Введение в нечеткую логику
Нечеткая логика – это логическая или управляющая система n-значной логической системы, которая использует степени состояния («степени правды») входов и формирует выходы, зависящие от состояний входов и скорости изменения этих состояний. Это не обычная «истинная или ложная» (1 или 0), булева (двоичная) логика, на которой основаны современные компьютеры. Она в основном обеспечивает основы для приблизительного рассуждения с использованием неточных решений и позволяет использовать лингвистические переменные.
Нечеткая логика была разработана в 1965 году профессором Лотфи Заде в Калифорнийском университете в Беркли. Первым приложением было выполнение обработки компьютерных данных на основе естественных значений.
Если говорить проще, состояниями нечеткой логики могут быть не только 1 или 0, но и значения между ними, то есть 0.15, 0.8 и т.д. Например, в двоичной логике, мы можем сказать, что мы имеем стакан горячей воды (то есть 1 или высокий логический уровень) или стакан холодной воды, то есть (0 или низкий логический уровень), но в нечеткой логике, мы можем сказать, что мы имеем стакан теплой воды (ни горячий, ни холодный, то есть где-то между этими двумя крайними состояниями). Четкая логика: да или нет (1, 0). Нечеткая логика: конечно, да; возможно, нет; не могу сказать; возможно да и т.д.
Базовая архитектура нечеткой логической системы
Система нечеткой логики состоит из следующих модулей:

Фазифаер (Fuzzifier или оператор размытия). Он принимает измеренные переменные в качестве входных данных и преобразует числовые значения в лингвистические переменные. Он преобразует физические значения, а также сигналы ошибок в нормализованное нечеткое подмножество, которое состоит из интервала для диапазона входных значений и функций принадлежности, которые описывают вероятность состояния входных переменных. Входной сигнал в основном разделен на пять состояний, таких как: большой положительный, средний положительный, малый, средний отрицательный и большой отрицательный.
Контроллер. Он состоит из базы знаний и механизма вывода. База знаний хранит функции принадлежности и нечеткие правила, полученные путем знания работы системы в среде. Механизм вывода выполняет обработку полученных функций принадлежности и нечетких правил. Другими словами, механизм вывода формирует выходные данные на основе лингвистической информации.
Дефазифаер (Defuzzifier или оператор восстановления чёткости). Он выполняет обратный процесс фазифаера. Другими словами, он преобразует нечеткие значения в нормальные числовые или физические сигналы и отправляет их в физическую систему для управления работой системы.
Принцип работы системы нечеткой логики
Нечеткая операция предполагает использование нечетких множеств и функций принадлежности. Каждое нечеткое множество представляет собой представление лингвистической переменной, которая определяет возможное состояние вывода. Функция принадлежности является функцией общего значения в нечетком множестве, так что и общее значение, и нечеткое множество принадлежат универсальному множеству.
Степени принадлежности в этом общем значении в нечетком множестве определяют выход, основанный на принципе IF-THEN. Принадлежность назначается на основе предположения о выходе с помощью входов и скорости изменения входных данных. Функция принадлежности в основном представляет собой графическое представление нечеткого множества.
Рассмотрим такое значение «х», что x ∈ X для всего интервала и нечеткого множества A, которое является подмножеством X. Функция принадлежности «x» в подмножестве A задается как: fA (x), Обратите внимание, что «x» обозначает значение принадлежности. Ниже приводится графическое представление нечетких множеств.

В то время как ось x обозначает универсальный набор, ось y обозначает степени принадлежности. Эти функции принадлежности могут быть треугольными, трапециевидными, одноточечными или гауссовыми по форме.
Практический пример системы на основе нечеткой логики
Давайте разработаем простую систему нечеткого управления для управления работой стиральной машины, так чтобы нечеткая система контролировала процесс стирки, водозабор, время стирки и скорость отжима. Входными параметрами здесь являются объем одежды, степень загрязнения и тип грязи. В то время как объем одежды определял бы водозабор, степень загрязнения в свою очередь определялась бы прозрачностью воды, а тип грязи определялся временем, когда цвет воды остается неизменным.
Первым шагом будет определение лингвистических переменных и терминов. Для входных данных лингвистические переменные приведены ниже:
- Тип грязи: {Greasy, Medium, Not Greasy} (жирное, среднее, не жирное)
- Качество грязи: {Large, Medium, Small} (высокое, среднее, незначительное)
Для вывода лингвистические переменные приведены ниже:
- Время стирки: {Short, Very Short, Long, Medium, Very Long} (короткий, очень короткий, длинный, средний, очень длинный).
Второй шаг включает в себя построение функций принадлежности. Ниже приведены графики, определяющие функции принадлежности для двух входов. Функции принадлежности для качества грязи:

Функции принадлежности для типа грязи:

Третий шаг включает разработку набора правил для базы знаний. Ниже приведен набор правил с использованием логики IF-THEN (если-тогда):
IF качество грязи Small И Тип грязи Greasy, THEN Время стирки Long.
IF качество грязи Medium И Тип грязи Greasy, THEN Время стирки Long.
IF качество грязи Large и тип грязи Greasy, THEN Время стирки Very Long.
IF качество грязи Small И Тип грязи Medium, THEN Время стирки Medium.
IF качество грязи Medium И Тип грязи Medium, THEN Время стирки Medium.
IF качество грязи Large и тип грязи Medium, THEN Время стирки Medium.
IF качество грязи Small и тип грязи Non-Greasy, THEN Время стирки Very Short.
IF качество грязи Medium И Тип грязи Non-Greasy, THEN Время стирки Medium.
IF качество грязи Large и тип грязи Greasy, THEN Время стирки Very Short.
Фазифаер, который первоначально преобразовал входные данные датчиков в эти лингвистические переменные, теперь применяет вышеуказанные правила для выполнения операций нечеткого набора (например, MIN и MAX) для определения выходных нечетких функций. На основе выходных нечетких множеств разработана функция принадлежности. Последним шагом является этап дефазификации, в котором дефазифаер использует выходные функции принадлежности для определения времени стирки.
Области применения нечеткой логики
Системы нечеткой логики могут использоваться в автомобильных системах, таких как автоматические коробки передач. Приложения в области бытовых приборов включают в себя микроволновые печи, кондиционеры, стиральные машины, телевизоры, холодильники, пылесосы и т. д.
Преимущества нечеткой логики
- Системы нечеткой логики являются гибкими и позволяют изменять правила.
- Такие системы также принимают даже неточную, искаженную и ошибочную информацию.
- Системы нечеткой логики могут быть легко спроектированы.
- Поскольку эти системы связаны с человеческими рассуждениями и принятием решений, они полезны при формировании решений в сложных ситуациях в различных типах приложений.
сайт
Теги:
Благодарим Вас за интерес к информационному проекту сайт.
Если Вы хотите, чтобы интересные и полезные материалы выходили чаще, и было меньше рекламы,
Вы можее поддержать наш проект, пожертвовав любую сумму на его развитие.
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
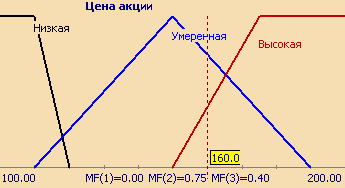
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.

Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.
Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).

Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.

Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.
Лекция № 1
Нечеткая логика
- Понятие нечеткой логики.
- Операции с нечеткими множествами.
- Лингвистическая переменная.
- Нечеткое число.
- 1. Понятие нечеткой логики
Нечеткая логика является многозначной логикой, что позволяет определить промежуточные значения для таких общепринятых оценок, как да|нет, истинно|ложно, черное|белое и т.п. Выражения подобные таким, как слегка тепло или довольно холодно возможно формулировать математически и обрабатывать на компьютерах. Нечеткая логика появилась в 1965 в работах Лотфи А. Задэ (Lotfi A. Zadeh ), профессора технических наук Калифорнийского университета в Беркли.
Математическая теория нечетких множеств, предложенная Л.Заде более четверти века назад, позволяет описывать нечеткие понятия и знания, оперировать этими знаниями и делать нечеткие выводы. Основанные на этой теории методы построения компьютерных нечетких систем существенно расширяют области применения компьютеров. В последнее время нечеткое управление является одной из самых активных и результативных областей исследований применения теории нечетких множеств. Нечеткое управление оказывается особенно полезным, когда технологические процессы являются слишком сложными для анализа с помощью общепринятых количественных методов, или когда доступные источники информации интерпретируются качественно, неточно или неопределенно. Экспериментально показано, что нечеткое управление дает лучшие результаты, по сравнению с получаемыми при общепринятых алгоритмах управления. Нечеткие методы помогают управлять домной и прокатным станом, автомобилем и поездом, распознавать речь и изображения, проектировать роботов, обладающих осязанием и зрением. Нечеткая логика, на которой основано нечеткое управление, ближе по духу к человеческому мышлению и естественным языкам, чем традиционные логические системы.
Нечеткая логика - раздел математики, являющийся новой мощной технологией.
Нечеткая логика возникла как наиболее удобный способ построения систем управления метрополитенами и сложными технологическими процессами, а также нашла применение в бытовой электронике, диагностических и других экспертных системах. Несмотря на то, что математический аппарат нечеткой логики впервые был разработан в США, активное развитие данного метода началось в Японии, и новая волна вновь достигла США и Европы. В Японии до сих пор продолжается бум нечеткой логики и экспоненциально увеличивается количество патентов, большая часть которых относится к простым приложениям нечеткого управления .
Термин fuzzy (англ. нечеткий, размытый - произносится "фаззи ") стал ключевым словом на рынке. Статьи по электронике без нечетких компонент постепенно исчезали и пропали совсем, как будто кто-то закрыл кран. Это показывает насколько стала популярной нечеткая логика; появилась даже туалетная бумага с напечатанными на ней словами "Fuzzy Logic".
В Японии исследования в области нечеткой логики получили широкую финансовую поддержку. В Европе и США усилия были направлены на то, чтобы сократить огромный отрыв от японцев. Так, например, агентство космических исследований NASA стало использовать нечеткую логику в маневрах стыковки.
Таким образом, нечеткая логика, в основном, обеспечивает эффективные средства отображения неопределенностей и неточностей реального мира. Наличие математических средств отражения нечеткости исходной информации позволяет построить модель, адекватную реальности.
2. Операции с нечеткими множествами
Определение и основные характеристики
нечетких множеств
Нечеткое множество (fuzzyset) представляет собой совокупность элементов произвольной природы, относительно которых нельзя точно утверждать - обладают ли эти элементы некоторым характеристическим свойством, которое используется для задания нечеткого множества.
Пусть E - универсальное множество, x - элемент E , а R - некоторое свойство. Обычное (четкое) подмножество A универсального множества E , элементы которого удовлетворяют свойству R , определяется как множество упорядоченных пар A = {µ A (х )/х } , где
µ A (х ) - характеристическая функция , принимающая значение 1 , если x удовлетворяет свойству R, и 0 - в противном случае.
Нечеткое подмножество отличается от обычного тем, что для элементов x из E нет однозначного ответа "да-нет" относительно свойства R . В связи с этим, нечеткое подмножество A универсального множества E определяется как множество упорядоченных пар A = {µ A (х )/х } , где
µ A (х ) - характеристическая функция принадлежности (или просто функция принадлежности), принимающая значения в некотором вполне упорядоченном множестве M (например, M = ). Функция принадлежности указывает степень (или уровень) принадлежности элемента x подмножеству A . Множество M называют множеством принадлежностей . Если M = {0,1} , то нечеткое подмножество A может рассматриваться как обычное или четкое множество.
Примеры записи нечеткого множества
Пусть E = {x 1 , x 2 , x 3 , x 4 , x 5 } , M = ; A - нечеткое множество, для которого
µ A (x 1)=0,3;
µ A (x 2)=0;
µ A (x 3)=1;
µ A (x 4)=0,5;
µ A (x 5)=0,9.
Тогда A можно представить в виде:
A = {0,3/x 1 ; 0/x 2 ; 1/x 3 ; 0,5/x 4 ; 0,9/x 5 } или
A = 0,3/x 1 + 0/x 2 + 1/x 3 + 0,5/x 4 + 0,9/x 5 , или
|
|
Замечание. Здесь знак "+ " не является обозначением операции сложения, а имеет смысл объединения.
Основные характеристики нечетких множеств
Пусть M = и A - нечеткое множество с элементами из универсального множества E и множеством принадлежностей M .
Величина µ A (x ) называется высотой нечеткого множества A . Нечеткое множество A нормально , если его высота равна 1 , т.е. верхняя граница его функции принадлежности равна 1 (µ A (x )=1 ). При µ A (x ) <1 нечеткое множество называется субнормальным .
Нечеткое множество пусто , если µ A (x )=0. Непустое субнормальное множество можно нормализовать по формуле A (x ) = .
Нечеткое множество унимодально , если µ A (x )=1 только на одном x из E.
Носителем нечеткого множества A является обычное подмножество со свойством µ A (x )>0 , т.е. носитель A = {x/µ A (x )>0} , x E .
Элементы x E , для которых µ A (x )=0,5 называются точками перехода множества A .
Примеры нечетких множеств
1) Пусть E = {0,1,2,..,10}, M =. Нечеткое множество "несколько" можно определить следующим образом: "несколько " = 0,5/3+0,8/4+1/5+1/6+0,8/7+0,5/8; его характеристики: высота = 1 , носитель = {3,4,5,6,7,8}, точки перехода - {3,8}.
2) Пусть E = { 0,1,2,3,...,n ,...}. Нечеткое множество "малый " можно определить:
"малый" = .
3) Пусть E = {1,2,3,...,100} и соответствует понятию "возраст ", тогда нечеткое множество "молодой ", может быть определено с помощью
4) Нечеткое множество "молодой " на универсальном множестве E" ={Иванов, Петров, Сидоров ,...} задается с помощью функции принадлежности µ "молодой " (x ) на E = {1,2,3,..100} (возраст), называемой по отношению к E" функцией совместимости, при этом:
µ "молодой" (Сидоров )= µ "молодой" (x ), где x - возраст Сидорова.
5) Пусть E = {Запорожец, Жигули, Мерседес ,....} - множество марок автомобилей, а E" = , формируя векторную функцию принадлежности { µ A (x 1 ), µ A (x 2 ),... µ A (x 9 )}.
При прямых методах используются также групповые прямые методы, когда, например, группе экспертов предъявляют конкретное лицо и каждый должен дать один из двух ответов: "этот человек лысый " или "этот человек не лысый ", тогда количество утвердительных ответов, деленное на общее число экспертов, дает значение µ "лысый" (данного лица). (В этом примере можно действовать через функцию совместимости, но тогда придется считать число волосинок на голове у каждого из предъявленных эксперту лиц).
Косвенные методы определения значений функции принадлежности используются в случаях, когда нет элементарных измеримых свойств, через которые определяется интересующее нас нечеткое множество. Как правило, это методы попарных сравнений. Если бы значения функций принадлежности были нам известны, например, µ A (x i ) = w i , i =1,2,...,n , то попарные сравнения можно представить матрицей отношений A = {a ij }, где a ij =w i /w j (операция деления).
На практике эксперт сам формирует матрицу A , при этом предполагается, что диагональные элементы равны 1, а для элементов симметричных относительно диагонали a ij = 1/a ij , т.е. если один элемент оценивается в n раз сильнее чем другой, то этот последний должен быть в 1/n раз сильнее, чем первый. В общем случае задача сводится к поиску вектора w , удовлетворяющего уравнению вида А w = λ max w , где λ max - наибольшее собственное значение матрицы A . Поскольку матрица А положительна по построению, решение данной задачи существует и является положительным.
Пример. Рассмотрим нечеткое множество A , соответствующее понятию «расход теплоносителя небольшой». Объект x - расход теплоносителя, x0; x max - множество физически возможных значений скорости изменения температуры. Эксперту предъявляются различные значения расхода теплоносителя x и задается вопрос: с какой степенью уверенности 0 ≤ μ A (x) ≤ 1 эксперт считает, что данный расход теплоносителя x небольшой. При μ A (x) = 0 - эксперт абсолютно уверен, что расход теплоносителя x небольшой. При μ A (x) = 1 - эксперт абсолютно уверен, что расход теплоносителя x нельзя классифицировать как небольшой.
Операции над нечеткими множествами
Включение .
Пусть A и B - нечеткие множества на универсальном множестве E.
Говорят, что A содержится в B , если .
Обозначение : .
Иногда используют термин "доминирование ", т.е. в случае когда A Ì B , говорят, что B доминирует A .
Равенство .
A и B равны, если " x Î E m A (x ) = m B (x ).
Обозначение : A = B .
Дополнение.
Пусть М = , A и B - нечеткие множества, заданные на E . A и B дополняют друг друга, если
" x Î E m A (x ) = 1 - m B (x ).
Обозначение : или.
Очевидно, что. (Дополнение определено для M = , но очевидно, что его можно определить для любого упорядоченного M ).
Пересечение .
A ÇB - наибольшее нечеткое подмножество, содержащееся одновременно в A и B .
m A Ç B(x ) = min(m A (x ), m B (x )).
Объединение.
А È В - наименьшее нечеткое подмножество, включающее как А , так и В , с функцией принадлежности:
m A È B(x ) = max(m A (x ), m B (x )).
Разность.
А - B = А Ç с функцией принадлежности:
m A-B (x ) = m A Ç (x ) = min(m A (x ), 1 - m B (x )).
Дизъюнктивная сумма.
А Å B = (А - B) È (B - А) = (А Ç ) È (Ç B) с функцией принадлежности:
m A-B (x ) = max{; }
Примеры.
