac o vzoroch a skupinách nájdete v časti Regulárne výrazy), ktoré najkompletnejšie a najpresnejšie analyzujú typickú štruktúru URI, kde:
- skupina 2 - schéma,
- skupina 4 - zdroj,
- skupina 5 - cesta,
- skupina 7 - žiadosť,
- skupina 9 - fragment.
Ak teda použijete tento vzor na analýzu napríklad takého typického URI:
http://www.ics.uci.edu/pub/ietf/uri/#Related
potom 9 vyššie uvedených skupín vzorov poskytne nasledujúce výsledky:
- http:
- //www.ics.uci.edu
- www.ics.uci.edu
- /pub/ietf/uri/
- žiadny výsledok
- žiadny výsledok
- #Súvisiace
- súvisiace
Rozdiel medzi URI a URL
Identifikátor URI nie vždy naznačuje, ako získať zdroj, na rozdiel od adresy URL, ale iba ho identifikuje. To umožňuje opísať pomocou RDF (Resource Description Framework) zdroje, ktoré nie je možné získať cez internet (napríklad osoba, auto, mesto atď.).
Príklady URI
Absolútne URI
http://ru.wikipedia.org/wiki/URI ftp://ftp.is.co.za/rfc/rfc1808.txt file://C:\UserName.HostName\Projects\Wikipedia_Articles\URI.xml ldap: ///c=GB?objectClass?one mailto: [e-mail chránený] dúšok: [e-mail chránený] news:comp.infosystems.www.servers.unix data:text/plain;charset=iso-8859-7,%be%fg%be tel:+1-816-555-1212 telnet://192.0.2.16:80 /urn:oáza:mená:špecifikácia:docbook:dtd:xml:4.1.2Odkazy URI
/relative/URI/with/absolute/path/to/resource.txt relatívna/cesta/k/resource.txt ../../../resource.txt resource.txt /resource.txt#frag01 #frag01 [prázdne riadok]pozri tiež
Odkazy
- RFC 3986 / STD 66 (od roku 2005)
- RFC 2396 (z roku 1998) – zastaraná syntax
Poznámky
Nadácia Wikimedia. 2010.
Pozrite sa, čo je „Uri“ v iných slovníkoch:
Uri- môže odkazovať na:Geografiu: * Kantón Uri je kantón (región) Švajčiarska * Uri (India), región a mesto v Kašmíre * Uri (SS), mesto na Sardínii, Taliansko * Úri, dedina v Pešti okres, Maďarsko * Sumerské URI, krajina AgadeURI, tri… … Wikipedia
uro- URÎ, urăsc, vb. IV. 1.prekl. A avea un puternic sentiment de antipatie, de duşmănie împotriva cuiva sau a ceva; a nu putea suferi pe cineva alebo ceva. 2.refl. impers. (Construit cu dativul) A se plictisi, a se sătura de ceva sau de cineva. ♢… … Diktár Roman
uri- urì interj., urỹ NdŽ, Jn, Aln, ùri kartojant 1. nusakomas puolančio šuns(ar šunų) urzgimas: Tik urỹ urỹ ir apipuolo mane šunes K.Būg(Ds). Urì urì šunes kad pradeda loti Šmn. ║ Ds sakoma pjudant šuniu. 2. Vžns nusakomas triukšmingas… … Slovník litovského jazyka
Ak chcete získať prístup k akýmkoľvek sieťovým zdrojom, musíte vedieť, kde sa nachádzajú a ako k nim možno pristupovať. World Wide Web používa štandardizovanú schému adresovania a identifikácie, berúc do úvahy skúsenosti s adresovaním a identifikáciou e-mailov, Gopher, WAIS, telnet, ftp a podobne. - URL, Uniform Resource Locator.
URI(Uniform Resource Identifier, Uniform Resource Identifier) (RFC 2396, august 1998) – Kompaktný reťazec znakov na identifikáciu abstraktného alebo fyzického zdroja. Zdroj je akýkoľvek objekt patriaci do nejakého priestoru. Zahŕňa a prepisuje predtým definované adresy URL (RFC 1738/RFC 1808) a URN (RFC 2141, RFC 2611).
Identifikátor URI je určený na jedinečnú identifikáciu akéhokoľvek zdroja.
Niektoré podmnožiny URI:
URN(Uniform Resource Name) – Súkromná schéma URI „urn:“ s podmnožinou „namespace“, ktorá musí byť jedinečná a nezmenená, aj keď zdroj už neexistuje alebo nie je dostupný.
Predpokladá sa, že napríklad prehliadač vie, kde tento zdroj hľadať.
Syntax:
urn:namespace: data1.data2,more-data kde menný priestor určuje, ako sa použijú údaje po druhom ":".
Príklad URN:
urna:ISBN: 0-395-36341-6
ISBN - tematický klasifikátor pre vydavateľov
0-395-36341-6 - konkrétne číslo predmetu knihy alebo časopisu
Po prijatí URN klientsky program pristupuje k ISBN (adresár „klasifikátor tém pre vydavateľov“ na internete). A dostane dekódovanie čísla predmetu "0-395-36341-6" (napríklad: "kvantová chémia").
URN je široko používaný v sieťach P2P (ako edonkey).
Príklad URN ukazujúci na obraz disku Adobe Photoshop v8.0 v sieti edonkey:
urn:ed2k://|file|AdobePhotoshopv8.0.iso|940769280|b34c101c90b6dedb4071094cb1b9f2d3|/
ed2k - ukazuje na sieť
Adobe Photoshop v8.0.iso – názov súboru
940769280 - veľkosť v bajtoch
- identifikátor súboru (vypočítaný pomocou hašovacej funkcie)
Adresa URL Uniform Resource Locator:
URL(Uniform Resource Locator, RFC 1738) - jednotný lokátor zdrojov (ukazovateľ), štandardizovaný spôsob zaznamenávania adresy zdroja na WWW a internete. URL má flexibilnú a rozšíriteľnú štruktúru pre čo najprirodzenejšie umiestnenie zdrojov v sieti, ktorá identifikuje zdroj podľa spôsobu, akým sa k nemu pristupuje (napríklad jeho „umiestnenie v sieti“), namiesto toho, aby ho identifikoval názvom resp. ďalšie atribúty tohto zdroja.
Príklady adries URL:
http://www.ipm.kstu.ru/index.php
ftp://www.ipm.kstu.ru/
Na vyjadrenie adresy sa používa obmedzená sada znakov ASCII.
Všeobecný tvar adresy môže byť reprezentovaný takto:
<схема>://<логин>:<пароль>@<хост>:<порт>/<полный-путь-к-ресурсу >
schému prístupu k prostriedkom: http, ftp, gopher, mailto, správy, telnet, súbor, muž, info, whatis, ldap, wais atď.
Prihlasovacie heslo- používateľské meno a heslo používané na prístup k zdroju
hostiteľ názov domény hostiteľa alebo jeho IP adresa.
port- hostiteľský port na pripojenie
úplná cesta k zdroju -špecifikujúce informácie o umiestnení zdroja (závisí od protokolu).