A = 0,4/ x 1 + 0,2/ x 2 +0/ x 3 +1/ x 4 ;
B = 0,7/ x 1 +0,9/ x 2 +0,1/ x 3 +1/ x 4 ;
C = 0,1/ x 1 +1/ x 2 +0,2/ x 3 +0,9/ x 4 .
A Ì B , т.е. A содержится в B или B доминирует A , С несравнимо ни с A , ни с B , т.е. пары {A, С } и {A, С } - пары недоминируемых нечетких множеств.
0,6/ x 1 + 0,8/x 2 + 1/x 3 + 0/x 4 ;
0,3/x 1 + 0,1/x 2 + 0,9/x 3 + 0/x 4 .
A Ç B = 0,4/x 1 + 0,2/x 2 + 0/x 3 + 1/x 4 .
А È В = 0,7/x 1 + 0,9/x 2 + 0,1/x 3 + 1/x 4 .
А - В = А Ç = 0,3/x 1 + 0,1/x 2 + 0/x 3 + 0/x 4 ;
В - А =Ç В = 0,6/x 1 + 0,8/x 2 + 0,1/x 3 + 0/x 4 .
А Å В = 0,6/x 1 + 0,8/x 2 + 0,1/x 3 + 0/x 4 .
Наглядное представление операций над нечеткими множествами
Для нечетких множеств можно строить визуальное представление. Рассмотрим прямоугольную систему координат, на оси ординат которой откладываются значения m A (x ) , на оси абсцисс в произвольном порядке расположены элементы E (мы уже использовали такое представление в примерах нечетких множеств). Если E по своей природе упорядочено, то этот порядок желательно сохранить в расположении элементов на оси абсцисс. Такое представление делает наглядными простые операции над нечеткими множествами.
На верхней части рисунка заштрихованная часть соответствует нечеткому множеству A и, если говорить точно, изображает область значений А и всех нечетких множеств, содержащихся в A . На нижней - даны, A Ç , A È .
Свойства операций È и Ç.
Пусть А, В, С - нечеткие множества, тогда выполняются следующие свойства:
Коммутативность;
Ассоциативность;
Идемпотентность;
Дистрибутивность;
A ÈÆ = A , где Æ - пустое множество , т.е. mÆ (x) = 0 " >x Î E ;
A Ç E = A , где E - универсальное множество;
Теоремы де Моргана.
В отличие от четких множеств, для нечетких множеств в общем случае:
Замечание. Введенные выше операции над нечеткими множествами основаны на использовании операций max и min . В теории нечетких множеств разрабатываются вопросы построения обобщенных, параметризованных операторов пересечения, объединения и дополнения, позволяющих учесть разнообразные смысловые оттенки соответствующих им связок "и ", "или ", "не ".
Расстояние между нечеткими множествами
Пусть A и B - нечеткие подмножества универсального множества E . Введем понятие расстояния r(A , B ) между нечеткими множествами. При введении расстояния обычно предъявляются следующие требования:
r(A, B ) ³ 0 - неотрицательность;
r(A, B ) = r(B, A ) - симметричность;
r(A, B ) < r(A, C ) + r(C, B ).
К этим трем требованиям можно добавить четвертое: r(A, A ) = 0.
Евклидово или квадратичное расстояние:
e(A, B ) = , e(A, B )Î.
Перейдем к индексам нечеткости или показателям размытости нечетких множеств.
Если объект х обладает свойством R (порождающим нечеткое множество A ) лишь в частной мере, т.е.
0< m A (x ) <1, то внутренняя неопределенность, двусмысленность объекта х в отношении R проявляется в том, что он, хотя и в разной степени, принадлежит сразу двум противоположным классам: классу объектов, "обладающих свойством R ", и классу объектов, "не обладающих свойством R ". Эта двусмысленность максимальна, когда степени принадлежности объекта обеим классам равны, т.е. m A (x ) = (x ) = 0,5, и минимальна, когда объект принадлежит только одному классу, т.е. либо m A (x ) = 1 и (x ) = 0, либо m A (x ) = 0 и (x ) = 1.
3. Лингвистическая переменная
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются ТЕРМАМИ. Так, значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Конечно, для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 метров. Как же нам поступить? Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ. В нашем случае расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами. При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины. В настоящее время сложилось мнение, что для большинства приложений достаточно 3-7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
Понятие нечеткой и лингвистической переменных используется при описании объектов и явлений с помощью нечетких множеств.
Нечеткая переменная характеризуется тройкой <α, X, A>, где
α - наименование переменной,
X - универсальное множество (область определения α),
A - нечеткое множество на X, описывающее ограничения (т.е. μ A (x )) на значения нечеткой переменной α.
Лингвистической переменной называется набор <β ,T,X,G,M>, где
β - наименование лингвистической переменной;
Т - множество ее значений (терм-множество), представляющих собой наименования нечетких переменных, областью определения каждой из которых является множество X.
Множество T называется базовым терм-множеством лингвистической переменной;
G - синтаксическая процедура, позволяющая оперировать элементами терм-множества T, в частности, генерировать новые термы (значения). Множество TÈ G(T), где G(T) - множество сгенерированных термов, называется расширенным терм-множеством лингвистической переменной;
М - семантическая процедура, позволяющая превратить каждое новое значение лингвистической переменной, образуемое процедурой G, в нечеткую переменную, т.е. сформировать соответствующее нечеткое множество.
Замечание. Чтобы избежать большого количества символов
символ β используют как для названия самой переменной, так и для всех ее значений;
пользуются одним и тем же символом для обозначения нечеткого множества и его названия, например терм "молодой ", являющийся значением лингвистической переменной β = "возраст ", одновременно есть и нечеткое множество М ("молодой ").
Присвоение нескольких значений символам предполагает, что контекст позволяет разрешить возможные неопределенности.
Пример: Пусть эксперт определяет толщину выпускаемого изделия с помощью понятий "малая толщина ", "средняя толщина " и "большая толщина ", при этом минимальная толщина равна 10 мм, а максимальная - 80 мм.
Формализация такого описания может быть проведена с помощью следующей лингвистической переменной < β, T, X, G, M>, где
β - толщина изделия;
T - {"малая толщина ", "средняя толщина ", "большая толщина "};
G - процедура образования новых термов с помощью связок "и ", "или " и модификаторов типа "очень ", "не ", "слегка " и др. Например: "малая или средняя толщина ", "очень малая толщина " и др.;
М - процедура задания на X = нечетких подмножеств А 1 ="малая толщина ", А 2 = "средняя толщина ", А 3 ="большая толщина ", а также нечетких множеств для термов из G(T) в соответствии с правилами трансляции нечетких связок и модификаторов "и ", "или ", "не ", "очень ", "слегка " и др. операции над нечеткими множествами вида: А Ç В, АÈ В, CON А = А 2 , DIL А = А 0,5 и др.
Замечание. Наряду с рассмотренными выше базовыми значениями лингвистической переменной "толщина " (Т={"малая толщина ", "средняя толщина ", "большая толщина "}) возможны значения, зависящие от области определения Х. В данном случае значения лингвистической переменной "толщина изделия" могут быть определены как "около 20 мм ", "около 50 мм ", "около 70 мм ", т.е. в виде нечетких чисел .
Продолжение примера:
Функции принадлежности нечетких множеств:
"малая толщина" = А 1 , "средняя толщина "= А 2 , " большая толщина "= А 3 .
Функция принадлежности:
нечеткое множество "малая или средняя толщина " = А 1 ?А 1 .
4. Нечеткое число
Нечеткие числа - нечеткие переменные, определенные на числовой оси, т.е. нечеткое число определяется как нечеткое множество А на множестве действительных чисел R с функцией принадлежности m A (x )Î, где x - действительное число, т.е. x Î R.
Нечеткое число А нормально , если μ A (x )=1, выпуклое , если для любых x≤y≤z выполняется μ A (x )≥ μ A (y )∩ μ A (z ).
Подмножество S A ÌR называется носителем нечеткого числа А, если
S = {x /μ A (x )>0}.
Нечеткое число А унимодально , если условие m A (x ) = 1 справедливо только для одной точки действительной оси.
Выпуклое нечеткое число А называется нечетким нулем , если
m A (0) = (m A (x )).
Нечеткое число А положительно , если "x Î S A , x >0 и отрицательно , если "x Î S A , x <0.
Операции над нечеткими числами
Расширенные бинарные арифметические операции (сложение, умножение и пр.) для нечетких чисел определяются через соответствующие операции для четких чисел с использованием принципа обобщения следующим образом.
Пусть А и В - нечеткие числа, и - нечеткая операция, соответствующая операции над обычными числами. Тогда
С = АB Ûm C (z )=(m A (x )Lm B (y ))).
С = Ûm C (z )=(m A (x )Lm B (y ))),
С = Û m C (z )=(m A (x )Lm B (y ))),
С = Û m C (z )=(m A (x )L m B (y ))),
С = Û m C (z )=(m A (x )Lm B (y ))),
С = Û m C (z )=(m A (x )Lm B (y ))),
С = Û m C (z )=(m A (x )Lm B (y ))).
Замечание. Решение задач математического моделирования сложных систем с применением аппарата нечетких множеств требует выполнения большого объема операций над разного рода лингвистическими и другими нечеткими переменными. Для удобства исполнения операций, а также для ввода-вывода и хранения данных, желательно работать с функциями принадлежности стандартного вида.
Нечеткие множества, которыми приходится оперировать в большинстве задач, являются, как правило, унимодальными и нормальными. Одним из возможных методов аппроксимации унимодальных нечетких множеств является аппроксимация с помощью функций (L-R)-типа.
Список литературы
1. Орлов А.И. Теория принятия решений. Учебное пособие / А.И.Орлов.- М.: Издательство «Экзамен», 2005. - 656 с.
2. Борисов А. Н., Кроумберг О. А., Федоров И. П. Принятие решений на основе нечетких моделей: примеры использования. - Рига: Зинатве, 1990. - 184 с.
3. Андрейчиков А.В., Андрейчикова О.Н. Анализ, синтез, планирование решений в экономике — М.: Финансы и статистика, 2000. — 368 с.
4. Нечеткие множества в моделях управления и искусственного интеллекта/Под ред. Д. А. Поспелова. — М.: Наука, 1986. — 312 с.
5. Боросов А.Н. Принятие решений на основе нечетких моделей: Примеры использования. Рига: Зинанте, 1990.
6. Вопросы анализа и процедуры принятия решений/Под ред. И.Ф. Шахнова. М.: Мир, 1976.
7. Кофман А. Введение в теорию нечетких множеств/Пер, с франц. М,: Радио и связь, 1982.
9. Лебег А. Об измерении величин. - М.: Учпедгиз, 1960. - 204 с.
10. Орлов А.И. Основания теории нечетких множеств (обобщение аппарата Заде). Случайные толерантности. - В сб.: Алгоритмы многомерного статистического анализа и их применения. - М.: Изд-во ЦЭМИ АН СССР, 1975. - С.169-175.
Классическая логика по определению не может оперировать с нечетко очерченными понятиями, поскольку все высказывания в формальных логических системах могут иметь только два взаимоисключающих состояния: «истина» со значением истинности «1» и «ложь» со значением истинности «0». Одной из попыток уйти от двузначной бинарной логики для описания неопределенности было введение Лукашевичем трехзначной логики с третьим состоянием «возможно» со значением истинности «0,5». Введя в рассмотрение нечеткие множества, Заде предложил обобщить классическую бинарную логику на основе рассмотрения бесконечного множества значений истинности. В предложенном Заде варианте нечеткой логики множество значений истинности высказываний обобщается до интервала 0 ; 1 , т.е. включает как частные случаи классическую бинарную логику и трехзначную логику Лукашевича. Такой подход позволяет рассматривать высказывания с различными значениями истинности и выполнять рассуждения с неопределенностью.
Нечеткое высказывание – это законченная мысль, об истинности или ложности которой можно судить только с некоторой степенью уверенности 0 ; 1: «возможно истинно», «возможно ложно» и т.п. Чем выше уверенность в истинности высказывания, тем ближе значение степени истинности к 1 . В предельных случаях 0 , если мы абсолютно уверены в ложности высказывания, и 1 , если мы абсолютно уверены в истинности высказывания, что соответствует классической бинарной логике. В нечеткой логике нечеткие высказывания обозначаются так же, как и нечеткие множества: A , B , C … . Введем нечеткое отображение T: Ω → 0 ; 1 , которое действует на множестве нечетких высказываний Ω = A , B , C … . В этом случае значение истинности высказывания A ∈ Ω определяется как T A ∈ 0 ; 1 и является количественной оценкой нечеткости, неопределенности, содержащейся в высказывании A .
Логическое отрицание нечеткого высказывания A обозначается ¬ A – это унарная (т.е. производимая над одним аргументом) логическая операция, результат которой является нечетким высказыванием «не A », «неверно, что A », значение истинности которого:
T ¬ A = 1 − T A .
Помимо приведенного выше исторически принятого основного определения нечеткого логического отрицания (нечеткого «НЕ»), введенного Заде, могут использоваться следующие альтернативные формулы:
T ¬ A = 1 − T A 1 + λT A , λ > − 1, – нечеткое λ -дополнение по Сугено;
T ¬ A = 1 − T A p , p > 0, – нечеткое p -дополнение по Ягеру.
Логическая конъюнкция нечетких высказываний A и B обозначается A ∩ B – это бинарная (т.е. производимая над двумя аргументами) логическая операция, результат которой является нечетким высказыванием « A и B », значение истинности которого:
T A ∩ B = min T A ; T B .
Помимо приведенного выше исторически принятого основного определения логической конъюнкции (нечеткого «И»), введенного Заде, могут использоваться следующие альтернативные формулы:
T A ∩ B = T A T B – в базисе Бандлера-Кохоута;
T A ∩ B = max T A + T B − 1 ; 0 – в базисе Лукашевича-Гилеса;
T A ∩ B = T B , при T A = 1 ; T A , при T B = 1 ; 0, в остальных случаях; – в базисе Вебера.
Логическая дизъюнкция нечетких высказываний A и B обозначается A ∪ B – это бинарная логическая операция, результат которой является нечетким высказыванием « A или B », значение истинности которого:
T A ∪ B = max T A ; T B .
Помимо приведенного выше исторически принятого основного определения логической дизъюнкции (нечеткого «ИЛИ»), введенного Заде, могут использоваться следующие альтернативные формулы:
T A ∪ B = T A + T B − T A T B – в базисе Бандлера-Кохоута;
T A ∪ B = min T A + T B ; 1 – в базисе Лукашевича-Гилеса;
T A ∪ B = T B , при T A = 0 ; T A , при T B = 0 ; 1, в остальных случаях; – в базисе Вебера.
Нечеткая импликация нечетких высказываний A и B обозначается A ⊃ B – это бинарная логическая операция, результат которой является нечетким высказыванием «из A следует B », «если A , то B », значение истинности которого:
T A ⊃ B = max min T A ; T B ; 1 − T A .
Помимо приведенного выше исторически принятого основного определения нечеткой импликации, введенного Заде, могут использоваться следующие альтернативные определения нечеткой импликации, предложенные различными исследователями в области теории нечетких множеств:
T A ⊃ B = max 1 − T A ; T B – Гедель;
T A ⊃ B = min T A ; T B – Мамдани;
T A ⊃ B = min 1 ; 1 − T A + T B – Лукашевич;
T A ⊃ B = min 1 ; T B T A , T A > 0 – Гоген;
T A ⊃ B = min T A + T B ; 1 – Лукашевич-Гилес;
T A ⊃ B = T A T B – Бандлер-Кохоут;
T A ⊃ B = max T A T B ; 1 − T A – Вади;
T A ⊃ B = 1, T A ≤ T B ; T B , T A > T B ; – Бауэр.
Общее число введенных определений нечеткой импликации не ограничивается приведенными выше. Большое количество работ по изучению различных вариантов нечеткой импликации обусловлено тем, что понятие нечеткой импликации является ключевым при нечетких выводах и принятии решений в нечетких условиях. Наибольшее применение при решении прикладных задач нечеткого управления находит нечеткая импликация Заде.
Нечеткая эквивалентность нечетких высказываний A и B обозначается A ≡ B – это бинарная логическая операция, результат которой является нечетким высказыванием « A эквивалентно B », значение истинности которого:
T A ≡ B = min max T ¬ A ; T B ;max T A ; T ¬ B .
Так же, как в классической бинарной логике, в нечеткой логике с помощью рассмотренных выше логических связок можно формировать достаточно сложные логические высказывания.
2.1 Основные понятия нечеткой логики
Как было упомянуто в предыдущих главах, классическая логика оперирует только двумя понятиями: «истина» и «ложь», и исключая любые промежуточные значения. Аналогично этому булева логика не признает ничего кроме единиц и нулей.
Нечеткая же логика основана на использовании оборотов естественного языка. Человек сам определяет необходимое число терминов и каждому из них ставит в соответствие некоторое значение описываемой физической величины. Для этого значения степень принадлежности физической величины к терму (слову естественного языка, характеризующего переменную) будет равна единице, а для всех остальных значений ‒ в зависимости от выбранной функции принадлежности.
При помощи нечетких множеств можно формально определить неточные и многозначные понятия, такие как «высокая температура», «молодой человек», «средний рост» либо «большой город». Перед формулированием определения нечеткого множества необходимо задать так называемую область рассуждений (universe of discourse). В случае неоднозначного понятия «много денег» большой будет признаваться одна сумма, если мы ограничимся диапазоном и совсем другая–в диапазоне .
Лингвистические переменные:
Лингвистической переменной является переменная, для задания которой используются лингвистические значения, выражающие качественные оценки, или нечеткие числа. Примером лингвистической переменной может быть скорость или температура, примером лингвистического значения - характеристика: большая, средняя, малая, примером нечеткого числа - значение: примерно 5, около 0.
Лингвистическим терм-множеством называется множество всех лингвистических значений, используемых для определения некоторой лингвистической переменной. Областью значений переменной является множество всех числовых значений, которые могут принимать определенный параметр изучаемой системы, или множество значений, существенное с точки зрения решаемой задачи.
Нечеткие множества:
Пусть
‒ универсальное множество, ‒
элемент, а
‒
элемент, а ‒
некоторое свойство. Обычное (четкое)
подмножество
‒
некоторое свойство. Обычное (четкое)
подмножество универсального множества
универсального множества , элементы которого удовлетворяют
свойству
, элементы которого удовлетворяют
свойству ,
определяются как множество упорядоченных
пар
,
определяются как множество упорядоченных
пар ,где
,где ‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
Нечеткое
подмножество отличается от обычного
тем, что для элементов
 из
из нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества
нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества определяется как множество упорядоченных
пар
определяется как множество упорядоченных
пар ,
где
,
где ‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например,
‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например, ).
Функция принадлежности указывает
степень принадлежности элемента
).
Функция принадлежности указывает
степень принадлежности элемента множеству
множеству .
Множество
.
Множество называют множеством принадлежностей.
Если
называют множеством принадлежностей.
Если ,
то нечеткое множество может рассматриваться
как обычное четкое множество.
,
то нечеткое множество может рассматриваться
как обычное четкое множество.
Множество
элементов пространства  ,
для которых
,
для которых  ,
называется носителем нечеткого множества
,
называется носителем нечеткого множества
 и обозначается supp
A
:
и обозначается supp
A
:
Высота
нечеткого множества
 определяется как
определяется как
Нечеткое
множество
 называется нормальным тогда и только
тогда, когда
называется нормальным тогда и только
тогда, когда .
Если нечеткое множество
.
Если нечеткое множество не является нормальным, то его можно
нормализовать при помощи преобразования
не является нормальным, то его можно
нормализовать при помощи преобразования
 ,
,
где
 ‒ высота этого множества.
‒ высота этого множества.
Нечеткое
множество ,
является выпуклым тогда и только тогда,
когда для произвольных
,
является выпуклым тогда и только тогда,
когда для произвольных и
и выполняется
условие
выполняется
условие
2.1.1 Операции над нечеткими множествами
Включение.
Пусть
 и
и ‒ нечеткие множества на универсальном
множестве
‒ нечеткие множества на универсальном
множестве .
Говорят, что
.
Говорят, что содежится в
содежится в ,
если
,
если
Равенство. и равны, если
Дополнение.
Пусть
 ,
, и
и ‒ нечеткие множества, заданные на
‒ нечеткие множества, заданные на .
. и
и дополняют
друг друга, если.
дополняют
друг друга, если.
Пересечение.
 ‒
наибольшее нечеткое подмножество,
содержащееся одновременно в
‒
наибольшее нечеткое подмножество,
содержащееся одновременно в и
и :
:
Объединение.
 ‒ наибольшее нечеткое подмножество,
содержащее все элементы из
‒ наибольшее нечеткое подмножество,
содержащее все элементы из и
и :
:
Разность.
 ‒ подмножество с функцией принадлежности:
‒ подмножество с функцией принадлежности:
2.1.2 Нечеткие отношения
Пусть
 ‒
прямое произведение универсальных
множеств и
‒
прямое произведение универсальных
множеств и ‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество
‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество на
на , принимающее свои значения в
, принимающее свои значения в .
В случае
.
В случае и
и нечетким отношением
нечетким отношением между
множествами
между
множествами и
и будет
называться функция
будет
называться функция ,
которая ставит в соответствие каждой
паре элементов
,
которая ставит в соответствие каждой
паре элементов величину
величину .
.
Пусть