Príklady adries URL:
http://example.com #default žiadosť o úvodnú stránku
http://www.example.com/site/map.html #request danú stránku v danom adresári
http://example.com:81/script.php #pripojte sa k neštandardnému portu
http://example.org/script.php?key=value #request s odoslaním parametra do skriptu
ftp://user: [e-mail chránený]#pripojenie k ftp serveru s autorizáciou
http://192.168.0.1/example/www #pripojenie k sieťovej adrese
file:///srv/www/htdocs/index.html #open local file
gopher://example.com/1 #pripojenie k serveru gopher
URL – Uniform Resource Locators explicitne popisuje, ako sa dostať k objektu.
Nástup adries URL sa stal významnou inováciou na internete. Od svojho vynálezu až dodnes má však štandard URL vážnu nevýhodu – môže používať iba obmedzenú množinu znakov, dokonca menších ako v ASCII: latinské písmená, čísla a len niektoré interpunkčné znamienka – .
Ak chceme v URL použiť znaky cyriliky, hieroglyfy, alebo povedzme špecifické francúzske znaky, potom treba znaky, ktoré potrebujeme, prekódovať špeciálnym spôsobom.
V ruskojazyčnej Wikipédii je možné vidieť príklady kódovania URL každý deň, keďže ruský jazyk používa znaky cyriliky. Napríklad riadok ako:
http://en.wikipedia.org/wiki/Microcredit
zakódované v URL ako:
http://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D0%BA%D1%80%D0%B5%D0%B4%D0 %B8%D1%82
Takáto konverzia prebieha v dvoch fázach: po prvé, každý znak cyriliky je zakódovaný v Unicode (UTF-8) do sekvencie dvoch bajtov a potom je každý bajt tejto sekvencie zapísaný v hexadecimálnom zobrazení:
M -> DO a 9C -> %D0%9C
a → DO a B8 → %D0%B8
do → D0 a BA → %D0%BA
p → D1 a 80 → %D1%80 atď.
Každému takémuto hexadecimálnemu bajtovému kódu podľa špecifikácie URL predchádza znak percenta (%) – preto vznikol aj anglický výraz „percent-encoding“, ktorý označuje spôsob kódovania znakov v URL a URI.
Keďže písmená všetkých abecied podliehajú takejto transformácii, s výnimkou základnej latinskej abecedy, adresa URL so slovami vo veľkej väčšine jazykov (okrem angličtiny, taliančiny, latinčiny) sa môže stať pre človeka nečitateľnou.
To všetko je v rozpore s princípom internacionalizmu, ktorý hlásajú všetky popredné organizácie internetu vrátane W3C a ISOC. Na vyriešenie tohto problému je navrhnutý štandard IRI (International Resource Identifier) - medzinárodné identifikátory zdrojov, v ktorých by sa dali bez problémov používať znaky Unicode, a ktoré by teda neporušovali práva iných jazykov.
Ďalšie schémy adries URL
Schéma HTTP.
Schéma špecifikuje jeho identifikátor, adresu stroja, TCP port, cestu v adresári servera, premenné a ich hodnoty, návestie.
Syntax:
http://[
http - názov schémy
užívateľ - užívateľské meno
hostiteľ - názov hostiteľa
port - číslo portu
dopyt(<имя-поля>=<значение>{&<имя-поля>=<значение>) - reťazec dopytu
Definované v RFC 2068. Štandardne je port=80.
Príklady:
http://ipm.kstu.ru/internet/index.php
Toto je najbežnejší typ URI používaný vo WWW dokumentoch. Za názvom schémy (http) nasleduje cesta pozostávajúca z adresy domény stroja a úplnej adresy dokumentu HTML v strome servera HTTP.
IP adresa môže byť použitá aj ako adresa stroja:
http://195.208.44.20/internet/index.php
Ak server protokolu HTTP beží na inom porte TCP ako 80, prejaví sa to v adrese:
http://195.208.44.20:8080/internet/index.php
http://195.208.44.20/internet/index.php#metka1
Znak „#“ oddeľuje názov dokumentu od názvu štítku.
Premenné a ich hodnoty sa odovzdávajú takto:
http://ipm.kstu.ru/internet/index.php?var1=value1&vard2=value2
Hodnoty „var1“ a „var2“ sú názvy premenných a „value1“ a „value2“ sú ich hodnoty.
FTP schéma
Táto schéma vám umožňuje adresovať archívy súborov FTP.
Syntax:
ftp://[
ftp - názov schémy
užívateľ - užívateľské meno
heslo - heslo používateľa
hostiteľ - názov hostiteľa
port - číslo portu
url-path - cesta k súboru a samotný súbor
Definované v RFC 1738. V predvolenom nastavení port=21, používateľ=anonym, heslo=e-mailová adresa, ak je zadané meno, ale nie je zadané heslo, zobrazí sa v dialógovom okne.
Príklady: ftp://ipm.kstu.ru/students/name/
Ak chcete zadať používateľské meno a heslo, musíte napísať takto:
ftp://meno: [e-mail chránený]://ipm.kstu.ru/students/name/
V tomto prípade sú tieto parametre oddelené od adresy stroja symbolom „@“ a navzájom dvojbodkou.
Schéma Mailto
Táto schéma je určená na odosielanie pošty.
Syntax:
mailto:[
mailto - názov schémy
e-mail-1 (
užívateľ - užívateľské meno
hostiteľ - názov hostiteľa
e-mail-2 - druhá e-mailová adresa
dopyt(<имя-поля-заголовка>=<значение>{&<имя-поля-заголовка>=<значение>) - reťazec dopytu
mailto: [e-mail chránený]
V tejto schéme sa odovzdávajú polia a ich hodnoty:
mailto: [e-mail chránený]?subject=Subject_of_the_mail&body=Text_to_be_embedded_in_the_mail
Adresu príjemcu je možné zapísať aj ako hodnotu poľa to:
mailto: [e-mail chránený]?subject=Subject_of_the_mail&body=Text_to_be_embedded_in_the_mail
Čo je HTTP?
Prvý dokument (nie však štandard) je RFC1945 (Hypertext Transfer Protocol -- HTTP/1.0 T. Berners-Lee, R. Fielding, H. Frystyk máj 1996)
Najnovšia verzia je RFC2616 (Hypertext Transfer Protocol -- HTTP/1.1 R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee jún 1999)
Hypertext Transfer Protocol je protokol na prenos hypertextu, protokol na vysokej úrovni (menovite na úrovni aplikácie). Používa sa službou WWW na prenos webových stránok.
HTTP (HyperText Transfer Protocol, RFC 2616, aktuálna verzia HTTP/1.1) je hypertextový prenosový protokol. Tento protokol bol pôvodne určený na výmenu hypertextových dokumentov, teraz boli jeho možnosti výrazne rozšírené (najmä pridané funkcie podpory streamovania).