‒ нечеткое отношение
‒ нечеткое отношение между
между и
и , и
, и нечеткое отношение
нечеткое отношение между
между и
и .
Нечеткое отношение между
.
Нечеткое отношение между и
и ,
обозначаемое
,
обозначаемое ,
определенное через
,
определенное через и
и выражением,
называется композицией отношений
выражением,
называется композицией отношений и
и .
.
Нечеткая импликация.
Нечеткая
импликация представляет собой правило
вида: ЕСЛИ
 ТО
ТО ,где
,где – условие, а
– условие, а – заключение, причем
– заключение, причем и
и ‒ нечеткие множества, заданные своими
функциями принадлежности
‒ нечеткие множества, заданные своими
функциями принадлежности ,
, и областями определения
и областями определения ,
, соответственно. Обозначается импликация
как
соответственно. Обозначается импликация
как .
.
Различие между классической и нечеткой импликацией состоит в том, что в случае классической импликации условие и заключение могут быть либо абсолютно истинными, либо абсолютно ложными, в то время как для нечеткой импликации допускается их частичная истинность, со значением, принадлежащим интервалу . Такой подход имеет ряд преимуществ, поскольку на практике редко встречаются ситуации, когда условия правил удовлетворяются полностью, и по этой причине нельзя полагать, что заключение абсолютно истинно.
В нечеткой
логике существует множество различных
операторов импликации. Все они дают
различные результаты, степень эффективности
которых зависит в частности от моделируемой
системы. Одним из наиболее распространенных
операторов импликации является оператор
Мамдани, основанный на предположении,
что степень истинности заключения не может быть выше степени выполнения
условия
не может быть выше степени выполнения
условия :
:
2.2 Построение нечеткой системы
Из разработок искусственного интеллекта завоевали устойчивое признание экспертные системы, как системы поддержки принятия решений. Они способны аккумулировать знания, полученные человеком в различных областях деятельности. Посредством экспертных систем удается решить многие современные задачи, в том числе и задачи управления. Одним из основных методов представления знаний в экспертных системах являются продукционные правила, позволяющие приблизиться к стилю мышления человека. Обычно продукционное правило записывается в виде: «ЕСЛИ (посылка) (связка) (посылка)… (посылка) ТО (заключение)».Возможно наличие нескольких посылок в правиле, в этом случае они объединяются посредством логических связок «И», «ИЛИ».
Нечеткие системы (НС) тоже основаны на правилах продукционного типа, однако в качестве посылки и заключения в правиле используются лингвистические переменные, что позволяет избежать ограничений, присущих классическим продукционным правилам.
Таким образом, нечеткая система - это система, особенностью описания которой является:
нечеткая спецификация параметров;
нечеткое описание входных и выходных переменных системы;
нечеткое описание функционирования системы на основе продукционных «ЕСЛИ…ТО…»правил.
Важнейшим классом нечетких систем являются нечеткие системы управления (НСУ).Одним из важнейших компонентов НСУ является база знаний, которая представляет собой совокупность нечетких правил «ЕСЛИ–ТО», определяющих взаимосвязь между входами и выходами исследуемой системы. Существуют различные типы нечетких правил: лингвистическая, реляционная, модель Такаги-Сугено и др.
Для многих приложений, связанных с управлением процессами, необходимо построение модели рассматриваемого процесса. Знание модели позволяет подобрать соответствующий регулятор (модуль управления). Однако часто построение корректной модели представляет собой трудную проблему, требующую иногда введения различных упрощений. Применение теории нечетких множеств для управления процессами не предполагает знания моделей этих процессов. Следует только сформулировать правила поведения в форме нечетких условных суждений типа «ЕСЛИ-ТО».