HTTP je typický protokol klient-server, správy sa vymieňajú podľa schémy „request-response“ vo forme ASCII príkazov. Vlastnosťou protokolu HTTP je možnosť špecifikovať v požiadavke a odpovedi, ako je ten istý zdroj reprezentovaný rôznymi parametrami: formát, kódovanie, jazyk atď. Vďaka možnosti špecifikovať metódu kódovania správy klient a server si môže vymieňať binárne dáta, hoci tento protokol je textový.
HTTP je protokol aplikačnej vrstvy, ale používa sa aj ako „transport“ pre iné aplikačné protokoly ako SOAP, XML-RPC, WebDAV.
Protokol HTTP definuje spôsob interakcie medzi klientskym programom a serverovým programom v rámci technológie World Wide Web.
Ak chcete stiahnuť webovú stránku do klientskeho prehliadača, odošle požiadavku špeciálnemu programu nainštalovanému na serverovom počítači, ktorý sa nazýva http server, a spracuje z neho prijaté údaje. V tomto prípade je funkciou prehliadača vyžiadať si určitú stránku zo servera, získať ju a zobraziť ju na obrazovke používateľa. Server na druhej strane prijme požiadavku, vyhľadá požadovaný dokument a klientovi poskytne buď obsah nájdeného súboru, alebo chybové hlásenie, ak sa takýto súbor nenašiel alebo bol z nejakého dôvodu odmietnutý prístup k nemu. Dôležitým bodom pre pochopenie tohto procesu je, že http server neanalyzuje obsah prenášaného dokumentu. Zhruba povedané, http server sa nestará o to, čo je v požadovanom súbore, iba to odovzdá prehliadaču a prehliadač sa už postará o všetku prácu pri štruktúrovaní a zobrazení prijatých informácií.
Hľadanie požadovanej stránky sa vykonáva v špecifickom adresári, ktorý je pre túto stránku pridelený na serverovom počítači - odkaz na tento adresár sa nachádza v adrese zadanej používateľom. V prípade, že požiadavka nie je zaslaná na konkrétny dokument, ale na stránku ako celok, http server automaticky nahradí takzvanú „úvodnú stránku“ namiesto názvu prenášaného súboru s názvom index.htm alebo index.html (v niektorých prípadoch - default. htm alebo default.html). Tento dokument sa musí nachádzať v koreňovom adresári určenom na hosťovanie vašej lokality alebo, ak je uvedené inak, v adresári s názvom WWW. Všetky ostatné súbory môžu byť umiestnené buď v rovnakom adresári, alebo vo vnorených adresároch, čo je niekedy výhodné, najmä ak stránka obsahuje niekoľko tematických sekcií alebo nadpisov.
Okrem vami vytvorených podpriečinkov, do ktorých môžete voľne vkladať takmer akýkoľvek potrebný obsah, adresár servera zvyčajne obsahuje niekoľko ďalších adresárov, ktoré by ste mali spomenúť samostatne. Po prvé, toto je priečinok CGI-BIN, kde sa nachádzajú CGI skripty a ďalšie interaktívne aplikácie spustené z vašej stránky, ako aj niekoľko adresárov služieb potrebných pre normálnu prevádzku servera. V počiatočnej fáze by sa im jednoducho nemala venovať pozornosť. Niekedy sa v tom istom adresári, kde je uložený index.html, nachádza množstvo ďalších súborov: not_found.html – dokument, ktorý sa zobrazí, ak http server nemôže nájsť súbor požadovaný používateľom, zakázaný.html – sa zobrazí ako chybové hlásenie, ak je prístup k požadovanému dokumentu odmietnutý, a napokon, robots.txt je súbor, ktorý špeciálnym spôsobom popisuje pravidlá pre indexovanie vašej stránky vyhľadávacími nástrojmi.
Vo väčšine prípadov a najmä pri publikovaní domovskej stránky na serveroch, ktoré poskytujú bezplatný hosting, je používateľom odmietnutý prístup k adresárom služieb a priečinku CGI-BIN a zmena obsahu súborov not_found a prohibited.html je tiež nemožná. Toto by ste mali vziať do úvahy, ak plánujete do svojho zdroja zahrnúť akýkoľvek interaktívny obsah, ktorý si vyžaduje aspoň možnosť umiestniť súbory do jedného z priečinkov služby. V niektorých prípadoch možno nebudete mať povolené vytvárať vnorené adresáre na serveri, v takom prípade sa používateľ bude musieť uspokojiť iba s jedným adresárom vyhradeným pre vaše potreby.
Z vyššie uvedeného je zrejmé, že klientsky prehliadač môže prijímať a spracovávať informácie zo servera a umiestňovať a upravovať ich iba vtedy, ak je nahrávanie súborov na server implementované na základe protokolu HTTP pomocou špeciálnych CGI skriptov zahrnutých na serveri. webové rozhranie. Vo všetkých ostatných prípadoch musíte použiť takzvaný ftp-server, na ktorý môžete pomocou špeciálneho softvéru preniesť potrebné súbory a automaticky ich nahrať do adresára určeného pre vašu stránku. V oboch prípadoch budete pre prístup do systému potrebovať poznať svoje prihlasovacie meno a heslo. Malo by sa tiež pamätať na to, že väčšina serverových programov (najmä Apache pre platformy kompatibilné so systémom UNIX) rozlišuje medzi malými a veľkými písmenami, takže všetky názvy súborov a ich prípony by mali byť napísané malými písmenami, aby sa predišlo chybám, a vždy v latinke. Ten je spôsobený rozdielmi v spracovaní kódovania ruského jazyka, ktoré sú typické pre určité servery.
Protokol HTTP funguje nasledovne: klientsky program nadviaže TCP spojenie so serverom (štandardné číslo portu je 80) a odošle naň požiadavku HTTP. Server spracuje túto požiadavku a odošle HTTP odpoveď klientovi.
Interakcia medzi klientom a webovým serverom sa uskutočňuje prostredníctvom výmeny správ. Správy HTTP sa delia na požiadavky typu klient-server a odpovede server-klient.
Správy so žiadosťou a odpoveďou majú spoločný formát. Oba typy správ vyzerajú takto: najprv príde začiatočný riadok, potom možno jedno alebo viac polí hlavičky, nazývaných aj hlavičky, potom prázdny riadok (t. j. riadok pozostávajúci zo znakov CR a LF), ktorý označuje koniec hlavičky. polia a potom prípadne telo správy:
počiatočný reťazec
pole hlavičky 1
pole hlavičky 2
pole hlavičky N
telo správy
HTTP hlavičky
Formát počiatočného reťazca klienta a servera sa líši a bude popísaný nižšie. Existujú štyri typy hlavičiek:
Všeobecné hlavičky (general-headers), ktoré môžu byť prítomné v požiadavke aj v odpovedi;
hlavičky požiadaviek (request-headers), ktoré môžu byť prítomné iba v požiadavke;
Hlavičky odpovede (hlavičky odpovede), ktoré môžu byť prítomné iba v odpovedi;
Hlavičky entít, ktoré odkazujú na telo správy a popisujú jej obsah.
Každý nadpis pozostáva z názvu, dvojbodky „:“ a hodnoty. Najdôležitejšie položky sú uvedené v tabuľke 1.
stôl 1
HTTP hlavičky
| hlavička | Účel |
| Názvy objektov | |
| dovoliť | Uvádza metódy podporované serverom |
| kódovanie obsahu | Spôsob, akým je telo správy zakódované, napríklad na zmenšenie veľkosti |
| dĺžka obsahu | Dĺžka správy v bajtoch |
| Druh obsahu | Obsahuje označenie typu obsahu MIME odpovede. V závislosti od hodnoty Content-Type prehliadač zaobchádza s odpoveďou ako so stránkou HTML, s obrázkom gif alebo jpeg, so súborom na uloženie na disk alebo s niečím iným a vykoná príslušnú akciu. Niektoré typy obsahu: text/html - text vo formáte HTML (webová stránka); text/plain - obyčajný text (podobne ako "poznámkový blok"); image/jpeg - obrázok vo formáte JPEG; obrázok/gif - to isté, vo formáte GIF; Môže tiež prejsť kódovaním pre textové údaje. Napríklad: charset=windows-1251 charset=koi8-rus Content-Length - dĺžka obsahu odpovede v bajtoch (veľkosť súboru). Last-Modified – dátum a čas, kedy bol dokument naposledy upravený. |
| Etag | Jedinečná značka prostriedku na serveri, ktorá vám umožňuje porovnávať zdroje |
| Platnosť vyprší | Dátum a čas, kedy sa zdroj na serveri zmení a je potrebné ho znova načítať |
| Naposledy zmenené | Dátum a čas poslednej úpravy obsahu |
| Hlavičky odpovedí | |
| Vek | Počet sekúnd na opätovný pokus o získanie nového obsahu |
| umiestnenie | Identifikátor URI zdroja, ku ktorému má pristupovať a získať obsah |
| Opakovať-po | Dátum a čas alebo počet sekúnd, po ktorých sa žiadosť musí znova pokúsiť získať úspešnú odpoveď |
| server | Názov serverového softvéru, ktorý odoslal odpoveď |
| Hlavičky žiadostí | |
| súhlasiť | Zoznam typov obsahu podporovaných prehliadačom v poradí preferencií tohto prehliadača, napríklad: Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/ msword, aplikácia/vnd. ms-powerpoint, */* Toto je samozrejme potrebné v prípade, keď server môže vydať rovnaký dokument v rôznych formátoch. Hodnotu tohto parametra využívajú najmä CGI skripty na generovanie odpovede prispôsobenej pre daný prehliadač. |
| Prijať znakovú sadu | Kódovanie znakov, v ktorých môže klient akceptovať textový obsah |
| Prijmite kódovanie | Spôsob, akým môže server kódovať správu |
| Hostiteľ | Číslo hostiteľa a portu, z ktorého sa dokument požaduje |
| If-Modified-Since If-Match If-None-Match If-Range If-Unmodified-Since | Hlavičky požiadaviek na podmienený prístup k zdroju |
| Rozsah | Vyžiadajte si časť dokumentu |
| Používateľský agent | Názov klientskeho softvéru – hodnota je „kódové meno“ prehliadača, napríklad: Mozilla/4.0 (kompatibilný; MSIE 5.0; Windows 95; DigExt) |
| Všeobecné nadpisy | |
| spojenie | Pripojenie (spojenie) - môže nadobúdať hodnoty Keep-Alive a close. Keep-Alive („udržať nažive“) znamená, že po vydaní tohto dokumentu sa spojenie so serverom nepreruší a je možné zadať ďalšie požiadavky. Väčšina prehliadačov pracuje v režime Keep-Alive, pretože vám umožňuje „stiahnuť“ html stránku a obrázky pre ňu v jednom pripojení k serveru. Po nastavení Keep-Alive pretrváva až do prvej chyby alebo explicitne špecifikovaného v ďalšej požiadavke Connection: close. close - Spojenie sa po odpovedi na túto požiadavku uzavrie. |
| Dátum | Dátum a čas vygenerovania správy |
| pragma | Špeciálne príkazy špecifické pre implementáciu týkajúce sa prenášaného obsahu |
| Kódovanie prenosu | Ako je správa zakódovaná počas prenosu |
V niektorých hlavičkách je hodnotou dátum a čas. Musia byť vo formáte opísanom v RFC 1123, napríklad:
Telo správy obsahuje aktuálne prenášané informácie – užitočné zaťaženie správy. Telo správy je sekvencia oktetov (bajtov). Telo správy môže byť zakódované, pričom metóda kódovania je špecifikovaná v hlavičke objektu Content-Encoding.
Správa s požiadavkou od klienta na server pozostáva z riadku požiadavky, hlavičiek (všeobecné, požiadavky, objekt) a voliteľne z tela správy.
Reťazec požiadavky začína metódou, za ktorou nasleduje ID požadovaného prostriedku, verzia protokolu a znaky na konci riadka:
<Метод> <Идентификатор> <Версия HTTP>
Metóda určuje metódu, ktorá sa má použiť na požadovaný zdroj. Napríklad metóda GET hovorí, že klient chce získať obsah zdroja. Identifikátor identifikuje požadovaný zdroj. Verzia HTTP je označená reťazcom, ako je tento:
http/<версия>.<подверсия>
Metódy protokolu HTTP
Zvážte základné metódy protokolu HTTP.
Metóda OPTIONS vyžaduje informácie o možnostiach pripojenia (napr. metódy, typy dokumentov, kódovania), ktoré server podporuje pre požadovaný zdroj. Táto metóda umožňuje klientovi určiť možnosti a/alebo požiadavky súvisiace so zdrojom alebo schopnosťami servera bez vykonania akejkoľvek akcie so zdrojom alebo spustenia jeho sťahovania.
Ak odpoveďou servera nie je chybová správa, hlavičky entít obsahujú informácie, ktoré možno považovať za možnosti pripojenia. Napríklad hlavička Allow uvádza všetky metódy podporované serverom pre daný zdroj.
Ak je požadovaným identifikátorom zdroja hviezdička ("*"), potom požiadavka OPTIONS je určená na adresu servera ako celku.
Ak požadovaný identifikátor zdroja nie je hviezdička, potom sa požiadavka OPTIONS vzťahuje na možnosti, ktoré sú dostupné pri pripájaní k určenému zdroju.
Metóda GET vám umožňuje získať akékoľvek informácie súvisiace s požadovaným zdrojom. Vo väčšine prípadov, ak identifikátor požadovaného zdroja ukazuje na dokument (napríklad textový dokument, grafický obrázok, video), potom server vráti obsah tohto dokumentu (obsah súboru). Ak je požadovaným prostriedkom aplikácia (program) generujúca údaje, vygenerované údaje sa vrátia do tela správy odpovede a nie binárny obraz spustiteľného súboru. To sa využíva napríklad pri tvorbe CGI aplikácií. Ak identifikátor požadovaného zdroja ukazuje na adresár (adresár, priečinok), potom v závislosti od nastavení servera buď obsah adresára (zoznam súborov) alebo obsah jedného zo súborov nachádzajúcich sa v tomto adresári (zvyčajne index.html alebo default.htm). V druhom prípade je možné zadať názov priečinka so znakom „/“ na konci alebo bez neho. Ak tento symbol na konci identifikátora chýba, server vydá jednu z odpovedí na presmerovanie (so stavovými kódmi 301 alebo 302).