Рисунок 2.1 -. Структура нечеткой системы управления
Процесс управления системой напрямую связан с выходной переменной нечеткой системы управления, но результат нечеткого логического вывода является нечетким, а физическое исполнительное устройство не способно воспринять такую команду. Необходимы специальные математические методы, позволяющие переходить от нечетких значений величин к вполне определенным. В целом весь процесс нечеткого управления можно разбить на несколько стадий: фаззификация, разработка нечетких правил и дефаззификация.
Фаззификаия подразумевает переход к нечеткости. На данной стадии точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно ‒ при помощи определенных функций принадлежности.
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются «термами». Так, значением лингвистической переменной «Дистанция» являются термы «Далеко», «Близко» и т. д. Для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Допустим переменная «Дистанция» может принимать любое значение из диапазона от 0 до 60 метров. Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет степень принадлежностиданного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной «Дистанция». Тогда расстоянию в 50 метров можно задать степень принадлежности к терму «Далеко», равную 0,85, а к терму «Близко» ‒ 0,15. Задаваясь вопросом, сколько всего термов в переменной необходимо для достаточно точного представления физической величины принято считать, что достаточно 3-7 термов на каждую переменнуюдля большинства приложений. Большинствоприменений вполне исчерпывается использованием минимального количества термов.Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число 7 же обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
Принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным, однако сформировалось понятие о так называемых стандартных функциях принадлежности