Rozlišuje sa medzi "podmieneným GET", v ktorom žiadosť obsahuje hlavičky požiadavky If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match alebo If-Range. Metóda podmieneného GET požaduje prenos objektu iba vtedy, ak spĺňa podmienky opísané v poskytnutých hlavičkách. Metóda podmieneného GET je určená na zníženie zbytočného zaťaženia siete, pretože umožňuje nenačítať dáta už uložené klientom.
Rozlišuje sa aj medzi „čiastočným GET“, v ktorom správa s požiadavkou obsahuje hlavičku žiadosti o rozsah. Čiastočný GET vyžaduje prenos iba časti objektu. Metóda čiastočného GET je určená na zníženie zbytočného zaťaženia siete tým, že požaduje iba časť objektu, keď druhá časť už bola načítaná klientom. Hodnota hlavičky Range je rozsah bajtov, ktoré sa majú prijať. Bajty sú číslované od 0. Začiatočné a koncové bajty rozsahu sú oddelené znakom „-“. Ak potrebujete získať niekoľko rozsahov, sú uvedené oddelené čiarkami.
Metóda HEAD je identická s metódou GET, okrem toho, že server v odpovedi nevracia telo správy. Metainformácie obsiahnuté v HTTP hlavičkách odpovede na požiadavku HEAD sú totožné s informáciami poskytnutými ako odpoveď na požiadavku GET. Túto metódu možno použiť na získanie informácií o objekte požiadavky bez priameho odovzdania tela objektu. Metóda HEAD sa často používa na testovanie hypertextových odkazov.
Metóda POST sa používa pre požiadavku, v ktorej adresovaný server prevezme údaje obsiahnuté v tele správy (objekte) požiadavky a odošle ich na spracovanie do aplikácie špecifikovanej ako požadovaný zdroj. POST je navrhnutý tak, aby bol bežnou metódou na implementáciu nasledujúcich funkcií:
Anotácia existujúcich zdrojov;
Uverejnenie správy na nástenke (BBS), diskusných skupinách, zoznamoch adries alebo podobnej skupine článkov;
Postúpenie bloku údajov, ako je výsledok vstupu vo formulári, do procesu spracovania;
Vykonávanie dopytov do databáz (DB);
Funkciu vykonávanú metódou POST v skutočnosti určuje aplikácia, na ktorú ukazuje identifikátor požadovaného zdroja. Spolu s metódou GET sa pri vytváraní CGI aplikácií používa aj metóda POST. Prehliadač môže pri odosielaní formulárov generovať požiadavky metódou POST. Na tento účel musí mať prvok FORM dokumentu HTML, ktorý obsahuje formulár, atribút METHOD s hodnotou POST.
Akcia vykonaná metódou POST môže vykonať akciu na serveri a nepreniesť žiadny obsah ako výsledok operácie. V tomto prípade, v závislosti od toho, či odpoveď obsahuje telo správy popisujúce výsledok alebo nie, stavový kód v odpovedi môže byť buď 200 (OK) alebo 204 (Žiadny obsah).
Ak bol prostriedok na serveri vytvorený, odpoveď obsahuje stavový kód 201 (Vytvorené) a obsahuje hlavičku odpovede Location.
Telo správy odovzdanej v požiadavke metódou PUT je uložené na serveri a identifikátor požadovaného zdroja bude identifikátorom uloženého dokumentu. Ak požadovaný identifikátor zdroja ukazuje na už existujúci zdroj, potom sa s objektom obsiahnutým v tele správy zaobchádza ako s upravenou verziou zdroja umiestneného na serveri. Ak je vytvorený nový zdroj, server o tom informuje užívateľského agenta prostredníctvom odpovede so stavovým kódom 201 (Vytvorené, Vytvorené).
Zásadným rozdielom medzi metódami POST a PUT je rozdielny význam požadovaného identifikátora zdroja. URI v požiadavke POST identifikuje zdroj, ktorý spracováva objekt zahrnutý v tele správy. Týmto zdrojom môže byť aplikácia, ktorá prijíma údaje. Na rozdiel od toho URI v požiadavke PUT identifikuje entitu zahrnutú v požiadavke ako telo správy, to znamená, že užívateľský agent priradí toto URI zahrnutému zdroju.
Metóda DELETE žiada server, aby vymazal zdroj, ktorý má požadovaný identifikátor. Požiadavku s touto metódou môže server odmietnuť, ak používateľ nemá povolenie na vymazanie požadovaného zdroja.
Metóda TRACE sa používa na vrátenie odovzdanej požiadavky na vrstve protokolu HTTP. Príjemca požiadavky (webový server) odošle prijatú správu späť klientovi ako telo objektu odpovede so stavovým kódom 200 (OK). Žiadosť TRACE nesmie obsahovať telo správy.
TRACE umožňuje klientovi vidieť, čo server prijíma na druhom konci a použiť tieto informácie na testovanie alebo diagnostiku.
Ak je požiadavka úspešná, potom odpoveď obsahuje celú správu žiadosti v tele správy odpovede a hlavička Content-Type má hodnotu „message/http“.
Kódy odpovedí
Po prijatí a interpretácii správy s požiadavkou server odpovie správou HTTP odpovede.
Prvý riadok odpovede je stavový riadok. Pozostáva z verzie protokolu, číselného kódu stavu, vysvetľujúcej frázy oddelenej medzerami a koncových znakov na konci riadku:
<Версия HTTP> <Код состояния> <Поясняющая фраза>
Verzia protokolu má rovnakú hodnotu ako v požiadavke.
Prvok Status-Code je celočíselný trojmiestny (trojmiestny) kód výsledku pochopenia a uspokojenia požiadavky. Reason-Phrase je krátky textový popis stavového kódu. Stavový kód je pre softvérové spracovanie a vysvetľujúca fráza je pre používateľov.
Prvá číslica stavového kódu určuje triedu odpovede. Posledné dve číslice nemajú v klasifikácii žiadnu špecifickú úlohu. Pre prvú číslicu je 5 hodnôt:
1xx: Informačné kódy - požiadavka prijatá, spracovanie pokračuje.
2xx: Kódy úspechu - Akcia bola úspešne prijatá, pochopená a spracovaná.
3xx: Presmerovacie kódy – Na dokončenie požiadavky je potrebné vykonať ďalšiu akciu.
4xx: Chybové kódy klienta – Požiadavka obsahuje chybu syntaxe alebo ju nemožno dokončiť.
5xx: Serverové chybové kódy – Server nedokáže splniť platnú požiadavku.
Reason-Fhras pre každý stavový kód sú uvedené v RFC 2068 a sú odporúčané, ale môžu byť nahradené ekvivalentnými bez ovplyvnenia protokolu. Napríklad v lokalizovaných ruských jazykových verziách serverov HTTP sú tieto frázy nahradené ruskými. Tabuľka 2 zobrazuje kódy odozvy servera HTTP.
tabuľka 2
Kódy odozvy servera HTTP
| Kód | Vysvetľujúca veta podľa RFC 2068 | Ekvivalentná vysvetľujúca fráza v ruštine |
| 1xx: Informačné kódy | ||
| ďalej | ďalej | |
| 2xx: Úspešné kódy | ||
| OK | OK | |
| Vytvorené | Vytvorené | |
| žiadny obsah | Žiadny obsah | |
| Obnoviť obsah | Obnoviť obsah | |
| Čiastočný obsah | Čiastočný obsah | |
| 3xx: Presmerovacie kódy | ||
| Dočasne presunuté | Dočasne premiestnené | |
| Neupravené | Neupravené | |
| 4xx: Kódy chýb klienta | ||
| Zlá požiadavka | Nefunkčná žiadosť | |
| Neoprávnené | Neoprávnené | |
| nenájdené | Nenájdené | |
| Metóda nie je povolená | Metóda nie je povolená | |
| Časový limit žiadosti | Požiadavka vypršala | |
| Konflikt | Konflikt | |
| Požadovaná dĺžka | Požadovaná dĺžka | |
| Požadovaná entita je priveľká | Objekt požiadavky je príliš veľký | |
| 5xx: Chybové kódy servera | ||
| Interná chyba servera | Interná chyba servera | |
| Nie je implementovaný | Nie je implementovaný | |
| Služba nie je k dispozícií | Služba je nedostupná | |
| Verzia HTTP nie je podporovaná | Nepodporovaná verzia HTTP |
Za stavovým riadkom nasledujú hlavičky (všeobecné, odpoveď a objekt) a voliteľne telo správy.
Jednou z najdôležitejších funkcií webového servera je poskytnúť prístup k časti lokálneho súborového systému. Na tento účel je v nastaveniach servera zadaný určitý adresár, ktorý je koreňovým adresárom tohto servera. Ak chcete publikovať dokument, to znamená, že ho chcete sprístupniť používateľom, ktorí tento server „navštívili“ (pripojili sa k nemu prostredníctvom protokolu HTTP), musíte tento dokument skopírovať do koreňového adresára webového servera alebo do jedného z jeho podadresárov. Pri pripájaní cez protokol HTTP sa na serveri vytvorí proces s používateľskými právami, ktorý spravidla v skutočnosti neexistuje, ale je špeciálne vytvorený na prezeranie zdrojov servera. Konfiguráciou práv a povolení daného používateľa môžete riadiť prístup k webovým zdrojom.
Zvážte najjednoduchší príklad HTTP požiadavky. Ak do adresného okna prehliadača zadáme adresu http://yandex.ru, prehliadač určí IP adresu servera yandex.ru a odošle mu nasledujúcu požiadavku HTTP na 80. port:
ZÍSKAJTE http://yandex.ru/ HTTP/1.0
Prijať: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/msword, application/vnd.ms-powerpoint, */*
Akceptačný jazyk: en
Súbor cookie: yandexuid=2464977781018373381
User-Agent: Mozilla/4.0 (kompatibilný; MSIE 5.5; Windows 98)
Hostiteľ: yandex.ru
Referent: narod.ru
Proxy pripojenie: Keep Alive
Žiadosť je odoslaná v nezašifrovanej textovej forme. Najdôležitejšia časť požiadavky sa nachádza v prvom riadku: Toto je typ požiadavky (GET), adresa URL požadovaného dokumentu (http://yandex.ru) a verzia protokolu HTTP (HTTP/1.0) . Parametre dopytu sú uvedené nižšie. Každý riadok zodpovedá jednému parametru. Riadok začína názvom parametra, za ktorým nasleduje dvojbodka a hodnota parametra.
Prijať – typ údajov, ktoré môže prehliadač prijať (v kódovaní MIME).
Accept-Language je preferovaný jazyk, v ktorom chce prehliadač akceptovať dáta. User-Agent – typ programu, ktorý odoslal požiadavku.
Host – DNS (alebo IP) názov hostiteľa, ktorému je požiadavka adresovaná.
Cookie - cookies (údaje, ktoré server uložil na lokálny disk klienta pri poslednej návšteve tohto hostiteľa).
Referer – hostiteľ, z ktorého stránky odosielame požiadavku. Ak sa teda nachádzame napríklad na stránke http://narod.ru a klikneme tam na odkaz http://yandex.ru, žiadosť sa odošle hostiteľovi yandex.ru a do poľa žiadosti sprostredkovateľa bude obsahovať názov hostiteľa narod.ru.
Sada parametrov dotazu nie je pevná. Okrem vyššie uvedeného môžu existovať ďalšie parametre.
Najzaujímavejšie parametre sú referer a cookie. Tieto parametre sa používajú hlavne na identifikáciu používateľa serverom.
Požiadavka GET môže obsahovať údaje prenesené z klienta na server. Prenášajú sa priamo cez URL pomocou protokolu CGI. Údaje sú oddelené od adresy URL znakom „?“ a sú spojené so znakom „&“:
GET
Tento typ prenosu údajov na server je pohodlný, má však obmedzenia týkajúce sa objemu. Príliš veľké dátové polia nie je možné preniesť cez URL. Na tieto účely existuje iný typ žiadosti: žiadosť POST. Požiadavka POST je veľmi podobná požiadavke GET, len s tým rozdielom, že údaje v požiadavke POST sa odovzdávajú oddelene od samotnej hlavičky požiadavky:
Telo požiadavky musí byť oddelené od hlavičky prázdnym riadkom. Ak server narazí na prázdny reťazec v požiadavke POST, potom všetko, čo nasleduje, sa považuje za telo požiadavky (prenesené údaje). Všimnite si nasledovné: formát údajov v tele požiadavky POST je ľubovoľný. Aj keď sa najčastejšie používa formát CGI, nie je potrebný. Okrem toho požiadavka POST nevyžaduje telo žiadosti a môže prenášať údaje aj cez adresu URL.
Okrem formátu CGI sa niekedy na prenos veľkého množstva informácií (napríklad súborov) používa tzv. viacdielny formát (formát prenášaných údajov je určený parametrom Content-Type):
Moderné prehliadače obsahujú nástroje pre vývojárov webu na získanie informácií o odosielaných žiadostiach o príspevky. Ak sa potrebujete pozrieť na hlavičky len niekoľkých požiadaviek, ich použitie bude jednoduchšie a rýchlejšie ako iné metódy.
Ak používate Firefox, môžete použiť jeho webovú konzolu. Zobrazuje hlavičky požiadaviek a obsah prenášaných cookies. Ak ho chcete spustiť, otvorte ponuku prehliadača, kliknite na položku „Vývoj webu“ a vyberte „Webová konzola“. Na zobrazenom paneli aktivujte tlačidlo "Sieť". Do poľa filtra zadajte názov metódy - príspevok. V závislosti od vašich cieľov kliknite na tlačidlo formulára, ktoré odošle požadovanú požiadavku, alebo obnovte stránku. Konzola zobrazí odoslanú požiadavku. Kliknutím naň myšou zobrazíte ďalšie podrobnosti.