Рисунок 2.2 ‒ Стандартные функции принадлежности
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Следующей стадией является стадия разработки нечетких правил.
На ней определяются продукционные правила, связывающие лингвистические переменные. Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (частьЕСЛИ …) и консеквента (часть ТО…). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок«И» или «ИЛИ».
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение.
Пусть имеется следующее правило:
ЕСЛИ «Дистанция» = средняя И «Угол» =малый, ТО «Мощность» = средняя.
На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: Min(…) и Max(…). Первый вычисляет минимальное значение степени принадлежности, а второй ‒ максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка «И», применяется оператор Min(…). Если же посылки объединены связкой «Или», необходимо применить оператор Max(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны.
Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов Min/Maxвычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил.
После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией.
На этапе дефаззификации осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству.
Результат нечеткого вывода, конечно же, будет нечетким. Например, если речь идет об управлении механизмом и команда для электромотора будет представлена термом «Средняя» (мощность), то для исполнительного устройства это ровно ничего не значит. В теории нечетких множеств процедура дефаззификации аналогична нахождению характеристик положения (математического ожидания, моды, медианы) случайных величин в теории вероятности. Простейшим способом выполнения процедуры дефаззификации является выбор четкого числа, соответствующего максимуму функции принадлежности. Однако пригодность этого способа ограничивается лишь одно экстремальными функциями принадлежности. Для устранения нечеткости окончательного результата существует несколько методов: метод центра максимума, метод наибольшего значения, метод центроида и другие. Для многоэкстремальных функций принадлежности наиболее часто используется дефаззификация путем нахождения центра тяжести плоской фигуры, ограниченной осями координат и функцией принадлежности.
2.3. Модели нечеткого логического вывода
Нечеткий логический вывод - это аппроксимация зависимости «входы–выход» на основе лингвистических высказываний типа «ЕСЛИ–ТО» и операций над нечеткими множествами. Нечеткая модель содержит следующие блоки:
‒
фаззификатор, преобразующий фиксированный
вектор влияющих факторов Xв вектор
нечетких множеств
 ,
необходимых для выполнения нечеткого
логического вывода;
,
необходимых для выполнения нечеткого
логического вывода;
‒ нечеткая
база знаний, содержащая информацию о
зависимости
 в виде лингвистических правил типа
«ЕСЛИ–ТО»;
в виде лингвистических правил типа
«ЕСЛИ–ТО»;
‒ машина
нечеткого логического вывода, которая
на основе правил базы знаний определяет
значение выходной переменной в виде
нечеткого множества ,
соответствующего нечетким значениям
входных переменных
,
соответствующего нечетким значениям
входных переменных ;
;
‒
дефаззификатор, преобразующий выходное
нечеткое множество
 в четкое число Y.
в четкое число Y.