Prehliadač Google Chrome má výkonné nástroje na ladenie. Ak ich chcete použiť, kliknite na ikonu kľúča a potom rozbaľte položku „Prispôsobiť a ovládať Google Chrome“. Vyberte "Nástroje" a spustite "Nástroje pre vývojárov". Na paneli s nástrojmi vyberte kartu Sieť a odošlite žiadosť. Nájdite požadovanú požiadavku v zozname a kliknutím na ňu zobrazte podrobnosti.
Prehliadač Opera má vstavané vývojárske nástroje pre Opera Dragonfly. Ak ich chcete spustiť, kliknite pravým tlačidlom myši na požadovanú stránku a z kontextovej ponuky vyberte položku „Skontrolovať prvok“. Prejdite na kartu „Sieť“ nástrojov pre vývojárov a odošlite požadovanú žiadosť. Nájdite ho v zozname a rozbaľte ho, aby ste preskúmali hlavičky a odpovede servera.
Internet Explorer 9 obsahuje balík s názvom „F12 Developer Tools“, ktorý poskytuje podrobné informácie o vykonaných požiadavkách. Spúšťajú sa stlačením tlačidla F12 alebo pomocou ponuky „Nástroje“ obsahujúcej rovnomennú položku. Ak chcete zobraziť žiadosť, prejdite na kartu „Sieť“. Nájdite daný dotaz v súhrne a dvojitým kliknutím rozbaľte podrobnosti.
Prehliadače Chrome a Internet Explorer 9 obsahujú vstavané nástroje, ktoré vám umožňujú podrobne preskúmať odoslanú žiadosť o príspevok. Ak chcete získať úplné podrobnosti, použite ich alebo Firefox s nainštalovaným doplnkom Firebug. Je veľmi praktický pri častom skúmaní dopytov, napríklad pri ladení webových stránok.
Ak chcete vidieť požiadavku odoslanú iným programom ako prehliadačom, použite Fiddler's HTTP debugger. Funguje ako proxy server a zachytáva požiadavky z akéhokoľvek programu a poskytuje veľmi podrobné informácie o ich hlavičkách a obsahu.
URL(Uniform Resource Locator)- jednotný lokátor (lokátor) zdroja. URL je štandardizovaný spôsob zaznamenávania adresy zdroja na internete.
URI(Uniform Resource Identifier)- jednotný (jednotný) identifikátor zdroja. URI je sekvencia znakov, ktorá identifikuje abstraktný alebo fyzický zdroj.
URI je všeobecnejší pojem ako adresa URL. Identifikátor URI nie vždy naznačuje, ako získať zdroj, na rozdiel od adresy URL, ale iba ho identifikuje. URL je URI, ktoré okrem identifikácie zdroja poskytuje aj informácie o umiestnení tohto zdroja. V skutočnosti každá adresa URL obsahuje dostatok informácií na presnú lokalizáciu stránky. Neskôr v tomto kurze sa pri používaní adries stránok budeme držať skratiek URL.
Štruktúra adresy stránky
Späť k URL http://school.it2moro.ru/ . Dá sa rozdeliť na 3 časti:
- http://
- škola
- it2moro
Prvá časť adresy (http://) definuje protokol pre interakciu medzi prehliadačom a serverom. V našom prípade ide o protokol HTTP, o ktorom bude reč neskôr.
Druhá časť panel s adresou sa nazýva SUBdoména a tretí - doména. Slúžia na identifikáciu konkrétnej stránky pomocou služby DNS. DNS (Domain Name System, domain name system) je počítačovo distribuovaný systém na získavanie informácií o doménach. Najčastejšie sa používa na získanie adresy IP z názvu hostiteľa (počítača alebo zariadenia). V sieti je veľké množstvo serverov DNS, ktoré môžu podľa názvu domény zdroja „navrhnúť“ jeho skutočné umiestnenie určené IP adresou.
zdrojový kód stránky HTML
Teraz sa pozrime na to, čo prehliadač dostane ako odpoveď na vygenerovanú požiadavku HTTP. Stránka môže pozostávať z textu, obrázkov, hypertextových odkazov, vstupných polí, tlačidiel a iných prvkov. Informácie o tom všetkom sa preniesli z webového servera do prehliadača, ktorý vygeneroval výsledný vzhľad stránky. Prenášané dáta sú popísané pomocou HTML protokolu.
HTML(Hypertextový značkovací jazyk, hypertextový značkovací jazyk) je štandardný značkovací jazyk pre dokumenty na internete. Jazyk HTML je interpretovaný prehliadačom a zobrazený ako dokument vo forme čitateľnej pre človeka.
Dá sa povedať, že prehliadače vykonávajú dve hlavné funkcie - to je interakcia s webovými servermi HTTP požiadavky , ako aj konverziu HTML kódu prijatého zo servera na vizuálnu reprezentáciu.
A sprostredkovateľ služby Google Play.
Platforma Android je veľmi roztrieštená, pretože Google núti vývojárov zariadení, aby sami riešili portovanie OS, spätnú kompatibilitu a podporu viacerých zariadení. V dôsledku toho sa často používajú zdĺhavé príkazy if-else, aby sa zabezpečilo, že najlepšia metóda sa použije v príslušnom kontexte.
S priamymi odkazmi v systéme Android je situácia úplne rovnaká. Postupom času sa objavilo veľké množstvo technických požiadaviek, ktoré je potrebné splniť v závislosti od okolností a používateľského kontextu. Riešenie Branch spája všetky tieto implementácie dohromady, je to referenčná platforma, ktorá funguje vo všetkých okrajových prípadoch. Pobočkové prepojenia vám umožňujú obísť zložitosť a použiť štandardné riešenie, takže sa nemusíte obávať kompatibility. Dôrazne odporúčame používať naše riešenia a nie pokúšať sa znovu vytvoriť podobné funkcie od začiatku, pretože ich poskytujeme zadarmo.
Táto séria príspevkov popisuje všetky rôzne mechanizmy priameho prepojenia, ktoré používame, a vysvetľuje ich implementáciu.
Môžete začať pracovať na stránke start.branch.io alebo kliknite na tlačidlo nižšie.
Schéma URI systému Android a filter zámerov
Android 1.0 zaviedol mechanizmus priameho prepojenia založený na schéme URI. Umožňuje vývojárovi zaregistrovať svoju aplikáciu pomocou identifikátora URI (Uniform Resource Identifier) v operačnom systéme pre konkrétne zariadenie po inštalácii aplikácie. Identifikátor URI môže byť ľubovoľný textový reťazec bez špeciálnych znakov, ako napríklad HTTP, pinterest, fb alebo myapp. Po registrácii, pridaním „://“ na koniec URI (napríklad pinterest://) a kliknutím na odkaz otvoríte aplikáciu Pinterest. Ak aplikácia Pinterest nie je nainštalovaná, zobrazí sa chyba „Stránka sa nenašla“.
Požiadavky na používanie schém URI v systéme Android
- Zaregistrujte akciu na odpoveď na URI pomocou filtra zámerov v manifeste.
- Ak chcete aplikáciu používať, musíte ju nainštalovať. Ak aplikácia nie je nainštalovaná, zobrazí sa chybové hlásenie.
Prispôsobenie schémy URI v systéme Android
Prispôsobenie vašej aplikácie pre schému URI je veľmi jednoduché. Najprv musíte vo svojej aplikácii vybrať akciu, ktorú má vaša aplikácia vykonať, keď je zahrnutá schéma URI, a zaregistrovať pre ňu filter zámerov. Pridajte nasledujúci kód do značky
Môžete zmeniť schému your_uri_scheme na požadovanú schému URI. Schéma by mala byť v ideálnom prípade jedinečná. Ak sa zhoduje so schémou URI inej aplikácie, používateľovi sa po kliknutí na odkaz zobrazí výber systému Android. Toto okno sa vám často zobrazí, ak máte na svojom zariadení nainštalovaných viacero webových prehliadačov, pretože všetky sú registrované pre HTTP URI.
Spracovanie priamych odkazov v aplikácii pre Android
Potom budete musieť analyzovať reťazec, aby ste si prečítali hodnoty pripojené schémou URI.
Používanie schém URI v systéme Android v praxi
Spôsob spracovania priamych spojení s URI má značné obmedzenia. Neodporúčame používať bez výrazných úprav, pretože ak zariadenie nemá aplikáciu, jednoducho zobrazí chybové hlásenie. Ak chcete efektívne používať schému URI, budete musieť pridať ďalšie nástroje na spracovanie okrajových prípadov, napríklad keď aplikácia nie je nainštalovaná.
Preto, aby ste poskytli primeranú používateľskú skúsenosť, keď aplikácia nie je nainštalovaná, musíte schému URI zabaliť do JavaScriptu na strane klienta, ktorý možno spustiť v prehliadači. Tento kód JS bude umiestnený na váš server a vy pošlete odkaz používateľom. Nižšie je uvedený príklad.
Kód sa pokúsi otvoriť aplikáciu nastavením zdroja iFrame na schému URI a potom bezpečne prejsť späť do obchodu s aplikáciami Google Play, ak sa aplikácia nepodarí načítať.
Záver
Zostaňte naladení na ďalšie príspevky na priamych odkazoch v systéme Android.
Priame odkazy v systéme Android sú veľmi zložité, prípady okrajov sa vyskytujú na každom kroku. Možno si myslíte, že všetko funguje skvele, až kým sa zrazu nejaký používateľ nesťažuje, že v systéme Android 4.4.4 nemôže otvárať odkazy z Facebooku. Preto sa oplatí používať programy ako Branch: na všetky tieto zložitosti môžete zabudnúť ako na zlý sen a zvyknúť si na to, že odkazy vždy fungujú.
Súvisiace príspevky
Priame odkazy, univerzálne odkazy, schémy URI/URL a odkazy na aplikácie v posledných rokoch zmenili spôsob, akým mobilné aplikácie súvisia s obsahom. Mnoho vývojárov aplikácií nemá jasné…
Každý deň v pobočke pracujeme na zlepšovaní skúseností s používaním odkazov na mobilných platformách. Naše odkazy poskytujú prístup k takým veciam, ako sú: inteligentné presmerovania, zobrazenie pre používateľa…
1.4. Uniform Resource Identifier (URI)
Aby ste plne porozumeli tomu, ako dokumenty HTML interagujú, pohybujú sa medzi stránkami a odkiaľ počítač používateľa prijíma údaje pri práci so sieťou, musíte zvážiť, ako a k čomu sa pristupuje pomocou globálnej siete.
Mnoho typov zdrojov hostovaných na internete, či už ide o HTML dokumenty, obrázky alebo archívne súbory, sú najčastejšie súbory na pevnom disku počítača (servera) pripojeného k sieti. Každý zdroj je spojený s hodnotou, ktorá môže jednoznačne určiť jeho umiestnenie – univerzálny identifikátor zdroja alebo URI (Universal Resource Identifier). Identifikátory URI sú široko používané, keď používateľ pristupuje k zdroju sám (keď napríklad používateľ sám zadáva URI do panela s adresou prehliadača), ako aj pri navigácii medzi webovými stránkami. Identifikátory URI sa používajú aj v dokumente HTML, aby prehliadaču povedali, kde má hľadať zdroje (napríklad obrázky) použité v samotnom dokumente.
Poznámka
V literatúre sa často používa aj URL notácie. Je potrebné poznamenať, že URI je všeobecnejší pojem, ktorý zahŕňa adresu URL: každá adresa URL je jednotný identifikátor zdroja a riadi sa rovnakými pravidlami ako URI.
Identifikátor URI zdroja pozostáva z troch častí: názvu mechanizmu na prístup k prostriedku, názvu domény počítača a cesty k súboru zdroja. Aby ste to objasnili, zvážte príklad:
Tu môžete vidieť, že HTTP (Hyper Text Transfer Protocol) sa používa na prístup k zdroju, ktorým je v tomto prípade HTML dokument. Zdroj je uložený v počítači s názvom domény somesite.com v súbore ex_1.html umiestnenom v priečinku /info/examples.
Identifikátory URI môžu tiež odkazovať na časti dokumentov HTML, napríklad:
Pomocou tohto URI môžete pristupovať k časti dokumentu HTML s názvom description (ako vytvoriť názvy pre fragmenty dokumentov HTML bude popísané v kapitole 5).
Identifikátory URI vám tiež umožňujú odkazovať na zdroje v rámci toho istého počítača. Toto určuje relatívnu cestu zdroja. Ak chcete napríklad odkazovať na súbor /info/files/file1.jpg z dokumentu HTML umiestneného v priečinku /info/examples, stačí zadať URI /files/file1.jpg. V dokumentoch HTML takéto odkazy označujú cesty obrázkov a iných objektov používaných v dokumentoch, ale nie sú v nich priamo uložené.
Vo všeobecnosti sa URI považujú za nerozlišujúce veľké a malé písmená. Aby ste si však boli úplne istí, že URI sa interpretuje správne, venujte pozornosť aj prípadom znakov v URI hypertextových odkazov, obrázkov atď. počítač, všetky hypertextové odkazy fungujú, ale stránka na serveri UNIX odmieta fungovať (v systéme UNIX sa v názvoch súborov rozlišujú malé a veľké písmená).

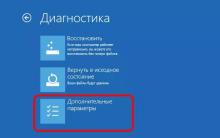



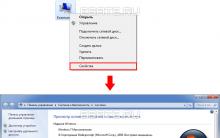




Po nainštalovaní aktualizácií sa systém Windows nespustí
Neobvyklé atrakcie v Mijas
Prístavy Kerkyra (Korfu) Pláž a more sú na nezaplatenie
Divoká zoologická záhrada v Changlong
Lyžiarske stredisko Koli vo Fínsku: národný park, zjazdovky, ubytovanie národný park Koli fínsko ako sa dostať