Рисунок 2.3 ‒ Структура нечеткой модели.
2.3.1Нечеткая модель типа Мамдани
Данный алгоритм описывает несколько последовательно выполняющихся этапов. При этом каждый последующий этап получает на вход значения полученные на предыдущем шаге.

Рисунок 2.4 – Диаграмма деятельности процесса нечеткого вывода
Алгоритм примечателен тем, что он работает по принципу «черного ящика». На вход поступают количественные значения, на выходе они же. На промежуточных этапах используется аппарат нечеткой логики и теория нечетких множеств. В этом и состоит элегантность использования нечетких систем. Можно манипулировать привычными числовыми данными, но при этом использовать гибкие возможности, которые предоставляют системы нечеткого вывода.
В модели типа Мамдани взаимосвязь между входами X = (x 1 , x 2 ,…, x n)и выходом y определяется нечеткой базой знаний следующего формата:
 ,
,
где
 -
лингвистический терм, которым оценивается
переменная x i в строке с номером
-
лингвистический терм, которым оценивается
переменная x i в строке с номером ;
; ),
где
),
где -
количество строк-конъюнкций, в которых
выход
-
количество строк-конъюнкций, в которых
выход оценивается
лингвистическим термом
оценивается
лингвистическим термом ;
; -
количество термов, используемых для
лингвистической оценки выходной
переменной
-
количество термов, используемых для
лингвистической оценки выходной
переменной .
.
С помощью операций ∪(ИЛИ) и ∩ (И) нечеткую базу знаний можно переписать в более компактном виде:
 (1)
(1)
Все лингвистические термы в базе знаний (1) представляются как нечеткие множества, заданные соответствующими функциями принадлежности.
Нечеткая база знаний (1) может трактоваться как некоторое разбиение пространства влияющих факторов на подобласти с размытыми границами, в каждой из которых функция отклика принимает значение, заданное соответствующим нечетким множеством. Правило в базе знаний представляет собой «информационный сгусток», отражающий одну из особенностей зависимости «входы–выход». Такие «сгустки насыщенной информации» или «гранулы знаний» могут рассматриваться как аналог вербального кодирования, которое, как установили психологи, происходит в человеческом мозге при обучении. Видимо поэтому формирование нечеткой базы знаний в конкретной предметной области, как правило, не составляет трудностей для эксперта.
Введем следующие обозначения:
 -
функция принадлежности входа
-
функция принадлежности входа нечеткому терму
нечеткому терму ,
, т.е
т.е
 -
функция принадлежности выхода y нечеткому
терму
-
функция принадлежности выхода y нечеткому
терму ,
т.е.
,
т.е.
Степень
принадлежности входного вектора
 нечетким термам
нечетким термам из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
Наиболее часто используются следующие реализации: для операции ИЛИ - нахождение максимума, для операции И- нахождение минимума.
Нечеткое множество , соответствующее входному вектору X * , определяется следующим образом:

где imp- импликация, обычно реализуемая как операция нахождения минимума; agg- агрегирование нечетких множеств, которое наиболее часто реализуется операцией нахождения максимума.
Четкое
значение выхода
 ,
соответствующее входному вектору
,
соответствующее входному вектору ,
определяется в результате дефаззификации
нечеткого множества
,
определяется в результате дефаззификации
нечеткого множества .
Наиболее часто применяется дефаззификация
по методу центра тяжести:
.
Наиболее часто применяется дефаззификация
по методу центра тяжести:

Модели типа Мамдани и типа Сугэно будут идентичными, когда заключения правил заданы четкими числами, т. е. в случае, если:
1) термы d j выходной переменной в модели типа Мамдани задаются синглтонами - нечеткими аналогами четких чисел. В этом случае степени принадлежностей для всех элементов универсального множества равны нулю, за исключением одного со степенью принадлежности равной единице;
2) заключения правил в базе знаний модели типа Сугэно заданы функциями, в которых все коэффициенты при входных переменных равны нулю.
2.3.2 Нечеткая модель типа Сугэно
На сегодняшний день существует несколько моделей нечеткого управления, одной из которых является модель Такаги-Сугено.
Модель Такаги-Сугено иногда носит называние Takagi-Sugeno-Kang. Причина состоит в том, что этот тип нечеткой модели был первоначально предложен Takagi и Sugeno. Однако Канг и Сугено провели превосходную работу над идентификацией нечеткой модели. Отсюда и происхождение названия модели.
В
модели типа Сугэно взаимосвязь между
входами  и
выходом y задается
нечеткой базой знаний вида:
и
выходом y задается
нечеткой базой знаний вида:
где
 -
некоторые числа.
-
некоторые числа.
База
знаний (3) аналогична (1) за исключением
заключений правил  ,
которые задаются не нечеткими термами,
а линейной функцией от входов:
,
которые задаются не нечеткими термами,
а линейной функцией от входов:
 ,
,
Таким
образом, база знаний в модели типа Сугэно
является гибридной - ее правила содержат
посылки в виде нечетких множеств и
заключения в виде четкой линейной
функции. База знаний (3) может трактоваться
как некоторое разбиение пространства
влияющих факторов на нечеткие подобласти,
в каждой из которых значение функции
отклика рассчитывается как линейная
комбинация входов. Правила являются
своего рода переключателями с одного
линейного закона «входы–выход» на
другой, тоже линейный. Границы подобластей
размытые, следовательно, одновременно
могут выполняться несколько линейных
законов, но с различными весами.
Результирующее значение выхода
 определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке
определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке  n-мерного факторного
пространства. Это может быть
взвешенное среднее
n-мерного факторного
пространства. Это может быть
взвешенное среднее
 ,
,
или взвешенная сумма
 .
.
Значения
 рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.
рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.










Значение слова неудачный
Обзор Samsung Galaxy A7 (2017): не боится воды и экономии Стоит ли покупать samsung a7
Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows